webpack默认会将尽可能多的模块代码打包在一起,这样能减少最终页面的 HTTP 请求数。
不过这样的缺点有:
- 页面初始代码包过大,影响首屏渲染性能;
- 无法有效应用浏览器缓存(特别对于 NPM 包这类变动较少的代码,业务代码哪怕改了一行都会导致 NPM 包缓存失效);
splitChunk就是用来解决这个问题,它可以根据一系列规则,将原本巨大的包拆分,从而尽量避免上述问题:比如我们可以异步组件拆分(lazy load)、可以把第三方依赖包统一拆分(有利于缓存)、可以把多个chunk之间的重复代码提取出来,等等。
Chunk概念回顾
Chunk 是 Webpack 内部一个非常重要的底层设计,用于组织、管理、优化最终产物,在构建流程进入生成(Seal)阶段后:
- Webpack 首先根据 entry 配置创建若干 Chunk 对象;
- 遍历构建(Make)阶段找到的所有 Module 对象,同一 Entry 下的模块分配到 Entry 对应的 Chunk 中;
- 遇到异步模块则创建新的 Chunk 对象,并将异步模块放入该 Chunk;
- 分配完毕后,根据 SplitChunksPlugin 的启发式算法进一步对这些 Chunk 执行裁剪、拆分、合并、代码调优,最终调整成运行性能(可能)更优的形态;
- 最后,将这些 Chunk 一个个输出成最终的产物(Asset)文件,编译工作到此结束。
Chunk 在构建流程中起着承上启下的关键作用 一方面作为 Module 容器,根据一系列默认 分包策略 决定哪些模块应该合并在一起打包; 另一方面根据 splitChunks 设定的策略优化分包,决定最终输出多少产物文件;
简单来说,就是如果没有splitChunk设置的规则,那么,一个异步模块对应一个chunk(Async Chunk ),以及一个入口就对应一个chunk( Initial Chunk)。(或者更粗暴的这样理解,异步模块理解成入口,所以chunk和入口一一对应)。当然,有splitChunk规则的话,在上述入口chunk的基础之上再进行拆分和合并等工作,最终形成若干chunks,输出为产物。
那么,假设没有splitChunk,就按照入口和异步模块这样划分chunk,会有什么问题呢?
- 重复代码多次打包问题
假设我们有两个入口,main.js、sub.js,以及一个异步模块modal.js他们都引用了一个common.js这个module,那么最终形成的chunks我们称之为:chunk[main]、chunk[sub]和chunk[common],但是这三个chunk都会包含common这部分代码;
举例子说明: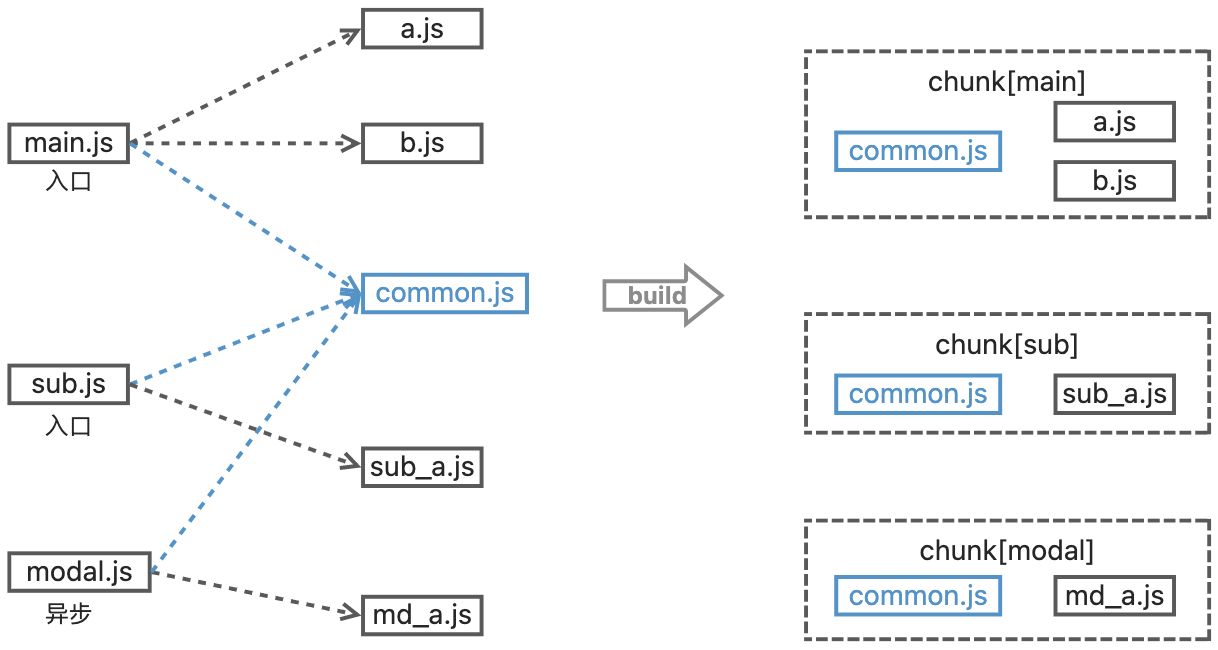
- 缓存失效
将所有资源都打包成一个包后,所有改动 ,客户端都需要重新下载整个代码包(文件名根据hash变化),缓存命中率极低;至少业务代码变动,不应该使得第三方依赖再被加载一次;
所以,针对这些问题的策略是:
利用splitChunks,1. 将重复代码提取出;2. 将第三方依赖提取出;
splitChunks
参考:
splitChunks 主要有两种类型的配置:
- minChunks/minSize/maxInitialRequest 等分包条件,满足这些条件的模块都会被执行分包;
- cacheGroup :用于为特定资源声明特定分包条件;
而每一个cacheGroup中,也可以包含其minChunks/minSize/maxInitialRequest 等分包条件;
chunks:设置分包范围
splitChunks.chunks 调整作用范围,该配置项支持如下值:
- 字符串 ‘all’ :对 Initial Chunk 与 Async Chunk 都生效,建议优先使用该值;
- 字符串 ‘initial’ :只对 Initial Chunk 生效;
- 字符串 ‘async’ :只对 Async Chunk 生效;
- 函数 (chunk) => boolean :该函数返回 true 时生效;
一般设置为all就行:
module.exports = {//...optimization: {splitChunks: {chunks: 'all',},},}
minChunks:根据使用频率分包
下面demo设定引用次数超过 2 的模块才进行分包:
module.exports = {//...optimization: {splitChunks: {// 设定引用次数超过 2 的模块才进行分包minChunks: 2},},}
但是这个“引用次数”不是具体某个module的import次数,而是chunk级别的,可以这样理解,就是具体某个module被多少个chunk使用的chunk数。
比如上述demo:
假设我们有两个入口,main.js、sub.js,以及一个异步模块modal.js他们都引用了一个common.js这个module,那么最终形成的chunks我们称之为:chunk[main]、chunk[sub]和chunk[common],但是这三个chunk都会包含common这部分代码;
那么这个common被3个chunk都引用了,所以能命中这里“minChunks: 2”的规则。
请求数限制
maxInitialRequest/maxAsyncRequest 配置项,用于限制分包数量:
- maxInitialRequest:用于设置 Initial Chunk 最大并行请求数;
- maxAsyncRequests:用于设置 Async Chunk 最大并行请求数;
什么是请求数?
为防止最终产物文件数量过多导致 HTTP 网络请求数剧增,反而降低应用性能。这里所说的“请求数”,是指加载一个 Chunk 时所需要加载的所有分包数。
例如对于一个 Chunk A,如果根据分包规则(如模块引用次数、第三方包)分离出了n个子 Chunk A[i],那么加载 A 时,浏览器需要同时加载所有的 A[i],此时并行请求数等于 n个分包加 A 主包,即 n+1
比如:
若 minChunks = 2 ,则 common1 、common2 同时命中 minChunks 规则被分别打包。
浏览器请求 entryB 时需要同时请求 common1 、common2 两个分包,B的并行数为 2 + 1 = 3。
此时若 maxInitialRequest = 2,则分包数超过阈值。这样webpack会放弃 common1、common2 中体积较小的分包,比如common1较小,则common2会被单独打包出来,而common1会合并到主包中。
maxAsyncRequest 逻辑与此类似。
并行请求数关键逻辑总结如下:
- Initial Chunk 本身算一个请求;
- 通过 runtimeChunk 拆分出的 runtime 不算并行请求;
- 如果同时有两个 Chunk 满足拆分规则,但是 maxInitialRequests(或 maxAsyncRequest) 的值只能允许再拆分一个模块,那么体积更大的模块会被优先拆解。
限制分包大小
为了避免拆分的chunk太琐碎,webpack提供了用来限制分包大小的规则:
- minSize: 分包最小尺寸,超过这个尺寸的 chunk 才会正式被分包;
- maxSize: 分包最大尺寸,超过这个尺寸的 chunk 会尝试进一步拆分出更小的 Chunk;
- maxAsyncSize: 与 maxSize 功能类似,但只对异步引入的模块生效;
- maxInitialSize: 与 maxSize 类似,但只对 entry 配置的入口模块生效;
- enforceSizeThreshold: 强制分包,超过这个尺寸的 Chunk 会被强制分包,忽略上述其它 Size 限制。
总结流程
最后,总结下minChunks、maxInitialRequests、minSize等规则配合下,webpack对分包的其具体策略:
- 尝试将命中 minChunks 规则的 Module 统一抽到一个额外的 Chunk 对象;
- 判断该 Chunk 是否满足 maxInitialRequests 阈值,若满足则进行下一步;
- 判断该 Chunk 资源的体积是否大于上述配置项 minSize 声明的下限阈值;
- 如果体积小于 minSize 则取消这次分包,对应的 Module 依然会被合并入原来的 Chunk;
- 如果 Chunk 体积大于 minSize 则判断是否超过 maxSize、maxAsyncSize、maxInitialSize 声明的上限阈值,如果超过则尝试将该 Chunk 继续分割成更小的部分;
cacheGroup分包组
上述 minChunks、maxInitialRequest、minSize 都是分包条件。
而分包组cacheGroup,用来对不同文件进行不同的分包配置处理。
cacheGroups 支持上述 minSice/minChunks/maxInitialRequest 等条件配置,此外,还包括:
- test:文件名筛选,接受正则表达式、函数及字符串,所有符合 test 判断的 Module 或 Chunk 都会被分到该组;
- type:文件类型筛选,接受正则表达式、函数及字符串,与 test 类似均用于筛选分组命中的模块,区别是它判断的依据是文件类型而不是文件名,例如 type = ‘json’ 会命中所有 JSON 文件;
- idHint:字符串型,用于设置 Chunk ID,它还会被追加到最终产物文件名中,例如 idHint = ‘vendors’ 时,输出产物文件名形如 vendors-xxx-xxx.js ;
- priority:优先级,数字型,用于设置该分组的优先级,若模块命中多个缓存组,则优先被分到 priority 更大的组。
这是webpack官网提供的默认的cacheGroups的配置(将默认分组设置为 false,关闭分组配置):
module.exports = {//...optimization: {splitChunks: {cacheGroups: {default: {idHint: "",reuseExistingChunk: true,minChunks: 2,priority: -20},defaultVendors: {idHint: "vendors",reuseExistingChunk: true,test: /[\\/]node_modules[\\/]/i,priority: -10}},// 关闭默认设置// cacheGroups: {// default: false// },},},};
- defaultVendors:node_modules 中的资源单独打包到 vendors-xxx-xx.js 命名的产物,
- default:引用次数大于等于 2 的模块 —— 也就是被多个 Chunk 引用的模块,单独打包;
实践总结
回顾spiltChunk的常用配置项:
| minChunks | 设置引用阈值,被引用次数超过该阈值的 Module 才会进行分包处理(具体某个module被多少个chunk使用的chunk数) |
|---|---|
| maxInitialRequest/maxAsyncRequests | 用于限制 Initial Chunk(或 Async Chunk) 最大并行请求数,本质上是在限制最终产生的分包数量 |
| minSize | 超过这个尺寸的 Chunk 才会正式被分包 |
| maxSize | 超过这个尺寸的 Chunk 会尝试继续对其分包 |
| maxAsyncSize/maxInitialSize | 与 maxSize 功能类似,但只对异步/同步引入的模块生效 |
| enforceSizeThreshold | 超过这个尺寸的 Chunk 会被强制分包,忽略上述其它 size 限制; |
| cacheGroups |
用于设置缓存组规则,为不同类型的资源设置更有针对性的分包策略; |
结合这些特性,业界已经总结了许多惯用的最佳分包策略:
- 针对 node_modules 资源:
可以将 node_modules 模块打包成单独文件(通过 cacheGroups 实现),防止业务代码的变更影响 NPM 包缓存,同时建议通过 maxSize 设定阈值,防止 vendor 包体过大;
- 针对业务代码:
- 设置 common 分组,通过 minChunks 配置项将使用率较高的资源合并为 Common 资源;
- 首屏用不上的代码,尽量以异步方式引入;
- 置 optimization.runtimeChunk 为 true,将运行时代码拆分为独立资源;
不过上述策略也是可能只是参考,软件工程没有银弹。真实场景,具体项目,还是得具体分析。

若有收获,就点个赞吧
0 人点赞
