- 1.react函数组件与类组件区别
- 2.className和classList的区别
- 3.检测数据的方法及原理
- 4.link和@import的区别
- 5.遍历对象时,把对象原型上的属性遍历出来怎么解决—-instanceof/hasOwnProperty
- 6.hash与history路由区别
- 7.前端性能优化
- 8.vue2与vue3数据劫持有什么区别
- 9.shouldComponentUpdate的作用
- 10.本地存储
- 11.history路由页面404怎么解决
- 12.ajax实现步骤;
- 13.APP分类
- 14.小程序的热启动和冷启动
- 15.回流,重绘
- 16.span最大值
- 17.vue响应式原理
- 18.深拷贝与浅拷贝
- 30.es6新增(Es6认识)
- 31.iOS和安卓兼容
- 32.HTTP和HTTPS
- 33.移动端常见的bug有哪些
- 34.tcp和udp的区别
- 35.设计模式
- 36.长链接和短连接
- 37.协商缓存和强缓存的区别
- 38.vue特性
- 39.vue3.0特点
- 40.vue生命周期钩子函数 (vue2,vue3)
- 41.vue3.0和vue2.0的区别
- 42.http三次握手,四次分手
- 43.原型和原型链
- 45.节流和防抖
- 46.vue模板里面引入计算属性和方法调用
- 47.webpack,webpack优化
- 48.canvas绘图
- 50.微任务与宏任务
- 51.call(),apply(),bind()三者的区别
- 52.vue的双向绑定原理
- 53.object.defineproperty有什么弊端
- 54.组件传值
- 55.v-for中的key值,不推荐使用index
- 56.diff算法怎么去比较有没有key值
- 57.webpack中loder和plugins的区别
- 55.vue3.0的数据响应
- 56.除了api,还有其他方法对数组新增元素,添加响应式
- 57.computed计算属性,它有什么优点
- 58.vue3的apiwatcheffect和watch有什么区别
- 59.vue3.0的apiwatcheffect 和 react的effect有什么区别
- 60.ts泛型,枚举
- 61.vite的理解
- 62.闭包的使用
- 63.css隐藏一个元素会用到什么
- 64.作用域链
- 65.js中的继承有那些
- 66.vue渐进式开发
- 67.MVVM数据驱动的原理
- 68.虚拟dom和真实dom的区别
- 69.app中px转rem
- 70.vue性能优化
- 71.三次握手四次连接
- 72.vue父子组件加载的顺序是怎么样
- 73.vue单项数据流
- 74.浏览器常用的兼容问题
- 75.vue的动态路由怎样配置
- 76.协商缓存的last-modified与eate有什么区别
- 77.cookie怎么防止xxs跟csrf攻击
- 78.ts怎么运行 (不用编译成js)
- 79.数组去重reduce怎么实现
- 80. react hooks中useState()怎么拿到最新的值 (除了useEffict())
- 81.promise中all与race这两个方法的区别
- 82.磁盘缓存与内存缓存的区别
- 83 indexedDB和 LocalStorage的区别
84.树形转平铺,平铺转树形- 85.websocket使用
- 86.平时用户上传的图片,或者我们自己的静态图,使用什么压缩工具压缩的
- 86.webpack性能优化
- 87.不同苹果手机兼容问题
- 88.5年与3年的区别
- 89.代码评审
- 90.commit规范
- 100.从业务上讲讲你遇到的逻辑难题
- 101.vue.nextTick()与setTimeout的区别
- 102.vue插槽
- 103.defineProperty与proxy的区别
- 104父子组件执行过程(vue)
- 105params和query的区别
- 106项目中的组件是怎么拆分的
- 107.什么是高阶组件(HOC)
- 108.setState为什么是异步的
1.react函数组件与类组件区别
1.语法
两者最明显的不同就是在语法上:
- 函数组件是一个纯函数,他接受一个props对象,返回一个react元素
(也称FC ,是函数的工具包)(纯展示,写的功能比较少)
- 类组件需要去继承React.Component并且创建render函数用来返回react元素,虽然实现的效果相同,但与要更多的代码
2.状态管理
- 因为函数组件是一个纯函数,所以不能在组件中使用setState(),因此函数组价也被称为无状态组件
- 如果要在组件中使用state,可以创建类组件或者将state提升到父组件中,然后通过props对象传递到子组件
3.生命周期钩子函数
- 函数组件中不能使用生命周期钩子,原因和不能使用state一样,所有的生命周期钩子都来自于继承的React.Component 中
- 因此,如果要使用生命周期钩子,就需要使用类组件
4.hooks
在react16.8版本添加了hooks,使我们可以在函数组件中使用useState钩子去管理state,使用useEffect钩子去使用生命周期函数
2.className和classList的区别
1. className
className属性设置或者返回元素的class属性,返回的是一个字符串,如果想要删除.添加.替换class属性的话,就必须对返回值进行处理,因为className返回的是一个字符串,所以只能改这个字符串的值,一个class值还好,如果是多个的话就会有点麻烦,要先转数组在添加元素,最后转回字符串 ,不能和关键词冲突
2. classList
- classList属性返回元素的类名,作为DOMTokenList对象,这个方法可以专门用于删除或者添加,替换class属性
其包含以下属性和方法
属性
- add(class1,class2,…)在元素中添加一个或者多个类名,如果指定的类名已存在,则不会添加.
- contains(class)返回布尔值,判断指定的类名是否存在
- item(index)返回类名在元素中的索引值.索引值从0开始.如果索引值在区间范围外则返回null
- remove(class1,class2,…)移除元素中一个或多个类名.注意:移除不存在的类名,不会报错.
- toggle(class,true/false)在元素中切换类名
- 第一个参数为要在元素中移除的类名,并返回false.如果该类名不存在则会在元素中添加类名,并返回true
- 第二个是可选参数,是个布尔值用于设置元素是否强制添加或移除类,不管该类名是否存在.
- 例如:移除一个class:element.classList.toggle(“classToRemove”,false);
- 添加一个class:element,classList.toggle(“classToAdd”,true)
3.检测数据的方法及原理
- typeof (只能检测基本数据类型)
- 原理: 直接去判断了js底层存储变量类型的信息
- 在ji的最初版本中,使用的是32位系统,为了性能考虑使用低位存储了变量的类型信息,会在变量的机器码的低位1~3位存储类型信息
- 000 ——- 对象 010 —— 浮点数 100 —— 字符串 110 —- 整数
- instanceof (找的不单单是父级,还有可能是父级的父级)
- 主要的实现原理就是,只要右边变量的protortype在左边的变量的原型链上即可,因此在查找的过程中会遍历左边变量的原型链,一直到找到右边的prototype,失败则返回false
- constructor (直接找的是父级,但undefind和null无法检测,返回的是function)
- 原理也是通过原型链,我们知道原型链prototype上都有一个constructor属性,指向其购找函数
- link属于HTML标签,而@import是Css提供的
- 页面被加载时,link会同时被加载,而@import引用的css会等到页面被加载完在加载
- @import只在IE5 以上才能识别,而link是HTML标签,无兼容问题
- link方式的样式的权重高于@import的权重
当使用js控制dom去改变样式的时候,只能使用link标签,因为@import不是dom可以控制的
5.遍历对象时,把对象原型上的属性遍历出来怎么解决—-instanceof/hasOwnProperty
使用hasOwnProperty判断,默认返回布尔值 (现在经常使用instanceof)
function Person(name){ this.name=name } Person.prototype.age=23 const person = new Person('Li_san') for(cosnt key in person ){console.log(key)} //name age // 使用 hasOwnPropertyfor(const key in person){ per.hasOwnProperty(key) && console.log(key) } //name
6.hash与history路由区别
- hash有#号.history没有
- hash能够兼容到IE8,history只能兼容到IE10
- hash,实际的URL之前使用哈希字符,这部分URL不会送到服务器,不需要在服务器层面上进行任何处理,,history没访问一个页面都需要服务器进行路由匹配生成html文件在发送响应给浏览器,消耗服务器大量资源
- hash刷新不会存在404问题,history浏览器直接访问嵌套路由时,会报404问题
- hash不需要服务器任何配置,history需要在服务器配置一个回调路由
- hash若以后将地址通过第三方手机app分享,若app校验严格,则地址会被标记为不合法,history用部署上线时,需要后端人员的支持,解决刷新页面服务端404问题
需要在后台服务器设置中间件, connect-history-api-fallback
7.前端性能优化
- 内容方面
- 减少HTTP 请求 (Make Fewer HTTP Requests)
- 减少DOM 元素数量 (Reduce the Numenr of DOM Element)
- 使得Ajax可缓存 (Make Ajax Cacheable)
- 针对CSS
- 把css放到代码页上端 (Put Stylesheets at the Top)
- 从页面中剥离JavaScript 与 CSS (Make JavaScript and CSS External)
- 精简JavaScript 与CSS (Minify JavaScript and CSS)
- 避免CSS表达式 (Avoid CSS Expressions)
- 针对JavaScript
- 脚本放到HTML代码页底部 (Put Sciipt at the Bottom)
- 精简 JavaScript 与 CSS (Minify JavaScript and CSS)
- 移除重复脚本 (Remove Duplicate Script)
- 面向图片
- 兼容区别
- 稳定版vue2.0兼容IE9+,9以下不兼容
- Vue3.0兼容IE11+,11以下不兼容
- 数据双向绑定区别
- Vue2.0 => 一次只能劫持一个属性,也可以劫持多个属性,但是需要for循环
- Vue2.0 => 如果在劫持之后再增加一个新的属性,这个属性是没有被劫持的,需要额外的进行劫持操作
- vue3.0 => 可以劫持多个属性,因为Vue3.0 通过proxy进行代理,返回的是一个新对象,从而达到目的
- vue3.0数据劫持通过proxy代理
- Vue3.0 => 通过proxy进行代理,代理过后无论是设置还是获取,都找这个代理对象,它有三个参数 1.target;代理的目标对象 2.key:属性名 3.value
- Vue2.0数据劫持通过ES5语法 object.defineProperty
- 1.object.defineProperty 1) 用于监听对象的数据变化 2) 无法监听数组变化(下标,长度) 3) 只能劫持对象的自身属性,动态添加的劫持不到
2.Proxy 1) proxy 返回的是一个新对象,可以通过操作返回的新对象达到目的 2) 可以监听数组变化,也可以监听到动态添加的数据
9.shouldComponentUpdate的作用
在更新数据的时候用setState修改整个数据,数据变了之后,遍历的时候所有内容都要被重现渲染,数据量少还好,数据量大就会严重影响性能
- 解决办法:
- shouldcomponentupdate 在渲染进行判断组件是否更新,更新了再渲染
- purecomponent(纯组件) 省去了虚拟dom生成和对比的过程,再类组件中使用
- react.memo() 类似于纯组件,在无状态组件中使用
10.本地存储
- cookies 是储存大小4kb,可以设置过期时间,如果不进项设置,则默认一个会话时间(一个会话指的是浏览器打开之后到浏览器关闭之前) 时需要服务器环境的
- sessionStorage 的储存大小是5mb,有过期时间,它的时间是一个会话,是不需要服务器环境的
- localStorage 的储存大小5mb,是没有过期时间,会在一直存在,除非将删除,是不需要服务器环境的
- cookies,sessionStorage,localStorage 都是不安全的,因为在浏览器上都可以直接操作修改,并且都不可以跨浏览器
seeion 存储大小是根据服务端大小确定,安全性较高,除非你将服务器攻破,过期时间根据浏览器决定
11.history路由页面404怎么解决
可以根据nginx配置得出,当我们在地址栏输入www.xxx.com时,这是会打开我们dist目录下的index.html文件,然后我们在跳转路由进入到www.xxx.com/login,关键在这里,当我们在www.xxx.com/login页执行刷新操作,ndinx loaction是没有相关/login配置的,所有就会出现404的情况,因此需要重新配置nginx,将任何页面都重定向到index.html
12.ajax实现步骤;
Ajax的原理简单来说通过XMLHttprequest对象来向服务器发异步请求,从服务器获得数据,然后用JavaScript来操作DOM而更新页面,这其中最关键的一步就是从服务器获得请求数据
步骤
- 创建一个XMLHttpRequest的对象
- XMLHttpRequest对象用于在后台与服务器交换数据
- 通过open() 与服务器建立连接
- xmlhttp.open(‘get’,url,true)
- 使用send() 来发送请求
- 使用onreadystatechange事件来监听.如果表示readystate==4就说明解析成功,且status==200(状态码成功),就说明与后台搭建成功
- 使用reaponseText来获取服务器返回的数据
get/post
- get ,post,head,options,put,patch,delete,trace,connect
- get
- 不安全,主要以为是通过地址栏进行传递数据
- 数据时可见的,而且还是可以操作,所以不安全
- 而且get的数据请求量比较小,32k,传输速度快
- 可以收藏和分享
- post
- 相对get比较安全
- 数据请求量比较大 2GB,是通过send进行传输
- 无论get还是post,发送的数据都是字符串形式
同步异步(false/true)
- 同步:一个一个执行 例:过独木桥
- 异步: 同时执行多个 例:一边听歌一边写代码
readyState 属性可能的值
- 0—-没有初始值
- 1—-已经创建了,并调用的open(),但是没有调用send()
- 2—-请求已经发送,正在处理
- 3—-正在处理
- 4—-响应完成,可以使用了
13.APP分类
- native APP 原生App (ios ->oc Android-> java)
- hybird APP 混合APP
- web APP 网页App (套了一层浏览器盒子(webiew)的页面)
区别
- native APP 原生App 性能高,成本高 (两个团队),开发周期长
- web APP 网页App 性能低,成本低,开发周期短(仅限于页面展示的),不能调用底层应用
- hybird APP 混合APP 性能一般,成本低(一个团队),可以调用底层应用 (Window.location.href=URL+?拼接参数,JSBridge)
14.小程序的热启动和冷启动
- 冷启动: 从未打开过小程序或者打开过小程序,但是已经被销毁了,这种情况下打开是冷启动 (完全从头开始)
- 热启动:此前使用过小程序且没有被销毁.这种情况在打开小程序就是热启动 (保持此前离开时的页面状态)
什么时候销毁小程序:如果小程序占用的内存过高或者小程序切入后台超过5分钟以上没有操作,那么微信会销毁小程序
15.回流,重绘
回流:当render tree的部分或者全部元素因改变自身的宽高,布局,显示或者隐藏,或元素内部的文字结构发生了变化,导致需要重新构建页面的时候,回流就产生了
(布局或者几何属性需要改变及称为回流)
- 重绘:当一个元素自身的宽高,布局,及显示或者隐藏没有改变,而只是改变了元素的外观风格的时候,就产生了重绘
(当节点需要更改外观而不会影响布局的,比如改变color就称为重绘)
- 结论:回流必定触发重绘,而重绘不一定触发回流
- 如何避免回流: 不使用能够触发回流的属性,建立一个图层,让回流在图层里面进行,限制回流和重绘的范围,减少浏览器的运算工作量
- 以下几个动作可能会导致性能问题:
- 改变window大小
- 改变字体
- 添加或删除样式
- 文字改变
- 定位或者浮动
- 盒模型
- 重绘和回流其实和Event-Loop有关
- 减少重绘和回流
- 使用translate替代top
- 使用visibility替换display:none,因为前者只会引起重绘,后者会引发回流(改变了布局)
- 不要使用table布局,可能很小的一个改动会造成整个table的重新布局
- 动画实现的速度的选择,动画速度越快,回流次数越多,也可以选择使用requestAnimationFrame.
16.span最大值
-
17.vue响应式原理
在new Vue()后,Vue会调用init函数进行初始化,也就是init过程,在这个过程Data通过Observer转换了getter/setter的形式,来对数据追踪变化,当被设置的对象被读取的时候会执行getter函数,而在被赋值的时候会执行setter函数
- 当外界通过Watcher读取数据时,会触发getter从而将Watcher添加到依赖中.
在修改对象的值的时候,会触发对应的setter,setter通知之前依赖收集得到的Dep中的每一个Watcher,告诉它们自己的值改变了,需要重新渲染视图.这时候这些Watcher就会开始调用update来更新视图.
18.深拷贝与浅拷贝
浅拷贝(浅拷贝是拷贝一层,属性为对象时,浅拷贝是复制,两个对象指向同一个地址)
function shallowClone(obj){let cloneObj={};for(let i in obj){cloneObj[i]=obj[i]}return cloneObj}
深拷贝(深拷贝是递归拷贝深层次,属性为对象时,深拷贝是新开栈,两个对象指向不同的地址) ```javascript function deepCopy(obj){ if(typeof obj ===’object’){ var result = obj.constructor ===Array?[]:{} for(var i in obj ){ result[i]=typeof obj[i]===’object’?deepCopy(obj[i]):obj[i]; } }else{ var result = obj }
return result }
<a name="SqWgQ"></a>## 20.JS实现手机底层应用原理- JSBridge:是JS和Native之前的一种通信方式.简单的说,JSBridge就是定义Native和JS的通信,Native只通过一个固定的桥对象调用JS,JS也只通过固定的桥对象调用Native.JSBridge另一个叫法及大家熟知的Hybrid APP 技术- 通过URL scheme,APP中定好方法,就是通过创建iframe方法去调用APP原生方法,或者提供方法给原生APP调用.- window.location.href+'调用接口'<a name="MJOIl"></a>## 21.对Ts的认识TypeScript,一种强类型语言<a name="UCvF6"></a>## 22.对于hooks的认识函数组件工具包<a name="dfx2Q"></a>## 23.Event-Loop- javaScript是一门单线程语言,意味着同一时间只能做一件事,但是这并不意味着单线就是阻塞,而实现单线程非阻塞非的方法就是**事件循环**- 在JavaScript中,所有任务都可以分为1. 同步任务:立即执行的任务,同步任务一般会直接进入到主线程中执行1. 异步任务:异步执行的任务,比如ajax网络请求,setTimeout定时函数等- 从上面我们可以看到,同步任务进入主线程,即主执行栈,异步任务进入任务队列,主线程内的任务执行完毕为空,会去任务对列读取对应的任务,推入主线程执行.上述过程的不断重复就是事件循环- **事件循环**1. 所有同步任务都在主线程上执行,形成一个执行栈(Exexution Context Stack)1. 而异步任务会被放入异步处理模块,当异步任务有了运行结果,就将该函数移入任务队列1. 一旦执行栈中所有的同步任务执行完毕,引擎就会读取任务队列,然后将任务队列中的第一个任务押入执行栈中运行1. 主线程不断重复第三步,也就是 **只要主线程空了,就会去读取任务队列,**该过程不断重复,这就是所谓的**事件循环**<a name="kfiBc"></a>## 24.route和router区别- $router是VueRouter的一个对象,通过Vue.use(VueRouter)和VueRouter构造函数得到一个router的实例对象,这个对象中是一个全局的对象,他包含了所有的路由包含了许多关键的对象和属性- $route是一个跳转的路由对象,每一个路由都会有一个route对象,是一个局部的对象,可以获取对象的name,path,params,query等1. $ router 指向当前的VueRouter实例,也就是new Vue({router:router})这里传入的router实例对象,可以使用上一节里列出的VueRouter实例的属性和方法1. $route 指向当前跳转的路由对象,是一个包含当前的路由信息的对象,<router-view/>组件会通过这个属性来获取需要渲染的组件想象对象继承<a name="OxMQZ"></a>## 25.diff算法diff算法使用来最小量更新虚拟Dom,不管是Vue还是React,比较虚拟DOM节点的变化,都是利用了diff算法,虚拟DOM指的是将真实的Dom转为js对象,从而解决浏览器操作真实Dom的性能问题,diff的用途就是在新老虚拟Dom之间进行比较,将DOM进行更新,diff算法的比较过程通过层级进行比较,由外向内递归进行比较,首先先查看节点类型是否相同,然后去查看属性是否相同,然后就是文本有无变化跨级时间复杂度 O(n^3) 同级复杂度O(n)<br />基于diff算法的同级对比,我们先讲下对比的过程中,它主要分为四种类型的对比,1. 新建 Create;新的VD中有这个节点,旧的没有1. 删除remove:新的VD中没有这个节点,旧的有1. 替换replace:新的VD的tagName和旧的tagName不同1. 更新updata:除了上面三点外的不用,具体是比较attributes先,然后在比较children<a name="ZRiKX"></a>## 26,new的作用- new操作符创建来了一个空对象,将this绑定在这个对象上- 将this绑定在这个对象上,- 这个对象原型指向构造函数的prototype- 执行构造函数后返回这个对象<a name="Lwo5G"></a>## 27.defer和async的区别向HTML页面中插入javascript代码的主要方法就是通过script标签.其中包含两种形式,第一种直接在script标签之间插入js代码.第二种即是通过scr属性引入外部js文件.由于解释器在解析执行js代码期间会阻塞页面其余部分的渲染,对于存在大量js代码的页面来说.会导致浏览器出现长时间的空白和延迟,为了避免这个问题,建议把全部的js引用放在标签之前.- defer和async在网络加载过程是一致的,都是异步执行的.- 两者的区别在与脚本加载之后何时执行,可以看出defer更符合大多数场景对应用脚本加载和执行的要求- 如果存在多个defer属性的脚本,那么它们是按照加载顺序执行脚本的,而对于async,它的加载和执行是紧紧挨着的,无论声明顺序如何,加载完成就立即执行,它对于应用脚本用处不大,因为它完全不考虑依赖- **小结**defer和async的共同点是都可以并行加载js文件,不会阻塞页面的加载,不同点是defer的加载完成之后,js会等待整个页面全部加载完成后在执行,而saync是加载完成之后,会马上执行js,所以对js的执行有严格顺序的话,那么建议用defer加载.<a name="MeVWC"></a>## 28.跨域的实现方式以及jsonp原理1. **解决跨域问题**- vue框架解决跨域问题,反向代理,vue-cli配置proxy,在vue.config.js中配置proxy- cors后端设置请求头- 后端做代理,后端请求接口,把请求过来的数据返回给前端,后端配置nginx代理- 前端jsonp- document.domain+iframe跨域- location.hash+iframe- window.name+iframe跨域- postMessage跨域- 跨域资源共享- Nginx代理跨域- nodejs中间件代理跨域- WebSocket协议跨域1. **jsonp**原理: 函数调用与定义,script本身属于一次性标签,所以需要动态创建script,请求一次就需要创建一次script,通过src动态引入我们的函数调用,通过函数调用的参数,将数据传递过来,当如果说我们前端在使用的时候,我们只需要定义函数,通过函数中的参数就可以将数据获取过来<br />--- 由于浏览器同源策略的限制,非同源的请求,都会产生跨域问题,jsonp即使为了解决这个问题出现的一种简便解决方案,只能用get调用<br />--- jsonp是一种解决同源策略的一种方式,通过get请求,将srcipt脚本发送到服务执行,将服务器响应后并返回数据的一种方式,它只能进行get请求,其他请求无法成功执行,因为同源策略没有对script进行限制2. **同源策略****同一协议,同一域名,同一端口号.当其中一个不满足时,我们的请求就会发生跨域问题**3. **cors请求头(**[https://blog.csdn.net/u014165119/article/details/111529729](https://blog.csdn.net/u014165119/article/details/111529729)**)**- **CORS** 全称 **Cross-Origin Resource Sharing**,即跨域资源共享- CORS 是一种基于 [HTTP Header](https://developer.mozilla.org/en-US/docs/Glossary/Header) 的机制,该机制通过允许服务器标示除了它自己以外的其它域。服务器端配合浏览器实现 CORS 机制,可以突破浏览器对跨域资源访问的限制,实现跨域资源请求。<a name="htUTB"></a>## 29.promise的使用以及其原型方法- **常用的几种方法**1. Promise.resolve() 返回一个给定值解析后的Promise对象1. Promise.reject() 返回一个带有拒绝原因的Promise对象1. Promise.all() 将多个Promise封装成一个新的Promise,成功的是一个结果数组,失败时,返回的是最先rejected状态的值1. Promise.race() 返回一个promise ,一旦迭代器中某个promise解决或拒绝,返回的Promise就会解决或拒绝.1. Promise.prototype.catch() 返回一个Promise,并处理拒绝的情况- **最简单的实现****Promise可以有三种状态**1. pedding Promise 对象实例创建时候的初始状态1. Fulfilled可以理解为成功的状态1. Rejected可以理解为失败的状态- **promise.all()**```javascriptlet p1 =new Promise((resolve,reject)=>{ resolve('成功了') })let p2= new Promise((resolve,reject)=>{ resolve('success') })let p3=Promise.reject('失败')Promise.all([p1,p2]).then((result)=>{console.log(result) //['成功了','success'] }).catch((error)=>{console.log(error)})Promise.all([p1,p3,p2]).then((result)=>{console.log(result)}).catch((error)=>{console.log(error) //失败了,打出'失败'})})
Promise.all在处理多个异步处理时非常有用,比如说一个页面上需要等两个或多个ajax的数据回来以后才正常显示,在此之前只显示loading图标。
30.es6新增(Es6认识)
- Let和const关键字
- let
- let关键是用来声明变量的
- 使用let关键字声明的变量具有块级作用域
- 在一个大括号中,使用let关键字声明的边才具有块级作用域,var关键字是不具备这个特点的,防止循环变量成全变量
- 使用let关键字声明的变量没有变量提升
- const
- 声明常量
- 不可以重新赋值
- 声明必须初始化
- 暂时性死区
- 字符串模板
- 在ES6之前,将字符串连接到一起的方法是 + 或者concat() 方法
- ‘…’展示运算符
- 展开运算符(用三个连续的点(…)表示) 是ES6中的新概念,使你能够将字面量对象展开为多个元素
- 数组结构 ```javascript // 数组解构允许我们按照一一对应的关系从数组中提取值,然后将值赋值给变量 let ary=[1,2,3] console.log(arr[1])
//解构赋值 let [a122,b221,c2]=ary
4. **对象结构**```javascript// 对象结构允许我们使用变量的名字匹配对选哪个的属性,匹配成功,将对象属性的值赋值给变量// 变量名 和 对象中的属性名 一致, 否则undefinedlet poerson={name:'lisi',age;30,sex:'男'};console.log(person.name)// case1// let {name,age,sex}==person;// console.log(name.sge,sex);// case2// let {name:myName}=person;// console.log(myName);//case3let {name,sex}=person
- 箭头函数 ```javascript
- 作用:定义匿名函数
- 基本语法
- 没有参数: ()=>console.log(‘XXX’)
- 一个参数: i=>
- 大于一个参数: (i,j)=>i+j
- 函数体不用大括号:一条语句,并且不书写return
- 函数体如果有多个语句,需要用{}包围,若有return,需要用{}包裹,
- 使用场景: 多用来定义回调函数
- 箭头函数的特点
- 简洁
- 箭头函数没有自己的this,箭头函数的this不是调用的时候决定的,而是在定义的时候处在的对象就是他的this
- 扩展理解 : 箭头函数的this看外层的是否有函数, 如果有,外层函数的this就是内部箭头函数的this
6. **数组常用方式**- Array.from()方法```javascript//使用Array.from()方法 将对象转化为数组:1.下标必须从0开始,下标连续 2.必须带length// var arrayLike = {// "0": "张三",// "1": "李四",// "2": "王五",// "length": 3// }// var ary = Array.from(arrayLike);// console.log(ary)var arrayLike = {"0": "1","1": "2","length": 2}var ary = Array.from(arrayLike, item =>item * 2)
find()方法
var ary = [{id: 1,name: '张三'}, {id: 2,name: '李四'}];//find():类似some(),找到,不再继续循环,跳出循环var res = ary.find(item => item.id == 2)
findIndex()方法
let ary = [10, 20, 50];let index = ary.findIndex(item => item > 15);
some()/find()/findIndex()区别
//都可以循环遍历数组,匹配到对应元素,就跳出循环//some():返回boolean//find(): 返回对应的元素
includes()方法
let ary = ["a", "b", "c"];let result = ary.includes('a')console.log(result)result = ary.includes('e')console.log(result)
- 字符串常用方式
- startsWith()方法,endsWith() ```javascript let str = ‘Hello ECMAScript 2015’; let r1 = str.startsWith(‘Hello’); console.log(r1); let r2 = str.endsWith(‘2016’);
- repeat()方法```javascriptconsole.log("y".repeat(50))
- set对象 ```javascript const s1 = new Set(); // console.log(s1) // console.log(typeof s1)//object // console.log(s1.size)//属性的个数 // const s2 = new Set([“a”, “b”]); // console.log(s2) // console.log(s2.size) //数组去重 // const s3 = new Set([“a”,”a”,”b”,”b”]); // console.log(s3) // const ary = […s3]; // console.log(ary)
const s4 = new Set(); //1 向set结构中添加值 使用add方法 s4.add(‘a’).add(‘b’).add(‘c’); console.log(s4) //2修改 var a4 = […s4] a4[0] = “a1”; console.log(new Set(a4)); // 3从set结构中删除值 用到的方法是delete const r1 = s4.delete(‘e’); console.log(s4) console.log(r1); //4 判断某一个值是否是set数据结构中的成员 使用has const r2 = s4.has(‘d’); console.log(r2) //5 清空set数据结构中的值 使用clear方法 s4.clear(); console.log(typeof s4);
//6 遍历set数据结构 从中取值 const s5 = new Set([‘a’, ‘b’, ‘c’]); s5.forEach(value => { console.log(value)
9. **Symbol()生成唯一标识码**```javascriptconst fnSymbol1 = Symbol("fn");console.log(fnSymbol)console.log(typeof fnSymbol)console.log(fnSymbol === fnSymbol1);
31.iOS和安卓兼容
const category=navigator.userAgent;const idAndroid=category.indexOf('Android')>-1 || category.indexOf('Adr')>1const isIos=!!category.match(/\(i[^;]+;( u;)? cpu.+Mac os x/) ;
32.HTTP和HTTPS
- 基本概念
http: 超文本协议,是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(Tcp),用于从WWW服务器传输超文本到本地浏览器的传输协议,他可以使浏览器更加高效,使网络传输减少
https : 是以安全为目标的HTTP通道,简单讲师HTTP的安全版,即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL
- https协议的主要作用是: 建立一个信息安全通道,来确保数组的传输,确保网站的真实性
http和https区别
http传输的数据;都是未加密的,也就是明文传输,网景公司设置了SSL协议来对http协议传输的数据进行加密处理,简单来说https协议是有http和ssl协议构建的可进行加密传输和身份认证的网络协议,比http协议的安全性更高
主要区别如下
- https协议需要ca证书,费用较高
- http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议
- 使用的链接方式,端口也不同,一般而言,http协议的端口为80,https的端口号为443
- http的链接也很简单,是无状态的;https协议是有SSL+HTTP协议构建的可进行加密传输,身份认证的网络协议,比如HTTP协议安全
- https协议的工作原理
客户端在使用https方式与web服务器通信时,有以下几个步骤
- 首先客户端通过URL访问服务器建立ssl链接
- 服务端收到客户端请求后,会将网站支持的证书信息(证书中包含公钥) 传送一份给客户端
- 客户端的服务器开始协商SSL连接的安全等级,也就是信息加密的等级
- 客户端的浏览器根据双方同意的安全等级,建立会话密钥,然后利用网站的公钥将会话密钥加密,并传送给网站
- 服务器利用自己的私钥解密出会话密钥
- 服务器利用会话密钥加密与客户端之间的通信
- https协议的优点
- 使用https协议可认证用户和服务器,确保数据发送到正确的客户端和服务器
- https协议是由SSL+http协议构建的可进行加密传输,身份认证的网络协议,要比http协议安全,可防止数据在传输过程中不被窃取,改变,确保数据的完整性
- https是现行架构下最安全的解决方案,虽然不是绝对安全,但它大幅度增加了中间人攻击的成本
- https协议的缺点
- https握手阶段比较费时,会使页面加载时间延长50%,增加10%~20%的耗电
- https缓存不如http高效,会增加数据开销
- SSL证书也需要钱,功能越强大,证书费用越贵
- SSL证书需要绑定IP,不能再同一个IP上绑定多个域名,ipv4资源支持不了这种消耗
33.移动端常见的bug有哪些
转文件34.tcp和udp的区别
- TCP是面向连接的,UDP是无法连接的,即发送数据前不需要先建立连接
- TCP提供可靠的服务,也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付.并且因为tcp可靠,面向连接,不会丢数据,因此适合大数据量的交换
- TCP是面向字节流,UDP面向报文,并且网络出现拥塞,不会使得发送速度降低(因此会出现丢包,对实时的应用,比如IP电话和视频会议等)
- TCP只能是1对1 ,UDP支持1对1 ,1对多
- TCP的首部较大20字节,而UDP只要8字节
- TCP是面向连接 的可靠性传输,而UDP是不可靠的
35.设计模式
GOF提出的23 中设计模式分为三大类
- 创建型模式,共5种,分别为 工厂方法模式, 抽象工厂模式, 单例模式 ,建造者模式, 原型模式
- 结构型模式 ,共7种,分别为 适配器模式, 装饰器模式 ,代理模式, 外观式桥接模式, 组合模式,享元模式
- 行为型模式 共11种,分别为 策略模式, 模板方法模式 ,观察者模式 ,选代子模式, 责任链模式, 命令模式 ,备忘录模式 ,状态模式, 访问者模式 ,中介者模式, 解释器模式
- 在前端开发中,有些特定的模式不适用.当然,有些适用于前端的模式并未包含在这23中设计模式中,如 委托模式,节流模式 等.
—— 开发中常用到的模式如下.
- singleton:单例模式,用来减少重复创建对象
- factory:工厂模式,用来解耦
- iterator:迭代器模式,用来遍历对象
- observer:观察者模式,用来收发消息
- templete:末班模式,用来避免执行相同的操作
- strategy: 策略模式,用来定义算法等.
36.长链接和短连接
- 长连接: 长连接指在一个连接上可以连续发送对个数据包,在连接保持期间,如果没有数据包发送,需要双方发链路检测包
- 短连接:短连接是相对于长连接而言的概念,指的是在数据传送过程中,只在需要发送数据时,才去建立一个连接,数据发送完成后,则断开此连接,即每次连接只完成一项业务的发送
37.协商缓存和强缓存的区别
强缓存相关字段有expires,cache-control,如果cache-control与expires同时存在的话
cache-control的优先级高于expires
协商缓存相关字段有Last-Modified/If-Modified-Since,Etag/If-None_Math
浏览器缓存分为强缓存和协商缓存.缓存的作用是提高客户端速度,节省网络流量,降低服务器压力
- 强缓存 : 浏览器请求资源,如果header中的Cache-Control和Expires,没有过期,直接从缓存(本地)读取资源,不需要在向服务器请求资源
协商缓存 : 浏览器请求的资源如果是过期的,那么会向服务器放送请求,header中带有Etag字段.服务器在进行判断,如果Etag匹配.则返回给客户端300系列状态码,客户端继续使用本地缓存,否则客户端会重新获取数据资源
38.vue特性
39.vue3.0特点
40.vue生命周期钩子函数 (vue2,vue3)
生命周期钩子又被叫做生命周期时间,生命周期函数,生命周期钩子就是vue生命周期中出发的各类事件,这些事件被称为生命周期钩子,在vue生命周期中,大部分分为四个阶段,创建,挂在,更新,销毁,这四个阶段各自对应两个生命周期钩子
vue2
- beforeCreate() : 实例在内存中被创建出来,还没有初始化好data和methods属性
- create() : 实例已经在内存中创建,已经初始化好data和method.此时还没有开始编译
- beforeMount():已经万和城那个了模板编译,还没有挂载到页面中
- mount():将编译好的模板挂载到页面指定的容器中显示
- beforeUpdata(): 状态更新之前执行函数,此时data中的状态值是最新的,但是界面上显示的数据还是旧的.因为还没有开始重新渲染DOM节点
- updated(): 此时data中的状态值和界面上显示是数据都是已经完成了更新,界面已经被渲染好了
- beforeDestroy(): 实例被销毁之前
- destroyed(): 实例销毁后调用,vue实例指示的所有东西都会解绑,所有的时间监听器都会被移除,所有的子实例也都被销毁,组件已经被完全销毁,此时组件中的 所有data.methods,以及过滤器,指令等,都已经不可用了
在实际开发项目中这些钩子函数如何使用呢?
- beforeCreate : 可以在函数中初始化加载动画
- created:做一些数据初始化,实现函数自执行
- destoryed:当前组件已被删除,清空相关内容
- mounted 中做网络请求和重新赋值,在destoryed中清空页面数据
还有个比较特殊的钩子函数nextTick(),数据更新后的dom操作,写在还函数里面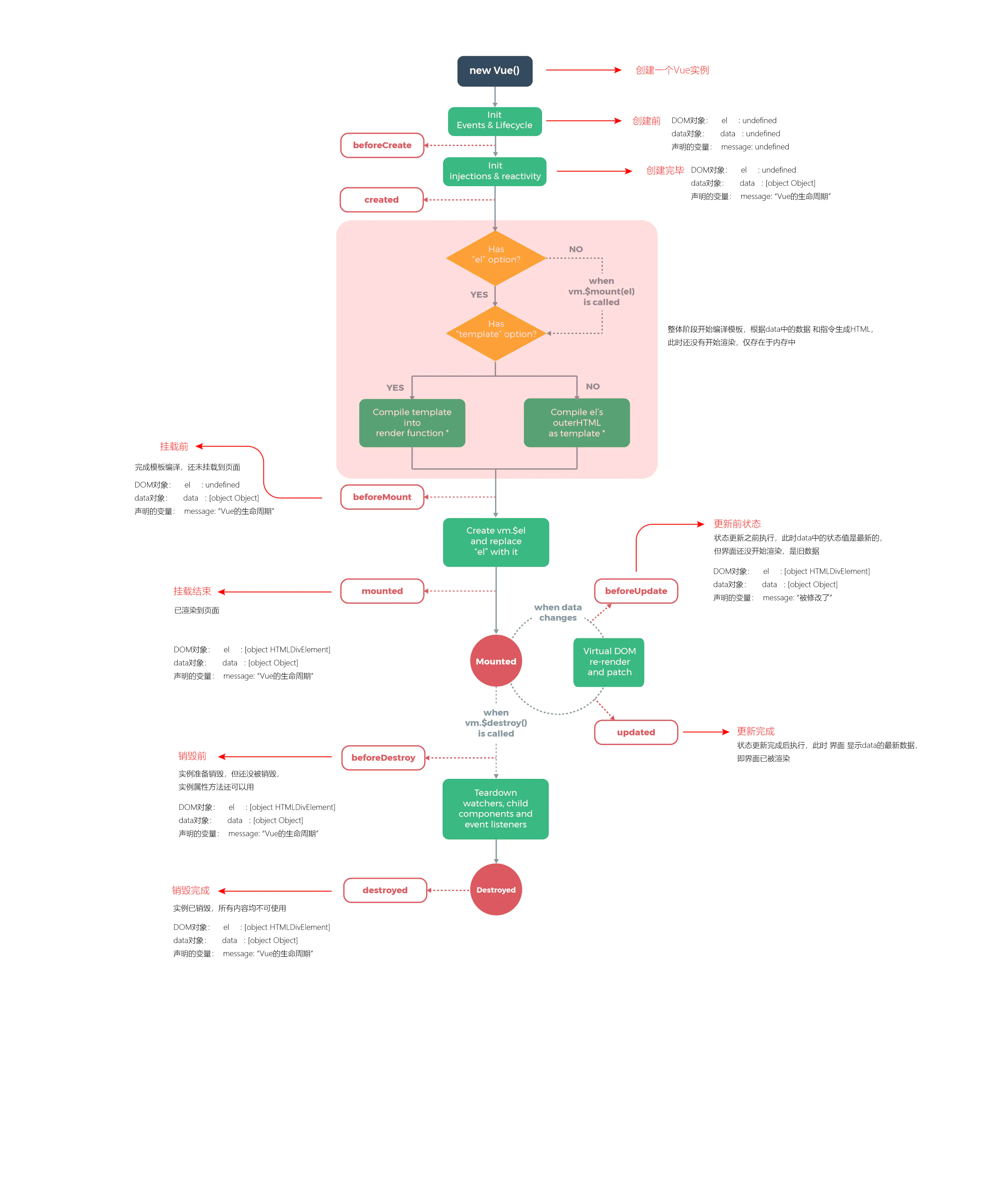
vue3
- setup() : 开始创建组件之前,在beforeCreated之前执行.创建的是data和method
- onBeforeMount() : 组件挂载到节点上之前执行的函数
- onMounted() : 组件挂载完后执行的函数
- onBeforeUpdate() : 组件更新之前执行的函数
- onUpdated() : 组件更新完成之后执行的函数
- onBeforeUnmount() : 组件卸载之前执行的函数
- onUnmounted() : 组件卸载完成后执行的函数
- onActivated() : 被包含在中的组件,会多出两个生命周期钩子函数,被激活时执行
- onDeactivated() : 比如 从A组件切换到B组件,A组件消失时执行
onErrorCaptured() : 当捕获一个来自子孙组件的异常时激活钩子函数
vue2相比vue3的改变
去掉了vue2中的beforeCreate和created两个阶段,同样的新增了一个setup
- beforeMount挂载之前 改名 onBeforeMount
- mounted挂载之后 改名为 onMounted
- beforeUpdate数据更新之前 改名为 onBeforeUpdtated
- updated 数据更新之后 改名为 onUpdated
- beforeDestroy 销毁前 改名 onBeforeUnmount
- destoryed销毁之后 改名 onUnmanned
- errorCapture 报错 改名 onErrorCaptured
41.vue3.0和vue2.0的区别
- 双向数据绑定原理发生了改变 vue2的双向数据绑定是利用es5的一个API Object.definePropert()对数据进行劫持 结合 发布 订阅模式的方式来实现的 vue3中使用了es6的proxyAPI对数据代理 相比于vue2.x,使用proxy的优势如下 1.defineProperty只能监听某个属性,不能对全对象监听
- 可以省去for in/闭包等内容提高效率,(直接绑定整个对象即可) 3.可以监听数组,不用再去单独的对数组做特异操作vue3.x可以检测到数组内部数据的变化
- vue3支持碎片 (Fragments) 支持多个根节点,不比非要写一个标签将全部标签写在一个标签里面Composition API Vue2与Vue3最大的区别 Vue使用选项类型API(options API)对比vue3合成型API(Composition API) 旧的选项型API在代码里分割了不同的属性:data.computed属性,methods,等等.新的合成型API能让我们用方法分割,相比于旧的API使用API使用属性来分组,这样代码会更加简便,整洁
- 建立数据data vue2中数据放在data属性中 vue3需要使用新的setup()方法,此方法在组件初始化构造的时候触发 1.从vue引入reactive 2.使用reactive()方法来声明我们的数据称为响应式 3.使用setup()方法来返回我们的响应式数据,从而我们的template可以获取这些响应性数据
- 生命周期钩子 —Lifecyle Hooks
- setup 开始创建组件前,在beforeCreate和created之前执行,创建的是data和methods;
- onBeforeMount() : 组件挂载到节点上之前执行的函数。
- onMounted() : 组件挂载完成后执行的函数。
- onBeforeUpdate(): 组件更新之前执行的函数。
- onUpdated(): 组件更新完成之后执行的函数。
- onBeforeUnmount(): 组件卸载之前执行的函数。
- onUnmounted(): 组件卸载完成后执行的函数 如果组件被keep-alive包含,则会多出下面两个钩子函数 onActivated():被包含在中的组件,会多出两个生命周期钩子函数,这个是被激活时执行 onDeactivater():切换组件,比如A组件切换到B组件,A组件消失时执行
- 父子传参不同 总结:
- setup函数时,他将接受两个参数:props,context(包含attrs,slots,emit)
- setup函数是处于生命周期函数beforeCreate和Created两个钩子函数之前的函数
- 执行setup时,组件实例尚未被创建(在setup内部,this不会是该活跃实例的引用,即不指向vue实例,vue为了避免我们错误的使用,直接将setup函数中的this修改成了undefined)
- 与模板一起使用,需要返回一个对象,在setup函数中定义的变量和方法最后都是需要return出去的 不然无法在模板中使用
- 使用渲染函数:可以返回一个渲染函数,该函数可以直接使用在同一作用域声明的响应式状态
- vue3的 teleport 瞬移组件 Teleport 可以把modal组件渲染到任意你想渲染的外部Dom上,不必嵌套在#app中,这样就可以互不干扰了,可以把Teleport看成一个传送门,把你的组件传送到任何地方
42.http三次握手,四次分手
三次握手
其实就是建立一个TCP连接是,需要客户端和服务器总共发送3个包,进行三次握手的主要作用就是为了确认双方的接收能力和发送能力是否正常,指定自己的初始化序列号为后面的可靠性传送做准备.实质上其实就是连接服务器指定端口,建立TCP连接,并同步连接双方的序列号和确定号,交换TCP窗口大小信息
- 刚开始客户端啊处于Closed的状态,服务端处于Listen状态
第一次握手:客户端个服务端发送一个SYN报文,并指明客户端的初始化序列号ISN,此时客户端处于SYN_SEND的一个状态
首部的同步为SYn=1,初始序列号seq=x,SYN=1的报文段不能携带数据,但要消耗掉一个序号
第二次握手:服务器收到客户端的SYN报文之后,会以自己的SYN报文作为应答,并且也是指定了自己的初始化序列号ISN,同时会把客户端的ISN+1作为ACK的值,表示自己已经收到了客户端的SYN,此时服务器处于SYN_REVD的状态
在确定报文段中SYN=1,ACK=1,确认号ACK=x+1.初始序号seq=y
第三次握手:客户端收到SYN报文之后,会发送一个ACK报文,当然,也是一样把服务器的ISN+1作为ACK的值,表示已经收到了服务器的SYN报文,此时客户端处于ESTABLISHED状态.服务器收到ACK报文之后,也处于ESTABLISHED状态,此时,双方已建立起了连接
确认报文段ACK=1,确认号ack=y+1.序号seqx+1(初始为seq=x,第二个报文段所以要+1),ACK报文段可以携带数据,不携带数据则不消耗序号
为什么要三次,而不是两次
- 为了确认双方的接收能力和发送能力都正常
- 如果是用两次握手,则会出现先下面的情况
如客户端发出里连接请求,但因连接请求报文丢失而未收到确定,于是客户端在重传一次连接请求,后来收到确认,建立了连接,数据传输完毕后,就释放了连接,客户端共发出了两个连接请求报文段,其中一个丢失,第二个达到服务端,但是第一个丢失的报文段只是在某些网络节点长时间滞留了,延误到连接释放以后才到达到服务端,此时服务端误认为客户端又发出一次新的连接请求,于是就像客户端发出确认报文段,同意建立来捏,不采用三次握手,只要服务端发出确认,就建立新的连接了,此时哭护短忽略服务端发来的确认,也不发送数据,则服务端一致等待客户端发送数据,浪费资源
四次回收原因
服务器在收到客户端断开连接诶Fin报文后,并不会立即关闭连接,而是先发送一个ACK包先告诉客户端收到关闭连接的请求,只有当服务器的所有报文发送完毕之后,才发送FIN报文断开连接,因此需要四次挥手
第一次挥手:客户端会发送一个FIN报文,报文中会指定一个序列号.此时客户端处于FIN_WAIT1状态
即发送链接释放报文段(FIN=1,序列seq=u),并停止在发送数据,主动关闭TCP连接,进入FIN_WAIT1(终止等待1)状态,等待服务端的确认
第二次挥手:服务端的收到FIN之后,会发送ACk报文,且把客户端的序列号值+1作为ACK报文的序列号值,表明已经收到客户端的报文了,此时服务端处于CLOSE_WAIT状态
即服务端收到连接释放报文段后即发出确认报文段(ACK=1,确认号ack=u+1,序号seq=v),服务端进入CLOSE_WAIT(关闭等待)状态,此时的TCP处于半关闭状态,客户端到服务端的连接释放.客户端收到服务端的确定后,进入FIN_WAIT2(终止等待2)状态,等待服务端发出的连接释放报文段.
-
43.原型和原型链
构造函数是使用了new关键字的函数,用来创建对象,所有函数都是Function()的实例
原型对象是用来存放实例对象的公有属性和公有方法的一个公共对象,所有原型对象都是Object()的实例
原型链又叫隐式原型链,是由proto属性串联起来,原型链的尽头是Object.prototype
js获取原型的方法:(1)p.proto (2)p.constructor.prototype (3)object.getPrototypeOf(p)
45.节流和防抖
46.vue模板里面引入计算属性和方法调用
47.webpack,webpack优化
48.canvas绘图
50.微任务与宏任务
51.call(),apply(),bind()三者的区别
- 三者都是用来改变函数this对象是指数。并且都可以传参,第一个参数是this要指向的对象
- 传参的方式不一样,apply是数组,call,bind是参数列表,而且call,apply都是一次性传入参数,bind可以分为多次传入
bind是返回绑定this之后的函数。apply、call则是立即执行
52.vue的双向绑定原理
53.object.defineproperty有什么弊端
54.组件传值
55.v-for中的key值,不推荐使用index
56.diff算法怎么去比较有没有key值
57.webpack中loder和plugins的区别
通俗点讲loader是转换,plugin是执行比转换更复杂的任务,比如合并压缩等
- loader:让webpack能够处理非js文件,人后你就可以利用webpack的打包功能,对他们进行处理
- plugins:从打包优化和压缩,一直到重新定义环境中的变量
- 相对于loader转换指定类型的模块功能,plugins能过被用于执行更广泛的任务,比如打包优化.文件管理,环境注入等,…..
- loader是一个转化器,将A文件进项编译成B文件 eg:将A.less转换成A.css文件,单纯的文件转换过程
- plugin是一个扩展器,他丰富了webpack本身,针对是loader结束后,webpack打包的整个过程,他并不直接操作文件,而是基于事件机制工作,会监听webpack打包过程中的默写节点,执行广泛的任务
55.vue3.0的数据响应
56.除了api,还有其他方法对数组新增元素,添加响应式
57.computed计算属性,它有什么优点
58.vue3的apiwatcheffect和watch有什么区别
59.vue3.0的apiwatcheffect 和 react的effect有什么区别
60.ts泛型,枚举
61.vite的理解
62.闭包的使用
63.css隐藏一个元素会用到什么
64.作用域链
65.js中的继承有那些
66.vue渐进式开发
67.MVVM数据驱动的原理
68.虚拟dom和真实dom的区别
69.app中px转rem
70.vue性能优化
71.三次握手四次连接
72.vue父子组件加载的顺序是怎么样
73.vue单项数据流
74.浏览器常用的兼容问题
滚动条到顶端的距离(滚动高度)
var scrollTop = document.documentElement.scrollTop || document.body.scrollTop;
滚动条到左端的距离
var scrollLeft = document.documentElement.scrollLeft || document.body.scrollLeft;
IE9以下byClassName
function byClassName(obj,className){//判断是否支持byClassNameif(obj.getElementsByClassName){//支持return obj.getElementsByClassName(className);}else{//不支持var eles = obj.getElementsByTagName('*');//获取所有的标签var arr = [];//空数组,准备放置找到的对象//遍历所有的标签for(var i = 0,len = eles.length;i < len;i ++){//找出与我指定class名相同的对象if(eles[i].className === className){ arr.push(eles[i]);//存入数组}}return arr; //返回}}
获取非行内样式兼容 IE:currentStyle 标准:getComputedStyle
function getStyle(obj,attr){return window.getComputedStyle ? getComputedStyle(obj,true)[attr] : obj.currentStyle[attr]; }//div.style.width = '';设置样式 //obj['属性']: 对象是变量时,必须用对象['属性']获取。
获取事件对象的兼容
evt = evt || window.event
获取鼠标编码值的兼容
function getButton(evt){ var e = evt || window.event; if(evt){return e.button;}else if(window.event){switch(e.button){case 1 :return 0;case 4 :return 1;case 2 :return 2;}}}
获取键盘按键编码值的兼容
var key = evt.keyCode || evt.charCode || evt.which;
阻止事件冒泡的兼容
e.stopPropagation ? e.stopPropagation() : e.cancelBubble = true;
阻止超链接的默认行为的兼容
evt.preventDefault ? evt.preventDefault() : evt.returnValue = false;
添加事件监听器的兼容
function addEventListener(obj,event,fn,boo){if(obj.addEventListener){obj.addEventListener(event,fn,boo);}else if(obj.attachEvent){obj.attachEvent('on' + event,fn);}}
移除事件监听器的兼容
function removeEventListener(obj,event,fn,boo){if(obj.removeEventListener){obj.removeEventListener(event,fn,boo);}else if(obj.detachEvent){obj.detachEvent('on' + event,fn);}}
- 获取事件源的兼容
var target = event.target || event.srcElement;
75.vue的动态路由怎样配置
我们经常需要把某种模式匹配到的所有路由,全都映射到同个组件。例如,我们有一个展示商品的组件,对于所有 上架状态 各不相同的商品,都要使用这个组件来渲染。那么,我们可以在 vue-router 的路由路径中使用“动态路径参数”(dynamic segment) 来达到这个效果:
// 简单配置一个动态路由const routes = [{path: "/",component: () => import("@/views/Main.vue"),redirect: "/index",children: [{path: "/index/:id",component: () => import("@/views/Index.vue"),},],},];
超级重点:一个“路径参数”使用冒号 : 标记。当匹配到一个路由时,参数值会被设置到 this.$route.params,可以在每个组件内使用
//HTML部分<div><button @click="goPage(1)">查看上架</button><button @click="goPage(2)">查看下架</button><ul><li v-for="(item,index) in showList" :key='index'>{{item.title}} </li></ul></div>//js部分export default {name: "",data() {return {state: 1, //默认显示上架list: [{ title: "眼影", state: 1 }, //1为上架,2为下架{ title: "口红", state: 2 },{ title: "防晒霜", state: 1 },],};},computed: {showList() {return this.list.filter((item) => {return item.state == this.state;});},},methods: {goPage(val) {this.state = val;this.$router.push({path: "/index2/" + val,});},},};
76.协商缓存的last-modified与eate有什么区别
- 究竟要不要使用浏览器的本地缓存,服务器和浏览器之间有一个沟通的机制,叫做缓存协商,一种是Last-modified,一种就是Etag。
- Last-Modified
浏览器发出一个请求,对于一般的静态内容,服务器端都会通过文件进行stat()系统调用,获取该文件的最后修改时间,然后放入了HTTP的响应头的信息。下一次浏览器再次发送请求的时候,就会在HTTP请求头上面加上一个 (If-Modified-SinceFri, 25 Mar 2011 07:55:33 GMT )这样的标记,服务器再次接受到这个请求的时候,就会将文件的Last-modified时间和HTTP请求的时间的进行对于,如果木有发生变化,返回状态为304 Not Modified的响应。
- ETag
另一种协商方法,就是使用Etag,与Last-Modified非常相近,它不是用文件的修改时间进行对比的,而是根据文件的内容进行生成一个标志串,一般都是使用文件的内容的md5值。比如,apache为一个静态的文件响应头上面加入了Etag的标志。下一次浏览器进行请求的时候,HTTP请求就会附加一个If-None-Match的标记,来询问文件是否被修改过,这时候服务器重新计算这个文件的Etag的值,如果相同的话,则直接允许浏览器使用本地缓存。不同的话,则直接返回最新的内容给浏览器。
- 两种的对比
有些特定的场合下,一些静态的文件,可能会被频繁的更新, 但是文件内容没有变化,这时候如果使用Last-modified,服务器端始终返回最新的内容给浏览器,而Etag是根据文件内容来的,如果内容没有变化的话,始终会让浏览器使用本地缓存的文件。所以,使用ETag可以更好的避免一些不必要的服务器相应。
[
](https://blog.csdn.net/liupengjava/article/details/83884584)
77.cookie怎么防止xxs跟csrf攻击
- CSRF
- 使用双重 Cookie 验证的办法,服务器在用户访问网站页面时,向请求域名注入一个Cookie,内容为随机字符串,然后当用户再次向服务器发送请求的时候,从 cookie 中取出这个字符串,添加到 URL 参数中,然后服务器通过对 cookie 中的数据和参数中的数据进行比较,来进行验证。使用这种方式是利用了攻击者只能利用 cookie,但是不能访问获取 cookie 的特点。并且这种方法比 CSRF Token 的方法更加方便,并且不涉及到分布式访问的问题。这种方法的缺点是如果网站存在 XSS 漏洞的,那么这种方式会失效。同时这种方式不能做到子域名的隔离。
- 使用在设置 cookie 属性的时候设置 Samesite ,限制 cookie 不能作为被第三方使用,从而可以避免被攻击者利用。Samesite 一共有两种模式,一种是严格模式,在严格模式下 cookie 在任何情况下都不可能作为第三方 Cookie 使用,在宽松模式下,cookie 可以被请求是 GET 请求,且会发生页面跳转的请求所使用
- XSS:
- 还可以对一些敏感信息进行保护,比如 cookie 使用 http-only ,使得脚本无法获取。也可以使用验证码,避免脚本伪装成用户执行一些操作
- CSRF攻击是攻击者利用用户的身份操作用户帐户的一种攻击方式,通常使用Anti CSRF Token来防御CSRF攻击,同时要注意Token的保密性和随机性。并且CSRF攻击问题一般是由服务端解决。
- XXS(跨站脚本攻击)是指攻击者在返回的HTML中嵌入javascript脚本,为了减轻这些攻击,需要在HTTP头部配上,set-cookie:
httponly-这个属性可以防止XSS,它会禁止javascript?/p脚本来访问cookie。
secure - 这个属性告诉浏览器仅在请求为https的时候发送cookie///。
78.ts怎么运行 (不用编译成js)
- ts-node 可以直接执行 ts 代码,不需要手动编译,为了深入理解它,我们实现了一个简易 ts-node,支持了直接执行和 repl 模式。
- 直接执行的原理是通过 require hook,也就是 Module._extensions[ext] 里通过 ts compiler api 对代码做转换,之后再执行,这样的效果就是可以直接执行 ts 代码。
- repl 的原理是基于 Node.js 的 repl 模块做的扩展,可以定制提示符、上下文、eval 逻辑等,我们在 eval 里用 ts compiler api 做了编译,然后通过 vm.runInContext 在 repl 的 context 中执行编译后的 js。这样的效果就是可以在 repl 里直接执行 ts 代码。
(当然,完整的 ts-node 还有很多细节,但是大概的原理我们已经懂了,而且还学到了 require hook、repl 和 vm 模块、 ts compiler api 等知识。)
https://zhuanlan.zhihu.com/p/440090468
79.数组去重reduce怎么实现
let arr = [1,2,3,4,3,45,6,5,33,2,2,2,2,33,2,1]let obj = {}let arr1 = arr.reduce((pre,cur)=>{if(obj[cur]){return pre}else{obj[cur]=truepre.push(cur)return pre}},[])console.log(arr1)// [1,2,3,4,45,6,5,33]
80. react hooks中useState()怎么拿到最新的值 (除了useEffict())
- 新的react hook写法,官方默认setState方法移除了回调函数,但我们有时候的业务场景需要我们同步拿到变量的最新变化值,以便做下一步操作,这时我们可以封装一个hook通过结合useref通过回调函数来拿到最新状态值。 ```javascript import {useEffect,useState,useRef} from “react”
function Text(state){ const cbRef=useRef() const [data,setData]=useState(state)
useEffect(()=>{ cdRef.current && cbRef.current(data) },[data]);
return [data,function (val,callback){ cbRef.current = callback setData(val) }]; }
export {Text}
- ** 使用的时候像平常一样,回调函数可以传可以不传**```javascriptconst [data,setData]=Text({});setData({},function(data){console.log('我是回调方法',data)})
81.promise中all与race这两个方法的区别
- Promise.all
- 有一个失败的请求,其他都失败;若需弥补这个缺陷,在Promise中增加Catch错误捕捉,retur出来
- 返回结果的顺序按照参数的顺序进行
- Promise.race
- 快速读取: 内存缓存会将编译解析后的文件,直接存入该进程的内存中,占据该进程一定的内存资源,以方便下次使用时的快速读取
- 时效性:缓存时效性很短,会随着进程的释放而释放
硬盘缓存
1. 硬盘缓存则是直接将缓存写入硬盘文件中,读取缓存需要对该缓存存放的硬盘文件进行I/O操作,然后重新解析该缓存内容,读取复杂,速度比内存缓存慢.
匹配优先级
浏览器读取命中强缓存资源的顺序为memory cache->disk cache
- 先去内存看,如果没有直接加载
- 如果内存没有,则取硬盘获取,如果有直接加载
- 如果硬盘也没有,那么就进行网络强求
- 加载到的资源缓存到硬盘和内存 | 比较 | 读取速度 | 时效性 | 容量 | 匹配优先级 | | —- | —- | —- | —- | —- | | 内存缓存 | 快速 | 进程关闭,内存清空 | 小 | 先 | | 硬盘缓存 | 速度比内存缓存慢,需要重新解析文件,进行I/O操作 | 时效长 | 大 | 后 |
83 indexedDB和 LocalStorage的区别
前言
两者都是在客户端存储数据,可以存储较多数据,且都是永久性保存。
不同点
- indexedDB是JS脚本语言可以操作的数据库
- 操作是异步的
- IndexedDB 支持事务(transaction),这意味着一系列操作步骤之中,只要有一步失败,整个事务就都取消,数据库回滚到事务发生之前的状态,不存在只改写一部分数据的情况。
- 储存空间大 IndexedDB 的储存空间比 LocalStorage 大得多,一般来说不少于 250MB,甚至没有上限。
- LocalStorage 不支持搜索。
相同点
- 可以在客户端存储永久性数据
- 都通过键值对存储数据
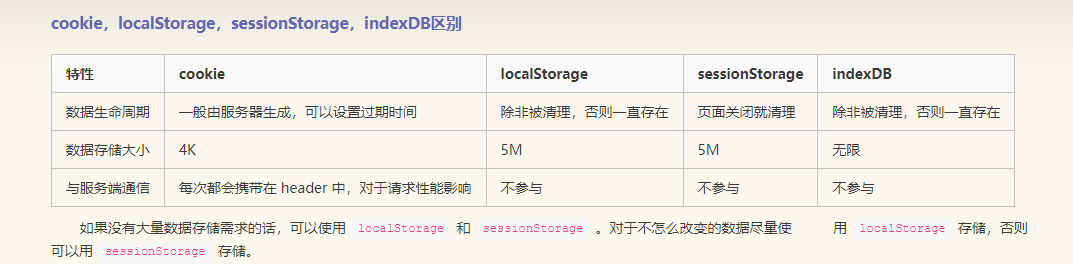
coolie,localStorage,sessionStorage,indexDB区别
| 特性 | cookie | loaclStorage | sessionStorage | indexDB |
|---|---|---|---|---|
| 属于生命周期 | 一般有服务器生成,可以设置过期时间 | 除非被清理,否则一直存在 | 页面关闭就清理 | 除非被清理,否则一直存在 |
| 数据存储大小 | 4K | 5M | 5M | 无限 |
| 与服务端通信 | 每次都会携带在header中,对于请求性能影响 | 不参与 | 不参与 | 不参与 |
84.树形转平铺,平铺转树形
- 正向-树形结构转平铺
```javascript
// 正向-树形结构转平铺
// 从外到内依次递归,有 children 则继续递归
function treeToArr(data, pid=null, res=[]) {
data.forEach(item => {
res.push({ pid: pid, id: item.id, name: item.name });
if(item.children && item.children.length !== 0) {
} }); return res; };treeToArr(item.children, item.id, res);
const arr = treeToArr(data); console.log(arr);
- 逆向-平铺结构转树形```javascript// 依次在数组中找到每一层级对应的元素,同时每个元素的 children 属性对应的 value 通过 pid 去找到,然后递归执行下去function arrToTree(arr, pid=null) {const res = [];arr.forEach(item => {if(item.pid === pid) {// 这样每次都需要遍历整个数组,因此时间复杂度为 n*n// const children = arrToTree(arr, item.id)// 往下递归时,每次数组的大小都在减小,每次都筛选掉父代元素,最终的时间复杂度为 n*lognconst children = arrToTree(arr.filter(v => v.pid !== pid), item.id);if(children.length) {res.push({ ...item, children })}else {res.push({ ...item })}}});return res;};const tree = arrToTree(arr);console.log(JSON.stringify(tree, null, 2));
85.websocket使用
86.平时用户上传的图片,或者我们自己的静态图,使用什么压缩工具压缩的
86.webpack性能优化
一、构建速度优化
1.1 缩小文件的搜索范围
resolve字段告诉webpack怎么去搜索文件,所以首先要重视resolve字段的配置:
设置resolve.modules:[path.resolve(__dirname, ‘node_modules’)]避免层层查找。resolve.modules告诉webpack去哪些目录下寻找第三方模块,默认值为[‘node_modules’],会依次查找./node_modules、../node_modules、../../node_modules。
设置resolve.mainFields:[‘main’],设置尽量少的值可以减少入口文件的搜索步骤第三方模块为了适应不同的使用环境,会定义多个入口文件,mainFields定义使用第三方模块的哪个入口文件,由于大多数第三方模块都使用main字段描述入口文件的位置,所以可以设置单独一个main值,减少搜索
对庞大的第三方模块设置resolve.alias, 使webpack直接使用库的min文件,避免库内解析
合理配置resolve.extensions,减少文件查找默认值:extensions:[‘.js’, ‘.json’],当导入语句没带文件后缀时,Webpack会根据extensions定义的后缀列表进行文件查找,所以:
列表值尽量少
频率高的文件类型的后缀写在前面
源码中的导入语句尽可能的写上文件后缀,如require(./data)要写成require(./data.json)
5.配置loader时,通过test、exclude、include缩小搜索范围
1.2 使用DllPlugin减少基础模块编译次数
1.DllPlugin动态链接库插件,其原理是把网页依赖的基础模块抽离出来打包到dll文件中,当需要导入的模块存在于某个dll中时,这个模块不再被打包,而是去dll中获取。为什么会提升构建速度呢?原因在于dll中大多包含的是常用的第三方模块,如react、react-dom,所以只要这些模块版本不升级,就只需被编译一次。我认为这样做和配置resolve.alias和module.noParse的效果有异曲同工的效果。
1.3 使用HappyPack开启多进程Loader转换
在整个构建流程中,最耗时的就是Loader对文件的转换操作了,而运行在Node.js之上的Webpack是单线程模型的,也就是只能一个一个文件进行处理,不能并行处理。HappyPack可以将任务分解给多个子进程,最后将结果发给主进程。JS是单线程模型,只能通过这种多进程的方式提高性能。
除了id和loaders,HappyPack还支持这三个参数:threads、verbose、threadpool,threadpool代表共享进程池,即多个HappyPack实例都用同个进程池中的子进程处理任务,以防资源占用过多。
1.4 使用ParallelUglifyPlugin开启多进程压缩JS文件
使用UglifyJS插件压缩JS代码时,需要先将代码解析成Object表示的AST(抽象语法树),再去应用各种规则去分析和处理AST,所以这个过程计算量大耗时较多。ParallelUglifyPlugin可以开启多个子进程,每个子进程使用UglifyJS压缩代码,可以并行执行,能显著缩短压缩时间。
二、开发体验优化
2.1 使用自动刷新
2.1.1 Webpack监听文件
Webpack可以使用两种方式开启监听:1. 启动webpack时加上—watch参数;2. 在配置文件中设置watch:true。此外还有如下配置参数。合理设置watchOptions可以优化监听体验。
三、优化输出质量-压缩文件体积
3.1 区分环境—减小生产环境代码体积
代码运行环境分为开发环境和生产环境,代码需要根据不同环境做不同的操作,许多第三方库中也有大量的根据开发环境判断的if else代码,构建也需要根据不同环境输出不同的代码,所以需要一套机制可以在源码中区分环境,区分环境之后可以使输出的生产环境的代码体积减小。Webpack中使用DefinePlugin插件来定义配置文件适用的环境。
3.2 压缩代码-JS、ES、CSS
压缩JS:Webpack内置UglifyJS插件、ParallelUglifyPlugin会分析JS代码语法树,理解代码的含义,从而做到去掉无效代码、去掉日志输入代码、缩短变量名等优化
3.3 使用Tree Shaking剔除JS死代码
Tree Shaking可以剔除用不上的死代码,它依赖ES6的import、export的模块化语法,最先在Rollup中出现,Webpack 2.0将其引入。适合用于Lodash、utils.js等工具类较分散的文件。它正常工作的前提是代码必须采用ES6的模块化语法,因为ES6模块化语法是静态的(在导入、导出语句中的路径必须是静态字符串,且不能放入其他代码块中)。如果采用了ES5中的模块化,例如module.export = {…}、require( x+y )、if (x) { require( ‘./util’ ) },则Webpack无法分析出可以剔除哪些代码。
四、优化输出质量—加速网络请求
4.1 使用CDN加速静态资源加载
CND加速的原理CDN通过将资源部署到世界各地,使得用户可以就近访问资源,加快访问速度。要接入CDN,需要把网页的静态资源上传到CDN服务上,在访问这些资源时,使用CDN服务提供的URL。由于CDN会为资源开启长时间的缓存,例如用户从CDN上获取了index.html,即使之后替换了CDN上的index.html,用户那边仍会在使用之前的版本直到缓存时间过期。业界做法:另外,HTTP1.x版本的协议下,浏览器会对于向同一域名并行发起的请求数限制在4~8个。那么把所有静态资源放在同一域名下的CDN服务上就会遇到这种限制,所以可以把他们分散放在不同的CDN服务上,例如JS文件放在js.cdn.com下,将CSS文件放在css.cdn.com下等。这样又会带来一个新的问题:增加了域名解析时间,这个可以通过dns-prefetch来解决 来缩减域名解析的时间。形如//xx.com 这样的URL省略了协议,这样做的好处是,浏览器在访问资源时会自动根据当前URL采用的模式来决定使用HTTP还是HTTPS协议。
HTML文件:放在自己的服务器上且关闭缓存,不接入CDN
静态的JS、CSS、图片等资源:开启CDN和缓存,同时文件名带上由内容计算出的Hash值,这样只要内容变化hash就会变化,文件名就会变化,就会被重新下载而不论缓存时间多长。
4.2 多页面应用提取页面间公共代码,以利用缓存
原理大型网站通常由多个页面组成,每个页面都是一个独立的单页应用,多个页面间肯定会依赖同样的样式文件、技术栈等。如果不把这些公共文件提取出来,那么每个单页打包出来的chunk中都会包含公共代码,相当于要传输n份重复代码。如果把公共文件提取出一个文件,那么当用户访问了一个网页,加载了这个公共文件,再访问其他依赖公共文件的网页时,就直接使用文件在浏览器的缓存,这样公共文件就只用被传输一次。
4.3 分割代码以按需加载
原理单页应用的一个问题在于使用一个页面承载复杂的功能,要加载的文件体积很大,不进行优化的话会导致首屏加载时间过长,影响用户体验。做按需加载可以解决这个问题。具体方法如下:
将网站功能按照相关程度划分成几类
每一类合并成一个Chunk,按需加载对应的Chunk
例如,只把首屏相关的功能放入执行入口所在的Chunk,这样首次加载少量的代码,其他代码要用到的时候再去加载。最好提前预估用户接下来的操作,提前加载对应代码,让用户感知不到网络加载
五、优化输出质量—提升代码运行时的效率
5.1 使用Prepack提前求值
原理:Prepack是一个部分求值器,编译代码时提前将计算结果放到编译后的代码中,而不是在代码运行时才去求值。通过在便一阶段预先执行源码来得到执行结果,再直接将运行结果输出以提升性能。但是现在Prepack还不够成熟,用于线上环境还为时过早。
5.2 使用Scope Hoisting
原理:译作“作用域提升”,是在Webpack3中推出的功能,它分析模块间的依赖关系,尽可能将被打散的模块合并到一个函数中,但不能造成代码冗余,所以只有被引用一次的模块才能被合并。由于需要分析模块间的依赖关系,所以源码必须是采用了ES6模块化的,否则Webpack会降级处理不采用Scope Hoisting。
87.不同苹果手机兼容问题
:hover在ios上无效(包含但不限于:active :focus)等
//解决方案一:js绑定事件document.body.addEventListener('touchstart',function(){});//解决方案一:body添加ontouchstart<body ontouchstart>
苹果手机下拉上拉滚动卡顿等问题
//解决方案:在body的样式上加入以下样式body {-webkit-overflow-scrolling: touch; //但是这个样式有时候会影响z-index失效overflow-scrolling: touch;}
多个position:fixed导致层级关系失效 ```javascript // 第一种情况 // 因为我是body中加了iOS的弹性滑动属性导致出现的层级z-index失效,故我的解决方案是注释该样式后问题解决
//第二种情况 transform导致的z-index失效
//其它的暂时未知道
4. click等事件在ios上无效问题```javascript// 方法一:将 click 事件直接绑定到目标元素(即 .target)上// 方法二:将目标元素换成 <a> 或者 button 等可点击的元素//方法三:(推荐)将 click 事件委托到非 document 或 body 的父级元素上// 方法四:(推荐)给目标元素加一条样式规则 cursor: pointer// 方法五:使用touch事件替换click事件,iOS 系统下默认的 click 事件会有300毫秒的延迟,可以使用 fastclick 来消除这个延迟。
88.5年与3年的区别
- 心态更加成熟,无论是人际交往还是业务的分歧都没有之前的针锋相对,
- 解决bug上更加老练熟练,,会少问一点,,沉稳,多一些方式方法
- 对公司的套路更加熟悉
- 能更好的处理人际关系
- 改变不了别人,就改变自己
89.代码评审
- feat :新功能
- fix:修复问题
- docs:修改文档
- style: 修改样式,不影响实现功能
- refactor:重构代码,理论上不
- perf:提升性能
- test:添加修改测试用例
- chore 修改工具相关
- deps:升级依赖
- scope 修改文件的范围 (包括但不限于doc,middleware,proxy,core,config)
- subject (用一句话清除的描述这次提交做了什么 )
- body (补充subject,适当增加原因,目的等相关因素,也可以不写)
- footer
- 当有非兼容修改时可在这里描述清除
- 关联相关issue,如Closes #1,closes#2,#3
- 如果功能点有新增或修改的,还需要关联chair-handbook和chair-init的MR,如chair/doc!123
100.从业务上讲讲你遇到的逻辑难题
主要从业的业务,尤其是产品经理应该,比如:跳转记录位置,七天免登陆,提邮箱登录,上拉加载,记录页面跳转位置,虚拟购物车,首屏加载速度比较快,多说一点关于用户体验的功能,(夸它).101.vue.nextTick()与setTimeout的区别
两者都代表主线程完成后立即执行,其执行结果是不确定的,可能是setTimeout回调函数执行结果在前,也可能是setImmediate回调函数执行结果在前,但setTimeout回调函数执行结果在前的概率更大些,这是因为他们采用的观察者不同,setTimeout采用的是类似IO观察者,setImmediate采用的是check观察者,而process.nextTick()采用的是idle观察者。
三种观察者的优先级顺序是:idle观察者>>io观察者>check观察者
结论:
process.nextTick(),效率最高,消费资源小,但会阻塞CPU的后续调用;
setTimeout(),精确度不高,可能有延迟执行的情况发生,且因为动用了红黑树,所以消耗资源大;
setImmediate(),消耗的资源小,也不会造成阻塞,但效率也是最低的。
- nextTick与setTimeout都是异步函数 不同的是nextTick比setTimeout优先执行
原因:
macro-task(宏任务):包括整体代码script,setTimeout,setInterval
micro-task(微任务):Promise,process.nextTick
1. process.nextTick:process.nextTick(callback)类似node.js版的”setTimeout”,在事件循环的下一次循环中调用 callback 回调函数。
2. javascript是单线程
3. setTimeout:因为要入微任务队列,即使是0最快也要4ms,要等待出队。
102.vue插槽
103.defineProperty与proxy的区别
- 用法 ```javascript const myProxy=new Proxy(target,handle) // traget:使用proxy包装的目标对象 // handle:用来指定拦截行为
Object.defineProperty(obj,prop,descriptor) // obj: 必需,目标对象 // prop :必需,需定义或修改的属性的名字 //descriptor : 必需,目标属性所拥有的的特性 (writable:可重写,enumerable:可枚举)
```
- 区别
- definedProperty 是劫持对象的属性,不能监听属性的添加和删除,新增元素需要再次 definedProperty
- Proxy 劫持的是整个对象,不需要做特殊处理
- 使用 defineProperty 时,我们修改原来的 obj 对象就可以触发拦截,而使用 Proxy,就必须修改代理对象,即 Proxy 的实例才可以触发拦截
- 使用 defineProperty 需要遍历对象的每一个属性,对于性能会有一定的影响
- Proxy 可以对数组基于下标的修改的检测,长度修改的监测,而且对 Map、Set、WeakMap 和 WeakSet 的支持
104父子组件执行过程(vue)
- 加载渲染
父beforeCreate->父created->父beforeMount->子beforeCreate->子created-> 子beforeMount->子mounted->父mounted
- 更新过程
父beforeUpdate->子beforeUpdate->子updated->父updated
- 销毁过程
父beforeDestroy->子beforeDestroy->子destroyed->父destroyed
105params和query的区别
query在name和path两种传递方式下都是有效的。 params只有name传参是有效的query传参在浏览器地址中显示参数,params不在浏览器中显示参数query传参强制刷新后参数还在。 params强制刷新后参数丢失query是拼接在url后面的参数, 没有也没关系。 params是路由的一部分,必须要有
106项目中的组件是怎么拆分的
- 是重用组件逻辑的高级方法,是一种源于React的组件模式。HOC是自定义组件,在它之内包含另一个组件,它们可以接受子组件提供的任何动态,但不会修改或复制其输入组件中的任何行为,你可以任务HOC是“纯(Pure)”组件
- 你能用HOC做什么?
HOC可以用于很多任务,例如:
代码重用,逻辑和引导抽象
渲染劫持
状态抽象和控制
Props控制
- 什么是纯组件?
纯(Pure)组件是可以编写的最简单、最快的组件。他们可以替换任何只有render()的组件,这些组件增强了代码的简单性和应用的性能
108.setState为什么是异步的
- setState值在合成事件和钩子函数中是”异步”的, 在原生事件和setTimeout中都是同步的
- setState的”异步”并不是说内容由异步代码实现,其实本身执行的过程和代码都是同步的,只是合成事件和钩子函数的调用顺序在更新之前,导致在合成事件和钩子函数中没法立马拿到更新后的值,形成了所谓的”异步”,当然可以通过第二个参数,setState(partialState,callback)中的callback拿到更新后的结果.
- setState的批量更新优化也是建立在”异步”(合成事件,钩子函数)之上的,在原生时间和setTimeout中不会批量更新,在”异步”中如果对同一个值进行多次setState,setState的批量更新策略会对其进行覆盖,去最后一次的执行,如果同时setState对个不同的值,在更新是会对其进行合并批量更新

若有收获,就点个赞吧
0 人点赞
