K8s是什么?
Kubernetes是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。
为什么需要K8s?
例如,如果一个容器发生故障,则需要启动另一个容器。如果系统如理此问题,会不会更容易? 这就是kubernetes来解决这些问题的方法!
kubernetes为你提供:
自动装箱 建构于容器之上,基于资源依赖及其他约束自动完成容器部署且不影响其可用性,并通过调度机制混合 关键性应用和非关键型应用的工作负载于同一节点以提升资源利用率
自我修复(自愈) 支持容器故障后自动重启、节点故障后重新调度容器,以及其他可用节点、健康状态检查失败后关闭容 器并重新创建等自我修复机制。
水平扩展 支持通过命令或UI手动水平扩展,以及基于cpu等资源负载率的自动水平扩展机制。
服务发现和负载均衡 Kubernets通过其附加组件KubeDNS(或CoreDNS)为系统内置了服务发现功能,它会为每个service 配置DNS名称,并允许集群内的客户端直接使用此名称发出请求,而Service则通过iptables或ipvs内建了负载均衡机制。
自动发布和回滚 Kubernets支持灰度更新应用程序或其配置信息,它会监控更新过程中应用程序的健康状态,以确保它 不会在同一时刻杀掉所有实例,而此过程中一旦有故障发生,就会立即自动执行回滚操作
密钥和配置管理 kubernetsd的configmap实现了配置数据与Docker镜像解耦,需要时,仅对配置做出变更而无须重新构 建docker镜像,这为应用开发部署带来了很大的灵活性。此外,对于应用所依赖的一些敏感数据,如用 户名和密码、令牌、密钥等信息,Kubernetes专门提供了secret对象为其解耦,既便利了应用的快速开 发和交付,又提供一定程度上的安全保障。
存储编排 Kubernets支持pod对象按需自动挂载不同类型的存储系统,这包括节点本地存储、公有云服务商的云 存储,以及网络存储系统(例如,NFS/ISCSI/GlusterFS/Ceph/Cinder/Flocker等)。
K8s组件:
Mater:集群中的一台服务器用作Master,负责管理整个集群。Master是集群的网关和中枢,负责诸如 为用户和客户端暴露API、跟踪其他服务器的健康状态、以最优方式调度工作负载,以及编排其他组件之 间的通信任务,它是用户或客户端与集群之间的核心联络点,并负载Kubernetes系统的大多数集中式管 控逻辑。单个master节点即可完成其所有的功能,但出于冗余及负载均衡等目的,生产环境中通常需要 协同部署多个此类主机。
Node:Node是Kubernetes集群的工作节点,负责接收来自master的工作指令相应地创建或销毁Pod 对象,以及调整网络规则以合理地路由和转发流量等。理论上讲,Node可以是任何形式的计算设备,不 过Master会统一将其抽象为Node对象进行管理。
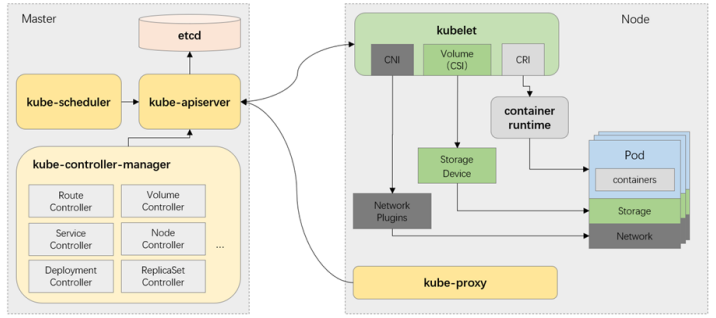
控制平面组件:
kube-apiserverr:Api server负责输出restful风格的kubernetes API,它是发往集群的所有REST操作命令的接入点,并负责接收、校验并响应所有的REST请求,结果状态被持久存储于etcd中。因此,api-server是整个集群的网关。
etcd kubernetes集群的所有状态信息都需要持久存储于存储系统etcd中,不过,etcd是由CoreOS基于Raft 协议开发的分布式键值存储,可用于服务发现、共享配置以及一致性保障(如数据库主节点选择、分布 式锁等)。因此,etcd是独立的服务组件,并不隶属于Kubernetes集群自身 etcd不仅能够提供键值数据存储,而且还为其提供了监听机制,用于监听和推送变更。Kubernetes集群 系统中,etcd中的键值发生变化时会通知到api server。
kube-controller-manager kubernetes中,集群级别的大多数功能都是由几个被称为控制器的进程执行实现的,这几个进程被集成 于kube-controller-manager守护进程中。由控制器完成的功能主要包括生命周期功能和api业务逻辑。
kube-scheduler Kubernetes是用于部署和管理大规模容器应用的平台,根据集群规模的不同,其托管运行的容器很可能 会数以千计甚至更多。api server确认pod对象的创建请求之后,便需要由scheduler根据集群内各节点 的可用资源状态,以及要运行的容器的资源需求做出调度决策。
Node组件:
kubelet:kubelet是运行于工作节点上的守护进程,它从api server接收关于pod对象的配置信息并确保他们处于 期望的状态,kubelet会在api server上注册当前的工作节点,定期向master汇报节点资源使用情况。
kube-proxy:每个工作节点都需要运行一个kube-proxy守护进程,它能够按需为service资源对象生成iptables或者 ipvs规则,从而捕获当前service的流量并将其转发至正确的后端pod对象。
容器运行时环境:每个node都要提供一个容器运行时环境,它负责下载镜像并运行容器。kubernetes支持多个容器运行 时环境。
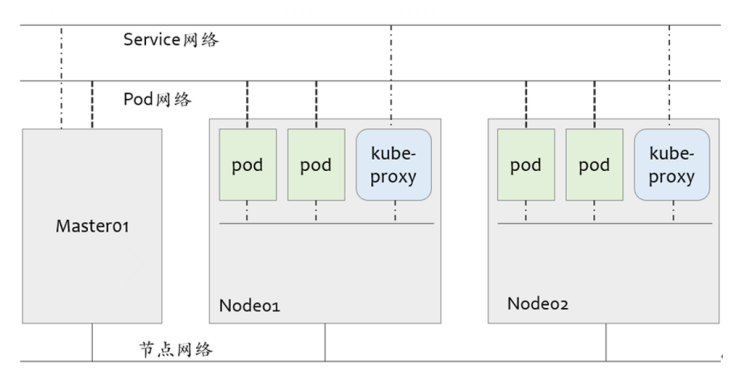
K8s网络模型:
一个是各主机自身所属的网络,其地址配置于主机的网络接口,用于各主机之间的通信,例如master与 各node之间的通信。此地址配置于kubernetes集群构建之前,它并不能由kubernetes管理,管理员需 要于集群构建之前自行确定其地址配置及管理方式。
第二个是kubernetes集群上专用于pod资源对象的网络,它是一个虚拟网络,用于为各pod对象设定ip 地址等网络参数,其地址配置于pod中容器的网络接口之上。pod网络需要借助kubenet插件或CNI插件 实现,该插件可独立部署于kubernetes集群之外,亦可托管于kubernetes之上,它需要在构建 kubernetes集群时由管理员进行定义,而后在创建Pod对象时由其自动完成各网络参数的动态配置。
第三个是专用于service资源对象的网络,它也是一个虚拟网络,用于为kubernetes集群之中的service 配置ip地址,但此地址不配置于任何主机或容器的网络接口上,而是通过Node之上的kube-proxy配置 为iptables或ipvs规则,从而将发往此地址的所有流量调度至其后端的各pod对象之上。service网络在 kubernetes集群创建时予以指定,而service的地址则在用户创建service时予以动态配置
K8s中所有资源的一级属性:
- apiVersion版本,由kubernetes内部定义,版本号必须可以用 kubectl api-versions 查询到
- kind类型,由kubernetes内部定义,版本号必须可以用 kubectl api-resources查询到
- metadata元数据,主要是资源标识和说明,常用的有name、namespace、labels等
- spec描述,这是配置中最重要的一部分,里面是对各种资源配置的详细描述
- status状态信息,里面的内容不需要定义,由kubernetes自动生成
spec的常见子属性:
- containers <[]Object> 容器列表,用于定义容器的详细信息
- nodeName根据nodeName的值将pod调度到指定的Node节点上
- nodeSelector根据NodeSelector中定义的信息选择将该Pod调度到包含这些label的 Node上 hostNetwork是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络 volumes
- volumes存储卷,用于定义Pod上面挂在的存储信息
- restartPolicy 重启策略,表示Pod在遇到故障的时候的处理策略
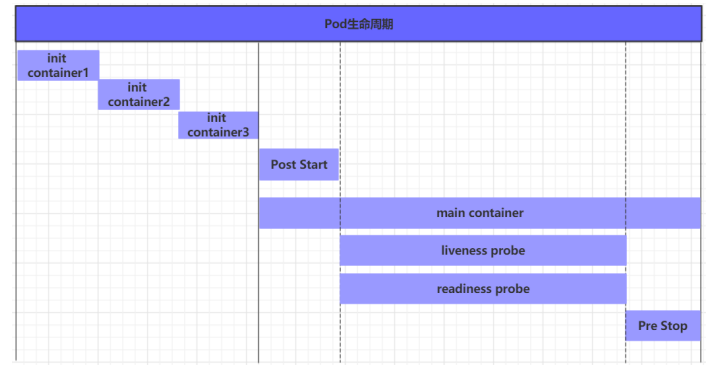
Pod对象的生命周期:
我们一般将pod对象从创建至终的这段时间范围称为pod的生命周期,
它主要包含下面的过程:
- pod创建过程
- 运行初始化容器(init container)过程
运行主容器(main container)
容器启动后钩子(post start)、容器终止前钩子(pre stop) 容器的存活性探测(liveness probe)、就绪性探测(readiness probe)
pod终止过程
Pod的相位:
在整个生命周期中,Pod会出现5种状态(相位),分别如下:
挂起(Pending):apiserver已经创建了pod资源对象,但它尚未被调度完成或者仍处于下载镜像 的过程中
运行中(Running):pod已经被调度至某节点,并且所有容器都已经被kubelet创建完成
成功(Succeeded):pod中的所有容器都已经成功终止并且不会被重启
失败(Failed):所有容器都已经终止,但至少有一个容器终止失败,即容器返回非0值的退出状态
未知(Unknown):apiserver无法正常获取到pod对象的状态信息,通常由网络通信失败所导致
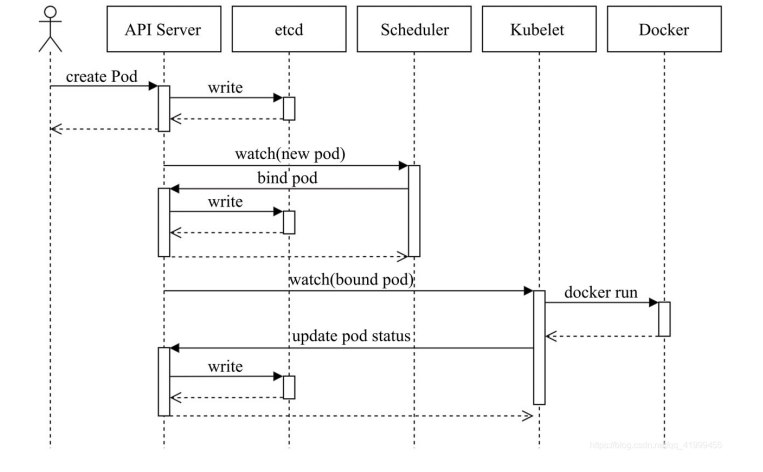
Pod的创建过程:
- 用户通过kubectl或其他api客户端提交pod spec给api server
- api server尝试着将pod对象的相关信息存入etcd中,待写入操作执行完成,api server即会返回确认信息至客户端
- api server开始反应etcd中的状态变化
- 所有的kubernetes组件均使用watch机制来跟踪检查api server上的相关的变动
- kube-scheduler(调度器)通过其watcher觉察到api server创建了新的pod对象但尚未绑定至任
何工作节点 - kube-scheduler为pod对象挑选一个工作节点并将结果信息更新至api server
- 调度结果信息由api server更新至etcd存储系统中,而却api server也开始反映此pod对象的调度结果
- pod被调度到的目标工作节点上的kubelet尝试在当前节点上调用docker启动容器,并将容器的结果状态回送至api server
- api server将pod状态信息存入etcd中
- 在etcd确认写入操作成功完成之后,api server将确认信息发送至相关的kubelet事件将通过它被接收
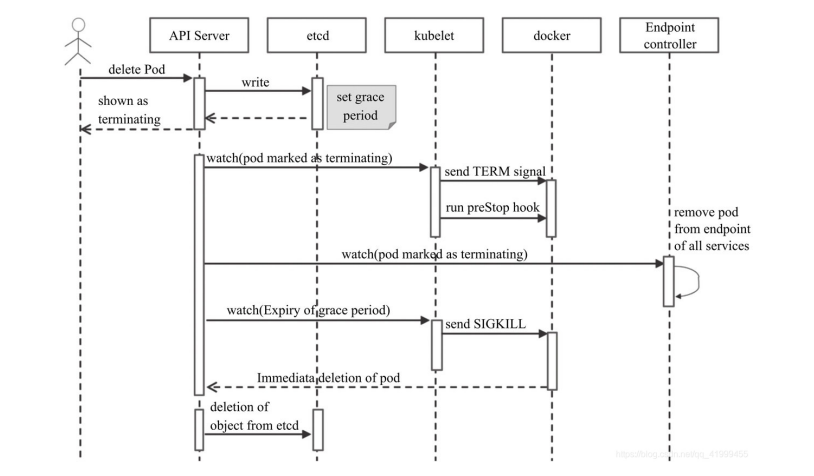
Pod的终止过程:
- 用户发送删除pod对象的命令
- api服务器中的pod对象会随着事件的推移而更新,在宽限期内(默认为30秒),pod被视为“dead”
- 将pod标记为terminating状态
- (与第三步同时运行)kubelet在监控到pod对象转为“Terminating”状态的同时启动Pod关闭过程
- (与第三步同时运行)端点控制器监控到pod对象的关闭行为时将其从所有匹配到此端点的service资源的端点列表中移除
- 如果当前Pod对象定义了preStop钩子处理器,则在其标记为“terminating”后即会以同步的方式启动执行;如若宽限期结束后,preStop仍未执行结束,则第2步会被重新执行并额外获取一个时长为2秒的小宽限期。
- Pod对象中的容器进程收到TERM信号。
- 宽限期结束后,若存在任何一个仍在运行的进程,那么Pod对象即会收到SIGKILL信号
- Kubelet请求API Server将此Pod资源的宽限期设置为0从而完成删除操作,它变得对用户不再可见
pod存活性探测 有不少应用程序长时间持续运行后会逐渐转为不可用状态,并且能够通过重启操作恢复,kubernetes的 容器存活性探测机制可发现诸如此类的问题,并依据探测结果结合重启策略出发后续的行为。存活性探 测是隶属于容器级别的配置,kubelet可基于它判定何时需要重启一个容器
容器探测用于检测容器中的应用实例是否正常工作,是保障业务可用性的一种传统机制。如果经过探 测,实例的状态不符合预期,那么kubernetes就会把该问题实例” 摘除 “,不承担业务流量。 kubernetes提供了两种探针来实现容器探测,分别是:
liveness probes:存活性探针,用于检测应用实例当前是否处于正常运行状态,如果不是,k8s会 重启容器
readiness probes:就绪性探针,用于检测应用实例当前是否可以接收请求,如果不能,k8s不会 转发流量

若有收获,就点个赞吧
0 人点赞
