- 是什么?
- 架构是由那些部分组成
- 有什么特点?
- 特点的原理是什么?
- 如何才能把它用好?
Prometheus是什么:
它是系统监控和告警工具包。
Prometheus的优势:
- 由指标名称和键值对标签标识的时间序列数据组成的多维数据模型
- 强大的查询语言PromQL
- 支持多种类型的图表和仪表盘
- 时间序列数据是服务端通过HTTP协议主动拉取获得的
- 也可以通过中间网关推送来获得时间序列数据
- 不依赖于分布式存储,单个节点具有自治能力
- 可以通过配置静态文件或者服务发现来获取监控目标
prometheus组件架构: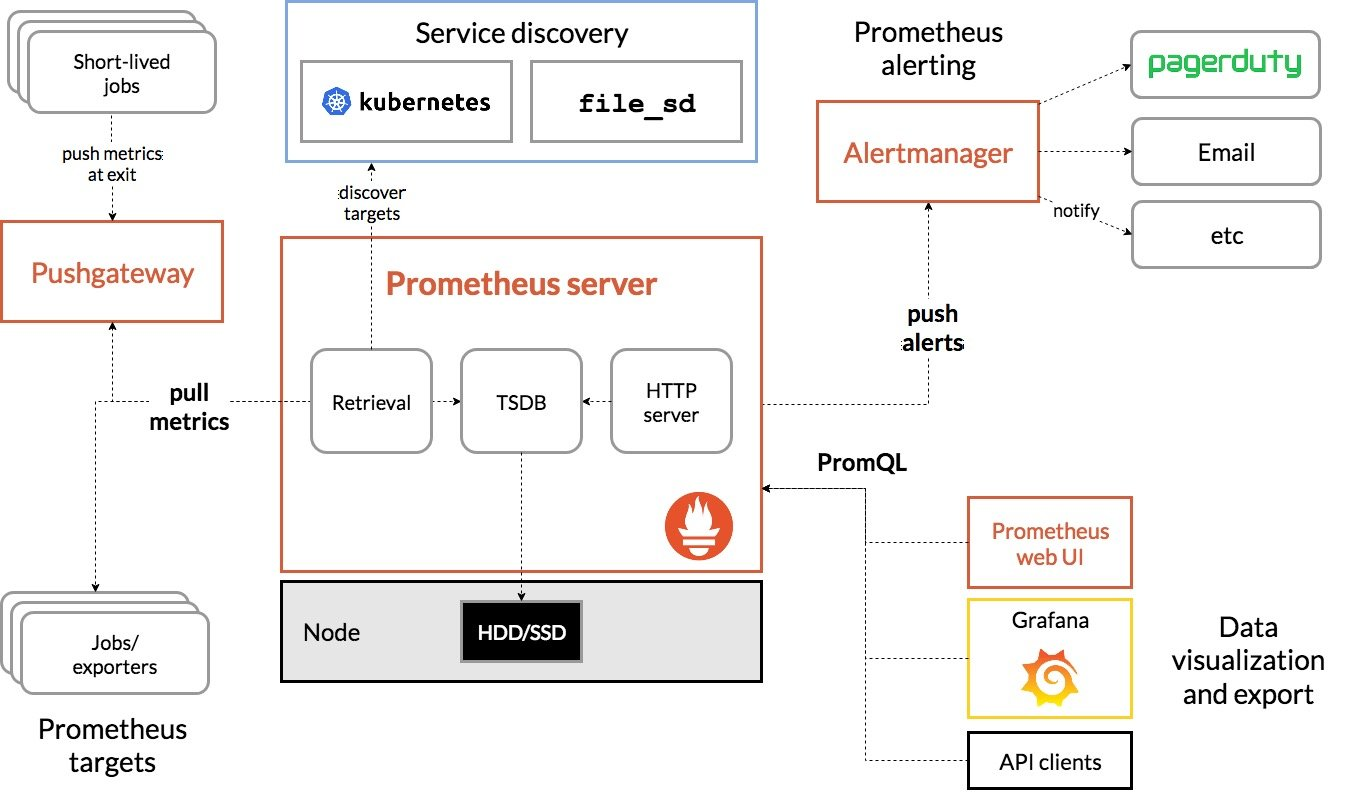
- Prometheus server:是架构中的核心组件,它直接从监控目标中或者是通过中间件拉取监控指标,它在本地存储所有抓取到的样本数据(也支持远程存储),并对此数据进行一系列的规则,以汇总和记录现有数据的新时间序列或生成告警,可以通过grafana或者其他工具来实现数据监控。它无第三方依赖关系,可以独立部署到物理主机上,云上,docker容器内。主要用于收集目标数据,并存储为时间序列数据,对外提供自定义的PromQL语言,可以对数据进行查询分析和告警规则配置管理。可以对监控目标进行静态规则匹配或者是动态配置管理。
- pushgateway:是指用于短期临时的job或批量任务工作的汇聚节点,主要用于短期的job,此类job存在的时间比较短,可能在Prometheus来拉去数据之前就已经消失了,所以针对这类job设计成可以直接向pushgateway推送metric,这样Prometheus便可以定时去pushgateway拉取metric
- exporter:用于输出被监控信息的HTTP接口统称为Exporter(导出器),目前互联网公司常用的组件大部分都有Exporter供直接使用,比如nginx,mysql,Linux系统信息
- service discovery:动态发现待监控的target,从而完成监控配置的重要组件,在容器中很重要
- altermaneger:主要处理Prometheus服务器端发送的alter信息,对其去重数据,分组并路由到正确的接受方式,发出告警,支持丰富的告警方式
- grafana:实时展示监控数据的可视化。
- client library:是用于检测应用程序代码的客户端库,在启动监控服务之前,需要向应用程序软件插入监测,从而实现prometheus的metric数据类型。
Prometheus适用于什么场景:
它适用于记录文本格式的时间序列,它既适用于以机器为中心的监控,也适用于高度动态的面向服务的监控,在微服务的世界中,它对多维数据收集和查询的支持有特殊优势,它是专门为提高系统可靠性而设计的,它可以在断电期间快速诊断问题,每个Prometheus都是相互独立的,不依赖于网络存储或者其他远程服务。当基础架构出现问题时,可以通过Prometheus快速定位故障点,而且不会消耗大量的基础架构资源。
Prometheus不适合于什么场景:
Prometheus非常重视可靠性,即使在出现故障的情况下,你也可以随时统计有关系统的可用信息。如果你需要百分之百的准确度,它可能就不太适合,它收集的数据可能不够详细完整精确,
相关概念:
数据模型:所有采集的监控数据均以指标的形式保存在内置的时间序列数据库中,属于同一指标名称,同一标签集合的,有时间戳标记的数据流。除了存储时间序列,Prometheus还可以根据查询请求,产生一些临时的,衍生的时间序列作为返回结果
指标名称和标签:每一条时间序列都由指标名称和标签唯一标识,其中的指标名称可以表示被监控样本的含义,(例如,http_request_total可以看出来表示当前系统接受到的http请求总量),指标名称只能由ascii字符,数字下划线和冒号组成,同时必须匹配正则表达式,通过标签Prometheus开启了强大的多维数据模型,对于相同的指标,通过不同的标签列表的集合,会形成特定的度量维度实例,(例如,所有包含度量名称为/api/tracks的http请求,打上method=post的标签,就会形成http的具体请求。查询语言在此基础上进行过滤和聚合,改变任何度量指标上的标签值都会创建新的时间序列)
样本:在时间序列中的每一个点称为样本,样本由以下三部分组成,指标:指标名字和描述当前样本特征的标签。时间戳:一个精确到时间毫秒的时间戳。样本值,一个浮点型数据表示当前样本的值。

指标类型:
Prometheus的客户端提供了四种核心的指标类型,但这些类型只是在客户端库(客户端可以根据不同的数据类型调用不同的api接口)和在线协议,实际上Prometheus-server并不对这些指标类型进行区分,而是简单地把这些指标统一为无类型的时间序列。
- counter计数器:代表一种样本值单调递增的指标,即只增不减。除非监控发生重置,例如,你可以使用counter类型的指标表示服务请求总数,已经完成的任务数,错误发生的次数等。counter类型的数据可以让用户方便的了解事件发生的速率变化,在PromQL内置的相关操作函数可以提供相应的分析。

- Gauge仪表盘:Gauge类型代表一种样本数据可以任意变化的指标。即可增可减,Gauge通常用于像温度或者内存使用率这种指标。

Histogram直方图:在大多数情况下人们都倾向于使用某些量化指标的平均值,例如cpu的平均使用率,页面的平均响应时间,这种方式存在的问题很明显,以系统api调用的平均时间为例,如果大多数api请求都维持在100ms的响应时间范围内,而个别请求的响应时间需要5s,那么就会导致某些web界面的响应落到中位数的情况,而这种现象被称为长尾问题。为了区分是平均的慢,还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组,例如统计延迟在0-10ms之间的请求数有多少而10-20ms之间的请求数又有多少,通过这种方式可以分析系统慢的原因,histogram和summary都是为了能够解决这样问题的存在,通过histogram和summary类型的监控指标我们可以快速了解监控样本的分布情况,histogram在一段时间范围内对数据进行采样,(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶中,后续可以通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。histogram类型的样本会提供三种指标。样本的值分布在bucket中的数量,命名为basename_bucket{le=”<上边界>”。解释得更通俗易懂一点,这个值表示指标值小于等于上边界的所有样本数量。

所有样本值的大小总和,命名为_sum 
样本总数命名为_count 
summary摘要:summary即概率图,类似于histogtam,常用于跟踪与时间相关的数据。典型的应用包括请求持续时间,响应大小等。summary同样提供样本的count和sum功能,还提供quantiles功能,可以按照百分比划分跟踪结果,例如quantile取值0.95,表示取样本里的95%数据。
job和instance:任何被采集的目标,即每一个暴露监控样本数据的http服务都称为一各个实例instance,通常对应于单个进程,而具有相同采集目的的实例集合称为作业job。
Prometheus安装:
Exporter:
在prometheus的核心组件中,Exporter是最重要的组成部分,在实际中监控样本数据的收集都是由exporter完成的,Prometheus服务器只需要定时从这些exporter提供的http服务获取数据即可,官方提供了多种常用的exporter,比如对于数据库监视的mysqld_exporter和redis_exporter
exporter本质上是将收集的数据转化为对应的文本记录格式,并提供http接口,供Prometheus定期采集数据。
Exporter类型:
- 直接采集型:这类Exporter直接内置了响应的应用程序,用于向Prometheus直接提供target数据支持,这样设计的好处是,可以更好地监控各自系统内部的运行状态,同时也适合更多自定义监控指标的项目实施
- 间接采集型:原始目标并不直接支持Prometheus,需要我们使用Prometheus提供的客户端库编写该监控目标的监控采集数据,用户可以将该程序独立运行,去获取指定的各类监控数据值,例如lilux操作系统自身并不能直接支持Prometheus,用户无法从操作系统层面上直接提供对Prometheus的支持,因此单独提供Node-Exporter,还有数据库或网站HTTP应用类等Exporter。
文本数据格式:
所有返回监控样本数据的Exporter程序,均需要遵守Prometheus规范,即基于文本的数据格式,其特点是具有更好的跨平台和可读性。
服务发现:Prometheus服务发现能够自动化检测分类,并且能够识别新目标和变更目标,也就是说,可以自动发现并监控目标或变更目标,动态进行数据采集和处理。
PromQL
prometheus提供了一种功能强大的表达式语言PromQL(Prometheus query lauguage)。prometheus允许用户实时选择和汇聚时间序列数据,是Prometheus自己开发的数据查询语言,使用这个查询语言能够进行各种聚合,分析和计算,使管理员能够根据指标更好地了解系统性能。
时序数据库:首先Prometheus是一款时序数据库,它结合生态系统内的其他组件例如pushgateway,alertmanager等可构成一个完整的it监控系统。
时序数据库写入特点:写入平稳,持续,高并发高吞吐,写多读少,在写操作上数据能达到95%无更新时,写入最近生成的数据。时序数据库查询特点:按时间范围读取一段时间的数据,对最近生成的数据读取概率高,对历史数据查询概率低,按照数据点的不同密集度实现多精度查询。数据存储特点:数据存储量比较大,具有时效性,数据通常会有一个保存周期
对时序数据库的基本要求如下:能够支持高并发,高吞吐写入,交互式的聚合查询,能够达到低延迟查询,依据场景设计可以支持海量数据存储。在线应用服务场景中,需要高可用架构支持,针对写入和存储量的要求,应用环境底层需要分布式架构支持。
案例 一:监控一台linux主机
- Server端:第一步在官网找到对应的版本,下载二进制文件,将二进制文件解压到文件夹中
- 为了简化操作,将解压好的文件创建了一个软连接。
- 被监控主机通过二进制安装node_exporter,并运行,查看暴露的端口
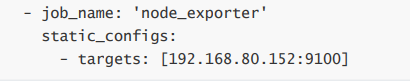
- 在server端中添加内容到Prometheus的yml配置文件中
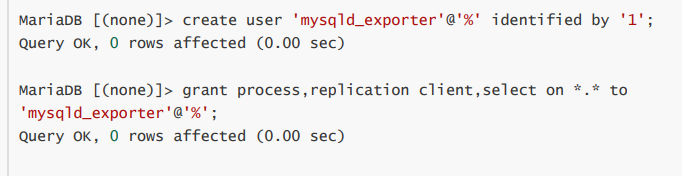
- 并且在mysqld_exporter目录中创建一个配置文件并允许mysqld_exporter
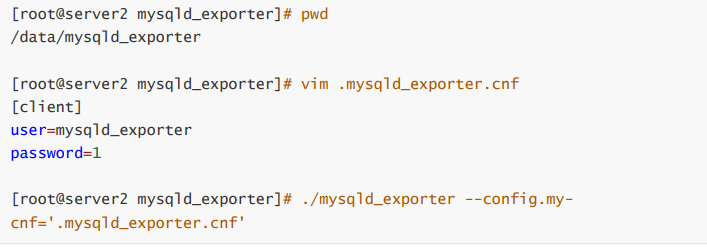
- 在server的配置文件中添加主机

访问prometheus的web界面的url是:ip:9090
案例三:基于文件自动发现
上面的两个案例中都是手动将主机添加到Prometheus的配置文件中,并且每一次配置完成都要重启
- 我们在设置yml配置文件的时候,可以监控一个目录下面的yml文件,具体做法是,在Prometheus的目录下创建一个名为targets的目录,目录下创建一个.yml格式的文件,Prometheus可以自动监测文件中的主机。
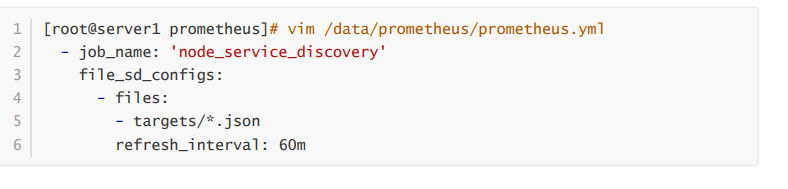
- 这个文件是在server端的主机上
文件内容是监控的ip:端口号

若有收获,就点个赞吧
0 人点赞
