CPU概念
中央处理器 (英语:Central Processing Unit,缩写:CPU)是计算机的主要设备之一,功能主要是解释计算机指令以及处理计算机软件中的数据。更多解释见 维基百科 。
CPU架构
CPU架构如下图所示,纯硬件角度和操作系统角度看到的有所不同。
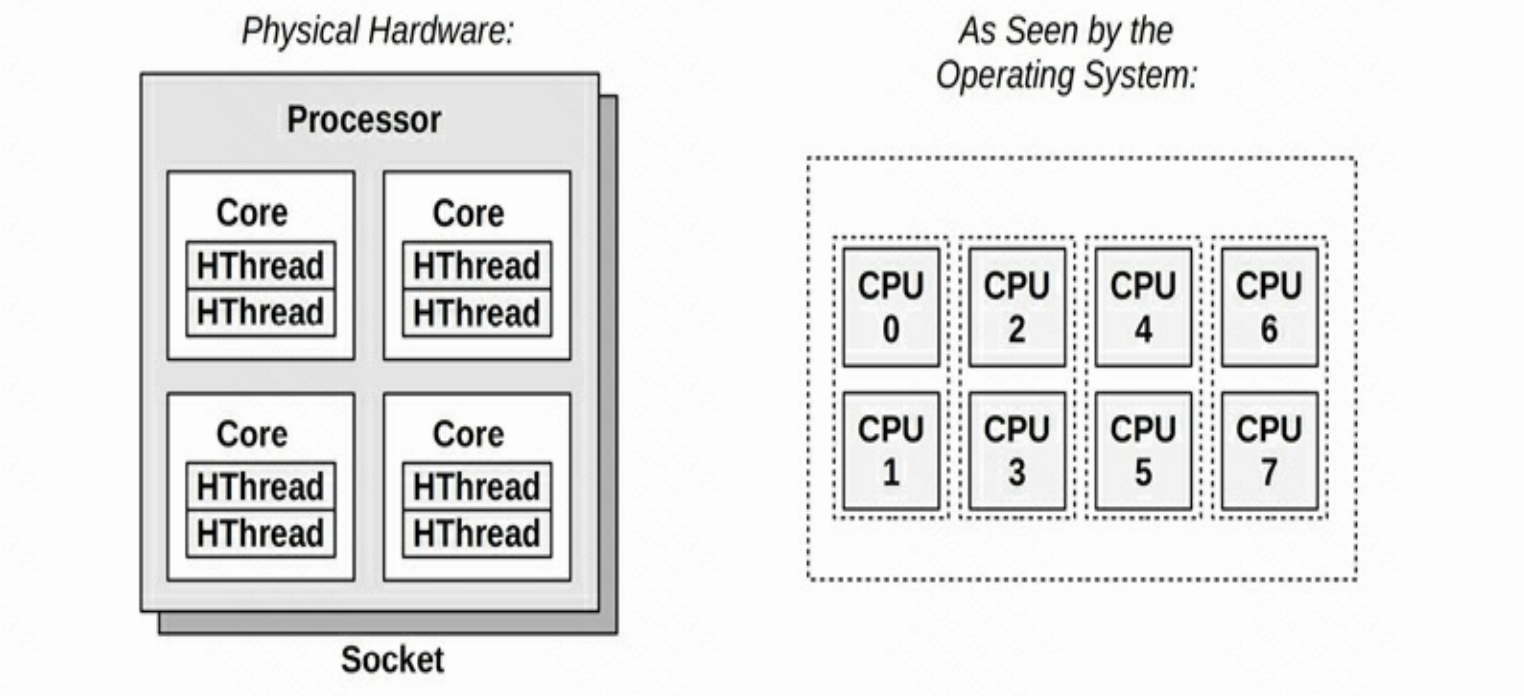
如上图所示,在硬件视角中一个处理器可以一般一颗或者多颗CPU,一颗CPU有一个或多个核(core),每个核根据是否开启超线程技术,可以有一个或者多个线程(HThread)。在Linux操作系统中我们通过top等命令看到的核数为线程数量(HThread)。
或者通过查看内核参数判断,如下图所示:
每个核由控制单元(Control Unit)、功能单元和存储单元组成,其中功能单元包含:算术逻辑单元(ALU)、浮点运算器(FPU)、内存管理单元(MMU) 、加载-存储单元转译后备缓冲器(TLB)等组成。存储单元由:寄存器(Registers)、L1缓存、L2缓存和L3存储组成。
主要包含:
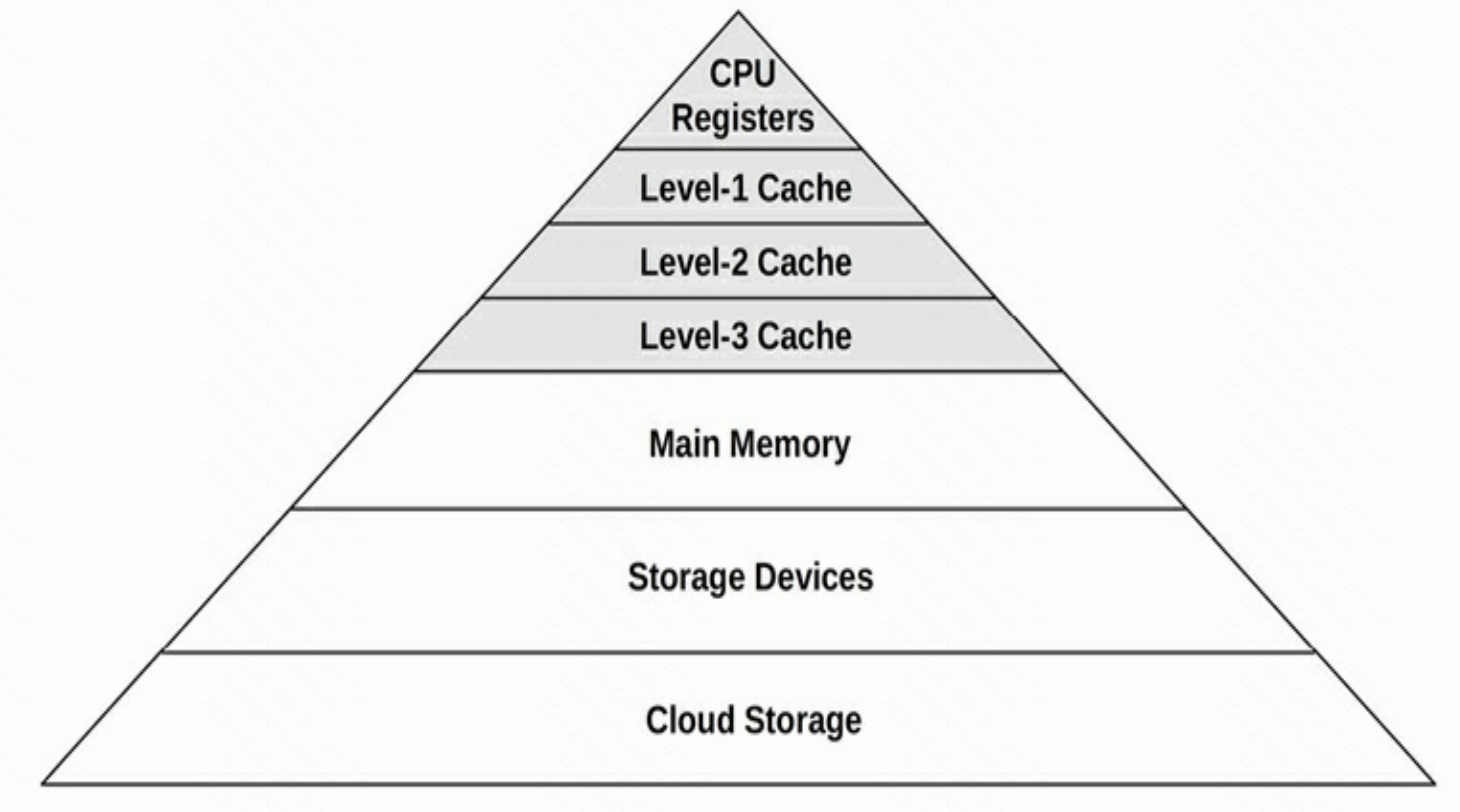
存储金字塔
如下图所示,金字塔顶端靠近CPU,速度更快,价格更高,越靠近金字塔底部,速度越慢,也越便宜。
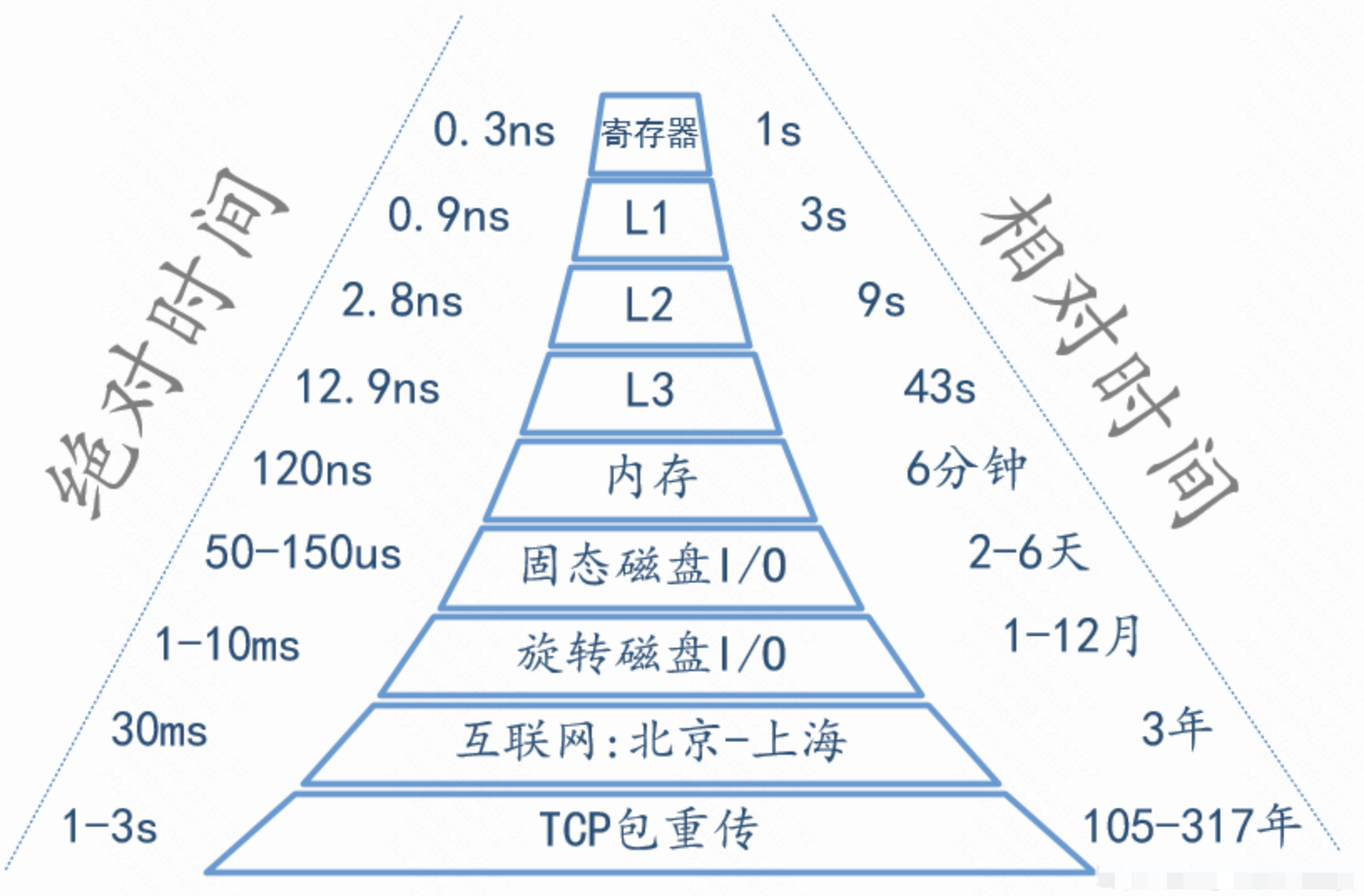
不同存储访问时延与相对CPU处理速度之间的关系如下图所示。
概念解释
时钟频率
时钟频率(又译:时脉速度,英语:clock rate)是指同步电路中时钟的基础频率,它以“每秒时钟周期”(clock cycles per second)来度量,量度单位采用SI单位赫兹(Hz),更多解释见 维基百科 。CPU指令的执行时间花销使用时钟来统计,比如1条指令执行花费1个或多个时钟。CPU的时钟频率一般第固定的,比如3.4GHz,但是现代操作系统可以控制使用频率,以此来节约能源或者获得更好的性能。一般线上服务器为取得更好的性能都是使用高性能模式而非节能模式。可以通过cpupower命令查看当前CPU的时钟频率,如下图所示: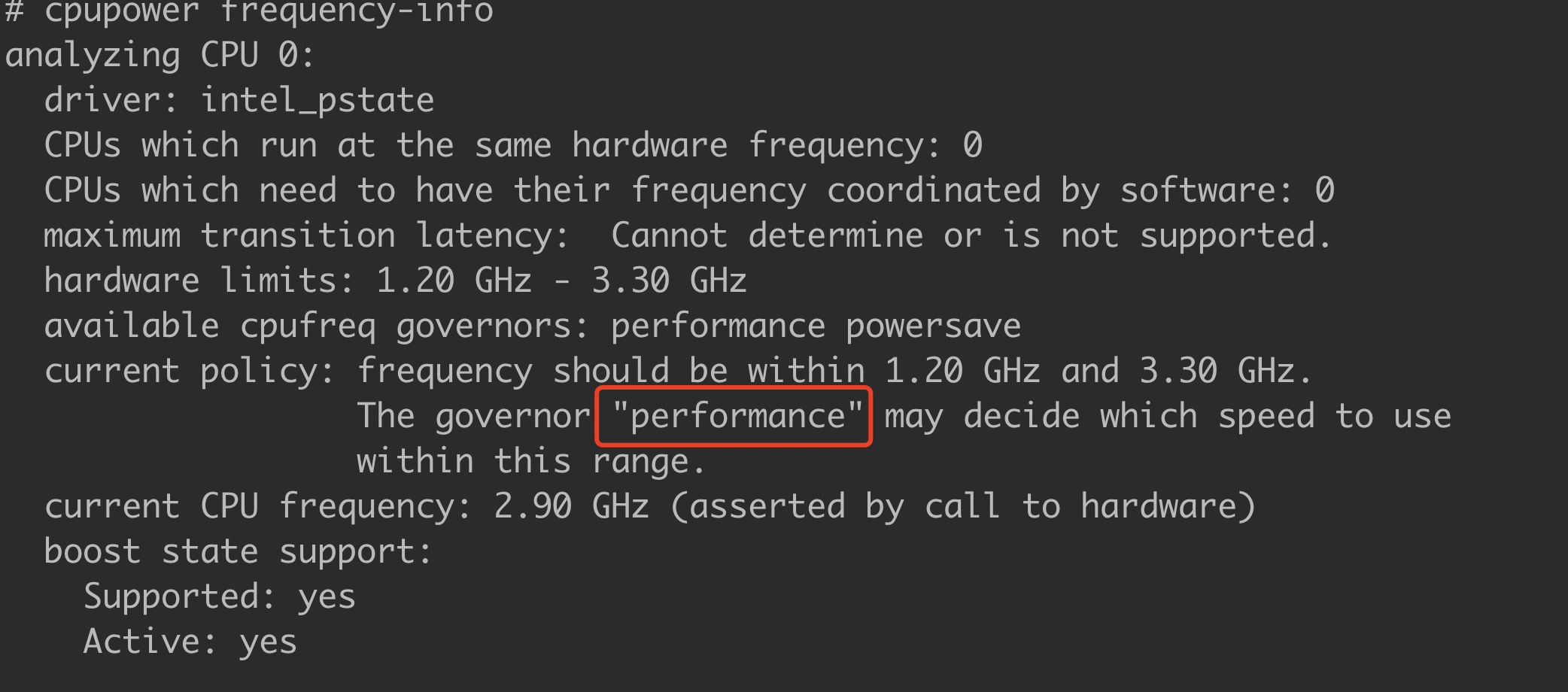
或者通过查看内核参数判断,如下图所示: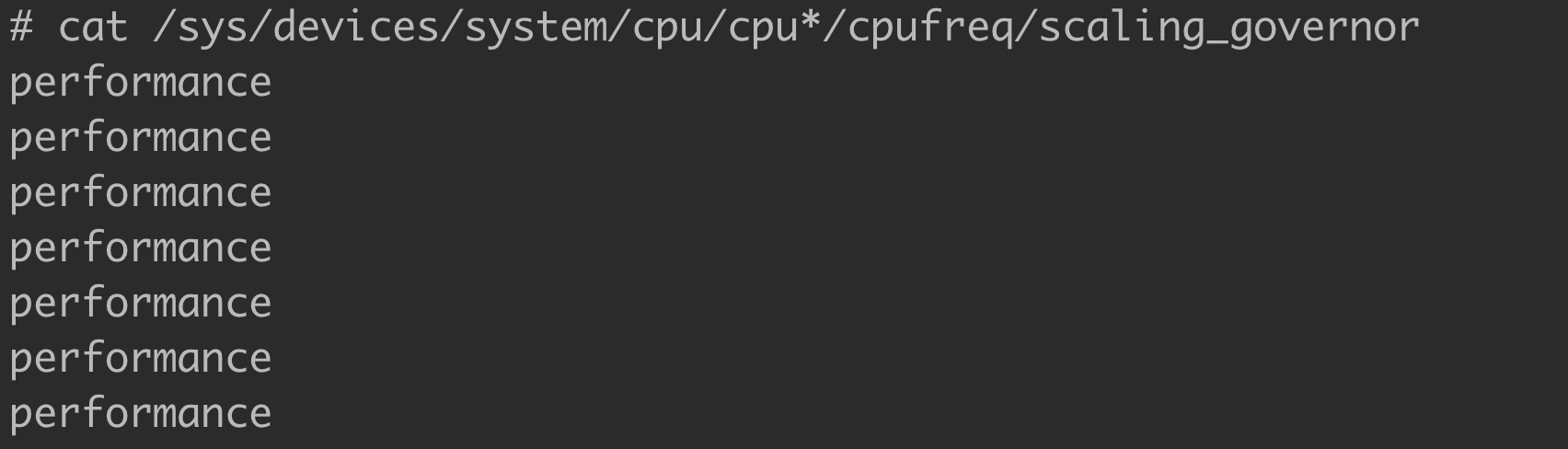
指令周期
指令周期,又称提取-执行周期(fetch-and-execute cycle)是指CPU要执行一条机器指令经过的步骤,由若干机器周期组成。更多解释见 维基百科 、百度百科 。
指令周期大体包含以下几个周期:
- 取指
- 译码
- 执行
- 存储
因为没有访问过的指令一般存储在内存或者磁盘上,故访问时间可能会比较长,为了减少访存时间,故引入了多级缓存,以空间换时间。从上面可以看出因为存在多个周期,每个周期可能与不同的硬件资源交互,如果一条指令执行完后再进行下一条指令的执行,从取指开始,则执行效率会非常低,在此基础上引入了指令流水的概念。
指令流水
指令流水是指为提高处理器执行指令的效率,把一条指令的操作分成多个细小的步骤,每个步骤由专门的电路完成。原理及更多解释请见 维基百科 、百度百科 。
可以通过指令流水来提高指令的执行效率。效果如下图所示。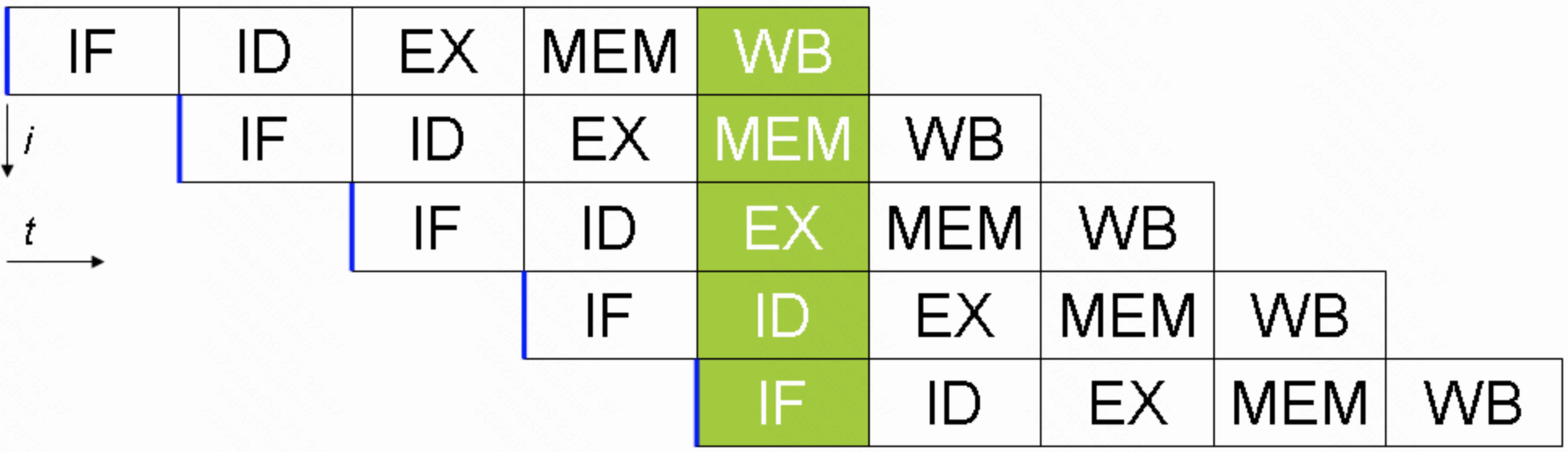
分支预测
分支预测(Branch Prediction):从P5时代开始的一种先进的,解决处理分支指令(if-then-else)导致流水线失败的数据处理方法,由CPU来判断程序分支的进行方向,能够加快运算速度。更详细的解释请见维基百科 、百度百科 、分枝预测-百度百科 。
分支预测效果如下图所示。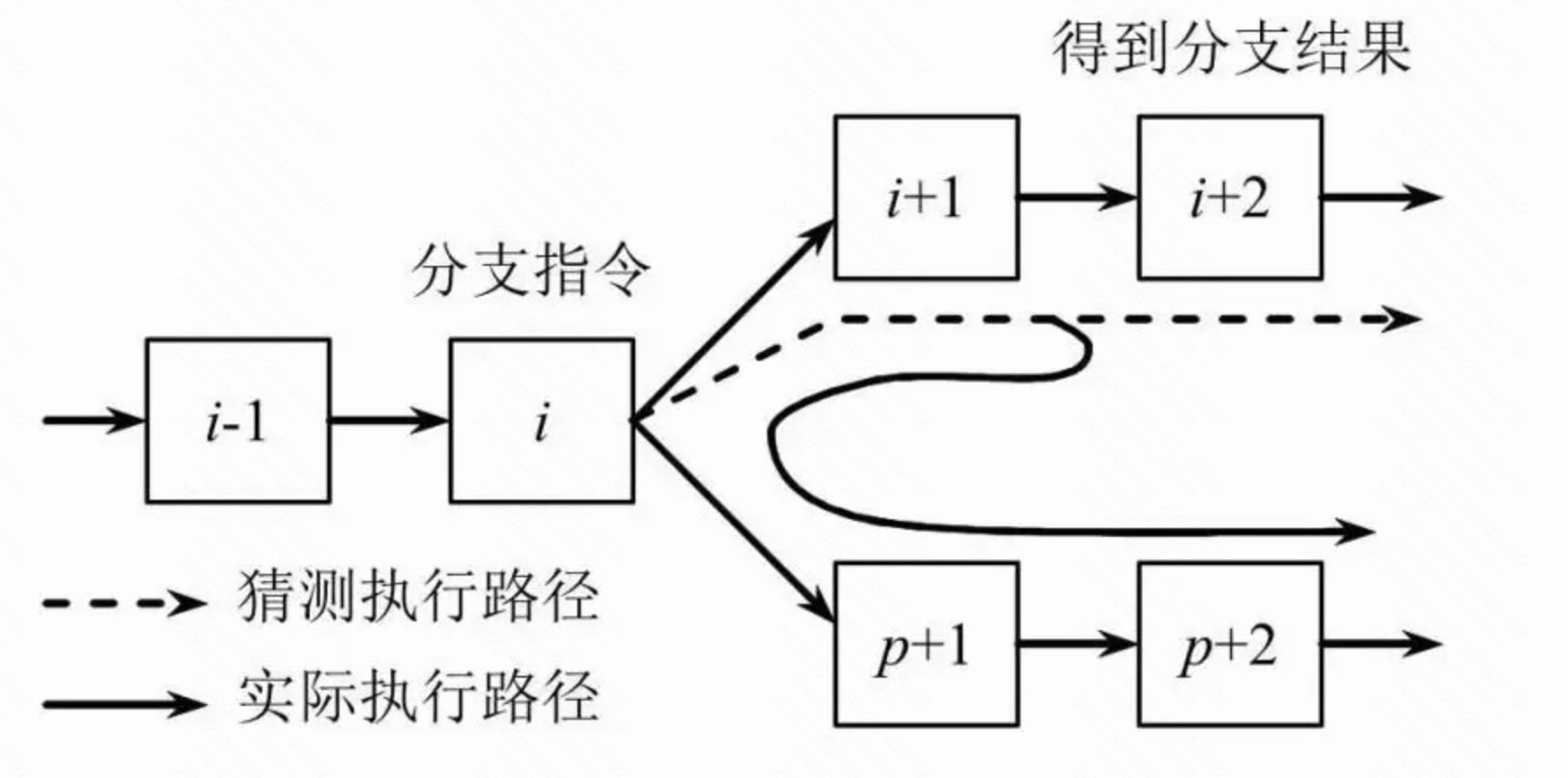
字长
在计算机领域,对于某种特定的计算机设计而言,字(word)是用于表示其自然的数据单位的术语,是用来表示一次性处理事务的固定长度。更详细的解释请见维基百科) 、百度百科
IPC/CPI
IPC:Instructions per cycle,每个时钟周期执行的指令数
CPI:cycles per instruction,每条指令需要的时钟数
IPC和CPI互为倒数关系,比如IPC为0.2,则CPI为5.0。IPC通常在Linux中使用比较多,而CPI通常在Intel内部和其它地方使用比较多。
处理器内部结构
处理器由复杂的部件组合而成,一个双核处理器结构如下图所示。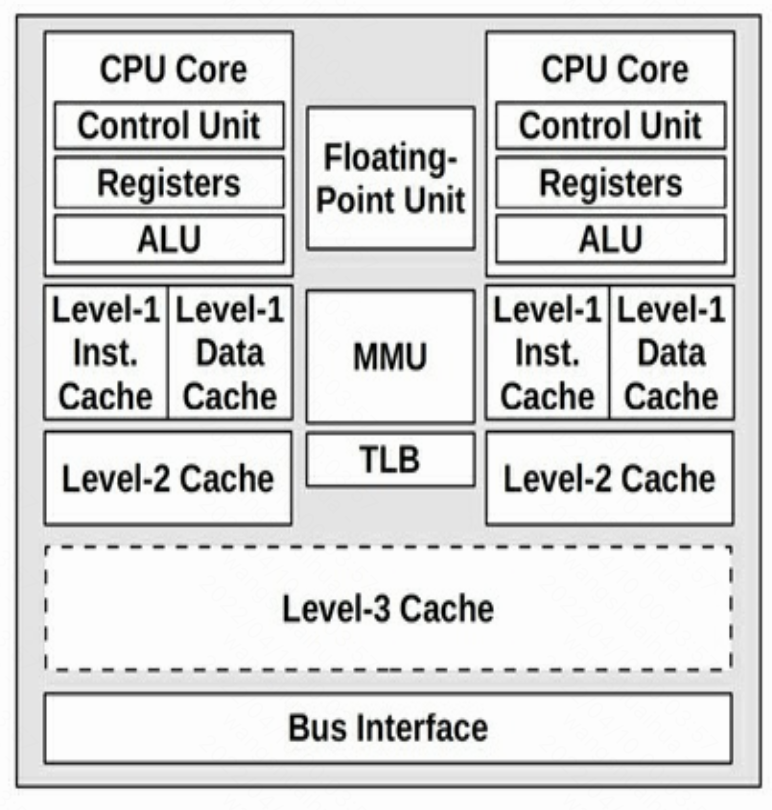
处理器缓存结构如下图所示。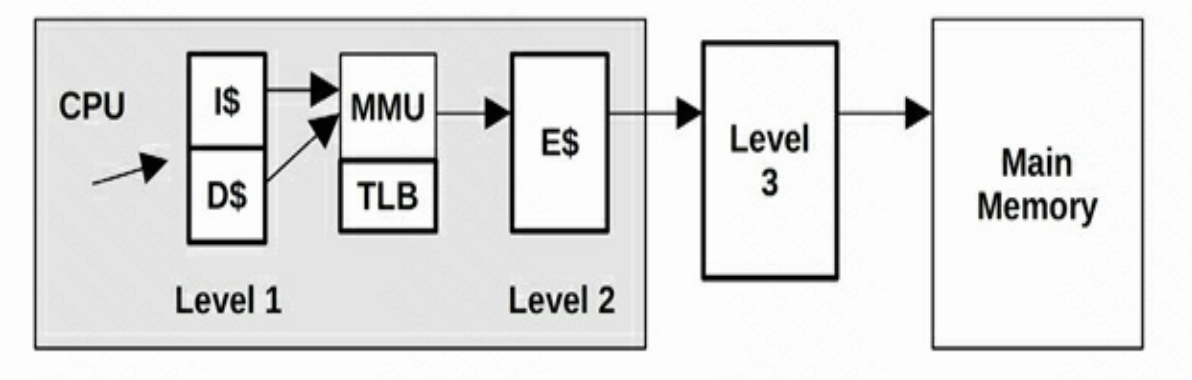
- L1 指令缓存(I$)
- L1 数据缓存(D$)
- 加载-存储单元转译后备缓冲器(TLB)
- L2 存储(E$)
- L3 缓存(可选)
缓存一致性
内存中的数据在同一时刻可能被不同处理器的多颗CPU缓存,当数据被一颗CPU修改时,其它CPU需要感知到数据被修改,丢弃当前数据并重新读取最新的数据,这可能会导致LLC(the longest-latency cache)增长。
- LLC 命中, 非共享: ~40 CPU 时钟
- LLC 命中, 与另一个CPU共享: ~65 CPU 时钟
- LLC 命中, 被另一个CPU修改: ~75 CPU 时钟
内存管理单元MMU
它的功能包括虚拟地址到物理地址的转换(即虚拟内存管理)[1]、内存保护、中央处理器高速缓存的控制等,更过介绍请参考 维基百科 ,其与CPU缓存的关系如下图所示。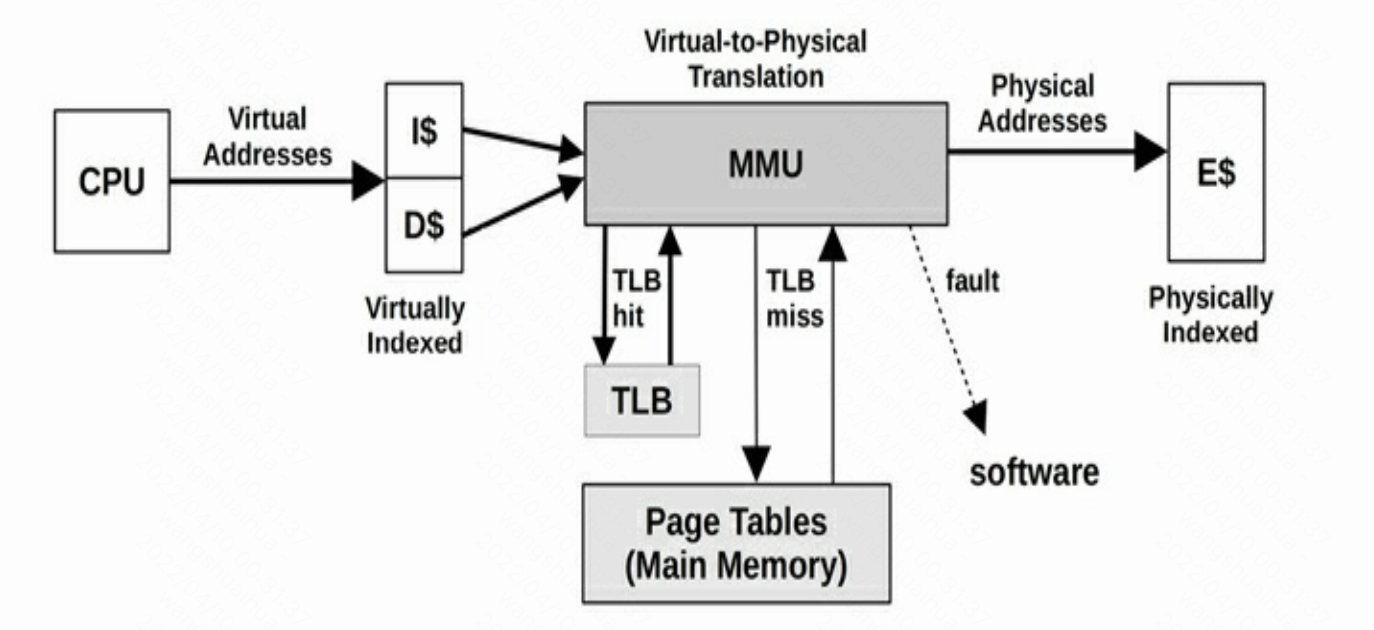
处理器内部连接方式
UMA结构
UMA(uniform memory access),通过系统总线访问内存,结构如下图所示。
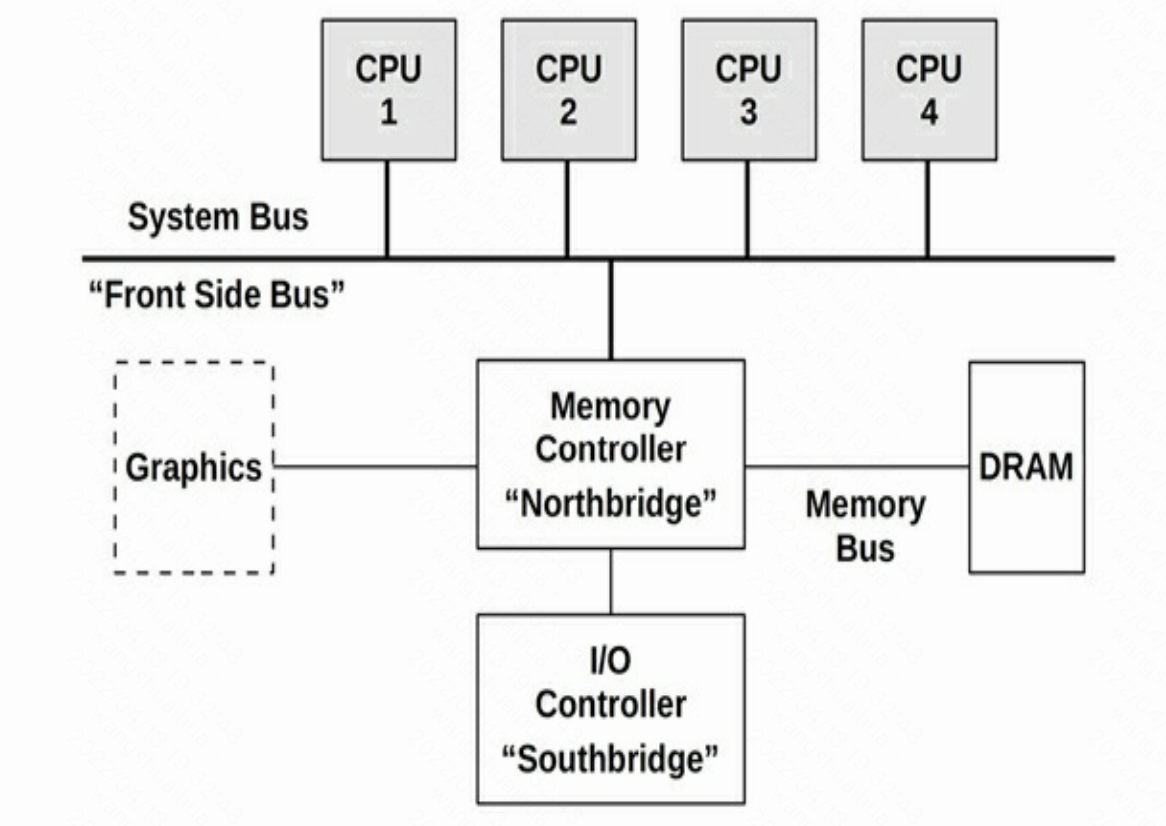
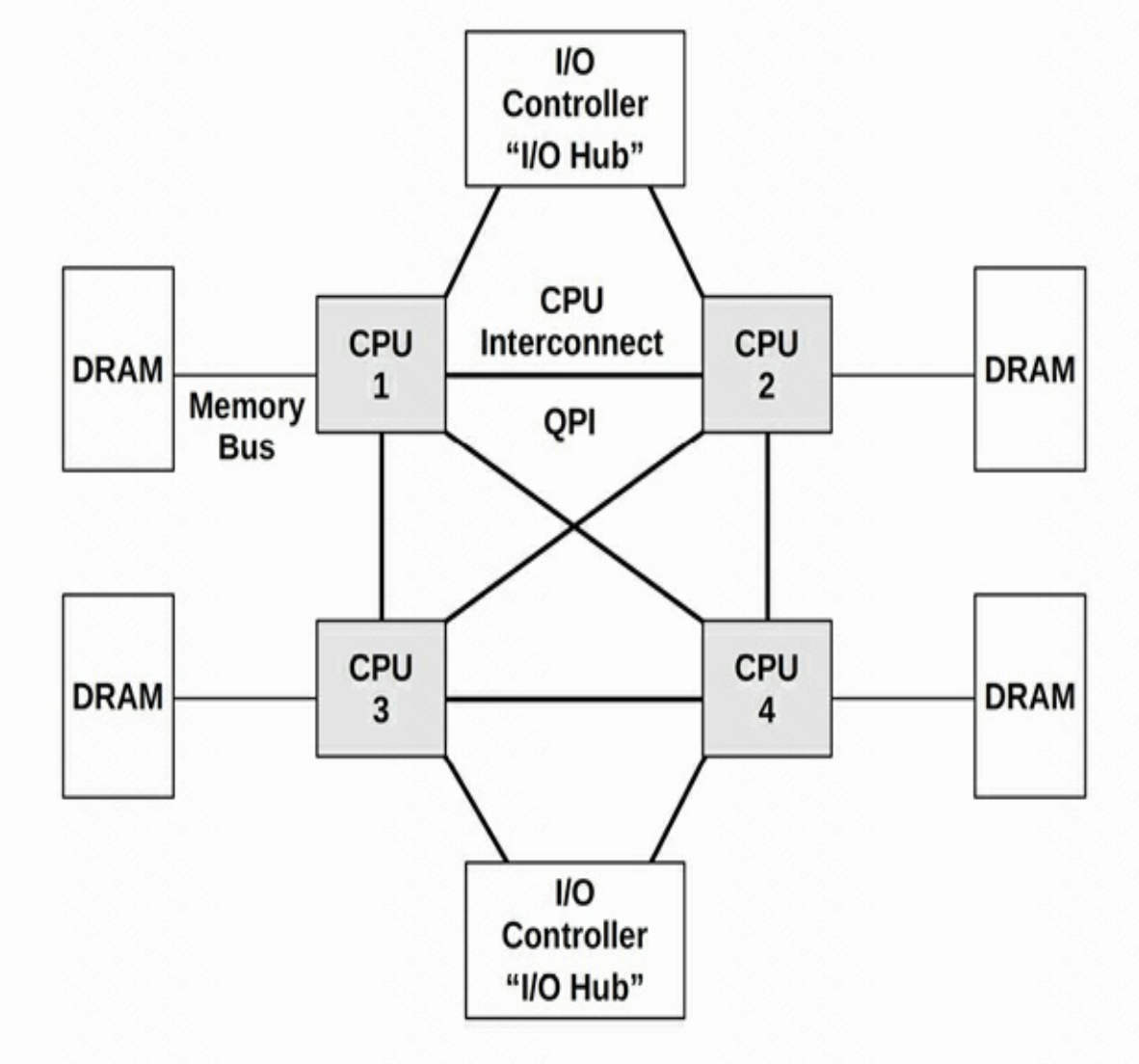
使用总线方式,当处理器数量增加时,因为共享总线资源会有瓶颈,现代操作系统一般使用处理器内部互联方式,即NUMA,如下图所示。

若有收获,就点个赞吧
0 人点赞
