方法论
CPU分析的一般步骤:
- 性能监控指标+工具:通过已有指标或者现成的工具进行初步分析和判断
- 使用USE方法进行进一步分析:U:CPU使用率,S:满载率:E:错误
- 测量分析
- 微基准测试
- 静态性能优化
基础分析工具
基础分析主要包含以下工具的使用:uptime、vmstat、mpstat、sar、ps、top、pidstat,time/ptime
1. uptime
通常uptime可以用来查看系统负载信息
$ uptime19:10:52 up 1135 days, 7:37, 1 user, load average: 87.87, 77.49, 66.99
最后三列分别是1分钟、5分钟和15分钟系统的平均负载。如果数字是依次减小的,说明现在系统负载在升高,如果是依次增大的,则说明系统负载在降低。
在Linux系统中load值的计算包含系统中正在运行的进行(RUNNING)、可以运行的进程(RUNABLE)和处于不可中断的进程。
相关参考文档:https://brendangregg.com/blog/2017-08-08/linux-load-averages.html
2. vmstat
虚拟内存分析工具第一列输出的是可运行进程数,最后几列输出的是cpu相关指标,可以用来分析cpu相关的问题,该工具可显示CPU正式使用率。
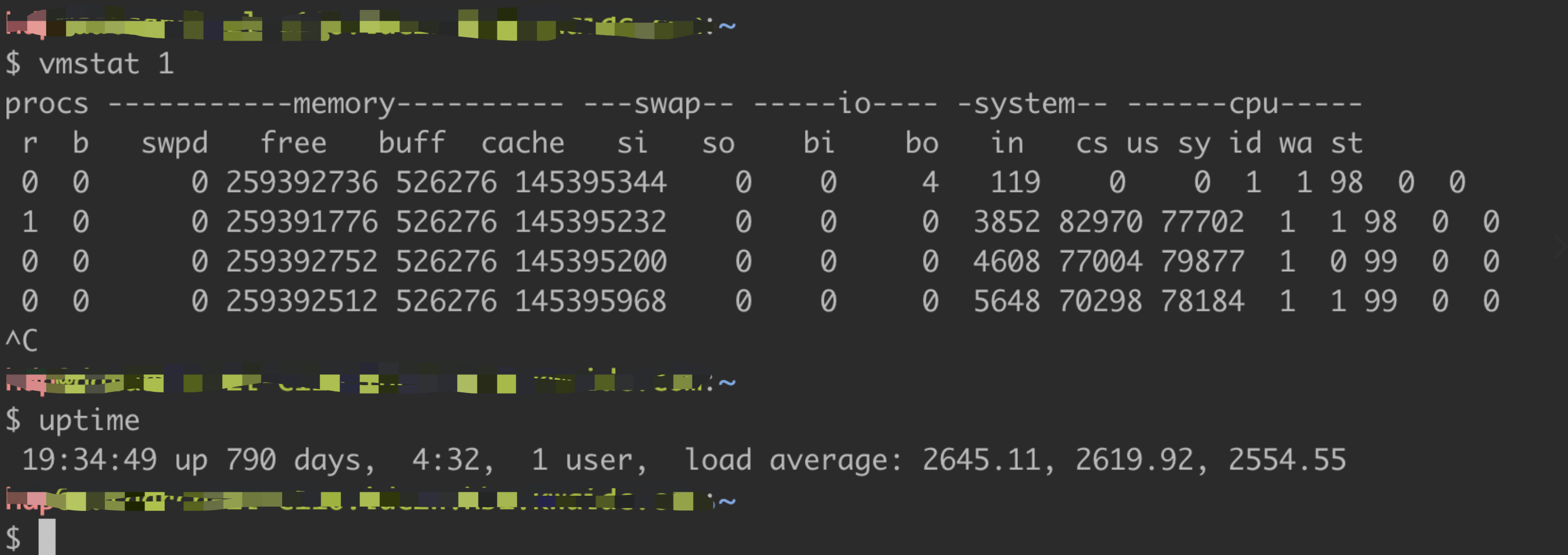
$ vmstat 1procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st58 9 0 856644 44052 88905592 0 0 4214 3852 0 0 61 8 26 5 060 7 0 973376 44072 88245416 0 0 324648 333560 265446 247480 62 11 23 3 058 5 0 1349060 44068 86577808 0 0 289808 257000 270242 276081 55 18 24 3 040 24 0 1573068 44080 84997592 0 0 224756 659252 250767 268095 64 13 17 6 0120 12 0 1636280 44080 83402944 0 0 307740 283888 249253 253964 56 14 22 8 037 14 0 867316 44080 81521136 0 0 454760 298512 275080 294816 51 16 24 10 052 11 0 2181236 44260 80656688 0 0 445088 560996 298539 249712 56 12 24 9 037 6 0 7423208 44260 81312632 0 0 401356 511956 306425 330183 50 9 33 7 0
跟CPU相关的列分析:
- r:对于Linux系统该字段表示所有的Runnable+Running进程,不包含处于D状态的进程,如下图所示
- us:用户态(用户)CPU使用率
- sy:内核态(系统)CPU使用率
- id:CPU空闲率
- wa:CPU等待I/O使用率,当进程阻塞在磁盘IO上时可以用来衡量CPU idle
- st:在虚拟化环境显示被其它租户占用的CPU使用率
3. mpstat
多CPU统计工具,可以统计每个CPU的使用情况
~# mpstat -P ALL 1
Linux 5.4.0-99-generic (ambariserver-wangshuaihua-02.dev.kwaidc.com) 02/26/22 _x86_64_ (8 CPU)
15:11:56 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
15:11:57 all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
15:11:57 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
15:11:57 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
15:11:57 2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
15:11:57 3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
15:11:57 4 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
15:11:57 5 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
15:11:57 6 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
15:11:57 7 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
命令输出列说明:
- CPU:逻辑CPU序号,或者是all
- %usr:用户态(用户)CPU使用率,不包含%nice
- %nice:带有nice进程的用户态CPU使用率
- %sys:内核态(系统)CPU使用率
- %iowait:I/O wait
- %irq:硬中断CPU使用率
- %soft:软中断CPU使用率
- %steal:虚拟化环境其它租户CPU使用率
- %guest:客户端虚拟机使用使用率
- %gnice:客户端虚拟机带有nice标记的进程CPU使用率
- %idle:CPU剩余率
需要关注的列是 %usr,%sys和%idle,注意查看每个CPU的使用率,看是否存在CPU使用不均衡或者热点。
mpstat默认只显示CPU的整体使用情况,如下图所示:
~# mpstat 1
Linux 5.4.0-99-generic (ambariserver-wangshuaihua-02.dev.kwaidc.com) 02/26/22 _x86_64_ (8 CPU)
15:14:04 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
15:14:05 all 0.00 0.00 0.12 0.00 0.00 0.00 0.00 0.00 0.00 99.88
15:14:06 all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
15:14:07 all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
4. sar
sar工具可以用来观测多项系统指标,针对CPU的参数有:
- -P ALL:效果与mpstat -P ALL一样,只是输出的列稍微少一些
- -u:与mpstat默认输出结果一样,系统平均指标
- -q:输出run-queue大小,RUNNABLE+RUNNING与vmstat的r列内容一致
初次使用sar工具可能会报错,如果没有sar工具则需要安装,安装后可能还会遇到以下错误
解决方法:~# sar -P ALL Cannot open /var/log/sysstat/sa26: No such file or directory Please check if data collecting is enabled~# sar -o 2 3
~# sar -P ALL 1 -u -q
Linux 5.4.0-99-generic (ambariserver-wangshuaihua-02.dev.kwaidc.com) 02/26/22 _x86_64_ (8 CPU)
15:27:19 CPU %user %nice %system %iowait %steal %idle
15:27:20 all 0.00 0.00 0.00 0.00 0.00 100.00
15:27:20 0 0.00 0.00 0.00 0.00 0.00 100.00
15:27:20 1 0.00 0.00 0.00 0.00 0.00 100.00
15:27:20 2 0.00 0.00 0.00 0.00 0.00 100.00
15:27:20 3 0.00 0.00 0.00 0.00 0.00 100.00
15:27:20 4 0.00 0.00 0.00 0.00 0.00 100.00
15:27:20 5 0.00 0.00 0.00 0.00 0.00 100.00
15:27:20 6 0.00 0.00 0.00 0.00 0.00 100.00
15:27:20 7 0.00 0.00 0.00 0.00 0.00 100.00
5. ps
ps方法是非常常用的工具,可以列出所有进程的相关信息,命令格式有两种:
- BSD格式,参数不带’-‘字符
- SVR4测试,参数带’-‘字符
BSD格式命令输出如下所示:
~# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 171060 13240 ? Ss Feb15 0:27 /sbin/init
root 2 0.0 0.0 0 0 ? S Feb15 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? I< Feb15 0:00 [rcu_gp]
root 4 0.0 0.0 0 0 ? I< Feb15 0:00 [rcu_par_gp]
root 6 0.0 0.0 0 0 ? I< Feb15 0:00 [kworker/0:0H-kblockd]
root 9 0.0 0.0 0 0 ? I< Feb15 0:00 [mm_percpu_wq]
root 10 0.0 0.0 0 0 ? S Feb15 0:00 [ksoftirqd/0]
root 11 0.0 0.0 0 0 ? I Feb15 8:49 [rcu_sched]
SVR4格式命令输出如下所示:
~# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Feb15 ? 00:00:27 /sbin/init
root 2 0 0 Feb15 ? 00:00:00 [kthreadd]
root 3 2 0 Feb15 ? 00:00:00 [rcu_gp]
root 4 2 0 Feb15 ? 00:00:00 [rcu_par_gp]
root 6 2 0 Feb15 ? 00:00:00 [kworker/0:0H-kblockd]
root 9 2 0 Feb15 ? 00:00:00 [mm_percpu_wq]
root 10 2 0 Feb15 ? 00:00:00 [ksoftirqd/0]
root 11 2 0 Feb15 ? 00:08:49 [rcu_sched]
root 12 2 0 Feb15 ? 00:00:06 [migration/0]
从命令的输出结果上面,看起来BSD格式的输出信息更全一些,但是ps命令可以通过-o参数定制输出列。针对CPU的使用情况,我们按照BSD格式的输出来说,需要关注的是%CPU和TIME列:
- %CPU:进程从启动以来的平均CPU使用率
- TIME:进程启动以来总消耗的CPU时间用户态+内核态(usr+sys)
6. top
top命令可以以指定的时间间隔实时展示进程的CPU使用情况。
~# top
top - 23:46:46 up 1135 days, 12:13, 1 user, load average: 46.75, 60.82, 66.77
Tasks: 1660 total, 2 running, 1657 sleeping, 0 stopped, 1 zombie
%Cpu(s): 28.5 us, 2.3 sy, 0.0 ni, 63.9 id, 4.7 wa, 0.0 hi, 0.5 si, 0.0 st
KiB Mem : 19780201+total, 606332 free, 70851200 used, 12634449+buff/cache
KiB Swap: 0 total, 0 free, 0 used. 12021227+avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
46652 yarn 20 0 8807788 3.459g 40876 S 428.9 1.8 7:49.67 java
69808 yarn 20 0 8643232 2.257g 41064 S 412.5 1.2 2:12.97 java
6608 yarn 20 0 9153288 3.615g 54376 S 404.9 1.9 17:39.61 java
8852 yarn 20 0 4104884 1.796g 47476 S 104.9 1.0 4:58.38 java
7359 hdfs 20 0 8616144 5.152g 3900 S 90.1 2.7 424070:32 java
46763 yarn 20 0 10.562g 7.527g 108768 S 66.1 4.0 1:09.90 java
28082 yarn 20 0 5371224 1.766g 34608 S 59.9 0.9 3:20.35 java
8030 yarn 20 0 4093672 1.656g 61588 S 52.0 0.9 5:33.91 java
51830 yarn 20 0 14.877g 0.010t 15560 S 33.2 5.3 64477:55 java
top命令的输出结果中包含了系统整体CPU使用情况(第3行),和每个进程的CPU使用情况。对于每个进程CPU使用情况我们需要关注的是%CPU和TIME列:
- %CPU:两次屏幕刷新期间进程的CPU使用率
- TIME:进程启动以来的总CPU使用时间,单位为秒,比如上面输出的7359号进程已经消耗的CPU时间是424070分32秒
虽然top是一个非常基础的分析工具,但是它对性能的损耗不可小觑,在负载重的机器上表现尤为明显,需要谨慎使用。top对系统性能有较大的影响主要是因为要读取/proc下面所有进程的信息。因为top是对/proc做快照,所以很容易漏掉执行时间比较短的进程。
7. pidstat
pidstat可以用来分析单个进程或线程的CPU使用情况,默认情况下会滚动输出。
# pidstat 1
Linux 3.10.0-693.5.2.el7.x86_64 (bjlt-h10366.sy) 02/27/2022 _x86_64_ (56 CPU)
12:00:34 AM UID PID %usr %system %guest %CPU CPU Command
12:00:35 AM 1107 24628 100.00 4.59 0.00 100.00 51 java
12:00:35 AM 1107 29868 100.00 3.67 0.00 100.00 38 java
12:00:35 AM 1107 37421 100.00 2.75 0.00 100.00 45 java
12:00:35 AM 1107 38523 0.92 0.00 0.00 0.92 38 java
12:00:35 AM 1107 44470 100.00 26.61 0.00 100.00 40 java
12:00:35 AM 1107 48401 100.00 17.43 0.00 100.00 40 java
12:00:35 AM 1107 51584 27.52 2.75 0.00 30.28 29 java
12:00:35 AM 1107 51830 0.00 100.00 0.00 100.00 45 java
CPU分析常用参数:
- -p ALL:显示所有进程或线程CPU使用情况
- -t:显示线程粒度统计
8. time
time有两个版本,一个是shell内建的,另外一个是/usr/bin/下的,这两个有不同的使用效果
shell内建time命令:
两次对同一个文件求MD5值 ```bashtime md5sum ambari-agent-2.6.2.0-0.x86_64.rpm
06e883c97b88079b0cc71a763fa2a99e ambari-agent-2.6.2.0-0.x86_64.rpm
real 0m0.417s user 0m0.175s sys 0m0.056s
time md5sum ambari-agent-2.6.2.0-0.x86_64.rpm
06e883c97b88079b0cc71a763fa2a99e ambari-agent-2.6.2.0-0.x86_64.rpm
real 0m0.242s user 0m0.177s sys 0m0.027s
从结果上可以看出第一次使用了0.417秒,用户态使用了0.175秒,内核态使用了0.056秒,其中有0.186(0.417-0.175-0.056)秒的差距,猜测可能是花等磁盘io上了,第二次计算后时间差值缩小到了0.038秒,估计是这个文件已经通过文件系统缓存到了内存中。<br />**/usr/bin/time**使用
```bash
# /usr/bin/time -v md5sum ambari-agent-2.6.2.0-0.x86_64.rpm
06e883c97b88079b0cc71a763fa2a99e ambari-agent-2.6.2.0-0.x86_64.rpm
Command being timed: "md5sum ambari-agent-2.6.2.0-0.x86_64.rpm"
User time (seconds): 0.16
System time (seconds): 0.03
Percent of CPU this job got: 98%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:00.20
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 724
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 227
Voluntary context switches: 0
Involuntary context switches: 22
Swaps: 0
File system inputs: 0
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
进阶分级工具
perf
perf是一个Linux的官方分析器,是一个强大的工具,可以做很多分析。这里只会介绍涉及到CPU部分的使用。
perf常见用法:
- 使用perf对指定命令以99Hz进行运行时采样:
perf record -F 99 xxxx
比如:
~# perf record -F 99 md5sum test.txt
7da6d500f2ebc693c9219ea53e5ccb3a test.txt
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.008 MB perf.data (9 samples) ]
~# perf report -n --stdio
# To display the perf.data header info, please use --header/--header-only options.
#
#
# Total Lost Samples: 0
#
# Samples: 9 of event 'cycles'
# Event count (approx.): 43611121
#
# Overhead Samples Command Shared Object Symbol
# ........ ............ ....... ................. ................................
#
30.92% 1 md5sum md5sum [.] 0x0000000000004709
22.97% 1 md5sum md5sum [.] 0x0000000000004314
22.97% 1 md5sum md5sum [.] 0x0000000000004800
8.74% 1 md5sum md5sum [.] 0x00000000000043b7
8.74% 1 md5sum md5sum [.] 0x0000000000004755
5.02% 1 md5sum md5sum [.] 0x00000000000046c9
0.64% 1 md5sum libc-2.31.so [.] realloc
0.00% 1 md5sum [kernel.kallsyms] [k] filemap_fault
0.00% 1 perf [kernel.kallsyms] [k] perf_event_addr_filters_exec
- 对CPU调用栈进行采样,99Hz,持续10s
perf record -a -g -F 99 -- sleep 10
- 对特定进程进行采样,使用dwarf (dbg信息)展开栈结构,99 Hz,持续10s
perf record -F 99 -p PID --call-graph dwarf -- sleep 10
- 通过exec调用统计新进程创建信息
perf record -e sched:sched_process_exec -a
- 记录上下文切换事件,包含栈信息,持续10s
perf record -e sched:sched_switch -a -g -- sleep 10
- 合并查看perf.data文件中的内容
perf report -n --stdio
- 列出perf.data文件中记录的所有事件,并列出数据头信息(推荐使用)
perf report --header
- 统计PMC信息,持续10s ```bash ~# perf stat -a — sleep 10
Performance counter stats for ‘system wide’:
80008.95 msec cpu-clock # 7.996 CPUs utilized 884 context-switches # 0.011 K/sec 0 cpu-migrations # 0.000 K/sec 71 page-faults # 0.001 K/sec 95619070 cycles # 0.001 GHz 22556744 stalled-cycles-frontend # 23.59% frontend cycles idle 13343963 stalled-cycles-backend # 13.96% backend cycles idle 21832747 instructions # 0.23 insn per cycle
1.03 stalled cycles per insn
4608307 branches # 0.058 M/sec 2187 branch-misses # 0.05% of all branches
10.005943705 seconds time elapsed
9. 查看上下文切换事件统计,持续10s
```bash
~# perf stat -e sched:sched_switch -a -- sleep 10
Performance counter stats for 'system wide':
1031 sched:sched_switch
10.001918573 seconds time elapsed
- 查看xx命令的LLC缓存(last level cache)统计
```bash
perf stat -e LLC-loads,LLC-load-misses,LLC-stores,LLC-store-misses md5sum ambari-agent-2.6.2.0-0.x86_64.rpm
06e883c97b88079b0cc71a763fa2a99e ambari-agent-2.6.2.0-0.x86_64.rpm
Performance counter stats for ‘md5sum ambari-agent-2.6.2.0-0.x86_64.rpm’:
1,383,647 LLC-loads (50.96%) 603,408 LLC-load-misses # 43.61% of all LL-cache hits (52.58%) 576,738 LLC-stores (49.12%) 40,283 LLC-store-misses (47.45%)
0.491177402 seconds time elapsed
11. 生成火焰图<br />对于高于5.8的内核版本可以直接使用perf命令自动生成
perf script report flamegraph
对于低于5.8内核版本,可以使用工具生成
```bash
# perf script --header > out.stacks
# git clone https://github.com/brendangregg/FlameGraph; cd FlameGraph
# ./stackcollapse-perf.pl < ../out.stacks | ./flamegraph.pl --hash > out.svg
# python3 -m http.server 1235
通过浏览器可打开火焰图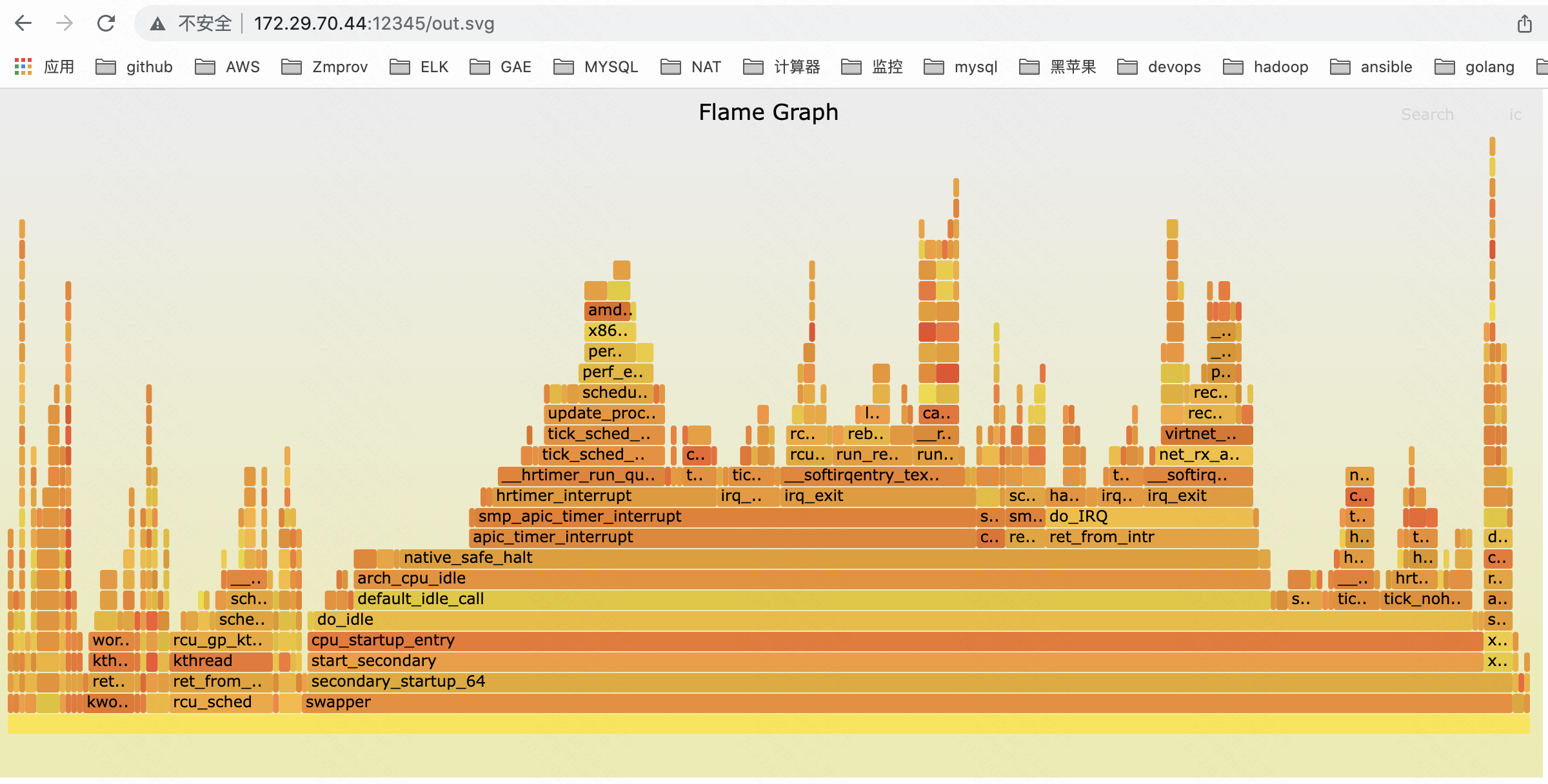
也可以通过管道方式将perf script —header结果直接重定向给stackcollapse-perf.pl,不使用out.stacks文件
eBPF工具
基于eBPF的分析工具主要有:cpudist、runqlat、runqlen、softiqrs、hardirqs、bpftrace
1. execsnoop
追踪新进程创建事件,通过exec事件实现,用法如下:
BCC版本:
~# execsnoop-bpfcc
PCOMM PID PPID RET ARGS
bash 129653 129624 0 /bin/bash
locale-check 129654 129653 0 /usr/bin/locale-check C.UTF-8
locale 129655 129653 0 /usr/bin/locale
lesspipe 129657 129653 0 /usr/bin/lesspipe
basename 129658 129657 0 /usr/bin/basename /usr/bin/lesspipe
dirname 129660 129659 0 /usr/bin/dirname /usr/bin/lesspipe
常用参数
- -x:包含调用exec失败的情况
- -n pattern:只输出命令行复合模式的结果
- -l pattern:只输出命令行参数复合模式的结果
- —max args args:输出命令行参数个数的上限,默认为20个
bpftrace版本
~# execsnoop.bt
Attaching 2 probes...
TIME(ms) PID ARGS
实现源码:
BEGIN
{
printf("%-10s %-5s %s\n", "TIME(ms)", "PID", "ARGS");
}
tracepoint:syscalls:sys_enter_execve
{
printf("%-10u %-5d ", elapsed / 1000000, pid);
join(args->argv);
}
2. exitsnoop
一个BCC工具,可以打印出进程运行的时长和退出原因.
~# exitsnoop-bpfcc
PCOMM PID PPID TID AGE(s) EXIT_CODE
kworker/dying 128579 2 128579 18302.81 0
systemd-udevd 129785 453 129785 3.94 0
systemd-udevd 129786 453 129786 3.94 0
常用参数:
- -p PID:指定进程
- -t:输出时间戳信息
- -x:仅输出进程退出码不为0的情况
3. cpudist
cpudist是一个BCC工,具用于统计进程在cpu上的运行时间,并输出直方图
~# cpudist-bpfcc
Tracing on-CPU time... Hit Ctrl-C to end.
^C
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 1 | |
8 -> 15 : 3 |* |
16 -> 31 : 8 |** |
32 -> 63 : 5 |* |
64 -> 127 : 3 |* |
128 -> 255 : 5 |* |
256 -> 511 : 1 | |
512 -> 1023 : 2 | |
1024 -> 2047 : 3 |* |
2048 -> 4095 : 21 |******* |
4096 -> 8191 : 113 |****************************************|
8192 -> 16383 : 6 |** |
16384 -> 32767 : 21 |******* |
32768 -> 65535 : 20 |******* |
65536 -> 131071 : 16 |***** |
131072 -> 262143 : 5 |* |
常用参数
- -m: 时间单位用ms,默认us
- -O: 展示不在cpu执行时间的分布
- -P: 每个进程打印一个直方图
-
4. runqlat
runqlat同时有bcc版本和bpftrace版本,通常用来衡量CPU的满载度,这个工具获取的指标数据是每一个任务等待cpu消耗的时间。
bcc版本,运行10s,只运行1次~# runqlat-bpfcc 10 1 Tracing run queue latency... Hit Ctrl-C to end. usecs : count distribution 0 -> 1 : 3 | | 2 -> 3 : 15 |*** | 4 -> 7 : 38 |******** | 8 -> 15 : 184 |****************************************| 16 -> 31 : 179 |************************************** | 32 -> 63 : 25 |***** | 64 -> 127 : 3 | |
bpftrace版本,按 {key control c} 结束运行
~# runqlat.bt
Attaching 5 probes...
Tracing CPU scheduler... Hit Ctrl-C to end.
^C
@usecs:
[1] 7 | |
[2, 4) 32 |@ |
[4, 8) 205 |@@@@@@@@@ |
[8, 16) 831 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[16, 32) 1135 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[32, 64) 448 |@@@@@@@@@@@@@@@@@@@@ |
[64, 128) 55 |@@ |
[128, 256) 5 | |
[256, 512) 9 | |
[512, 1K) 6 | |
[1K, 2K) 1 | |
[2K, 4K) 1 | |
因为qunlat是通过调度器唤醒和上下文切换事件进行计算的等待时间,所以对于繁忙的系统可能会带来比较明显的开销,在这种情况下可以尝试使用runqlen工具。
5. runqlen
runqlen工具有BCC和bpftrace版本,其实现原理是对CPU运行队列进行采样,计算还有多少任务等待运行,可以作为一个粗略的分析,命令使用方式如下所示
BCC版本,运行1次,持续10s:
~# runqlen-bpfcc 10 1
Sampling run queue length... Hit Ctrl-C to end.
runqlen : count distribution
0 : 3859 |****************************************|
bpftrace版本,使用 {key control c} 结束运行:
~# runqlen.bt
Attaching 2 probes...
Sampling run queue length at 99 Hertz... Hit Ctrl-C to end.
^C
@runqlen:
[0, 1) 2498 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
6. softiqrs
softirqs 是一个BCC工具,当前还没有bpftrace版本,对于软中断的cpu使用率可以使用mpstat查看,可以参考mpstat命令的输出结果。softirqs与mpstat一个显著的区别是sortirqs可以显示每个软中断的时间消耗。
mpstat 运行1次,持续时间10s
~# softirqs-bpfcc 10 1
Tracing soft irq event time... Hit Ctrl-C to end.
SOFTIRQ TOTAL_usecs
block 34
sched 2436
rcu 2584
timer 3861
net_rx 4305
常用参数:
- -d: 以直方图方式显示软中断处理时间
- -T: 打印时间戳
~# softirqs-bpfcc -d -T 10 1
Tracing soft irq event time... Hit Ctrl-C to end.
15:30:27
softirq = net_rx
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 13 |******* |
4 -> 7 : 40 |*********************** |
8 -> 15 : 24 |************** |
16 -> 31 : 28 |**************** |
32 -> 63 : 68 |****************************************|
64 -> 127 : 2 |* |
7. hardirqs
hardirqs也是BCC工具可以用来展示硬中断的处理时间,CPU在处理硬中断的使用率可以参照mpstat命令的结果输出,该命令与sortirqs类似,可以显示每一个中断的消耗时间,使用示例如下:
运行1次,持续10s
~# hardirqs-bpfcc 10 1
Tracing hard irq event time... Hit Ctrl-C to end.
HARDIRQ TOTAL_usecs
virtio3-output.0 20
virtio0-request 60
virtio3-input.0 1567
常用参数可参考sortirqs
~# hardirqs-bpfcc -d -T 10 1
Tracing hard irq event time... Hit Ctrl-C to end.
15:35:56
hardirq = b'virtio3-input.0'
usecs : count distribution
0 -> 1 : 16 |************ |
2 -> 3 : 30 |*********************** |
4 -> 7 : 23 |****************** |
8 -> 15 : 51 |****************************************|
16 -> 31 : 42 |******************************** |
32 -> 63 : 2 |* |
hardirq = b'virtio3-output.0'
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 1 |****************************************|
8. runqslower
列出运行队列中等待延迟超过阈值的线程名字
~# runqslower-bpfcc
Tracing run queue latency higher than 10000 us
TIME COMM PID LAT(us)
命令语法
runqslower [options] [min_us]
命令行选项
- -p PID:仅测量给定的进程
默认的阈值为10 000 微秒
9. bpftrace
bpftrace 是eBPF的另外一个前端,通过bpftrace单行命令可以快速实现一些追踪分析的功能,后端是eBPF。
bpftrace最擅长的是使用一行或几行脚本式的命令进行观测,不适合写比较复杂的程序,单行程序示例如下:
单行脚本式程序的语法:
bpftrace -e 'xxxxx'
-e ‘xxxxx’: 引号中是bpftrace程序,bpftrace的其它使用方式可以使用-h参数查看,具体的bpftrace语言语法解析会有专门介绍的文章。
1) 追踪新创建的进程
bpftrace -e 'tracepoint:syscalls:sys_enter_execve { join(args->argv); }'
2) 追踪每个系统调用,并以pid和进程名进行分组统计
~# bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[pid, comm] = count(); }'
Attaching 1 probe...
^C
@[813, wpa_supplicant]: 2
@[425, journal-offline]: 4
@[425, systemd-journal]: 8
@[784, gmain]: 10
@[1172, rtkit-daemon]: 16
@[102034, sshd]: 18
@[780, gmain]: 20
@[1690, gsd-color]: 24
@[1597, gmain]: 24
@[788, irqbalance]: 24
@[990, apache2]: 60
@[602, multipathd]: 85
@[102582, bpftrace]: 213
@[884, snmpd]: 911
3) 统计系统调用次数:
~# bpftrace -e 'tracepoint:syscalls:sys_enter_* { @[probe] = count(); }'
Attaching 332 probes...
^C
@[tracepoint:syscalls:sys_enter_bind]: 1
[...]
@[tracepoint:syscalls:sys_enter_futex]: 155
@[tracepoint:syscalls:sys_enter_read]: 200
@[tracepoint:syscalls:sys_enter_dup]: 302
@[tracepoint:syscalls:sys_enter_bpf]: 322
@[tracepoint:syscalls:sys_enter_openat]: 404
@[tracepoint:syscalls:sys_enter_dup2]: 602
@[tracepoint:syscalls:sys_enter_ioctl]: 652
@[tracepoint:syscalls:sys_enter_close]: 1115
4) 对系统中的进程以99Hz进程采样,以进程名分组计算被采样的次数:
~# bpftrace -e 'profile:hz:99 { @[comm] = count(); }'
Attaching 1 probe...
^C
@[rcu_sched]: 1
@[swapper/5]: 48
@[swapper/7]: 48
@[swapper/1]: 513
@[swapper/6]: 567
@[swapper/4]: 959
@[swapper/2]: 1017
@[swapper/0]: 1729
@[swapper/3]: 3115
5) 对全系统范围内的用户和内核空间栈以49Hz进程采样:
~# bpftrace -e 'profile:hz:49 { @[kstack, ustack, comm] = count(); }'
Attaching 1 probe...
^C
@[
group_balance_cpu+5
rebalance_domains+616
run_rebalance_domains+130
__do_softirq+225
irq_exit+174
smp_apic_timer_interrupt+123
apic_timer_interrupt+15
native_safe_halt+14
arch_cpu_idle+21
default_idle_call+35
do_idle+507
cpu_startup_entry+32
start_secondary+359
secondary_startup_64+164
, , swapper/3]: 1
6) 对“sshd”进程用户空间栈以49Hz进行采样:
~# bpftrace -e 'profile:hz:49 /comm == "sshd"/ { @[ustack] = count(); }'
Attaching 1 probe...
^C
7) 计算所有以”vfs_”开头的内核函数的调用,以函数名分别统计:
~# bpftrace -e 'kprobe:vfs_* { @[func] = count(); }'
Attaching 65 probes...
^C
@[vfs_fsync_range]: 2
@[vfs_statfs]: 6
@[vfs_writev]: 6
@[vfs_readlink]: 10
@[vfs_write]: 37
@[vfs_statx]: 54
@[vfs_statx_fd]: 584
@[vfs_getattr_nosec]: 683
@[vfs_getattr]: 684
@[vfs_open]: 759
@[vfs_read]: 991
8) 追踪所有使用pthread_create()创建的线程
~# bpftrace -e 'u:/lib/x86_64-linux-gnu/libpthread-2.31.so:pthread_create { printf("%s by %s (%d)\n", probe, comm, pid); }'
Attaching 1 probe...
9) 列出所有跟sched相关的追踪点(tracepoint)
bpftrace -l 'tracepoint:sched:*'

若有收获,就点个赞吧
0 人点赞
