首先,**BERT是一个transformer的Encoder**,我们已经讲过transformer了,我们也花了很多时间来介绍Encoder和Decoder,transformer中的Encoder它实际上是BERT的架构,它和transformer的Encoder完全一样,里面有很多Self-Attention和Residual connection,还有Normalization等等,那么,这就是BERT。<br />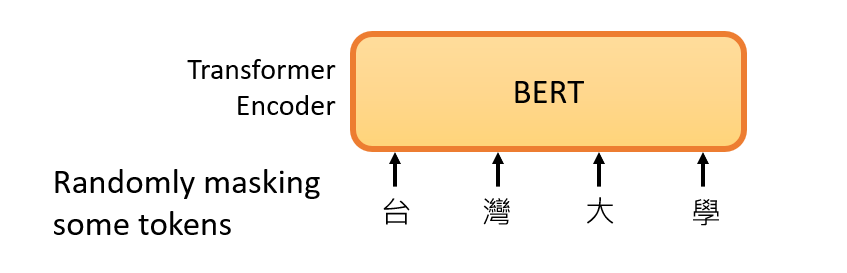<br />**BERT可以输入一行向量,然后输出另一行向量,输出的长度与输入的长度相同**。 <br />BERT一般用于自然语言处理,用于文本场景,所以一般来说,它的输入是一串文本,也是一串数据。<br />当我们真正谈论Self-Attention的时候,我们也说**不仅文本是一种序列,而且语音也可以看作是一种序列,甚至图像也可以看作是一堆向量**。BERT同样的想法是,不仅用于NLP,或者用于文本,它也可以用于语音和视频。
做填空题
接下来我们需要做的是,随机盖住一些输入的文字,被mask的部分是随机决定的,例如,我们输入100个token,什么是token?在中文文本中,我们通常把一个汉字看作是一个token,当我们输入一个句子时,其中的一些词会被随机mask。
mask的具体实现有两种方法。
- 第一种方法是,用一个特殊的符号替换句子中的一个词,我们用 “MASK “标记来表示这个特殊符号,你可以把它看作一个新字,这个字完全是一个新词,它不在你的字典里,这意味着mask了原文。
- 另外一种方法,随机把某一个字换成另一个字。中文的 “湾”字被放在这里,然后你可以选择另一个中文字来替换它,它可以变成 “一 “字,变成 “天 “字,变成 “大 “字,或者变成 “小 “字,我们只是用随机选择的某个字来替换它
所以有两种方法来做mask,一种是添加一个特殊的标记 “MASK”,另一种是用一个字来替换某个字。
开始做填空题
mask后,一样是输入一个序列,我们把BERT的相应输出看作是另一个序列,接下来,我们在输入序列中寻找mask部分的相应输出,然后,这个向量将通过一个Linear transform。
在训练过程中。我们知道被mask的字符是什么,而BERT不知道,我们可以用一个one-hot vector来表示这个字符,并使输出和one-hot vector之间的交叉熵损失最小。
Next Sentence Prediction
它的意思是,我们从数据库中拿出两个句子,这是我们通过在互联网上抓取和搜索文件得到的大量句子集合,我们在这两个句子之间添加一个特殊标记。这样,BERT就可以知道,这两个句子是不同的句子,因为这两个句子之间有一个分隔符。
我们还将在句子的开头添加一个特殊标记,这里我们用CLS来表示这个特殊标记。
现在,我们有一个很长的序列,包括两个句子,由SEP标记和前面的CLS标记分开。如果我们把它传给BERT,它应该输出一个序列,因为输入也是一个序列,这毕竟是Encoder的目的。
我们将只看CLS的输出,我们将把它乘以一个Linear transform。
现在它必须做一个二分类问题,有两个可能的输出:是或不是。这个方法被称为Next Sentence Prediction ,所以我们需要预测,第二句是否是第一句的后续句。
初步总结
当我们训练时,我们要求BERT学习两个任务。
- 一个是掩盖一些字符,具体来说是汉字,然后要求它填补缺失的字符。
-
下游任务
所以总的来说,BERT它学会了如何填空。BERT的神奇之处在于,在你训练了一个填空的模型之后,它还可以用于其他任务。这些任务不一定与填空有关,也可能是完全不同的任务,但BERT仍然可以用于这些任务,这些任务是BERT实际使用的任务,它们被称为Downstream Tasks(下游任务),以后我们将谈论一些Downstream Tasks 的例子。
所谓的 “Downstream Tasks “是指,你真正关心的任务。但是,当我们想让BERT学习做这些任务时,我们仍然需要一些标记的信息。
总之,BERT只是学习填空,但是,以后可以用来做各种你感兴趣的Downstream Tasks 。它就像胚胎中的干细胞,它有各种无限的潜力,虽然它还没有使用它的力量,它只能填空,但以后它有能力解决各种任务。我们只需要给它一点数据来激发它,然后它就能做到。
BERT分化成各种任务的功能细胞,被称为Fine-tune(微调)。所以,我们经常听到有人说,他对BERT进行了微调,也就是说他手上有一个BERT,他对这个BERT进行了微调,使它能够完成某种任务,与微调相反,在微调之前产生这个BERT的过程称为预训练。Case 1: Sentiment analysis
比如说Sentiment analysis情感分析,就是给机器一个句子,让它判断这个句子是正面的还是负面的。

对于BERT来说,它是如何解决情感分析的问题的?
你只要给它一个句子,也就是你想用它来判断情绪的句子,然后把CLS标记放在这个句子的前面,我刚才提到了CLS标记。我们把CLS标记放在前面,扔到BERT中,这4个输入实际上对应着4个输出。然后,我们只看CLS的部分。CLS在这里输出一个向量,我们对它进行Linear transform,也就是将它乘以一个Linear transform的矩阵,这里省略了Softmax。
然而,在实践中,你必须为你的Downstream Tasks 提供标记数据,换句话说,BERT没有办法从头开始解决情感分析问题,你仍然需要向BERT提供一些标记数据,你需要向它提供大量的句子,以及它们的正负标签,来训练这个BERT模型。
在训练的时候,Linear transform和BERT模型都是利用Gradient descent来更新参数的。 Linear transform的参数是随机初始化的
- 而BERT的参数是由学会填空的BERT初始化的。
首先,在训练网络时,scratch与用学习填空的BERT初始化的网络相比,损失下降得比较慢,最后,用随机初始化参数的网络的损失仍然高于用学习填空的BERT初始化的参数。
- 当你进行Self-supervised学习时,你使用了大量的无标记数据。
- 另外,Downstream Tasks 需要少量的标记数据。
所谓的 “半监督 “是指,你有大量的无标签数据和少量的有标签数据,这种情况被称为 “半监督”,所以使用BERT的整个过程是连续应用Pre-Train和Fine-Tune,它可以被视为一种半监督方法。
Case 2 :POS tagging
第二个案例是,输入一个序列,然后输出另一个序列,而输入和输出的长度是一样的。我们在讲Self-Attention的时候,也举了类似的例子。 例如,POS tagging。
POS tagging的意思是词性标记。你给机器一个句子,它必须告诉你这个句子中每个词的词性,即使这个词是相同的,也可能有不同的词性。
你只需向BERT输入一个句子。之后,对于这个句子中的每一个标记,它是一个中文单词,有一个代表这个单词的相应向量。然后,这些向量会依次通过Linear transform和Softmax层。最后,网络会预测给定单词所属的类别,例如,它的词性。
当然,类别取决于你的任务,如果你的任务不同,相应的类别也会不同。接下来你要做的事情和案例1完全一样。换句话说,你需要有一些标记的数据。这仍然是一个典型的分类问题。唯一不同的是,BERT部分,即网络的Encoder部分,其参数不是随机初始化的。在预训练过程中,它已经找到了不错的参数。
Natural Language Inference(语言推断)
在案例3中,模型输入两个句子,输出一个类别。好了,第三个案例以两个句子为输入,输出一个类别,什么样的任务采取这样的输入和输出? 最常见的是Natural Language Inference ,它的缩写是NLI。
机器要做的是判断,是否有可能从前提中推断出假设。这个前提与这个假设相矛盾吗?或者说它们不是相矛盾的句子?
在这个例子中,我们的前提是,一个人骑着马,然后他跳过一架破飞机,这听起来很奇怪。但这个句子实际上是这样的。这是一个基准语料库中的例子。
这里的假设是,这个人在一个餐馆。所以推论说这是一个矛盾。
所以机器要做的是,把两个句子作为输入,并输出这两个句子之间的关系。这种任务很常见。它可以用在哪里呢?例如,舆情分析。给定一篇文章,下面有一个评论,这个消息是同意这篇文章,还是反对这篇文章?该模型想要预测的是每条评论的位置。事实上,有很多应用程序接收两个句子,并输出一个类别。
BERT是如何解决这个问题的?你只要给它两个句子,我们在这两个句子之间放一个特殊的标记,并在最开始放CLS标记。
这个序列是BERT的输入。但我们只把CLS标记作为Linear transform的输入。它决定这两个输入句子的类别。对于NLI,你必须问,这两个句子是否是矛盾的。它是用一些预先训练好的权重来初始化的。
Extraction-based Question Answering (QA)
这是Extraction-based的QA。也就是说,我们假设答案必须出现在文章中。答案必须是文章中的一个片段。
在这个任务中,一个输入序列包含一篇文章和一个问题,文章和问题都是一个序列。对于中文来说,每个d代表一个汉字,每个q代表一个汉字。你把d和q放入QA模型中,我们希望它输出两个正整数s和e。根据这两个正整数,我们可以直接从文章中截取一段,它就是答案。这个片段就是正确的答案。
你的保证模型应该输出,s等于17,e等于17,来表示gravity。因为它是整篇文章中的第17个词,所以s等于17,e等于17,意味着输出第17个词作为答案。
或者举另一个例子,答案是,”within a cloud”,这是文章中的第77至79个词。你的模型要做的是,输出77和79这两个正整数,那么文章中从第77个词到第79个词的分割应该是最终的答案。这就是作业7要你做的。
当然,我们不是从头开始训练QA模型,为了训练这个QA模型,我们使用BERT预训练的模型。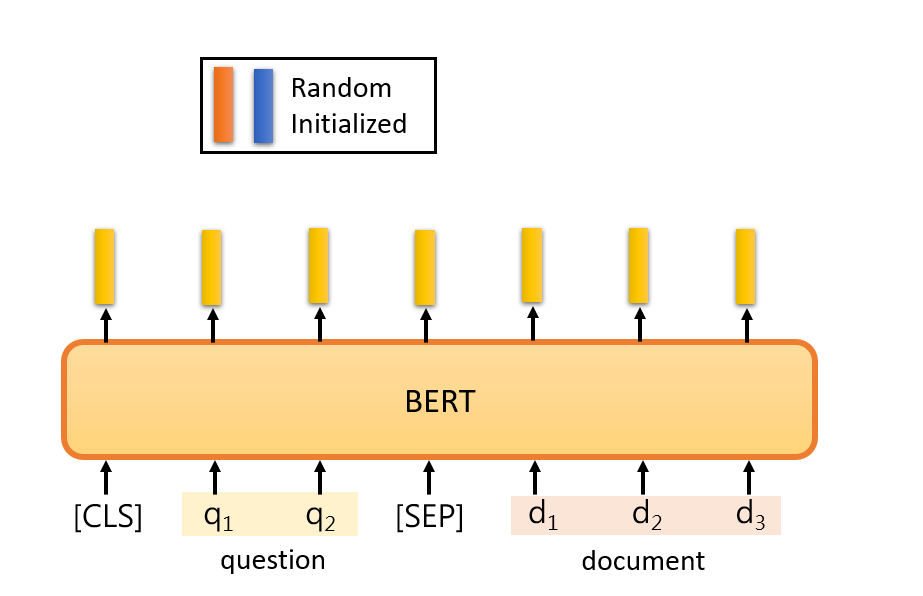
这个解决方案是这样的。对于BERT来说,你必须向它展示一个问题,一篇文章,以及在问题和文章之间的一个特殊标记,然后我们在开头放一个CLS标记。
在这个任务中,你唯一需要从头训练的只有两个向量。”从头训练 “是指随机初始化。这里我们用橙色向量和蓝色向量来表示,这两个向量的长度与BERT的输出相同。
假设BERT的输出是768维的向量,这两个向量也是768维的向量。那么,如何使用这两个向量?
首先,计算这个橙色向量和那些与文件相对应的输出向量的内积,由于有3个代表文章的标记,它将输出三个向量,计算这三个向量与橙色向量的内积,你将得到三个值,然后将它们通过softmax函数,你将得到另外三个值。这个内积和attention很相似,你可以把橙色部分看成是query,黄色部分看成是key,这是一个attention,那么我们应该尝试找到分数最大的位置,就是这里,橙色向量和d2的内积,如果这是最大值,s应该等于2,你输出的起始位置应该是2。
bert为什么会有用
“为什么BERT有用?”
最常见的解释是,当输入一串文本时,每个文本都有一个对应的向量。对于这个向量,我们称之为embedding。
它的特别之处在于,这些向量代表了输入词的含义。例如,模型输入 “台湾大学”(国立台湾大学),输出4个向量。这4个向量分别代表 “台”、”湾”、”大 “和 “学”
更具体地说,如果你把这些词所对应的向量画出来,或者计算它们之间的距离
你会发现,意思比较相似的词,它们的向量比较接近。例如,水果和草都是植物,它们的向量比较接近。但这是一个假的例子,我以后会给你看一个真正的例子。”鸟 “和 “鱼 “是动物,所以它们可能更接近。
你可能会问,中文有歧义,其实不仅是中文,很多语言都有歧义,BERT可以考虑上下文,所以,同一个词,比如说 “苹果”,它的上下文和另一个 “苹果 “不同,它们的向量也不会相同。
水果 “苹果 “和手机 “苹果 “都是 “苹果”,但根据上下文,它们的含义是不同的。所以,它的向量和相应的embedding会有很大不同。水果 “苹果 “可能更接近于 “草”,手机 “苹果 “可能更接近于 “电”。
现在我们看一个真实的例子。假设我们现在考虑 “苹果 “这个词,我们会收集很多有 “苹果 “这个词的句子,比如 “喝苹果汁”、”苹果Macbook “等等。然后,我们把这些句子放入BERT中。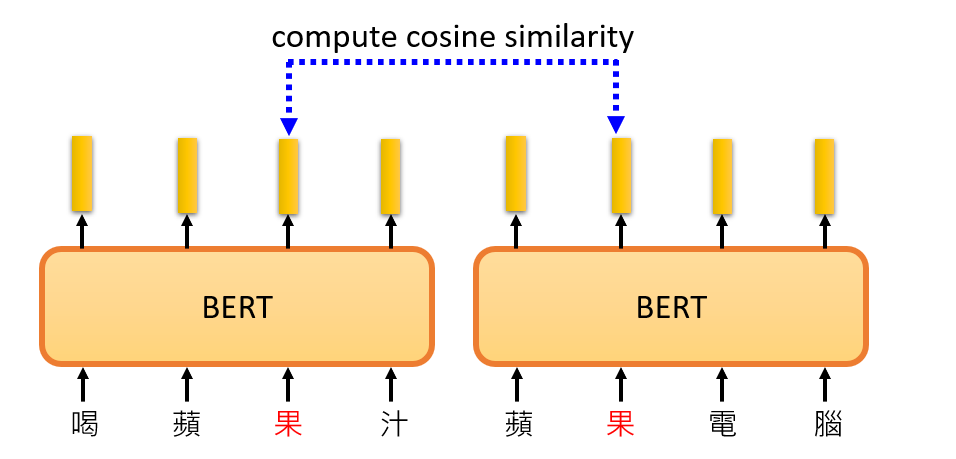
接下来,我们将计算 “苹果 “一词的相应embedding。输入 “喝苹果汁”,得到一个 “苹果 “的向量。为什么不一样呢?在Encoder中存在Self-Attention,所以根据 “苹果 “一词的不同语境,得到的向量会有所不同。接下来,我们计算这些结果之间的cosine similarity,即计算它们的相似度。
结果是这样的,这里有10个句子
- 前5个句子中的 “苹果 “代表可食用的苹果。例如,第一句是 “我今天买了苹果吃”,第二句是 “进口富士苹果平均每公斤多少钱”,第三句是 “苹果茶很难喝”,第四句是 “智利苹果的季节来了”,第五句是 “关于进口苹果的事情”,这五个句子都有 “苹果 “一词,
- 后面五个句子也有 “苹果 “一词,但提到的是苹果公司的苹果。例如,”苹果即将在下个月发布新款iPhone”,”苹果获得新专利”,”我今天买了一部苹果手机”,”苹果股价下跌”,”苹果押注指纹识别技术”,共有十个 “苹果”
计算每一对之间的相似度,得到一个10×10的矩阵。相似度越高,这个颜色就越浅。所以,自己和自己之间的相似度一定是最大的,自己和别人之间的相似度一定是更小的。
但前五个 “苹果 “和后五个 “苹果 “之间的相似度相对较低。
BERT知道,前五个 “苹果 “是指可食用的苹果,所以它们比较接近。最后五个 “苹果 “指的是苹果公司,所以它们比较接近。所以BERT知道,上下两堆 “苹果 “的含义不同。
BERT的这些向量是输出向量,每个向量代表该词的含义。BERT在填空的过程中已经学会了每个汉字的意思。”,也许它真的理解了中文,对它来说,汉字不再是毫无关联的,既然它理解了中文,它就可以在接下来的任务中做得更好。
那么接下来你可能会问,”为什么BERT有如此神奇的能力?”,为什么……,为什么它能输出代表输入词含义的向量? 这里,约翰-鲁伯特-弗斯,一位60年代的语言学家,提出了一个假说。他说,要知道一个词的意思,我们需要看它的 “Company“,也就是经常和它一起出现的词汇,也就是它的上下文。
一个词的意思,取决于它的上下文
- 所以以苹果(apple)中的果字为例。如果它经常与 “吃”、”树 “等一起出现,那么它可能指的是可食用的苹果。
- 如果它经常与电子、专利、股票价格等一起出现,那么它可能指的是苹果公司
当我们训练BERT时,我们给它w1、w2、w3和w4,我们覆盖w2,并告诉它预测w2,而它就是从上下文中提取信息来预测w2。所以这个向量是其上下文信息的精华,可以用来预测w2是什么。
这样的想法在BERT之前已经存在了。在word embedding中,有一种技术叫做CBOW。
Multi-lingual BERT(多语言的bert)
它是由很多语言来训练的,比如中文、英文、德文、法文等等,用填空题来训练BERT,这就是Multi-lingual BERT的训练方式。
google训练了一个Multi-lingual BERT,它能够做这104种语言的填空题。神奇的地方来了,如果你用英文问答数据训练它,它就会自动学习如何做中文问答
它是可以被验证的。我们实际上做了一些验证。验证的标准被称为Mean Reciprocal Rank,缩写为MRR。我们在这里不做详细说明。你只需要知道,MRR的值越高,不同embedding之间的Alignment就越好。
更好的Alignment意味着,具有相同含义但来自不同语言的词将被转化为更接近的向量。如果MRR高,那么具有相同含义但来自不同语言的词的向量就更接近。

若有收获,就点个赞吧
0 人点赞
