what’s transformer
Transformer就是一个,Sequence-to-sequence的model,他的缩写,我们会写做Seq2seq,那Sequence-to-sequence的model。
Encoder-Decoder
一般的seq2seq’s model,它裡面会分成两块 一块是Encoder,另外一块是Decoder。
真正的transformer架构

Encoder
seq2seq model Encoder要做的事情,就是给一排向量,输出另外一排向量,现在的Encoder裡面,会分成很多很多的block。
每一个block都是输入一排向量,输出一排向量,你输入一排向量 第一个block,第一个block输出另外一排向量,再输给另外一个block,到最后一个block,会输出最终的vector sequence,每一个block 其实,并不是neural network的一层。
每一个block裡面做的事情,是好几个layer在做的事情,在transformer的Encoder裡面,每一个block做的事情,大概是这样子的。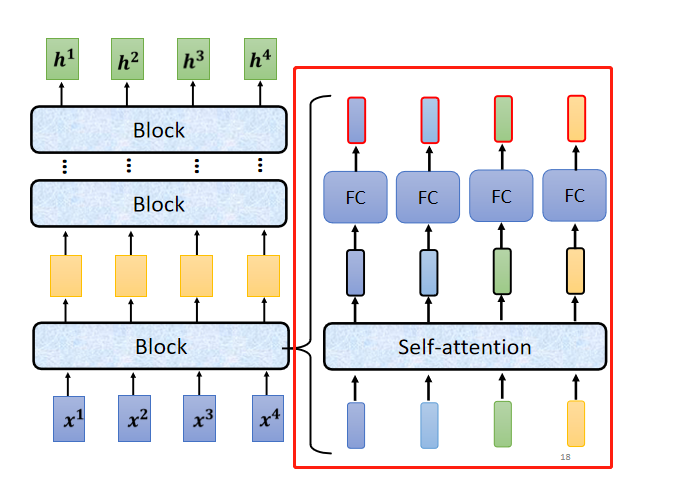
具体每个block做的内容
先做一个self-attention,然后把self-attention的输出和输入相加(这样子的network架构,叫做residual connection),相加后的结果再进行normalization,这个标准化是每个向量进行标准化,而非每个向量的维度进行标准化。之后再接入一个FC网络,同样也要做一次residual connection,和normalization。
Decoder
Autoregressive
Encoder 做的事情,就是输入一个 Vector Sequence,输出另外一个 Vector Sequence。
接下来,就轮到 Decoder 运作了,Decoder 要做的事情就是產生输出,也就是產生语音辨识的结果, Decoder 怎麼產生这个语音辨识的结果。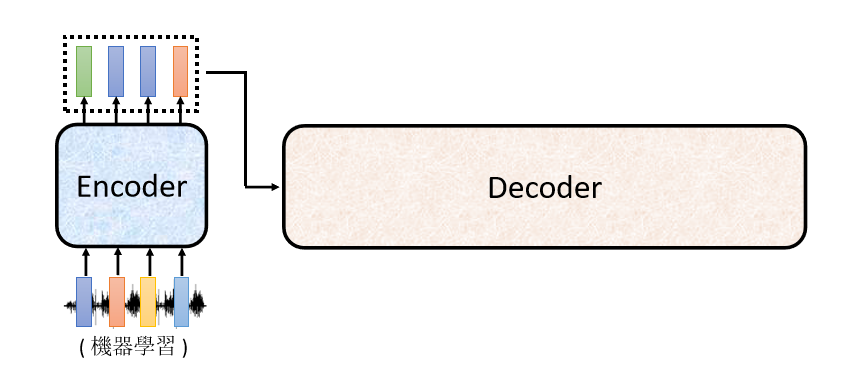
Decoder 怎麼產生一段文字?首先,你要先给它一个特殊的符号,这个特殊的符号,代表开始,在助教的投影片裡面,是写 Begin Of Sentence,缩写是 BOS。
在这个机器学习裡面,假设你要处理 NLP 的问题,每一个 Token,你都可以把它用一个 One-Hot 的 Vector 来表示,One-Hot Vector 就其中一维是 1,其他都是 0,所以 BEGIN 也是用 One-Hot Vector 来表示,其中一维是 1,其他是 0
接下来Decoder 会吐出一个向量,这个 Vector 的长度很长,跟你的 Vocabulary 的 Size 是一样的。

然后接下来,你把“机”当做是 Decoder 新的 Input,原来 Decoder 的 Input,只有 BEGIN 这个特别的符号,现在它除了 BEGIN 以外,它还有“机”作為它的 Input。
然后这个 Process ,就反覆持续下去,这边有一个关键的地方,我们特别用红色的虚线把它标出来。
也就是说 Decoder 看到的输入,其实是它在前一个时间点,自己的输出,Decoder 会把自己的输出,当做接下来的输入。
Decoder内部的结构
如果我们把 Decoder 中间这一块,中间这一块把它盖起来,其实 Encoder 跟 Decoder,并没有那麼大的差别。
Encoder 这边,Multi-Head Attention,然后 Add & Norm,Feed Forward,Add & Norm,重复 N 次,Decoder 其实也是一样。Decoder 这边,Multi-Head Attention 这一个 Block 上面,还加了一个 Masked。
早期的self-attention
当我们把 Self-Attention,转成 Masked Attention 的时候,它的不同点是,现在我们不能再看右边的部分,也就是產生b1的时候,我们只能考虑a1的资讯,你不能够再考虑 a2,a3,a4。
讲了 Decoder 的运作方式,但是这边,还有一个非常关键的问题,Decoder 必须自己决定,输出的 Sequence 的长度,可是到底输出的 Sequence 的长度应该是多少,我们不知道!
所以我们要让 Decoder 做的事情,也是一样,要让它可以输出一个断,所以你要特别准备一个特别的符号,这个符号,就叫做断,我们这边,用 END 来表示这个特殊的符号。
Decoder – Non-autoregressive (NAT)
就假设我们现在產生是中文的句子,它不是依次产生一个字,它是一次把整个句子都产生出来
NAT 的 Decoder可能吃的是一整排的 BEGIN 的 Token,你就把一堆一排 BEGIN 的 Token 都丢给它,让它一次产生一排 Token 就结束了。
举例来说,如果你丢给它 4 个 BEGIN 的 Token,它就產生 4 个中文的字,变成一个句子,就结束了,所以它只要一个步骤,就可以完成句子的生成。
这边你可能会问一个问题:刚才不是说不知道输出的长度应该是多少吗,那我们这边怎麼知道 BEGIN 要放多少个,当做 NAT Decoder 的输入?
没错 这件事没有办法很自然的知道,没有办法很直接的知道,所以有几个,所以有几个做法
- 一个做法是,你另外learn一个 Classifier,这个 Classifier ,它吃 Encoder 的 Input,然后输出是一个数字,这个数字代表 Decoder 应该要输出的长度,这是一种可能的做法。
另一种可能做法就是,你就不管三七二十一,给它一堆 BEGIN 的 Token,你就假设说,你现在输出的句子的长度,绝对不会超过 300 个字,你就假设一个句子长度的上限,然后 BEGIN ,你就给它 300 个 BEGIN,然后就会输出 300 个字嘛,然后,你再看看什麼地方输出 END,输出 END 右边的,就当做它没有输出,就结束了,这是另外一种处理 NAT 的这个 Decoder,它应该输出的长度的方法。
Encoder-Decoder
接下来就要讲Encoder 跟 Decoder它们中间是怎麼传递资讯的了,也就是我们要讲,刚才我们刻意把它遮起来的那一块。
这块叫做 Cross Attention,它是连接 Encoder 跟 Decoder 之间的桥梁。那这一块里面啊,会发现有两个输入来自于Encoder,Encoder 提供两个箭头,然后 Decoder 提供了一个箭头,所以从左边这两个箭头,Decoder 可以读到 Encoder 的输出。
那这个模组实际上是怎麼运作的呢,那我们就实际把它运作的过程跟大家展示一下
这个是你的 Encoder
1输入一排向量,输出一排向量,我们叫它 a1,a2,a3
2接下来 轮到你的 Decoder,你的 Decoder 呢,会先吃 BEGIN 当做,BEGIN 这个 Special 的 Token,那 BEGIN 这个 Special 的 Token 读进来以后,你可能会经过 Self-Attention,这个 Self-Attention 是有做 Mask 的,然后得到一个向量,就是 Self-Attention 就算是有做 Mask,还是一样输入多少长度的向量,输出就是多少向量,所以输入一个向量 输出一个向量,然后接下来把这个向量呢,乘上一个矩阵做一个 Transform,得到一个 Query 叫做 q
3然后这边的a1,a2,a3呢,也都產生 Key,Key1 Key2 Key3,那把这个 q 跟 ,去计算 Attention 的分数,得到α1,α2,α3,当然你可能一样会做 Softmax,把它稍微做一下 Normalization,所以我这边加一个 ‘,代表它可能是做过 Normalization
接下来再把α1,α2,α3,就乘上v1,v2,v2,再把它 Weighted Sum 加起来会得到 v
那这一个 V,就是接下来会丢到 Fully-Connected 的,Network 做接下来的处理,那这个步骤就是 q 来自於 Decoder,k 跟 v 来自於 Encoder,这个步骤就叫做 Cross Attention。
当然这个,就现在假设產生第二个,第一个这个中文的字產生一个“机”,接下来的运作也是一模一样的。
training
在训练的时候,每一个输出都会有一个 Cross Entropy,每一个输出跟 One-Hot Vector,跟它对应的正确答案都有一个 Cross Entropy,我们要希望所有的 Cross Entropy 的总和最小,越小越好
所以这边做了四次分类的问题,我们希望这些分类的问题,它总合起来的 Cross Entropy 越小越好,还有 END 这个符号。
那这个就是 Decoder 的训练:把 Ground Truth ,正确答案给它,希望 Decoder 的输出跟正确答案越接近越好
那这边有一件值得我们注意的事情,在训练的时候我们会给 Decoder 看正确答案,也就是我们会告诉它说在已经有 “BEGIN”,在有”机”的情况下你就要输出”器”
- 有 “BEGIN” 有”机” 有”器”的情况下输出”学”
- 有 “BEGIN” 有”机” 有”器” 有”学”的情况下输出”习”
- 有 “BEGIN” 有”机” 有”器” 有”学” 有”习”的情况下,你就要输出”断”
在 Decoder 训练的时候,我们会在输入的时候给它正确的答案,那这件事情叫做 Teacher Forcing。

若有收获,就点个赞吧
0 人点赞
