RISC-V版
计算机抽象及相关技术
知识点
计算机组成:
- 输入
- 输出
- 存储器
- 数据通路
- 控制器
数据通路和控制器合称处理器响应时间/挂钟时间/运行时间:完成某项任务所需的总时间
降低响应时间总可以增大吞吐率- 吞吐率/带宽:单位时间内完成总工作量
- 机器字长:计算机进行一次整数运算所能处理的二进制数据位数
- 数据通路带宽:外部数据总线一次并行传送信息的位数
- 主存容量:
。MAR为16位,MDR为32位,则为
位
八个伟大思想
- 面向摩尔定律的设计:芯片上所集成的晶体管资源每18至24个月翻一番
- 使用抽象简化设计:隐藏低层细节以提供给高层一个更简单的模型
- 加速经常性事件
- 通过并行提高性能
- 通过流水线提高性能
- 通过预测提高性能
- 存储层次
- 通过冗余提高可靠性:引入冗余组件在系统发生故障时可以替代失效组件并帮助检测故障
性能运算
指令
知识点
- 1字节 = 8位;1字 = 4字节;双字 = 8字节 = 64位
- 32个64位寄存器
- 大端方式:高位放在数据存储器中的低位;小端方式:低位放在数据存储器中的低位

- RISC-V使用以字节为单位寻址
eg.对于双字数组A,编译f = g + A[8],其中f,g,A的基址分别存放在x20,x21,x22中
ld x9, 64(x22)add x20, x21, x9
- RISC-V的指令都是32位长
- 跳转-链接指令:
jal x1, ProcedureAddress跳转至ProcedureAddress并写入x1
jalr x0, 0(x1)跳转至返回地址jal x0, Label无条件跳转beq x0, x0, Label无条件跳转 - 过程帧(活动记录):栈中包含过程所保存的寄存器和局部变量的段
- 帧指针指向帧的第一个双字(通常是保存的参数寄存器)
- 读取指令有有符号类型、无符号类型:例如lbu读取1字节并经过符号扩展至8字节
- 存储指令只有有符号类型,因为其存储寄存器的低位端,不需要考虑符号
- 大立即数(79页):
- lui指令将31位到12位加载到寄存器
- 将31位扩展至高32位
- addi加载低12位
如果加载的大立即数第11位为1,则会出现addi加负数的情况,需要lui时+1。以加载00101111 11111111为例(高位省略):
如果lui此时加10,则addi相当于-1,最终加载的是011111 11111111。加1后则为110000 00000000 - 1 = 101111 11111111,加载正常。lui x19, 11 addi x19, 111111111111长距离跳转:
- lui将地址的第12位至31位写入临时寄存器
- jalr将地址的低12位加到临时寄存器并跳转
远距离无条件跳转,将SB型指令改为UJ型。例如
beq x10, x0, L1:bne x10, x0, L2 jal x0, L1 L2:寻址模式:
- 立即数寻址
- 寄存器寻址
- 基址或偏移寻址
- PC相对寻址
- 保留加载
lr.d rd, (rs1),将rs1加载至rd - 条件存储
sc.d rd, rs2, (rs1),将rs2存储进rs1,若lr.d执行后rs1值不变则存储成功,rd为0;如果rs1值变化则存储失败,rd为1 - C程序变为可执行程序过程:
- 编译:将高级语言变为汇编语言程序
- 汇编:将汇编程序变为目标文件:机器语言模块
- 链接:将多个独立汇编的机器语言程序缝合生成可执行文件(静态)
- 加载器:将可执行文件加载到内存中
- 动态链接库:
- 避免由于静态链接所有库文件导致镜像膨胀
- 可以自动获取新版本的库程序
- 只有链接/加载库过程时才会被调用
- 三条设计原则:
- 简单源于规整
- 更少则更快
- 优秀的设计需要适当的折中
指令表示
R型(用于寄存器)
| funct7 | rs2 | rs1 | funct3 | rd | opcode |
|---|---|---|---|---|---|
| 7位 | 5位 | 5位 | 3位 | 5位 | 7位 |
I型(用于带常数的算术指令)
| immediate | rs1 | funct3 | rd | opcode |
|---|---|---|---|---|
| 12位(补码值) | 5位 | 3位 | 5位 | 7位 |
S型
| immediate[11:5] | rs2 | rs1 | funct3 | immediate[4:0] | opcode |
|---|---|---|---|---|---|
| 7位 | 5位 | 5位 | 3位 | 5位 | 7位 |
eg.读取数值sd x9, 240(x10),左边7位为111(十进制为8),右边5位为10000(十进制为16)。相当于240右移5位,即:
注:寄存器x9和x10存放于rs2和rs1
ld和sd指令中基址寄存器均为rs1
SB型(分支指令)
| imm[12] | imm[10:5] | rs2 | rs1 | funct3 | imm[4:1] | imm[11] | opcode |
|---|---|---|---|---|---|---|---|
| 1位 | 6位 | 5位 | 5位 | 3位 | 4位 | 1位 | 7位 |
12位立即数,忽略0位,只能跳转至偶数地址,可跳转至当前指令个字的地方
UJ型(jal)
| imm[20] | imm[10:1] | imm[11] | imm[19:12] | rd | opcode |
|---|---|---|---|---|---|
| 1位 | 10位 | 1位 | 8位 | 5位 | 7位 |
20位立即数,忽略0位,只能跳转至偶数地址,可跳转至当前指令个字的地方
指令汇总
84页
算数运算
知识点
- 上溢:正指数太大而无法用指数字段表示的情况
- 下溢:负指数太大而无法用指数字段表示的情况
- 单精度浮点:32位字段,1位符号,8位指数,23位尾数
- 双精度浮点:64位字段,1位符号,11位指数,52位尾数
- 可以直接对浮点表示下的数比较,比较结果即为浮点数大小比较结果
- 由于指数段存在有符号数,例如
相比较,高位分别为
,这不便于直接比较(指数为-1的数在浮点表示法中更大),所以引入偏移量
- 单精度偏移量为127,双精度偏移量为1023
- 单精度指数部分为00000001到11111110,即
- 浮点寄存器f0没有硬连接到常数0,单精度值存在低32位
| 单精度 | | 双精度 | | 表示对象 | | —- | —- | —- | —- | —- | | 指数 | 尾数 | 指数 | 尾数 | | | 0 | 0 | 0 | 0 | 0 | | 0 | 非0 | 0 | 非0 | 正负非规格化数 | | 1~254 | 任意 | 1~2045 | 任意 | 正负浮点数 | | 255 | 0 | 2047 | 0 | 正负无穷 | | 255 | 非0 | 2047 | 非0 | NaN |
增加保护位、舍入位、粘滞位用于精准计算
溢出检测
- 有符号溢出:
正数相加;负数相加
;正数减负数
;负数减正数
- 无符号溢出:
- 和小于任何加数——加法溢出
- 差大于被减数——减法溢出
- mulhu的结果为0,64位乘法不溢出
- mulh结果的所有位都是mul结果的符号位的复制,则64位有符号乘法没有溢出
处理器
知识点
- 数据通路单元
- 指令存储器:存程序的指令
- ALU和加法器
- 立即数生成单元:将32位指令输入,扩展成64位立即数
- 寄存器堆
- 数据存储器
- 数据通路中:
- 计算beq地址偏移时需要左移1位,因为在指令中就没有0位。这样可以增大跳转范围
- ALU control仅在R型指令需要接收funct3、funct7指令;sd和ld时只需要接收ALUOp信号
- ld指令用时最长,5个部分都经历了
- 单周期所有指令使用同一个周期,违反了加速大概率事件原则
流水线
- 流水线通过增大吞吐量来提速,指令时间没有降低
- 加速比约等于流水线级数
- 面向流水线的RISC-V指令集特点:
- 所有指令均为32位:便于在一个时钟周期内获取指令和解码
- 指令格式少,源寄存器和目标寄存器位置相同。可以在一个阶段解码和读取寄存器
- 可以在第三个阶段(ALU)计算地址,在第四个阶段(Memory Data Access)访存
- 控制信号:
- EX阶段信号:ALUOp、ALUSrc
- MEM阶段信号:Branch、MemRead、MemWrite
- WB阶段信号:MemtoReg、RegWrite
结构风险
- 所需调用的资源占用
- 例如加载/存储需要进行数据访问,而指令的获取不得不在访存的周期停止
- 流水线数据通路需要分离的指令/数据存储器/数据缓存
数据风险
- 需要等待上一条指令来完成其数据的读或写
- R型指令之间可以通过旁路前递数据
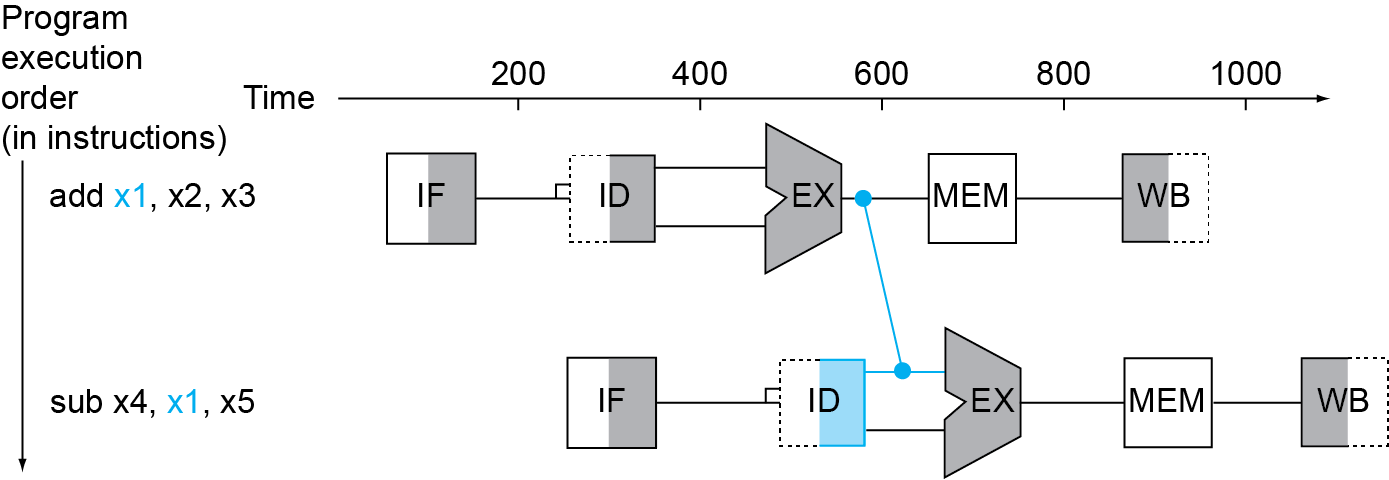
- ld后的数据风险必须停顿一次

- 当ld的下一条指令执行到ID,发现和ld的目标寄存器冲突时,冒险发生,停顿一次。此时ID阶段的控制信号置零并将该阶段的指令过滤。
- 数据前递的两种情况,EX/MEM阶段前递和MEM/WB阶段前递:
- 1a. EX/MEM.RegisterRd = ID/EX.RegisterRs1
- 1b. EX/MEM.RegisterRd = ID/EX.RegisterRs2
- 2a. MEM/WB.RegisterRd = ID/EX.RegisterRs1
- 2b. MEM/WB.RegisterRd = ID/EX.RegisterRs2
- EX前递的三个条件:
- EX阶段写寄存器
- EX阶段的目标寄存器不为x0(因为x0不会被改变)
- EX阶段的目标寄存器 = ID阶段(后一条指令取指)的源寄存器
- MEM前递的四个条件:
- MEM阶段写寄存器
- MEM阶段的目标寄存器不为x0
- 不是EX冒险
- MEM阶段的目标寄存器 = ID阶段(后面第二条指令取指)的源寄存器
- WB阶段不存在冒险,因为ID阶段和WB阶段写入同一个寄存器时内部实现一个前递,能够处理好结果
控制风险
- 控制的指令由之前的指令执行结果所决定
- 分支预测:
- 静态分支预测:
- 循环:预测向后跳转总是发生
- if分支:预测向前跳转总是不发生(顺序执行)
- 动态分支预测:通过硬件衡量实际分支行为
- 静态分支预测:
- 若假设分支不发生,则每次发生需要清除时的IF、ID、EX阶段的指令。可以将分支地址计算和分支判断提前至ID阶段,缩短分支延迟
- 分支预测缓存:按照分支指令的低位地址定位的缓存,包含1个或多个bit表示分支最近是否发生跳转
- 分支目标缓存:缓存分支目标PC或者目标指令的结构,可以在发生跳转时直接读取,减少1个时钟周期的消耗
- 1bit存储分支跳转信息的问题:当一个常态化的事件中插进一个非常态化事件,会导致预测错误两次。例如:9次跳转后发生1次不跳转,再发生9次跳转。不跳转发生时预测错误,更改分支预测缓存,再次跳转会导致又一次预测错误。
- 修正为有限状态机:只有在两次预测失败后才会改变预测结果

存储
知识点
- 存储类型分类:
- 随机存取
- 直接存储:磁盘。先直接定位至小区域,再顺序存取
- 顺序存取:磁带
- Cache-主存这一层次的作用是为了解决CPU和主存速度不匹配的问题
磁盘:
直接映射容量计算P271页
- 写穿透:每次写操作都会同时更新cache和下一级存储
- 写缓冲:设定一个缓冲器保存写回主存的数据,每次写操作同时写入cache和缓冲器,当缓冲器满了以后,处理器停顿流水线,缓冲器写入主存
- 写返回:写命中时,只修改cache的内容不立即写入主存,只当此行被换出时才写回主存。当写失效时,被替换的修改过的数据块存入写返回缓冲区,再由缓冲区写回主存
- 写分配:cache中分配一个数据块。写失效时先在主存块中更新,然后将数据写到cache中
- 非写分配:直接把数据写回主存而不加载数据到缓存
- 当写操作产生速度小于主存系统处理速度(写入主存速度)时,用写缓冲策略
- 当写操作产生速度大于等于主存系统处理速度(写入主存速度)时,用写返回策略
写穿透-非写分配,写返回-写分配
假设一:全写法和按写分配法搭配。
(1)第一次Cache写不命中,那么就要更新主存,同时调块入Cache。
(2)然后再对这个块写n次,这时由于(1)的按写分配法已经更新了Cache,此时写命中,那么要同时写主存和Cache各n次。
实际情况一:全写法和不按写分配搭配。
(1)第一次Cache未命中,更新主存,不调入Cache。
(2)再写n次,此时由于(1)未把主存块调入Cache,那就还是未命中,那么只写了主存n次。这2种情况相比,实际采取的搭配更有效率。
同理另外的一个假设和实际情况也可以得出类似结论。
知乎作者:超级大笨蛋
写返回-写分配时,若失效则从主存中将数据放入cache,再命中n次,只需要对cache修改n次,最后替换时再对主存写回
虚拟存储
- 根据虚拟地址给出对应的物理地址,并以此访问主存和辅存
- 虚拟存储中地址分为:
- 页号:表示页的数量
- 页内偏移:表示页内地址,可以反映页的大小
- 地址转换依靠页表进行,页表存放在主存中
- 虚拟存储采用写返回策略
重点
- 立即数只有加法,化减为加(加负数),为什么还会有sub指令?
立即数本身就包含在指令中,从一开始就知道正负,所以可以化加为减立即数本身就包含在指令中,从一开始就知道正负,所以可以化加为减。Sub指令是由人编写,变量的值则是读入到寄存器中进行的具体操作,此时编译器无法得知寄存器中数值的正负。
- 为什么没有sb,sh,sw存储的无符号版本呢?
存储字节/半字/字:存储最右边的8/16/32位,没有符号扩展的问题
- 对于手写汇编:
- 只要是调用了函数,就要把参数寄存器(x10,x11…)入栈,或者在调用之前把参数寄存器赋值给临时寄存器
- 注意循环体固定格式(书96、97页)
- 非流水线的时钟周期:所有步骤的和
- 流水线化的时钟周期:时钟周期最长的那一级的时间

若有收获,就点个赞吧
0 人点赞
