Lec 1-1
System I Review
杂项
- 计算机结构的体系
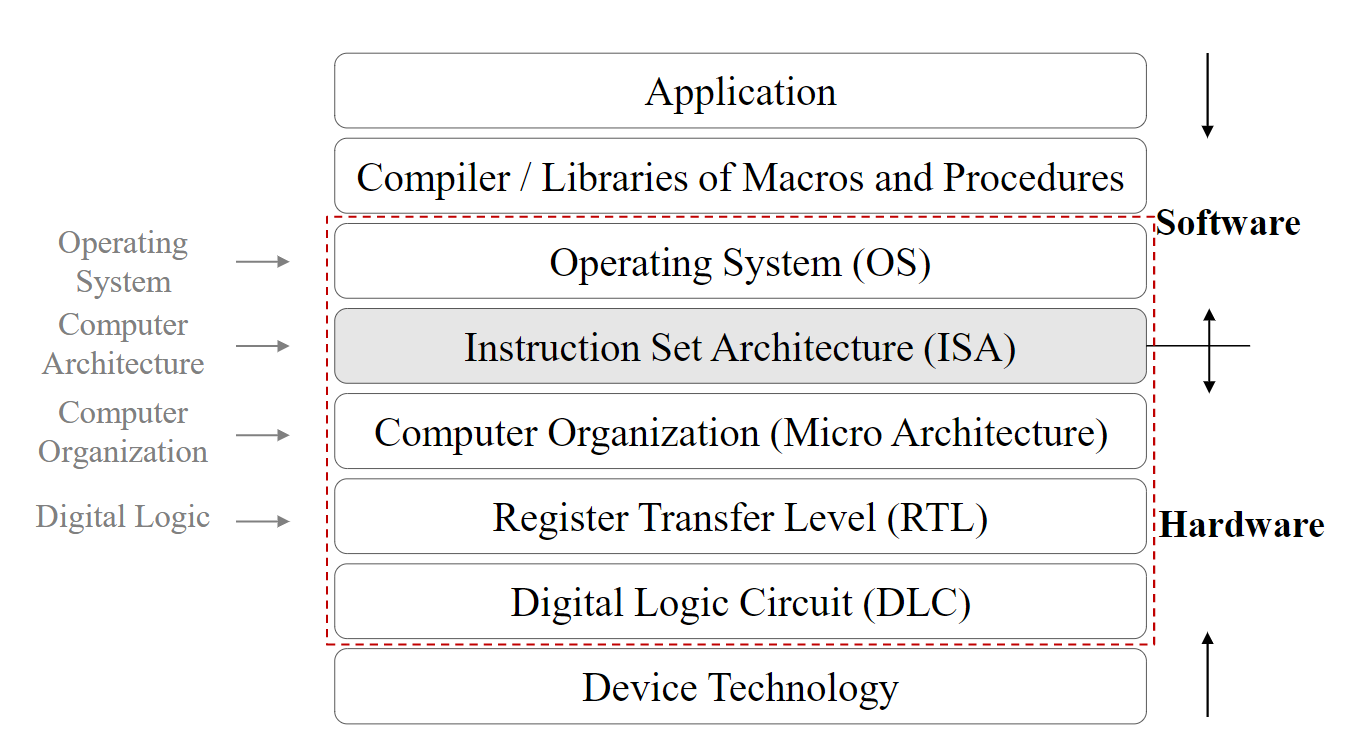
- CPU中包括Datapath,Control 和Cache memory因为main memory的速度很慢,Cache memory是一种为了让CPU能更快的取数据,制作出的一块速度极快但是容量极小的存储设备,且一般会分为三级,即L1 cache,L2 cache和L3 cache,其中,第一级速度最快,但容量最小
Istruction Set Principles
几种不同的架构
这里的三种架构是基于internal storage的,即数据是从memory或cache中取出的
主要不同是R型指令的形式不同
stack architecture
- Push:将数据从memory中取出,放到processor中
- Add:取出栈中顶层的两个数据,做相应的运算然后再放回栈中
- Pop:将数据从栈中取出
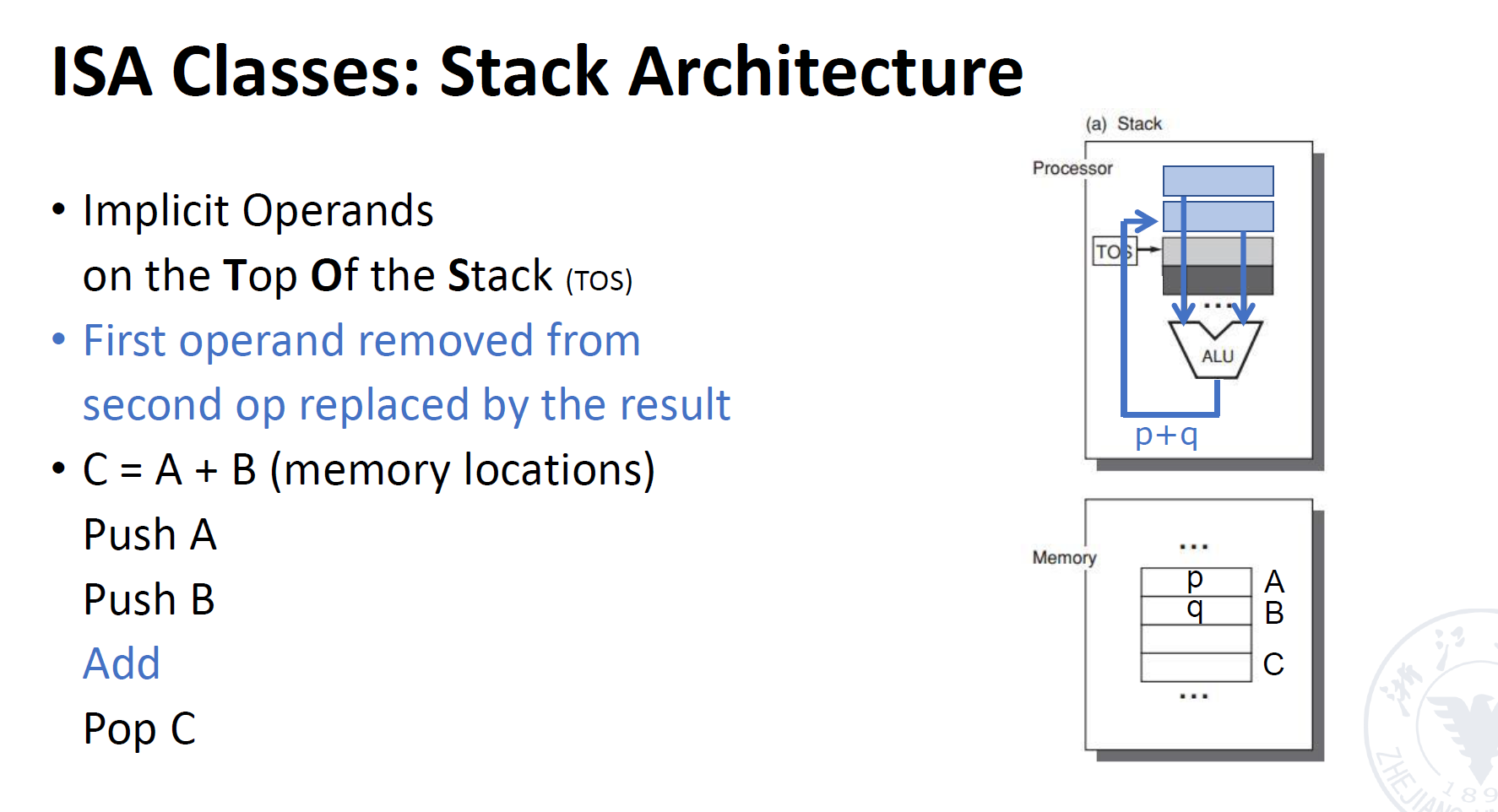
图中示例的为计算的过程
Accumulator Architecture
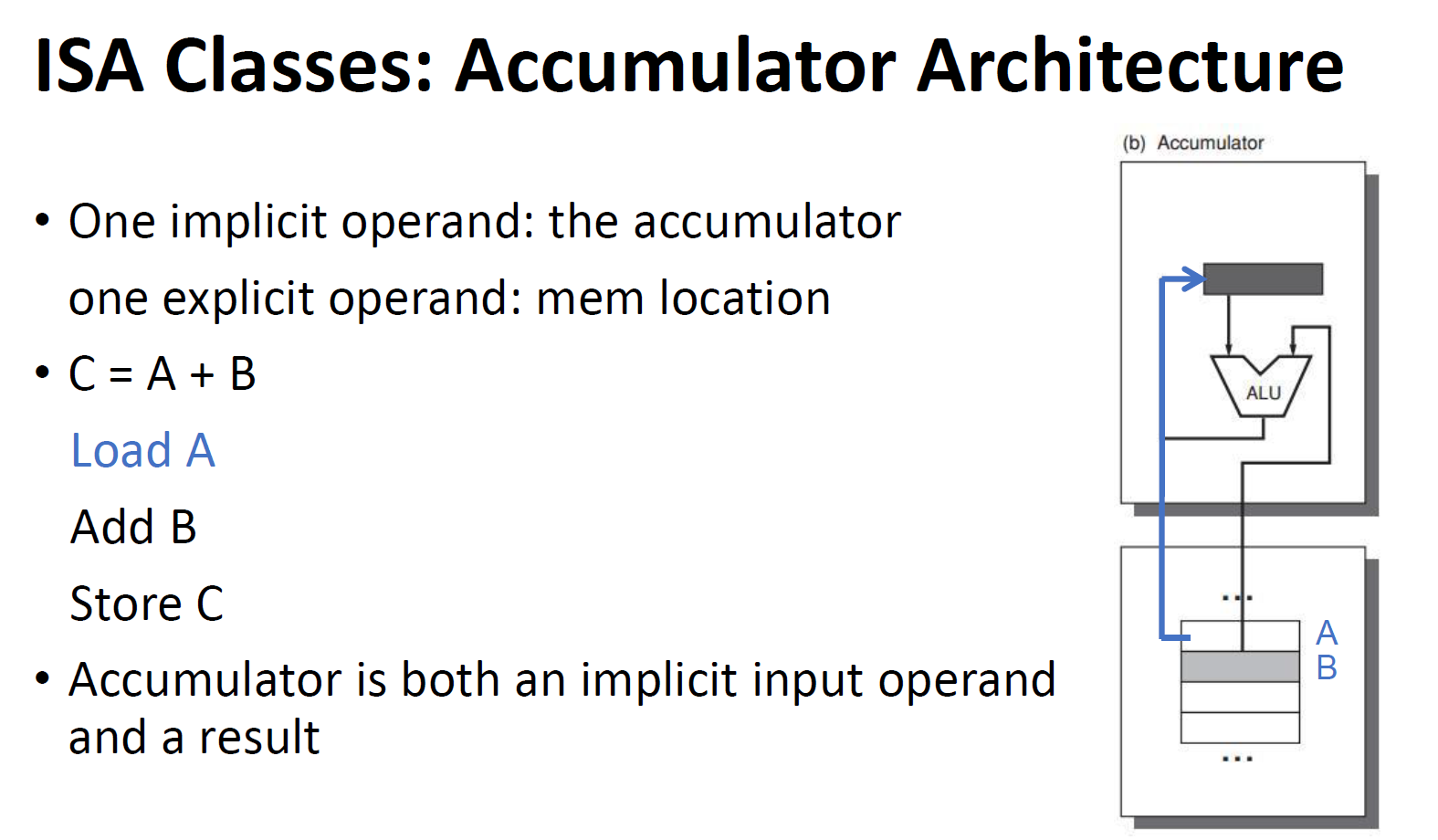
- 先将一个数据从内存中取出,放到Accumulator的一个操作数对于的位置上
- 然后将另一个数据从内存中取出,直接作为另一个操作数与之完成运算,并将运算结果放在ALU上面的那个放数据的地方
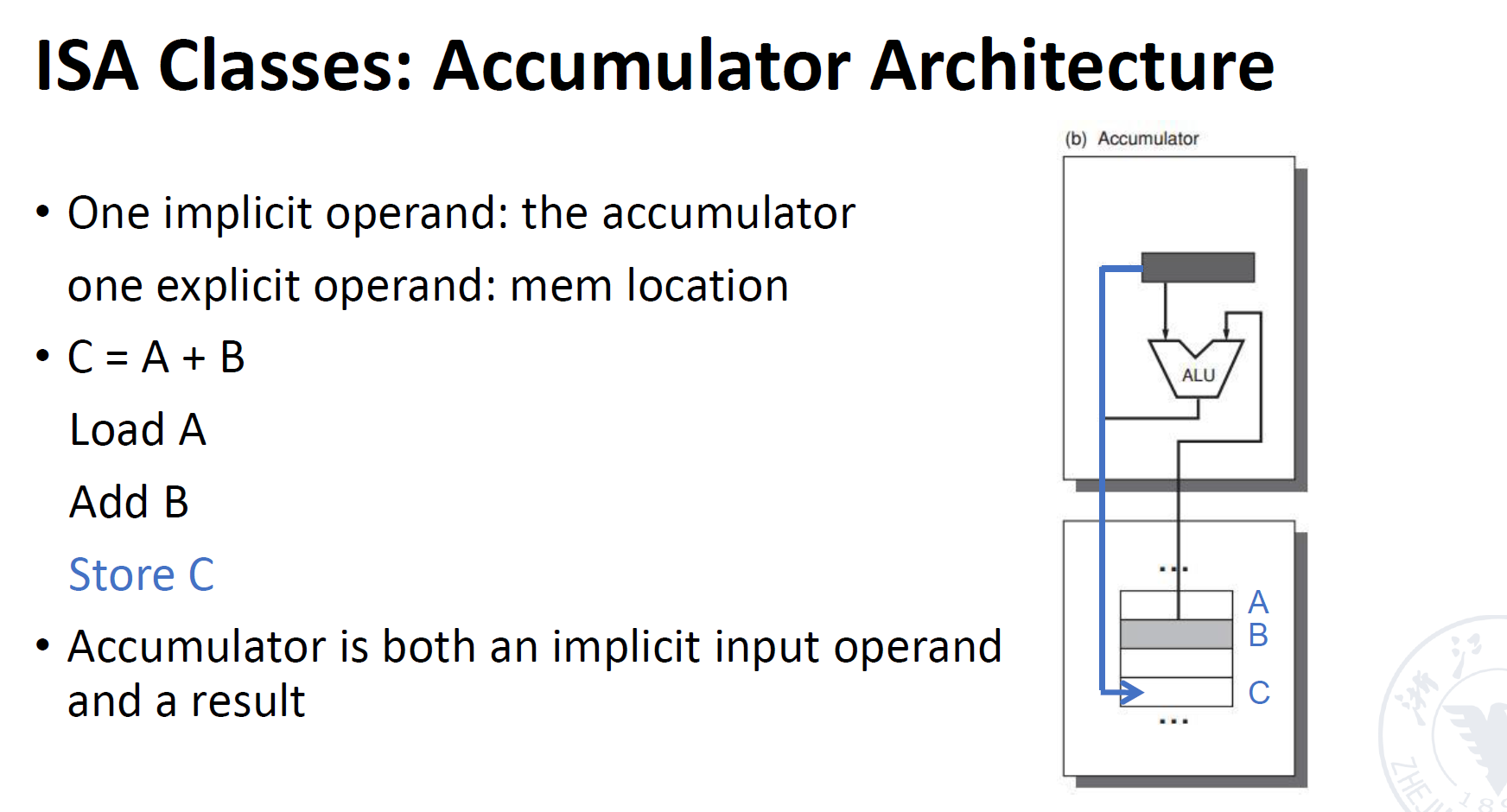
- 然后将数据从上面取出,放到C中,如下所示
General-Purpose Register Arch
即(Register-memory architecture),也被称作RM
即所有的指令都可以访问数据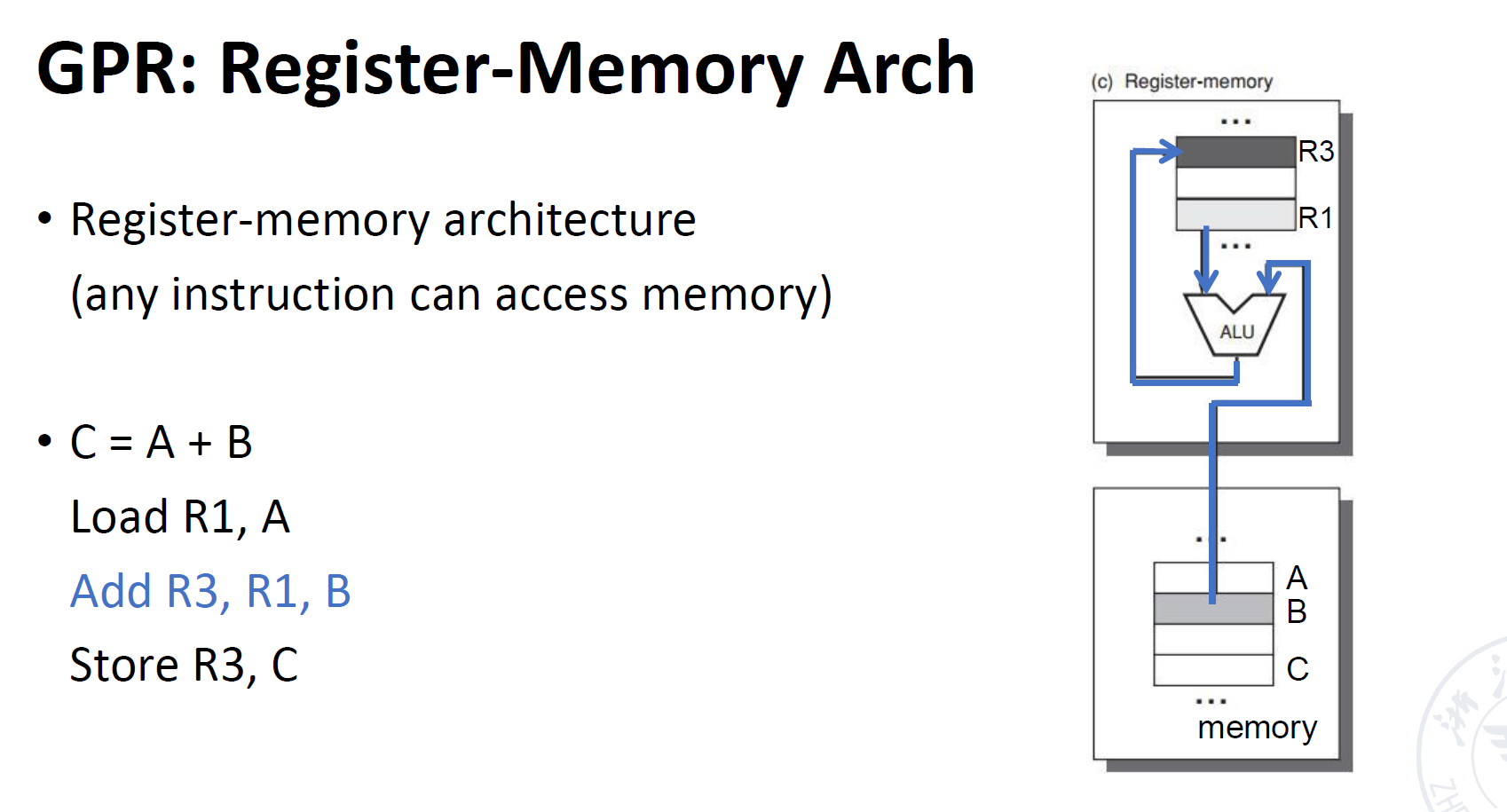
- 先将一个操作数从内存中取出,放到一个寄存器上
- 然后将另一个操作数从内存中取出,直接作为另一个操作数与第一个操作数(现在位于寄存器中)完成运算,并将运算结果放在另一个寄存器中
- 然后将数据从寄存器取出,放到C中
其实这里感觉和上面那中除了多了几个可以放数据的地方外没有什么差别
General-Purpose Register Arch
即(Load-Store Architecture),也被称作RR
这个操作与上面的区别就是将数据B也放在了一个寄存器中,然后再计算时只需要将这两寄存器的数据相加就好了
Lec 1-2
More about ISA
Byte addressing
- Byte - 8 bits
- half word - 16 bits
- word - 32 bits
- double word - 64 bits
小端规则,大端规则

RISC-V是小端序的
Caller saving和Calling saving

RISC-V 与之前架构的区别
- 与 CISC 的区别
- 与其他 RISC 的区别
 需要说明的是,基础的RISC-V指令集,比如RV32I,RV64I中,所有指令长度都是固定的32 bits, 但是标准的RiscV指令编码方案是支持其它指令长度的,只要指令长度是16 bits的倍数,这样就可以理解最后一句话了
需要说明的是,基础的RISC-V指令集,比如RV32I,RV64I中,所有指令长度都是固定的32 bits, 但是标准的RiscV指令编码方案是支持其它指令长度的,只要指令长度是16 bits的倍数,这样就可以理解最后一句话了- 且是开源的
寻址方式:
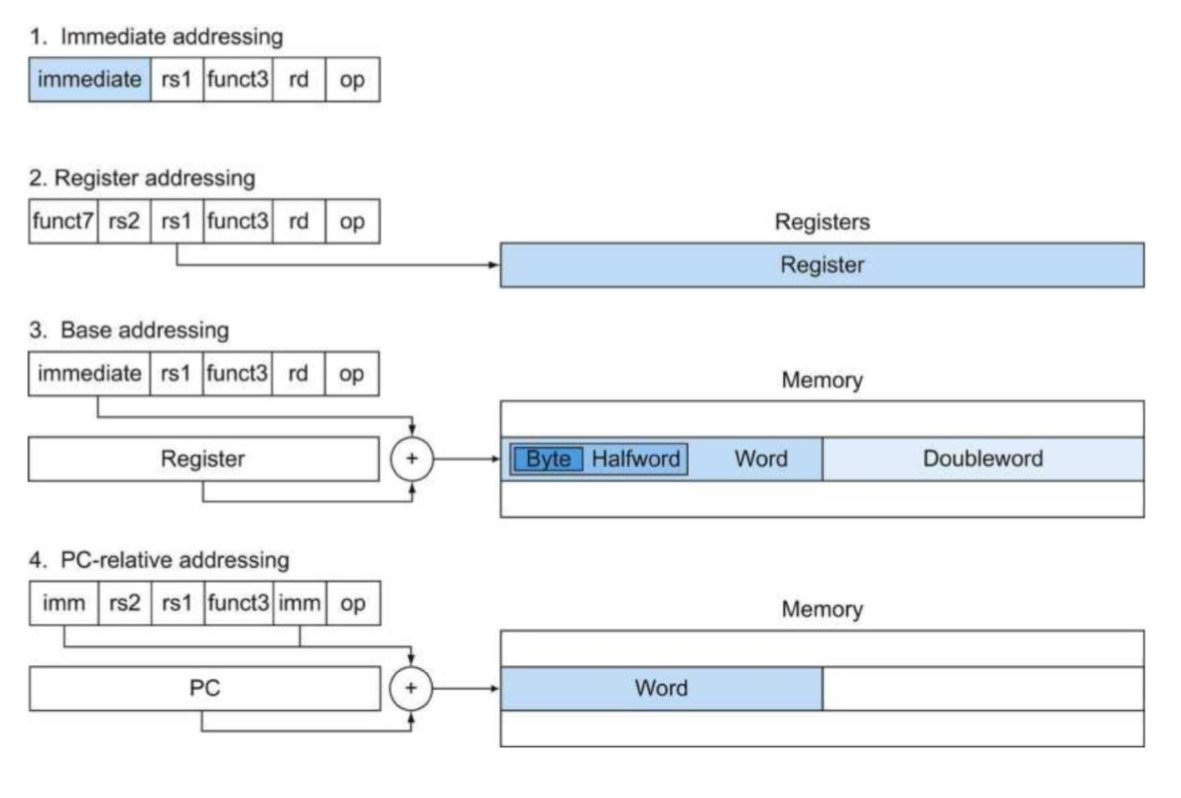
大致可以分为三类:
- 立即数的寻址
- 寄存器的寻址
- 存储器的寻址
寄存器的基本类别
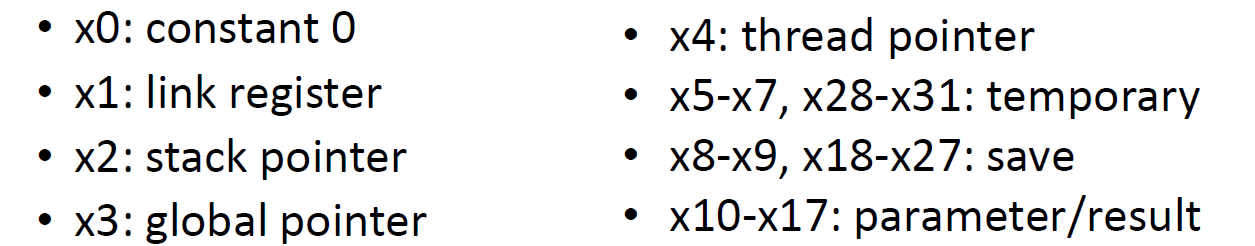
对应关系不用记,但是基本的类别还是要知道的
内存的操作数

上面的这个例子非常重要,尤其是要理解为什么offset为32

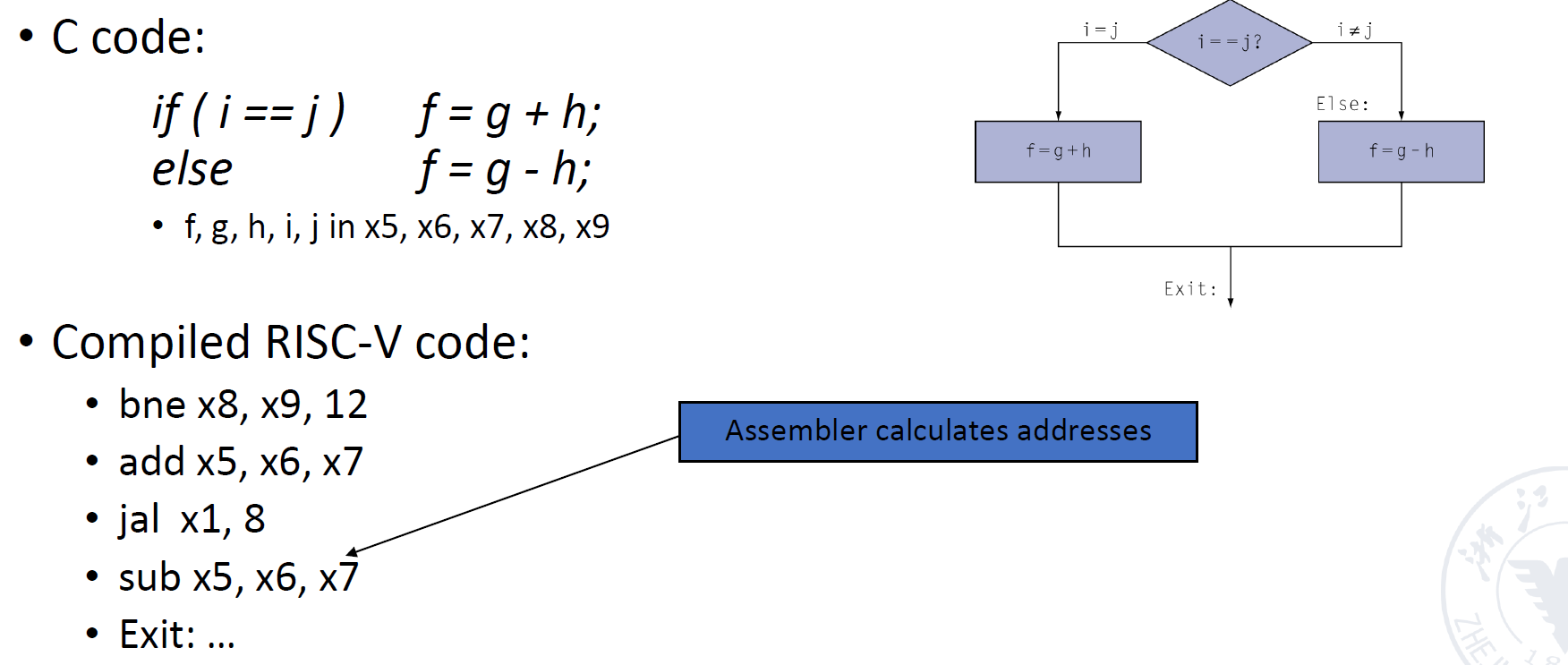
- 注意一下bne指令后的偏移地址,是以4为基本的偏移量的
(其实PPT上这里还有很长一段,但他复习课没说,我就认为不考了)

这个没考,但要有个了解
Lec2-1 Introduction of Pipeline
流水线的基本介绍
- 流水线的定义:将一条指令执行的若干过程分解成可以独立执行的过程,然后再采用重叠(overlapping)的方式来达到的一种可以以更高效率执行的方式
- 流水线的三条性质


- Pass time和Empty time

流水线的分类
- 静态流水线和动态流水线(都是Muti function pipeline)

- 静态流水线:只有当其中的一个function全部运行完之后才能切换到下一个流水线
- 动态流水线:在上一个功能没有结束之前,下一个功能也可以进行运行
- 示意图如下所示
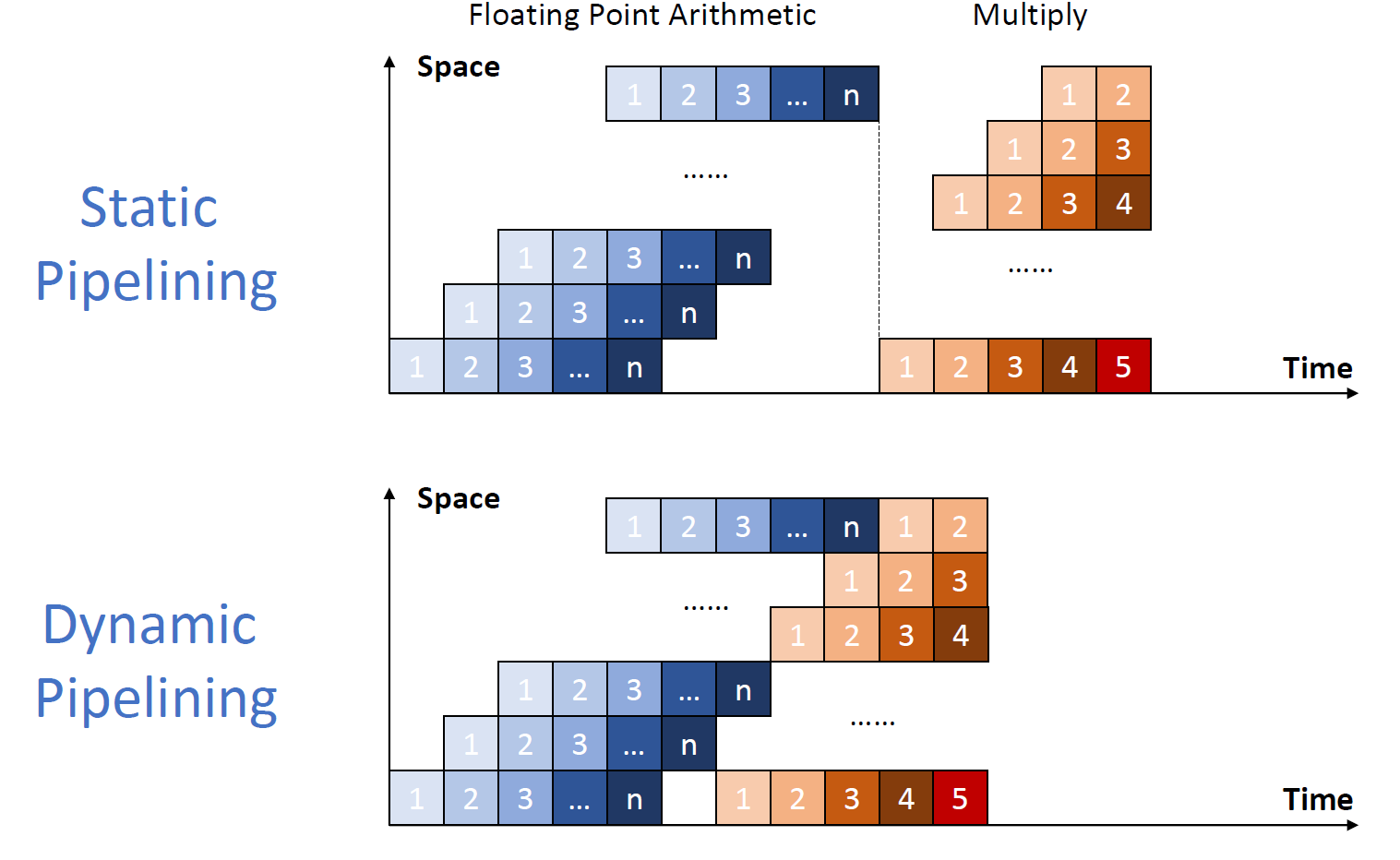
- operation, instruction and macro

- operation:即根据不同的操作,加法和乘法进行可以同时去做,实现operation的pipeline
- instruction:即根据指令来流水,例如做的lab
- macro:将不同的指令进行集合,形成一个宏去实现某一个特定的功能,宏和宏之间可以进行pipeline
Lec 2-2 流水线性能
- throughput(吞吐率)吞吐率 = 指令条数 / 流水线执行的时间
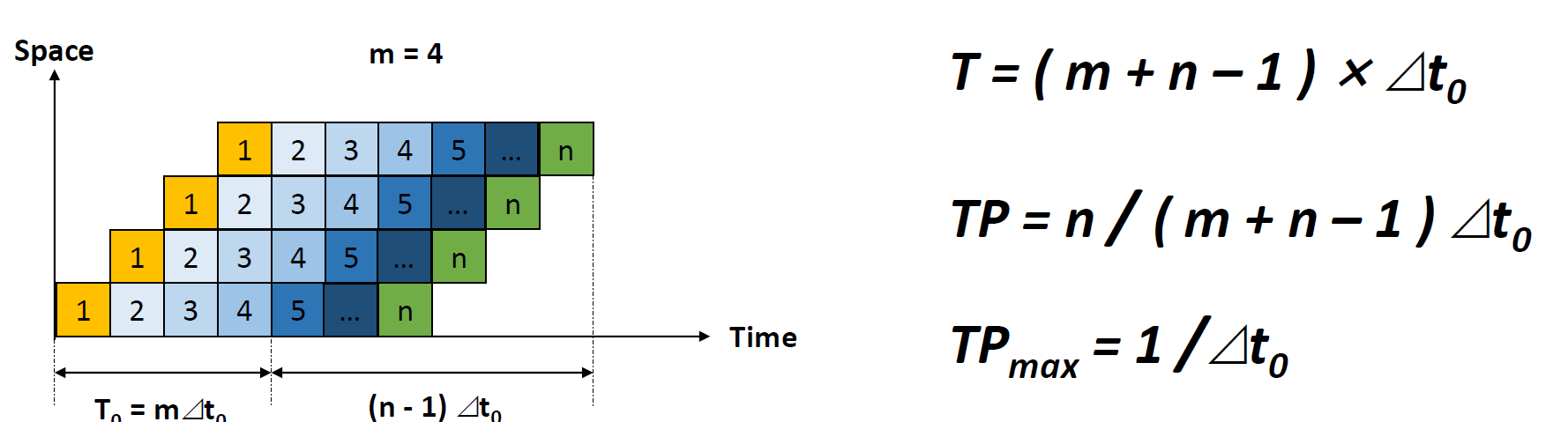 其中
其中- \Delta t_0为pipeline的时钟周期,即时间最长阶段的周期
- m为阶段数
- n为指令条数
- 加速比
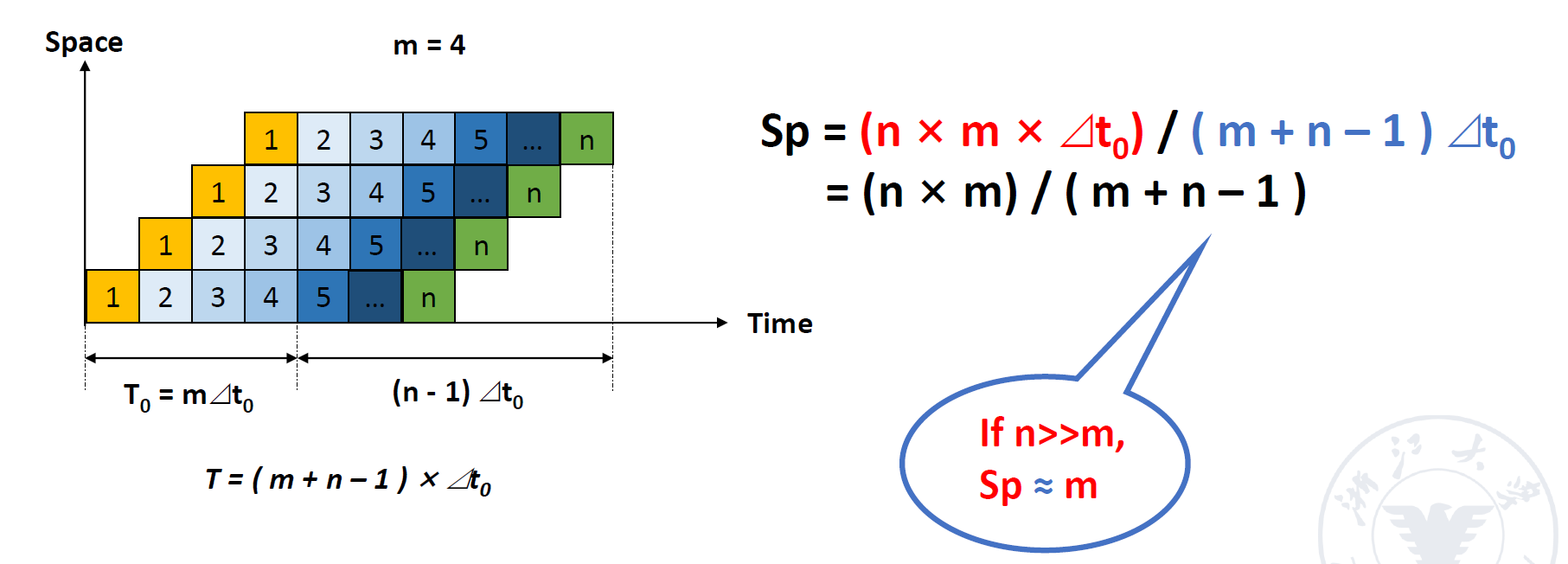 即为非流水线上的执行时间与流水线上的执行时间之比
即为非流水线上的执行时间与流水线上的执行时间之比 - 效率
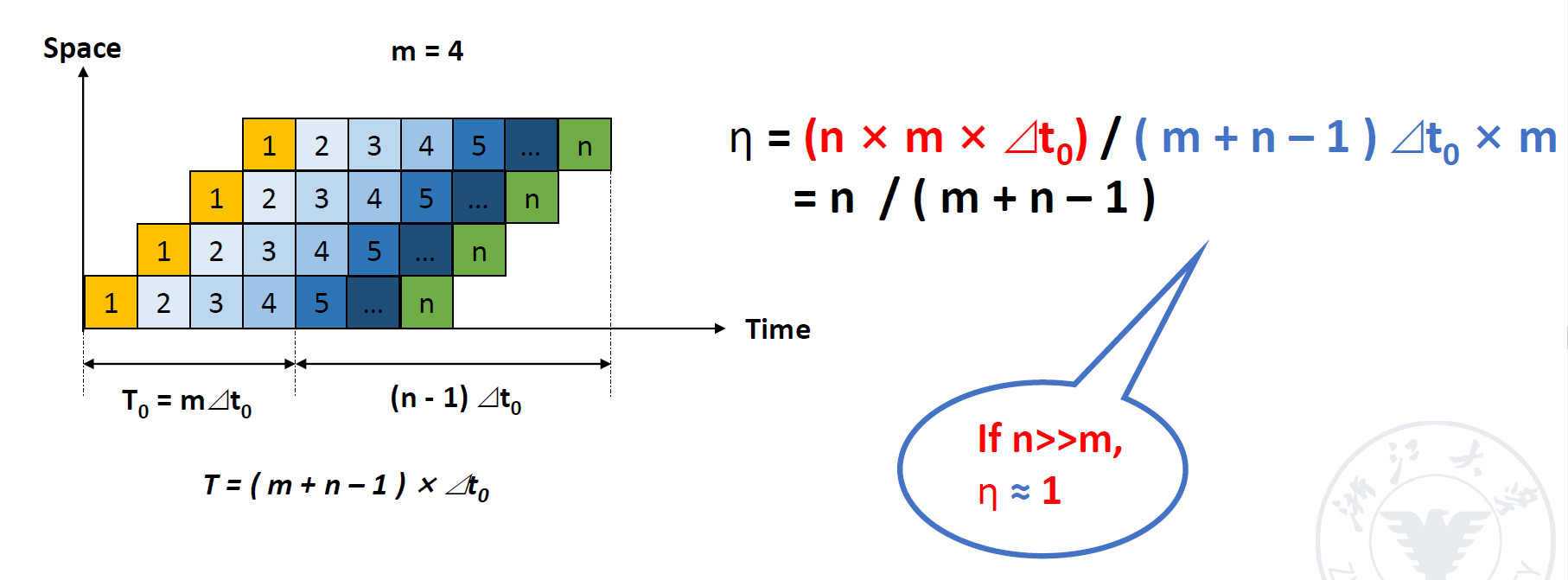 效率 = 实际上使用的时空区域/总的时刻区域
效率 = 实际上使用的时空区域/总的时刻区域 - 上面的这些到时候看一下32页到36页的几个例子
Lec 3 Overview of Pipeline
Datapath 和 Control
How Pipelining Improves Performance:提高吞吐量
(做完lab1和lab2一定会对这章的内容有一个深刻的认识,所以我也就没有整理)
Lec 4 Hazards
结构冒险(Structural Hazard)
Problem: Two or more instructions in the pipeline compete for access to a single physical resource.
即两条或多条指令在执行时会在同一时刻访问同一条资源引起的冲突
两种解决方案
- 让其中的一条指令暂停,去等
- 添加更多的硬件
并且总是可以通过添加更多的硬件来解决冲突
数据冒险(Data Hazards)
Problem: Instruction depends on result from previous
普通的R型指令的数据冒险
forwarding
需要去侦测什么时候需要forwarding 写入的两个条件
写入的两个条件
 即只有当我们需要将上一条指令计算的结果写回到寄存器时,才需要发生forwarding
即只有当我们需要将上一条指令计算的结果写回到寄存器时,才需要发生forwarding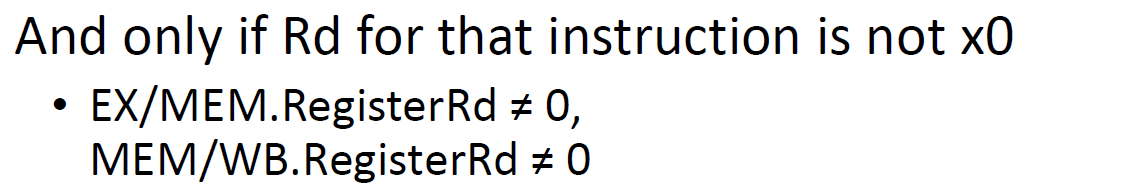 以及上一条指令写入的结果不能是X0
以及上一条指令写入的结果不能是X0
下图是考虑了double hazard的情况
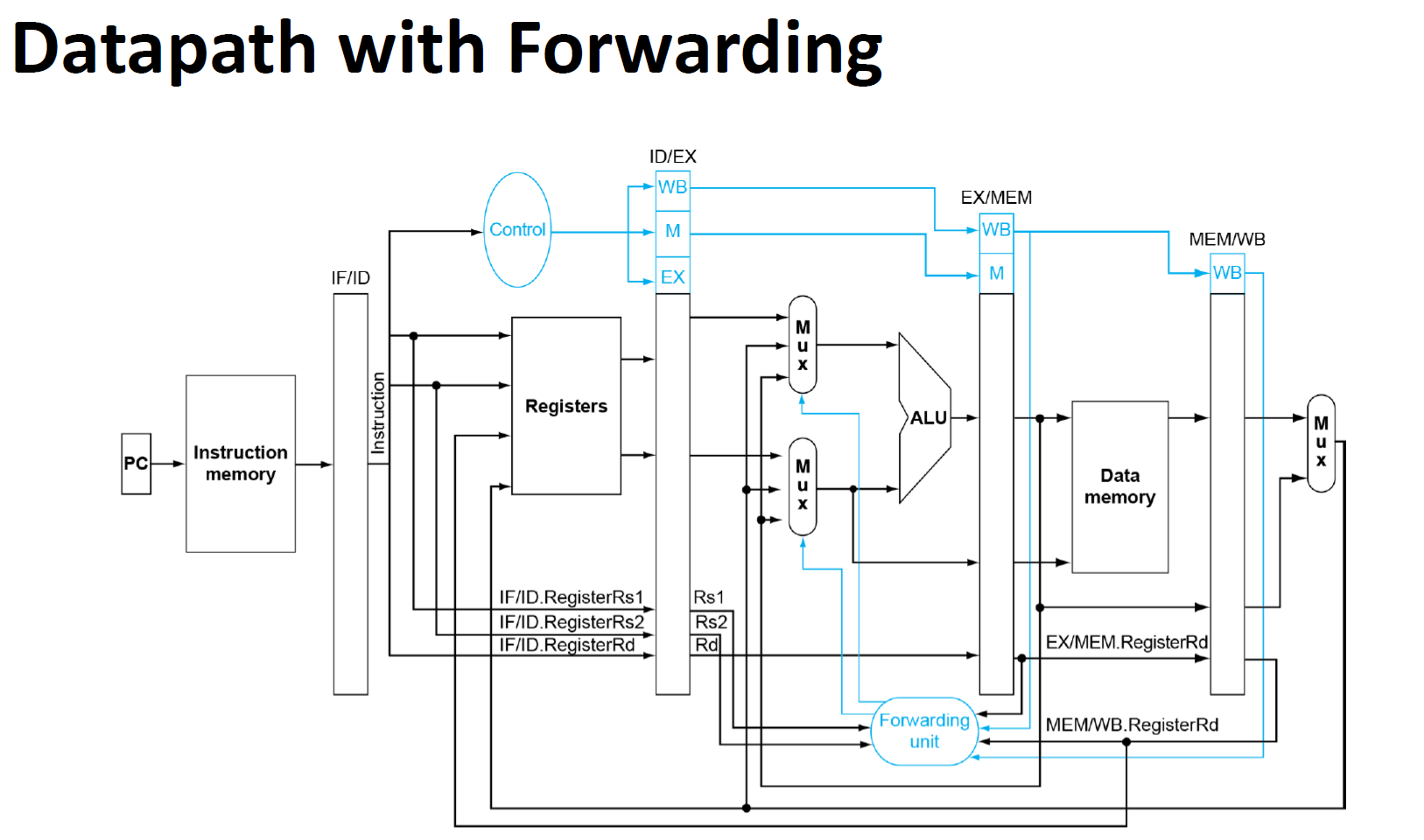
这些数据冒险的图一定要记下,考试会考的
Load-Use的数据冒险
检查方法
需要暂停一个周期,如何暂停
即让控制信号清零,并且保证PC以及IF/ID阶段的控制信号不会更新
存在暂停的数据通路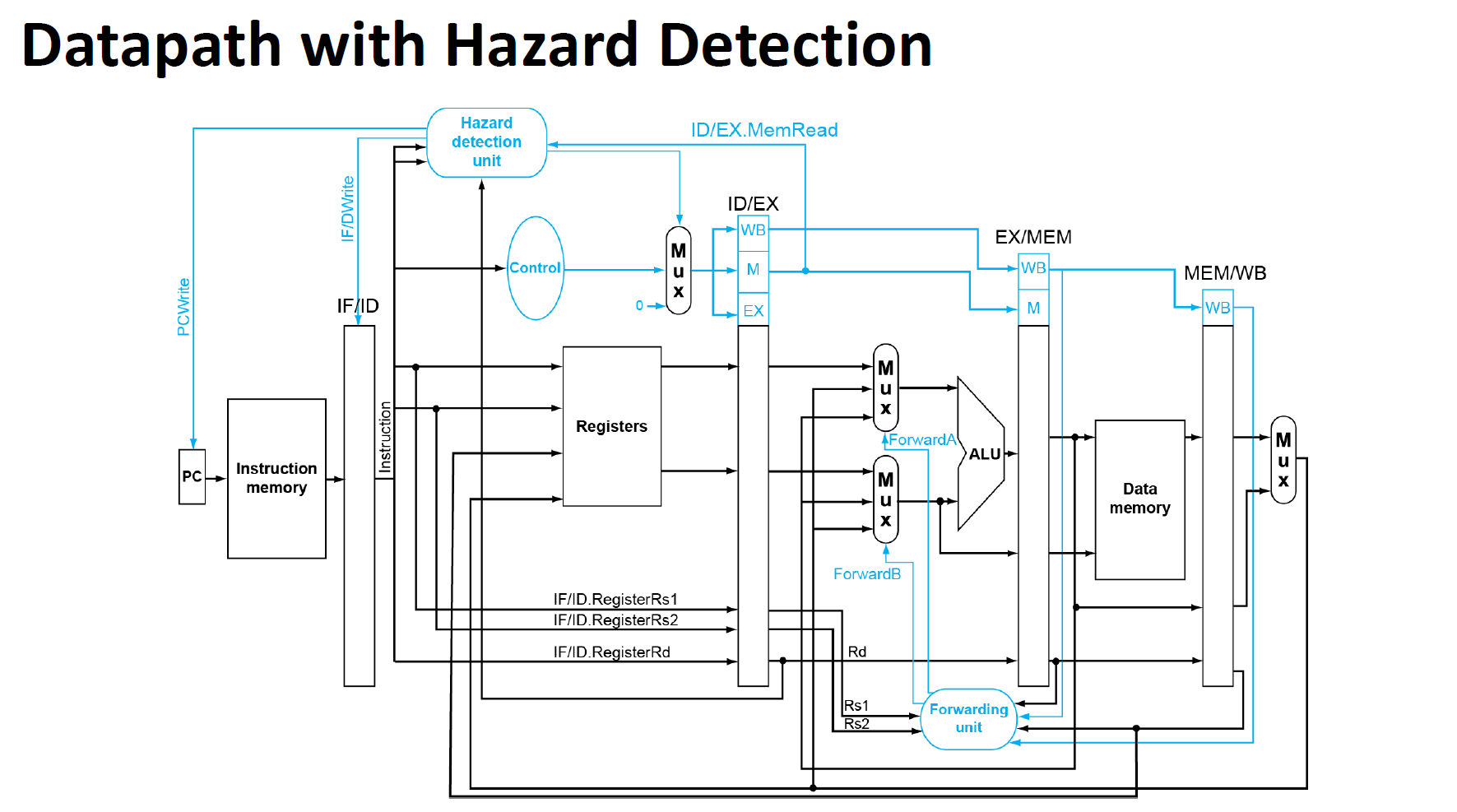
控制冒险(Control Hazards)
Problem: 因为流水线不知道下一条指令可能在哪里
(无条件跳转指令也会出现控制冒险)
解决方法:
- 将两条指令尽可能早的做完
- 也可以通过预测这次跳转是否会发生
- 还有一种方式是通过code scheduling的方式来让它不会有冒险
注意,在控制跳转指令所需的计算用的寄存器中也可能会产生冒险的行为,这时候由于beq指令的一些操作被提前,所以可能也需要来加入bubble来解决,甚至当lw和beq指令贴在一起时可能会需要添加两条bubble才能解决
通过Branch History Table(BHT)来判断本次是否会跳转
1 bit:
但这种1位的predictor在第一次进入循环,和出循环的时候往往会出现错误,尤其是在嵌套循环中,从而造成一些负担,如下所示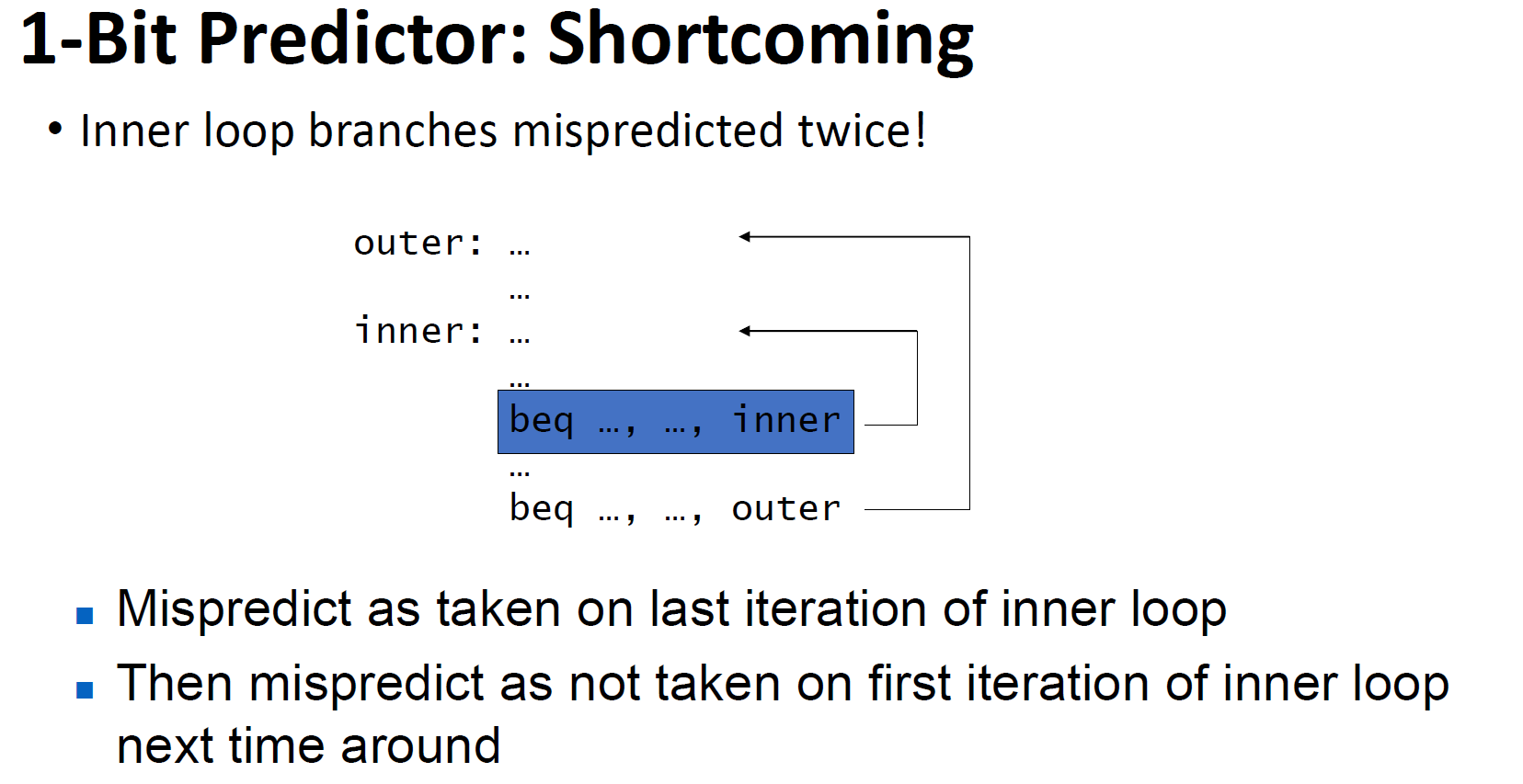
所以出现了2 bits的predictor这样可以避免掉循环中的一些预测错误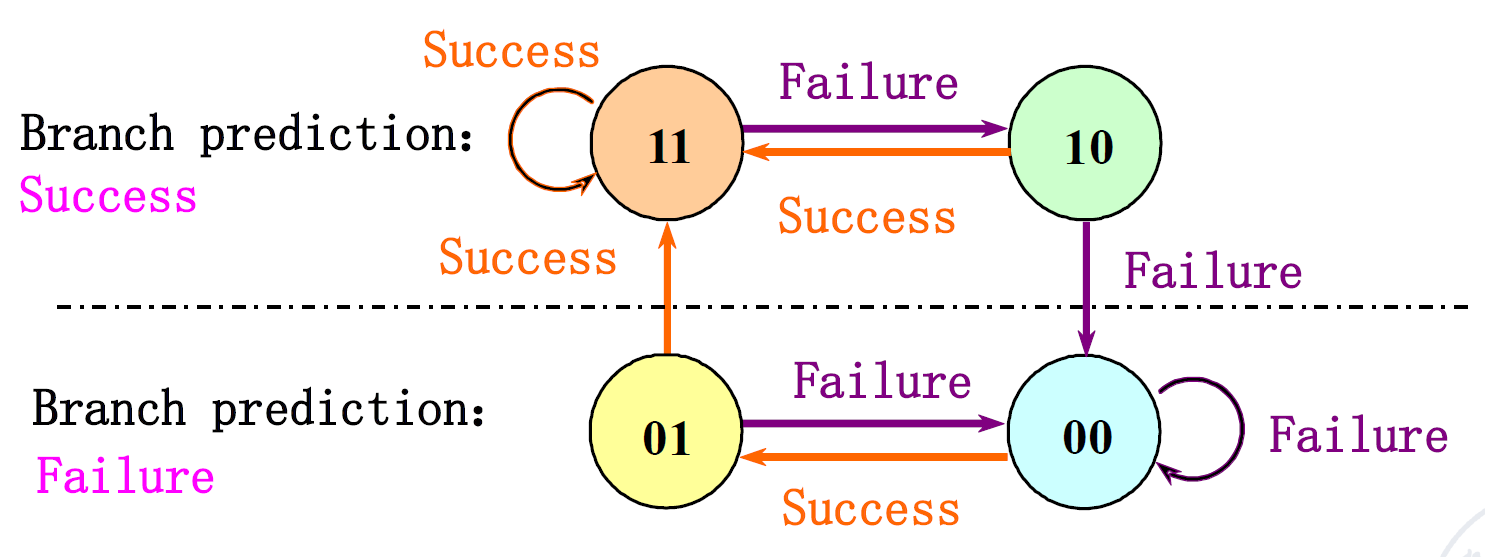
这样可以避免掉循环中的一些预测错误
- CPI: Cycle Per Instruction
- IPC: Instruction Per Cycle
Lec 5
线性流水线和非线性流水线
- 线性流水线(linear pipelines):流水线地各段串行连接,没有反馈回路

- 非线性流水线(nonlinear pipelines):流水线中除有串行连接地通路,还有反馈回路。常用于递归或组成多功能流水线。在非线性流水线中地重要问题是流水线地调度问题

多发射技术(multiple issue)
指令集并行(Instruction Level Parallelism )(ILP)

- parallel:并行
增加ILP的方法:
- 采用更深的pipeline
- 采用多发射技术

注意,这里在最后一条中所说的CPI 和IPC一般往往是达不到的,因为实际的发射过程中可能会发射一些bubble,就会使CPI增加,IPC降低
分类
多发射技术需要决定一个问题即:如何确定在给定的时钟周期发射多少条指令以及发射何种指令呢?由此将多发射分为了两类
静态多发射(Static multiple issue)即上面的问题完全由编译器来做,数据冒险和控制冒险也完全是通过编译器来处理的

- 动态多发射(Dynamic multiple issue)不依赖于编译器,但编译器可能还会提供一定的帮助,而是依赖CPU。数据冒险和控制冒险绝大多数的依赖硬件来处理的

两种多发射的处理器
- 超标量(superscalar)

- 每个周期会发射出的指令条数不固定
- 但会有个上限,比如4,那么对于这个处理器来说,最多就只可能发射出四条指令
- 是动态流水线来实现的,但也可以通过静态来实现
- 超长指令字 VLIW (Very Long Instruction Word)

- 每个时钟周期发射出的指令条数一定固定
- 是一个很典型的静态流水线,即所有的调度工作都由编译器来完成
super pipeline:即通过进一步加大流水线的级数来实现
以上所说的集中流水线的对比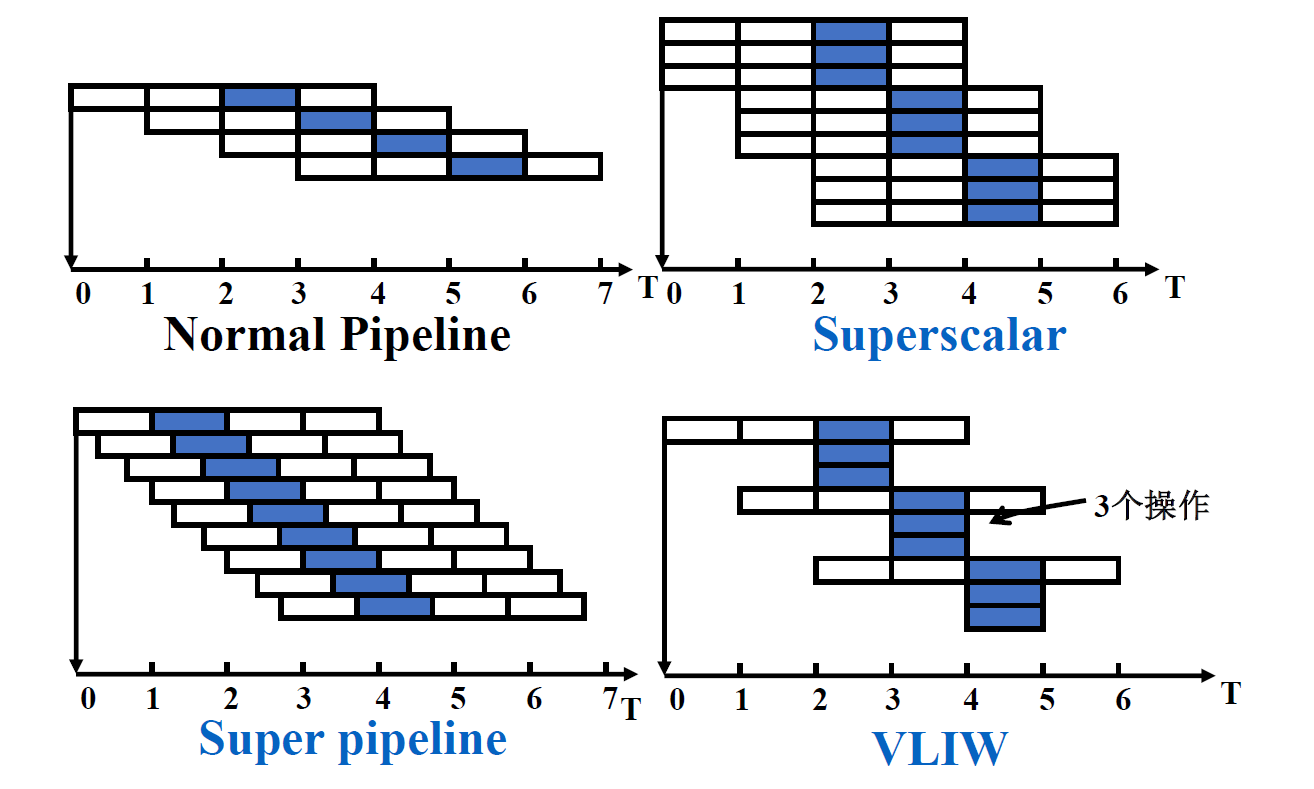
- 需要注意的是,VLIW的在IF和ID阶段是将多条指令的IF和ID同时完成的(将多条指令装在同一个指令字中),即通过增加多余的硬件来同时完成,所以看上图感觉好像少掉了几块过程
发射指令的条数在动态和静态的区别




Lec 6 Exceptions and Interrupts
- Exception:由CPU引起的,例如syscall,未定义的操作码等
- Interrupts:由外部的输入输出设备引起的
处理异常


若有收获,就点个赞吧
0 人点赞
