感谢xyx学长的操作系统的笔记qwq
Lec1 Introduction
操作系统是什么
- 操作系统通过将实际的的东西进行抽象从而起到管理计算机硬件与软件资源的目的,例如将CPU和RAM所运行的process抽象成APP
- 也可以是:software layer between the applications and the hardware because the hardware would be too difficult for users to use
- It’s a resource abstractor(提取器) and a resource allocator(分配器)
- os和kernel不是一个running的job,而是一个在memory中的一段代码,如果有event发生了,它就回去执行
- 关于kernel和os的代码一定是lean and mean
- lean: nothing more
- mean: single-minded
-
操作系统的启动
当一个计算机启动的时候,它就会开始启动自己的第一个程序,即bootstrap program,它被写在ROM里,它会初始化整个计算机,并将OS kernel载入memory,然后kernel就会执行第一个程序。
通过ps -eaf或ps aux指令可以列出每一个进程,只不过两者列出的风格不一样
Multi-Programming
通过time-sharing来实现,When the job has to wait for “something”, then the OS picks another job to run
两种mode
如果没有kernel mode
A user program could wipe out the whole system due to a bug (or a malicious(恶意的) user)
- Multiple user programs could write to the same device concurrently, leading to incoherent(不合逻辑的) behavior
在user mode中产生异常,会在kernel mode中处理,而在kernel mode中产生错误则会崩溃
System Call
一个user program需要去做一些privileged的事情,就可以通过调用system call来解决
Timers
os必须知道过了多少时间从而去管理不同的CPU对time进行分配,故需要一个timer
一道题

- hard-disk drives:即硬盘驱动器,电脑中的C盘,D盘等都是硬盘驱动器,即计算机存放数据的地方
- Registers:寄存器,没啥好说的
- Optical disk:光碟光盘
- Main memory:即随机访问主存(Random Access Memory, RAM)属于volatile memory(易失性内存),即计算机工作的场所,一般手机上8GB的那个就是
- Nonvolatile memory:非易失性内存,指当电流关掉后,所存储的数据不会消失的电脑存储器,例ROM等
- Magnetic tapes:磁带
我还以为是什么高级的东西。。。 - Cache:缓存,介于CPU和主存之间
故从慢到快的排序应该为
f.Magnetic tapes c.Optical disk 这两个肯定很慢就不解释了
a.hard-disk drives 用来存放数据的地方,肯定很慢
e.Nonvolatile memory 非易失性内存,这玩意肯定比a快,也肯定比d快,毕竟如果比d快d就没什么用了
d.Main memory g.Cache b.Registers 这些也很好理解就不多解释了
f. magnetic tapes c. optical disk a. Hard-disk drives e. Nonvolatile memory d. Main memory g.Cache b. Registers
Lec 2 Structures
os services
- program execution
- load and run a program
- allow a program to end in multiple ways
- error detection
- I/O operations
- file systems
- provide file/dictionary abstractions
- allow program to create/delete/read/write
- implements permissions
- communication
- resource allocation(分配)
- accounting
- keep track of how much is used by each user
-
User os interface
CLI or command interpreter:就是那个黑框
- desktop
-
System calls
system calls 是user mode调用kernel mode的功能时的入口
大多数情况下通过Application Programming Interface(API)和一些预定的接口,来进行调用 man 2 (syscall)可以查看syscall的内容
这里的printf()相当于一个wrapper,它将write()给封装了起来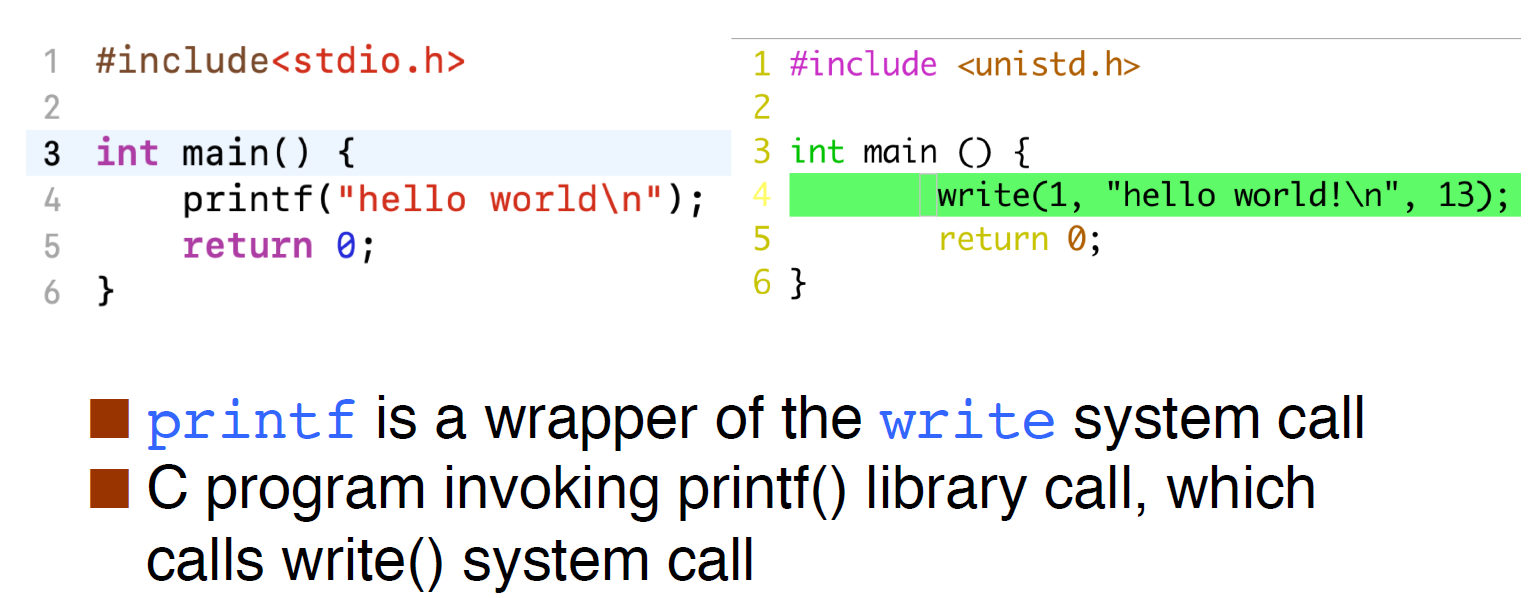
syscall table中是用数组实现的,它在数组中的index就是自己的syscall number,这个table是静态的
在汇编下,它会将syscall的number给某个(或某些)特定的寄存器(RISC-V下是a0和a1),然后通过调用syscall函数将控制流从user转交给kernel,并由上文所提到的寄存器来判断是什么syscall
在进入syscall时,会有一个kernel entry作为这个syscall的入口,它会将user space的context都save下来然后进行syscall的处理,在syscall结束后 ,它会将saved的context进行restore,然后return
- strace ./a.out可以查看在执行./a.out中,有多少个syscall,以及它们的信息
- 事实上,即使调用一个简单的操作就会调用很多个syscall
- 用gcc对文件进行编译时,默认的是dynamic编译
- gcc -static main.c就会静态编译
- 静态编译所占的空间会大很多,它将所有需要的code都打包进去,所有运行起来会更方便
syscall在不同的架构,不同的os的情况下,syscall也不一样
故windows的可执行文件在Linux上不能运行,因为syscall不一样
执行时间
可以用time命令查看一个program执行的时间,它会有三个时间
real time
- user time
- system time
参数传递
有三种传递参数的方式
- 直接通过寄存器传递参数
- 将参数放在memory的一片地址里,并通过寄存器传入这片内存的首地址来进行传递
-
system call的分类
process control
- file management
- device management
- information maintenance
- communications
-
system services
是在user space中运行的,不属于内核,就是那个框框,例如,ubuntu中的gcc ls等命令
linkers and loaders
Source code compiled into object files designed to be loaded into any physical memory location – relocatable object file. 即源代码经过编译之后会变成.o文件
- linker将这些.o文件进行链接陈一个可执行的二进制文件
- 当要执行时,会由loader将它们载入内存中并且执行
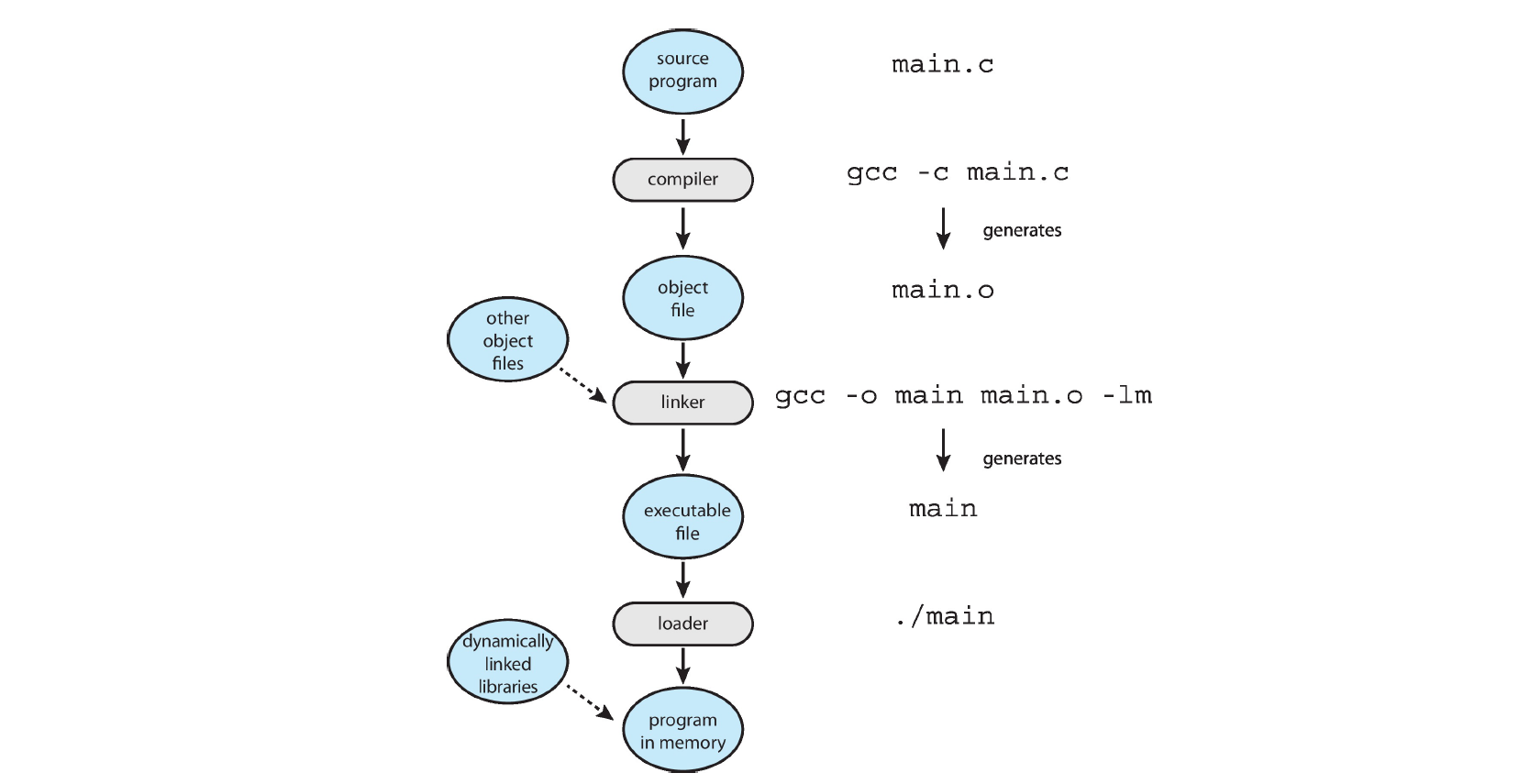
可执行文件基础
Executable and Linkable Format (ELF)
一个ELF文件会分为以下几个段
- .text段:用来存放代码
- .rodata段:用来存放已被初始化的只读数据,如static const等
- .data段:已经被初始化的全局变量
- .bss段:未被初始化或者被初始化为0的全局变量
- stack:存放局部变量
- heap:动态分配内存
当查看process在内存的映射中,可以看到
其中第一行有读和执行的权限,故为code section
第二行有读的权限,故为.rodata
第三行有读写的权限,故为.data
static link
- _start是程序的入口
- _start函数中会调用__lib_start_main
并且会在__lib_start_main中定义main函数的指针并进行调用
static link and dynamic link
static link
- 将所有的程序模块都连接成一个单独的可执行文件,所有的代码都被打包在一个二进制文件中,因此这个文件会很大
- 并不需要dynamic loader
- 会首先执行一个_start函数
- 会将程序的entry设置为指向_start
dynamic link
Policy: 要做什么
- Mechanism: 怎么去做
policy and mechanism 应该要分开,这样就可以在改变policy的同时不用改变已经实现了的mechanism
Monolithic kernel && Micro kernel区别
- 单核(Monolithic),例如Windows,Linux等
- 整个操作系统都放置在内核中
- 它作为一个大过程运行
- 由于所有服务都放置在内核中,因此它们只有一个地址空间
- 更大
- 易于实现/编码
- 性能高(因为内核可以将所有内容放入内核,因此可以直接调用任何函数)
- 安全性降低(如果一项服务失败,则整个系统崩溃)
微内核(Micro kernel)
cat /proc/self/maps可以查看一个process内存的映射
- rwx中的x代表的是可执行
- 在Unix中提出了mode的概念
Lec 3-1 process
Concept
进程是一个正在执行的程序
- program是放在disk中的
- 如果被load进入memory就会变成一个process
- process是一个resource的分配和组织单元,而thread是一个执行单元
Process由以下几部分组成
- code(aka text)
- data section
- program counter
- registers
- stack
-
Memory layout of a C program
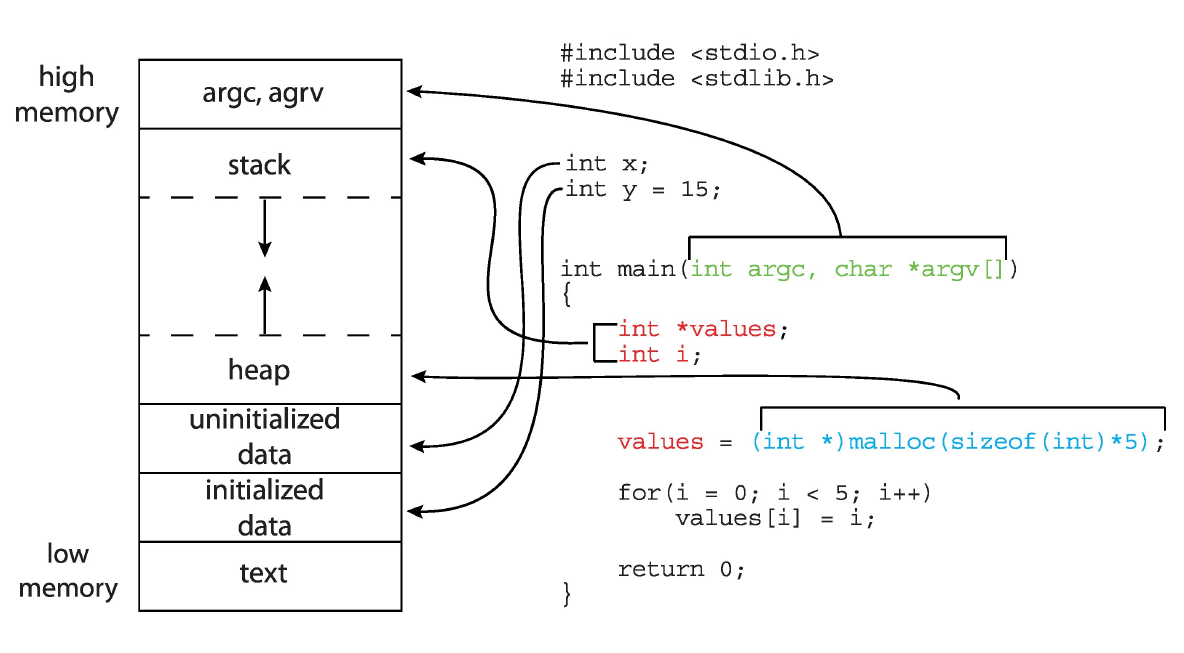
一个ELF文件会分为以下几个段 .text段:用来存放代码
- .rodata段:用来存放已被初始化的只读数据,如static const等
- .data段:已经被初始化的全局变量,即initialized data
- .bss段:未被初始化或者被初始化为0的全局变量,即uninitialized data
- stack:存放局部变量
-
stack
stack为了实现函数的调用及返回从而创建的,它有两个指针
stack pointer:指向栈顶
- stack frame:指向当前frame的base,即指向上一级栈指针的地方
它主要是为了保存函数中的一些东西,如
- 传入函数的参数
- 这个函数的本地变量
- 返回地址
- 和它的返回值
但也引入的stack overflow的安全的问题
将heap从stack中独立
- heap用于分配大段的内存,可以提高stack的效率
在一个函数中分配了内存,如果在return后还想继续去用,如果放在stack中就已经没了
Process Control Block(PCB)
PCB中包括了每一个进程运行所需要的main data及相关信息,每个进程有且只有一个PCB,且在Linux中,PCB位于kernel space
在进程创建时PCB会被分配
- 在进程结束后PCB会被释放掉
PCB主要包括:(应该不重要QAQ)
- Process state
- Program counter
- CPU registers ,存储所有进程相关的寄存器的值
- CPU scheduling information ,properities, scheduling queue pointers, etc.
- Memory-management information
- Accounting information ,CPU 使用时间、时间期限、记账数据等
- I/O status information ,分配给进程的 I/O 设备列表、打开文件列表等
所有进程的PCB通过一个linked list将它们连接在一起
进程的状态
一个进程有五个状态
- New
- Running
- Waiting
- Ready
- Terminated
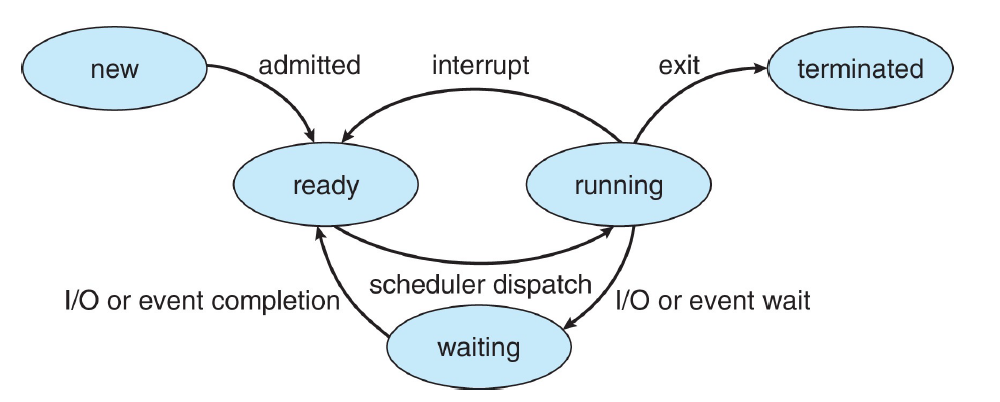
New (Process Creation)
大多数操作系统通过一个唯一的 进程标识符 (process indentifier, pid) 来识别一个进程。一个进程在运行时可以创建新的进程,则它成为父进程,新建进程称为子进程;父进程的 pid 称为子进程的 ppid (parent’s pid) 。这样进程会成为一个 进程树 (process tree) :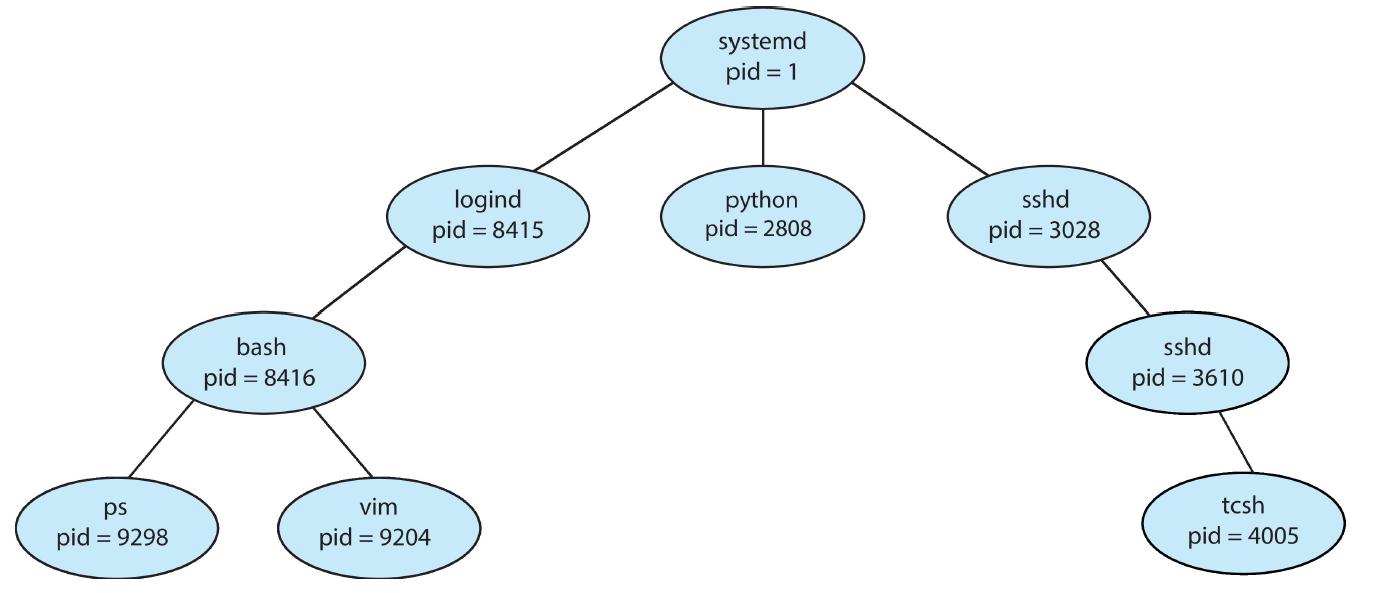
- 子进程可能会继承它的父进程的一些资源或者与它的父进程共享一些资源
- 父进程也可以通过通信的channel来向子进程传递一些初始化的数据
- 当父进程创建出子进程时,它自己可以
- 继续执行
- 或者等待子进程的结束
- 子进程
- 既可以是父进程的完全赋值
- 也可以是一份新的程序
- 可以通过fork()这个syscall来创建一个进程
- fork()函数对父进程的返回值是子进程的pid
- 对子进程的返回值是0
- fork()结束后,若无特别的说明外,子进程和父进程除了pid和ppid上的关系外就毫无关系了
加深对fork()理解的一道题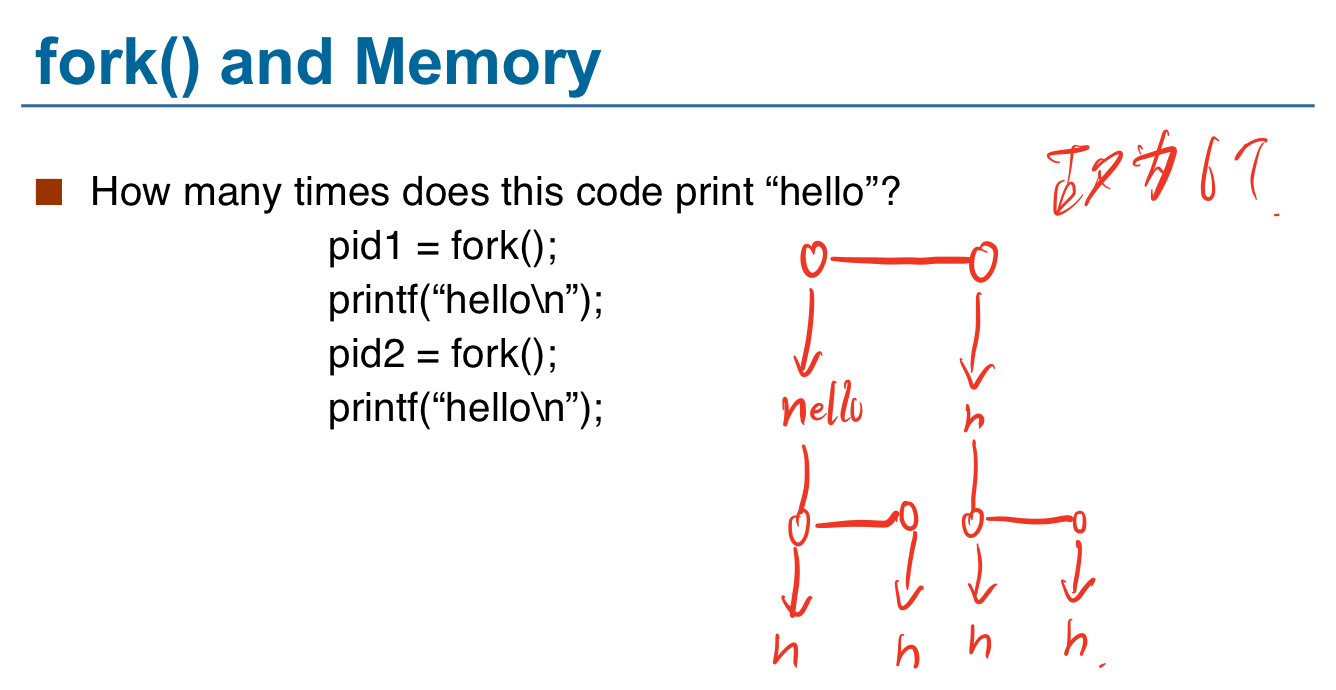
但是,fork()的作用仅仅是复制一个进程,要想创造出一个全新的进程,就需要exec()
- exec()会用一个新程序来取代内存的进程空间
- 一种典型的情况如下所示
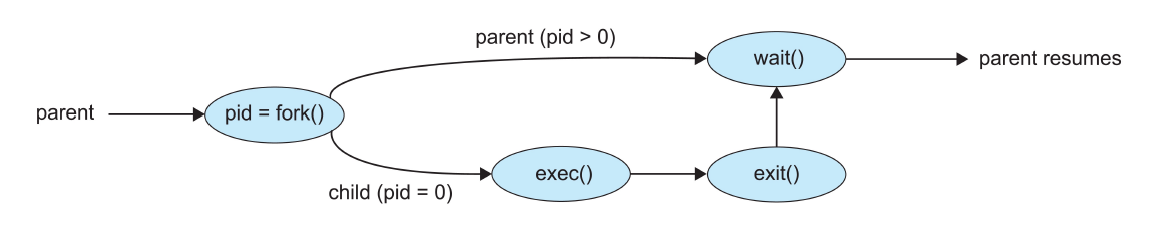
fork()的优点和缺点
- 优点:
- 调用起来比较简洁,没有参数
- fokr()与exec()分工明确
- 可以保持进程和进程在ID上的联系
缺点
wait()可以等待任何一个进程的终止
- waidpid()可以等待一个特定的进程的终止
有些系统不允许子进程在父进程已经被终止的情况下仍然存在,这种终止被称为级联终止(cascade termination)
Ready, Running and Waiting
ready是为了提高CPU的利用率而出现的一个状态
ready和waiting这两个状态会有一个queue
- waiting可能会有很多个queue因为需要去等待很多情况下的中断等等
- 而ready一般只有一个
Context switch
context switch会在CPU从一个进程切换到另一个进程的时候发生,它主要是通过将一个旧的进程的状态(信息等)存起来并且load入新的进程中去
这里的context主要指的是进程的一些信息(寄存器等),它们会被save到PCB中,也就是task_struct中的一个叫做哦cpu_context的结构体中
下面是对这个过程的一个概括(一定要看明白)
x0指向prev(被switch out的process)的task_struct,x1指向next(被switch in的process)的task_struct,它们是在一个叫做cpu_switch_to的函数里完成切换,下图的#THREAD_CPU_CONTEXT是一个常数,即cpu_context相当于task_struct的偏移量,所以相加后x8会指向cpu_context,lr即link register,也就是返回地址

我们知道,context switch要在kernel中进行切换,但事实上,由于大多数我们需要进行user space的进程切换,所以我们需要先切换到kernel mode然后进行切换,流程图如下所示(下图的文字也很重要)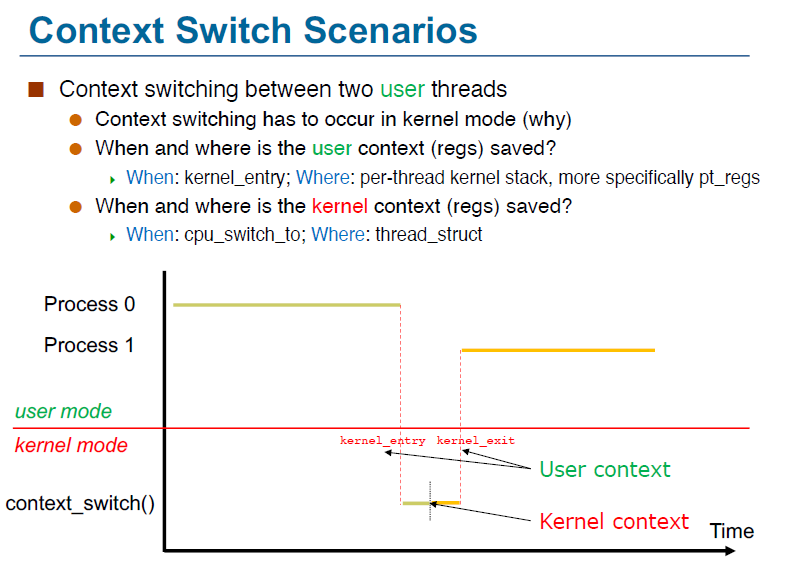
所以整个过程应该是这样的:
P0(被切换出的进程)进入kernel space,将user space的context保存到P0的kernel stack上,然后调用cpu_switch_to函数,将P0的寄存器save到thread_strcut中,然后从P1(切换入的进程)的thread_struct中切换入寄存器,最后再从P1的kernel stack中load入user的context
Zombie process
僵尸进程即已经被terminate了,但还有一些资源,由于这些资源(PCB)它们自己无法释放,故只能由其父进程来帮忙释放
处理僵尸进程的方法
- 它的父亲调用wait()
- 因为调用wait()可以通过参数让父进程获得子进程的退出状态,从而让父进程知道哪个子进程已经被终止了
-
Orphans
孤儿进程即它的父进程已经终止了(往往是由于父进程没有调用wait()去等待子进程的结束造成的),此时它就会被pid==1的进程收养,而pid==1得进程会调用wait()函数,故它可以处理掉子进程得termination
上课提到过的一些Linux命令
pgrep a.out获得a.out进程的ID,如果现在有两个a.out在执行中就会产生两个ID
- fork就是对进程的一个完全的copy,除了它们的pid不一样
- getpid()可以获得自己的pid,getppid()可以获得它的ppid
- 强制结束进程的方法(注意,如果一个进程能够成功handle所有的terminate signal,那么它就不会被terminate)
- ctrl+c
- 利用pgrep指令得到其进程号,再kill掉这个进程号
Lec 3-2 Inter-Process Communications (IPC)
从这章起主要面向考试,考试感觉不会考的就没整理,不然整理不完了qaq
两种主要IPC的模型
- shared memory:即将相同的一块内存映射给两个process
- 不安全
- 效率高
- 在操作系统上不易实现
- 对user来说比较友好,因为我们只用在RAM中读写数据即可
- 低开销(low-overhead),只需要在创建的时候的几个syscall,然后就不再需要
message passing: A将message发送给kernel,kernel再发送给B
direct:即两个进程直接连接
- 优点:效率高
- 缺点:多个process通信时,需要建立非常多的channel
- indirect:即建立一个mail box,每个 只需要连接到mail boxjike
- 坏处,时延大

Lec 4 Thread
线程 (Thread) 是进程中的基本运行单元。
- 不共享:thread ID, PC, register set 和 stack。
- 共享: code section, data section (global variable), heap, open files 以及 signals。
并发 (Concurrency) : 一个多线程的进程可以同时做多个工作。例如,一个浏览器可能用一个线程来显示文字和图像,另一个线程从网络接受数据。
一个process的ID即为它所对应的第一个的thread的ID
线程的优缺点
优点
- Economy
- 建立线程相比进程是很经济的,因为 code, data & heap 不需要新建
- 在同一进程的线程间进行 context switch 时也会更快
- Resource sharing
- 同一进程的线程之间共享内存,故无需IPC
- 这也允许我们对同一块内存做并行的处理。但这也会引入风险。
- Responsiveness
- 多线程的进程会有更好的响应性,即当一个线程 blocked 或者在做一些长时间的操作时,其他线程仍然能完成工作,包括对用户的响应。
- Scalability(可拓展性)
- 在多处理器的体系结构中,多线程进程可以更好地发挥作用,因为每个线程都可以在一个处理器上运行;而单线程进程只能在一个处理器上运行。
实际上,后两点对多个单线程进程也是适用的。但多线程进程相较而言更加经济和自然。
缺点
- 如果一个进程出现错误,那么整个进程都会去世
- 由于 OS 对每个进程地址空间的大小限制,多线程可能会使得进程的内存限制更加紧缩(这在 64 位体系结构中不再是问题)。
-
多线程模型
user thread和kernel thread存在某些必然关系,下面来说明这些关系的几种模型
Many-to-One Model
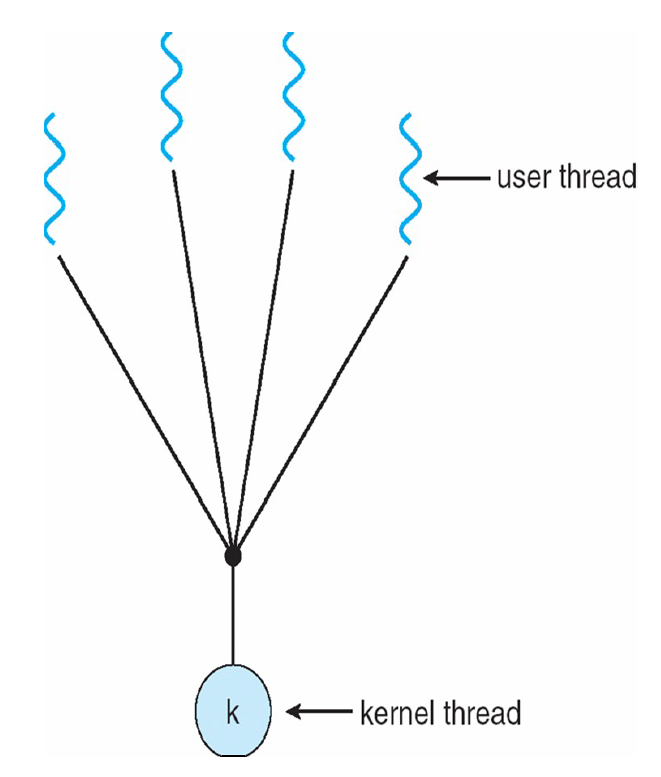
主要缺点: cannot take advantage of a multi-core architecture! 因为kernel不知道它是多线程的,故也无法为其分配多个core
if one threads blocks, then all the others do!
One-to-One Model
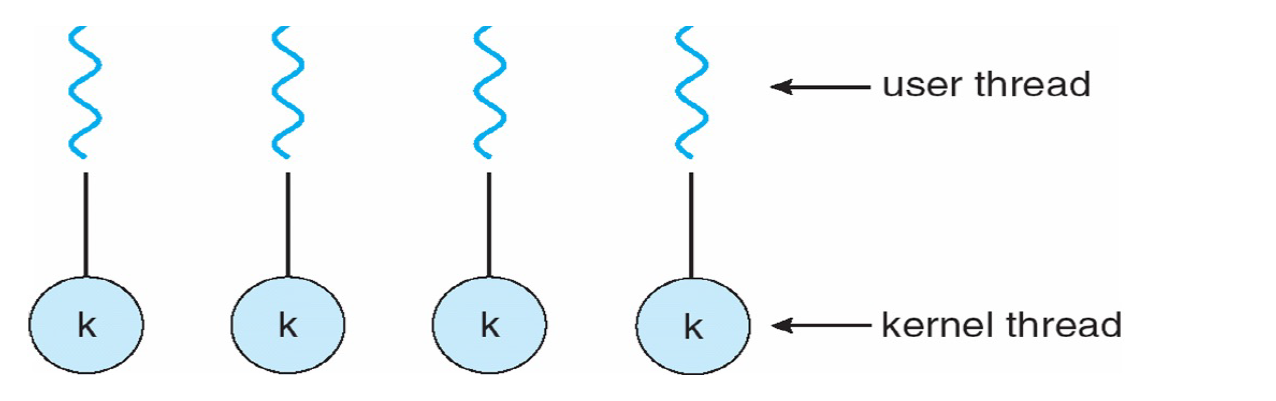
Removes both drawbacks of the Many-to-One Model
- 但由于每一个user thread都需要create一个kernel thread,故它没有Many-to-One Model快
-
Many-to-Many Model
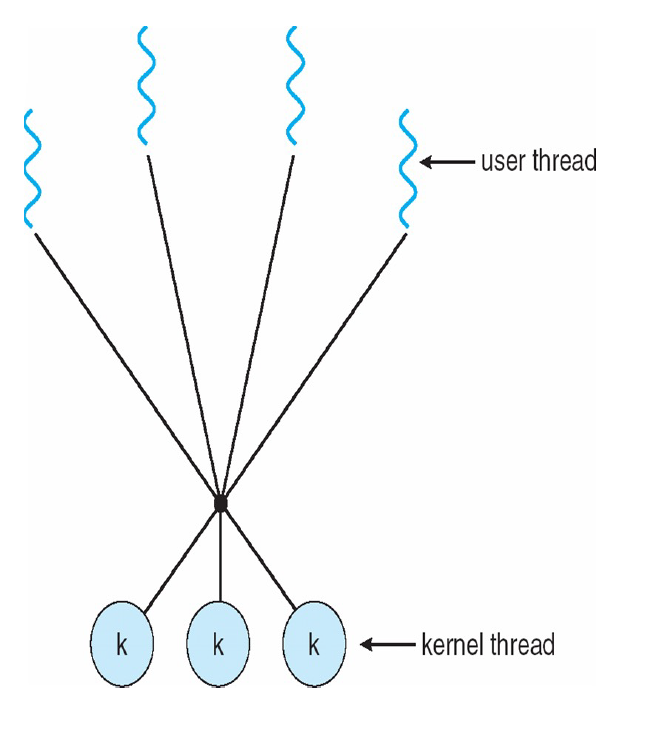
If a user thread blocks, the kernel can create a new kernel threads to avoid blocking all user threads.
- A new user thread doesn’t necessarily require the creation of a new kernel thread. 因此降低了时间
-
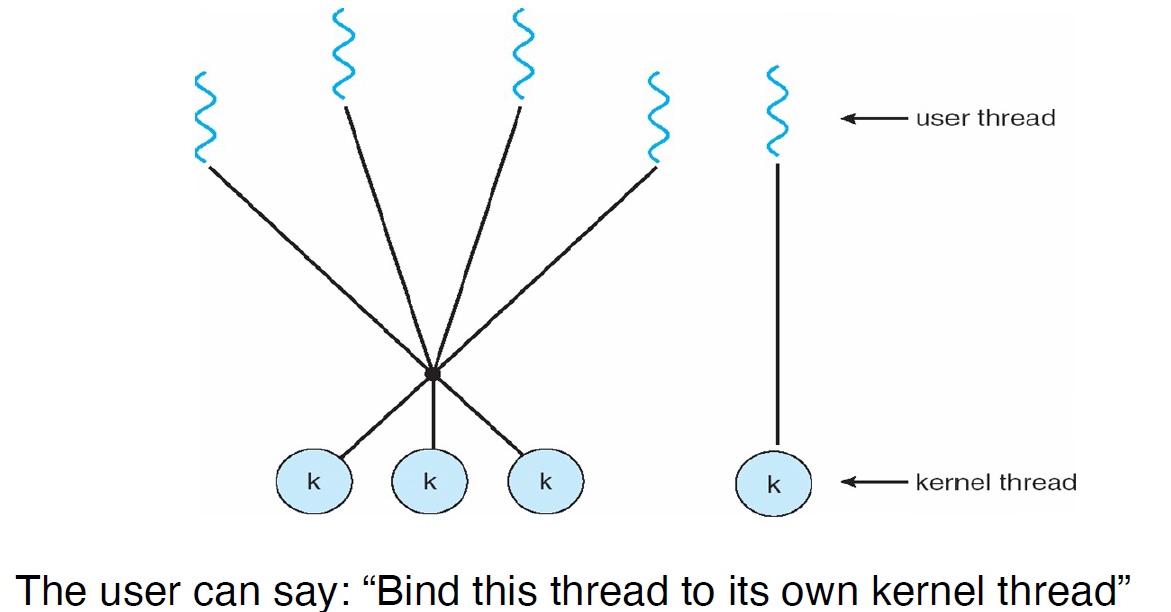
Two-Level Model
Thread Libraries
Thread libraries provide users with ways to create threads in their own programs
Pthreads 是一个创建线程的标准Thread和Process
process是resource的组织和分配单元,而thread是一个执行单元
- process分为single-threaded和muti-threaded
-
Linux
ps -eLf中的LWP显示的就是thread的ID
Lec 5 CPU Scheduling
基本概念
CPU 调度就是 OS 关于哪个 ready 进程或线程可以运行(使用 CPU)以及运行多久的决定。这在 multi-programming 环境下是必要的,关系到系统的整体效率。其目标是始终允许某个进程运行以最大化 CPU 利用率。
进程可以分为两种
- I/O-bound
- CPU-bound
每当 CPU 空闲,OS 就应该选择一个 ready process 来运行。两种调度模式:
- 非抢占式调度 (Non-preemptive scheduling) : 一个进程可以不断运行直到它主动释放 CPU。
- 抢占式调度 (Preemptive scheduling) : 一个进程会被抢占
抢占式调度is good but complex,因为在一些不合适的情况下被抢占会导致一些非常难受的bug
调度的目标(也是Scheduling Criteria):(conflicting goals,即目标有可能相互排斥)
- Maximize CPU Utilization:keep the CPU as busy as possible
- Maximize Throughput(完成的任务数)
- Minimize Turnaround Time:amount of time to execute a particular process
- Minimize Waiting Time:
- Minimize Response Time: amount of time it takes from when a request wassubmitted until the first response is produced, not output
上两点和下三点会矛盾
CPU 调度功能的实现者是 调度程序 (dispatcher) 。Dispatcher 停止一个进程而启动另一个所需的时间称为 调度延迟 (dispatch latency)
调度算法
First-Come, First-Served (FCFS) Scheduling
先申请 CPU 的进程首先获得 CPU。可以用一个 FIFO 队列简单实现。

出现的问题:Convoy effect:short process behind long process
Shortest-Job-First (SJF) Scheduling
SJF is optimal(最优的) – gives minimum average waiting time for a given set of processes
Non-preemptive

Preemptive

虽然SJF算法是最优的,但是它不能在短期CPU调度级别上加以实现,因为没有办法知道下次CPU执行的长度。
Round-Robin Scheduling
- RR Scheduling is preemptive and designed for time-sharing.
- 它会去定义一个 时间片 (time slice / time quantum) ,即一个固定的较小时间单元 (10-100ms)。
- 除非一个 process 是 ready queue 中的唯一进程,否则它不会连续运行超过一个时间片的时间。
- Ready queue 是一个 FIFO 的循环队列。每次调度时取出 ready queue 中的第一个进程

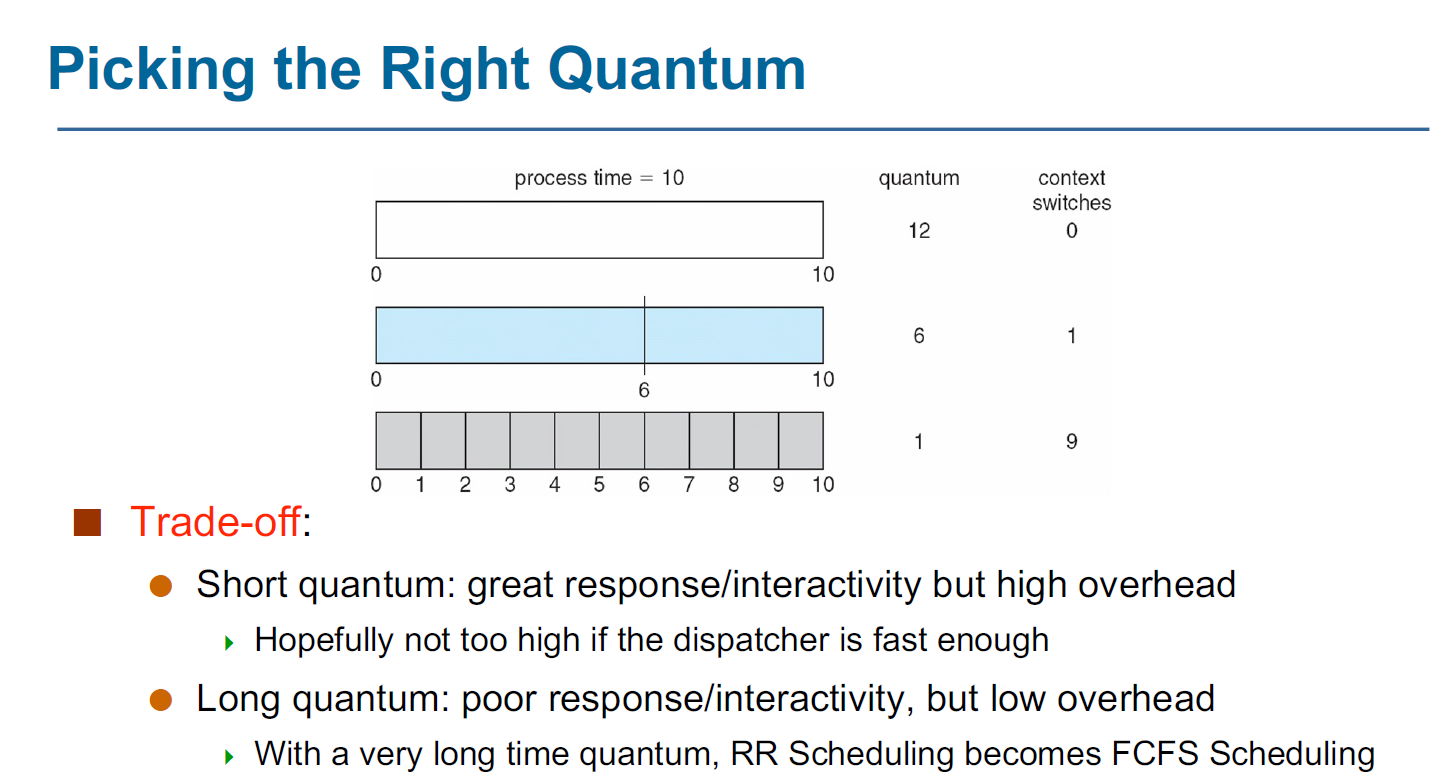
在手机上一般用short quantum,因为不需要做过多的运算,在大型计算机上一般用long quantum
Priority Scheduling
每个进程都有一个优先级,每次调度时选取最高优先级的进程。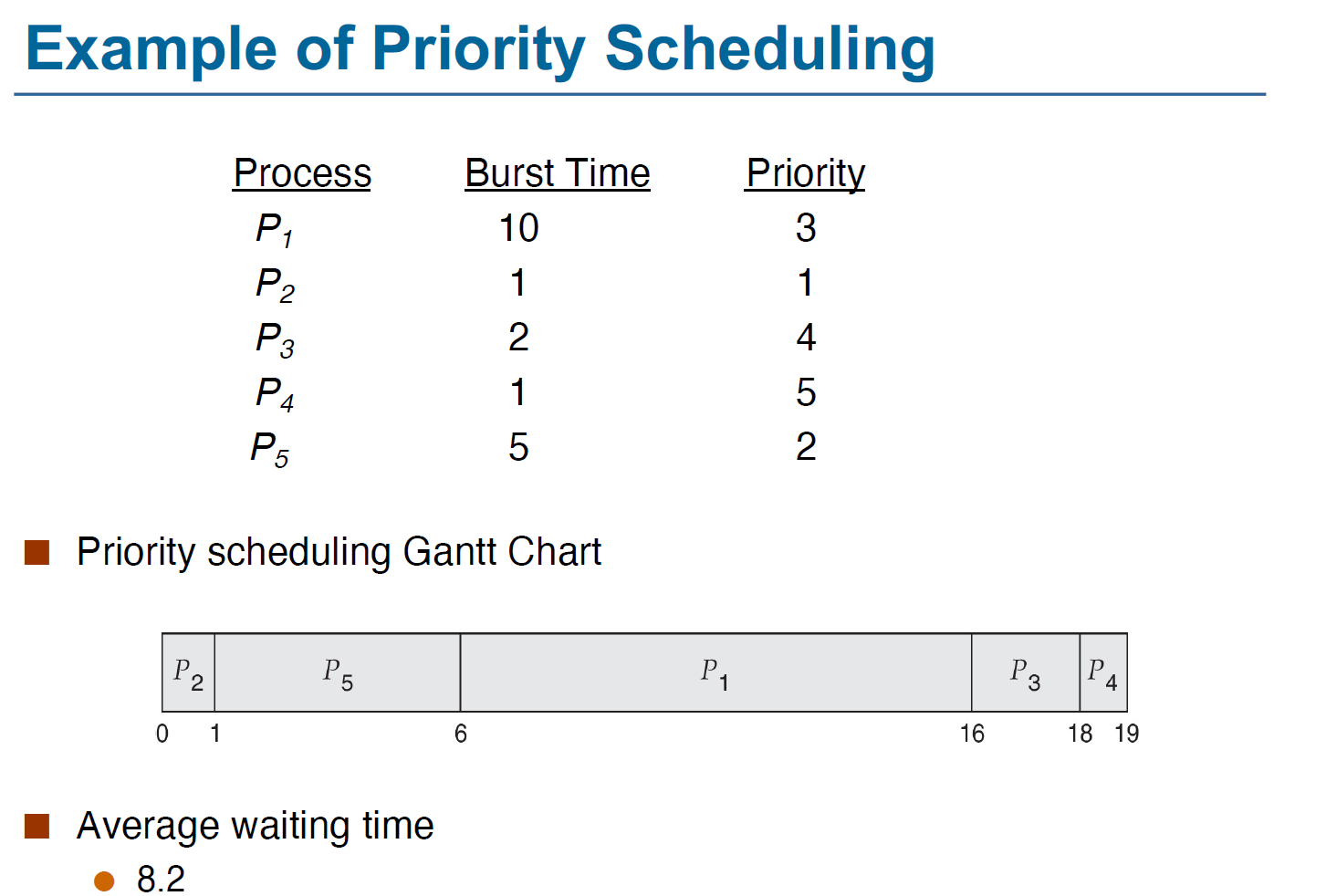
Priority Scheduling 也可以与 Round-Robin 结合来实现,如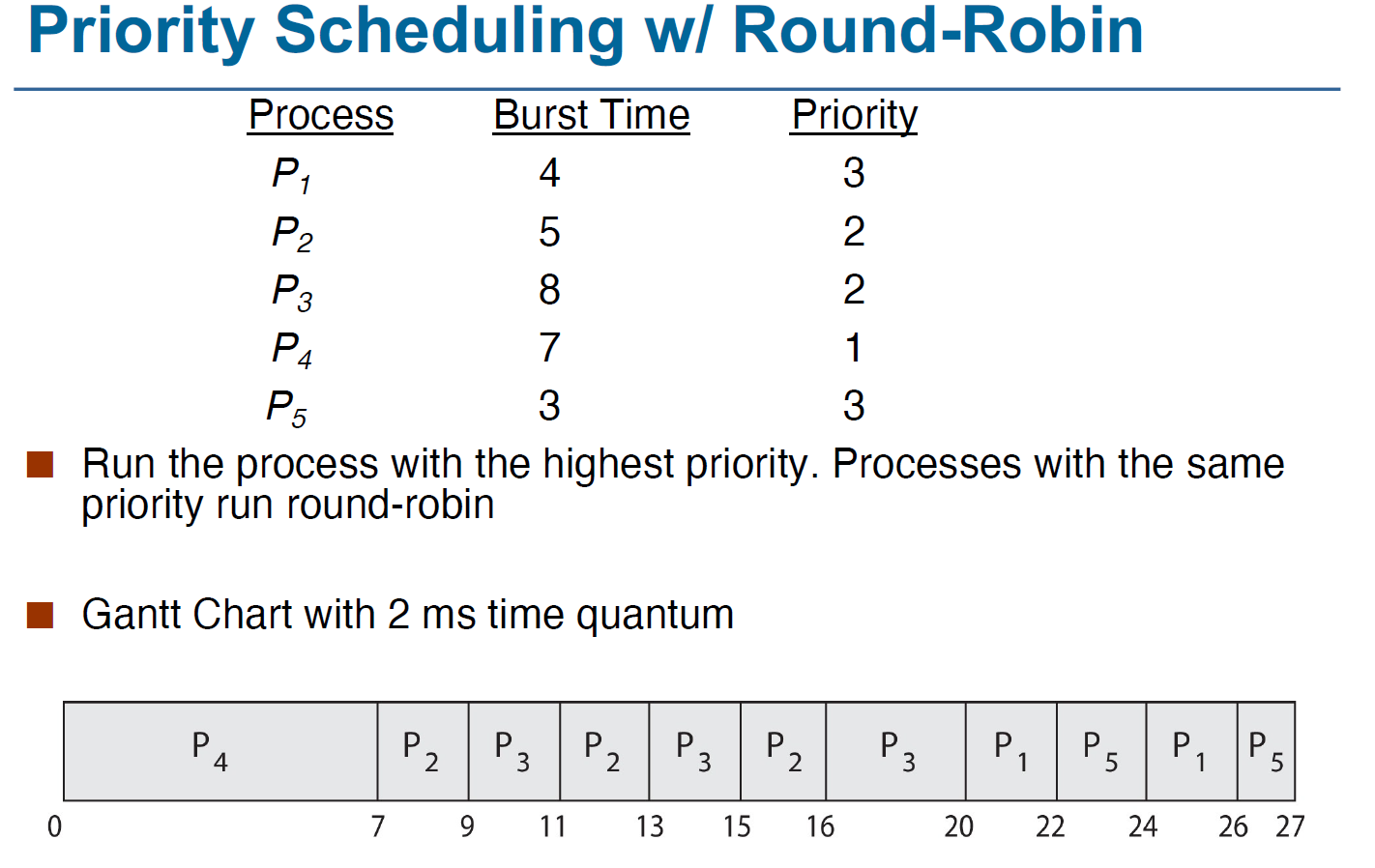
存在的问题:starvation某些优先级过低的进程可能永远都没有机会执行
解决方法:Priority Aging ,即根据等待时间逐渐增加在系统中等待的进程的优先级。
Multilevel Queue Scheduling
在实际应用中,进程通常被分为不同的组,每个组有一个自己的 ready queue,且每个队列内部有自己独立的调度算法。例如,前台队列使用 RR 调度以保证 response,后台队列可以使用 FCFS。同时,队列之间也应当有调度。通常使用 preemptive priority scheduling,即当且仅当高优先级的队列(如前台队列)为空时,低优先级的队列(如后台队列)中的进程才能获准运行。也可以使用队列间的 time-slicing,例如一个队列使用 80% 的时间片而另一个使用 20%。例如: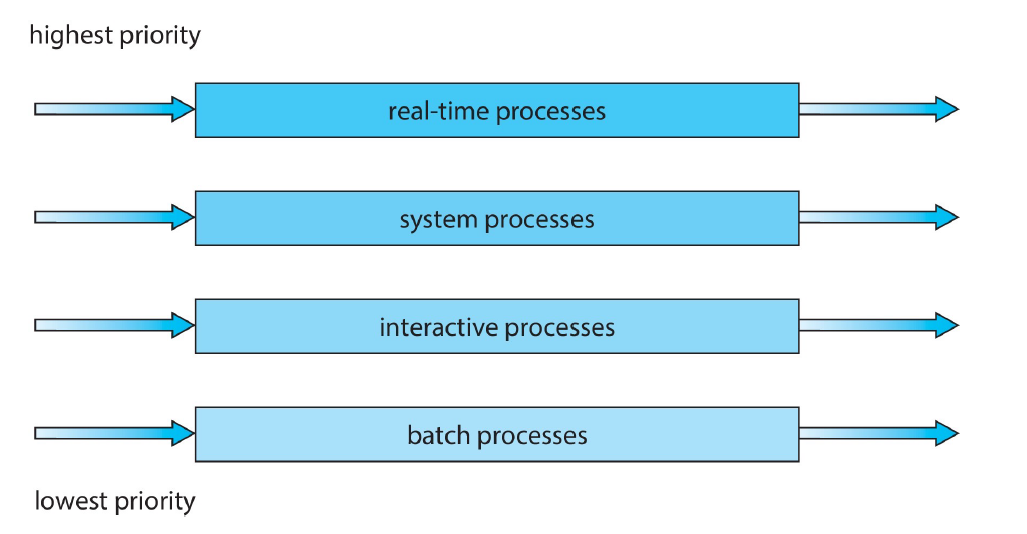
Multilevel Feedback Queue Scheduling
Multilevel Feedback Queue Scheduling 允许进程在队列之间迁移。这种算法可以有很多种实现,因为队列的数量、每个队列中的调度策略、队列之间的调度算法以及将进程升级到更高优先级/降级到更低优先级的队列的条件都是可变的。一个系统中的最优配置在另一个系统中不一定很好。这种算法也是最为复杂的。
看这样一个例子:有三个队列 0, 1, 2,优先级逐次降低。当进程 ready 时被添加到 Q0 中,Q0 内部采用 RR Scheduling,的每个进程都有 8ms 的时间完成其运行,如果没有完成则被打断并进入 Q1;只有当 Q0 为空时 Q1 才可能被运行。Q1 内部也使用 RR Scheduling,每个进程有 16ms 时间完成其运行,如果没有完成则被打断并进入 Q2;只有当 Q1 也为空时 Q2 才可能被运行。Q2 内部采用 FCFS 算法。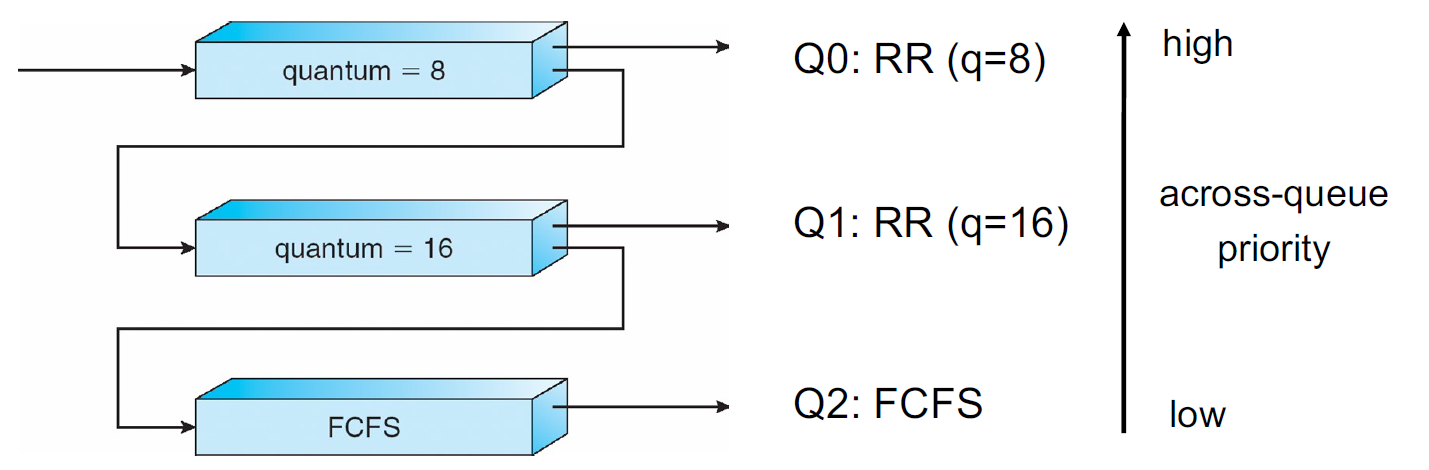
后面的复习课没提,所以大概不会考?考完了,确实没有考
Lec 6 synchronization_tools
竞态
多个线程同时去修改⼀个数据,而执行的结果对受执行的先后顺序的影响,即称作⼀个竞态(race condition),为了防止 race condition,我们需要保证同一时间只有一个进程可以操控某个变量。
Critical Section
考虑一个有 n 个进程的系统,每个进程中都有这样一段代码,它可能会修改一些与其他至少一个进程公用的数据,这段代码称为 critical section。这个系统的重要性质是,当一个进程正在运行它的 critical section 时,其他进程都不能进入它的 critical section。
每个进程必须在 entry section 中申请进入 critical section 的许可;在 critical section 运行结束后进入 exit section,在这里许可被释放。其他代码称为 remainder section。如下所示:
- Single-core system: preventing interrupts
- Multiple-processor: preventing interrupts are not feasible. 因为即使能将每一个core的interrupt关掉,在其它core的仍然能访问该程序
Critical-section problem 的解决方法必须满足如下三个要求:(临界区即为critical section)
- Mutual Exclusion (互斥访问):即在同⼀时刻,最多只有⼀个线程可以执行临界区
- Progress (空闲让进):当没有线程在执行临界区代码时,必须在申请进入临界区的线程中选择⼀个线程,允许其执⾏临界区代码,保证程序执行的进展
- Bounded waiting (有限等待):当⼀个进程申请进⼊临界区后,必须在有限的时间内获得许可并进⼊临界区,不能⽆限等待
Peterson’s Solution(好像不考)

一些缺陷:
Memory Barriers

Test-and-Set Instruction



解决方法:(估计不考),考完了,确实没考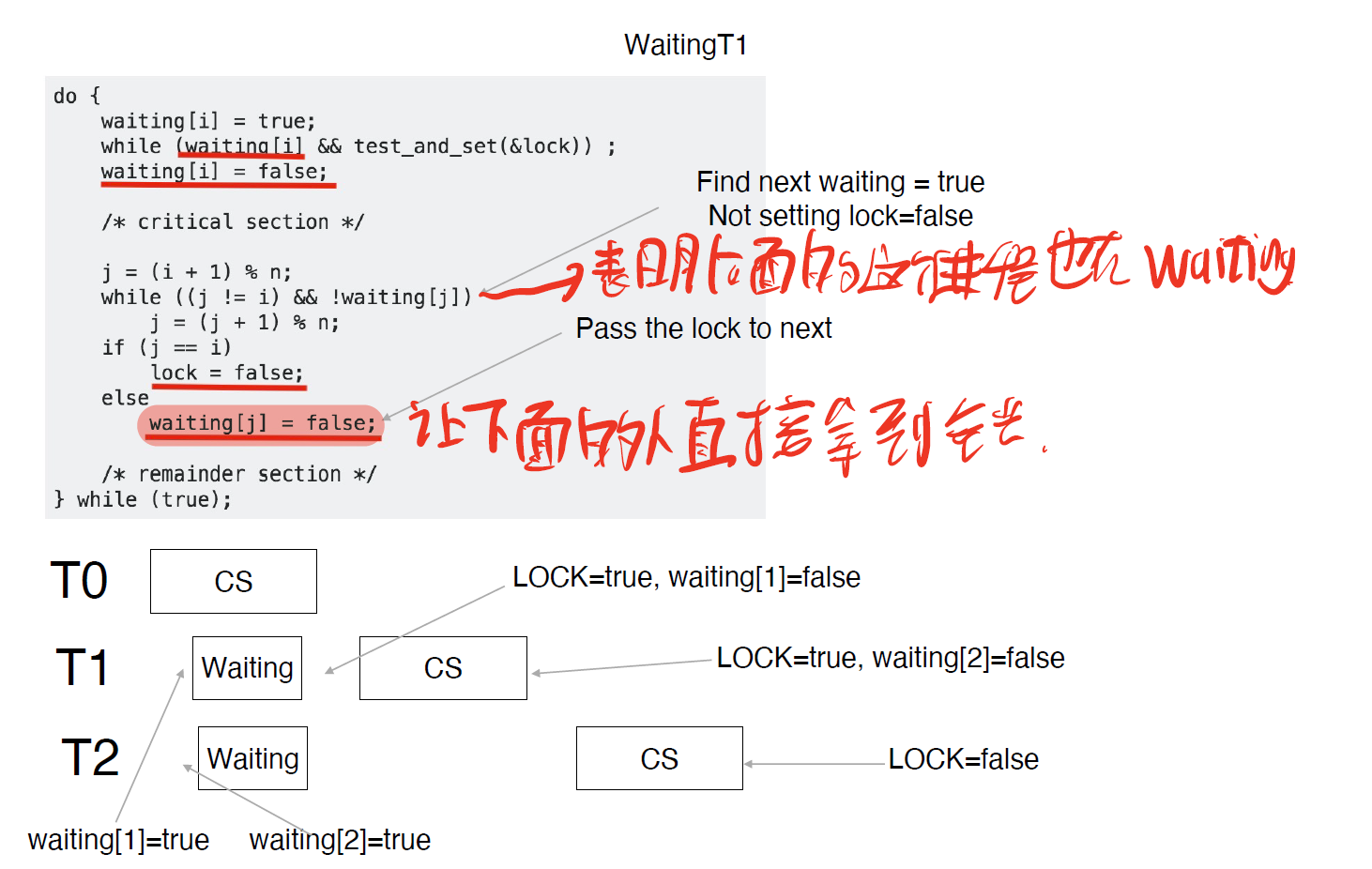
Compare-and-Swap Instruction

在 Intel x86 架构中,汇编指令 cmpxchg 用于实现 compare_and_swap() 指令
但在ARM中没有
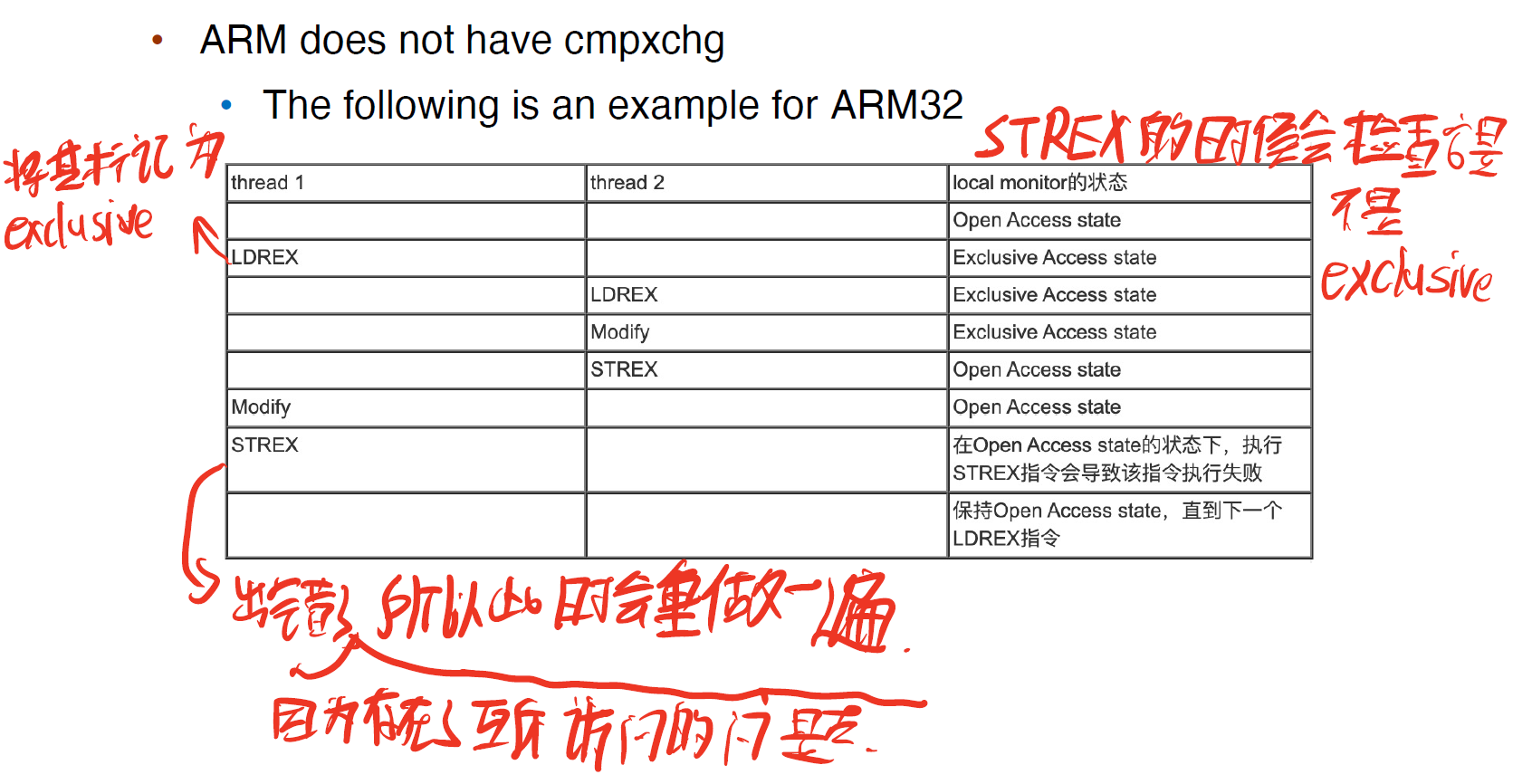
Mutex Locks
我们尝试设计软件工具来解决 critical section problem。我们考虑让进程在 Entry Section 申请 acquire() 一个锁,然后在 Exit Section release() 一个锁。对于这个锁,我们用一个布尔变量来表示它是否 avaliable ```c while (true) { acquire(); / critical section / release(); / remainder section / }
/ ———- / void acquire() { while (!available) ; / busy waiting / avaliable = false; }
void release() {
avaliable = true;
}
```
我们需要保证 acquire() 和 release() 是 atomic 的。我们可以使用 test_and_set() 和 compare_and_swap() 来实现:
但是这种实现的缺点是,它需要 busy waiting,即当有一个进程在临界区中时,其他进程在请求进入临界区时在 acquire() 中持续等待,例如当两个进程同时使用一个资源时:
这样会浪费CPU的时间
Semaphores
我们给出一种更厉害的 synchronization tool,称为 semaphore。一个 semaphore S 是一个整型变量,它除了初始化外只能通过两个 atomic 操作 wait() 和 signal() (原称为 P() 和 V() )来访问:
wait()就是等待资源的过程,signal()就是释放资源的过程,可以将S理解为剩余的资源数
通常有 2 种 semaphore:
- Counting semaphore - S 的值不受限制
- Binary semaphore - S 的值只能是 0 或 1。类似于互斥锁。
我们可以使用 semaphore 来解决各种同步问题,例如:
但是,semaphore 也具有 busy waiting 的问题。为了解决这个问题,我们可以为 semaphore 引入 waiting queue:
同时会有两种操作
- block – place the process invoking the operation on the appropriate waiting queue. 将进程放在合适的waiting queue中
- wakeup – remove one of processes in the waiting queue and place it in the ready queue. 将进程从waiting queue中唤醒并将其放在ready queue中
建议下面的代码抄下来

在上面的这一串代码之后,我们可以将busy waiting的时间缩短如下: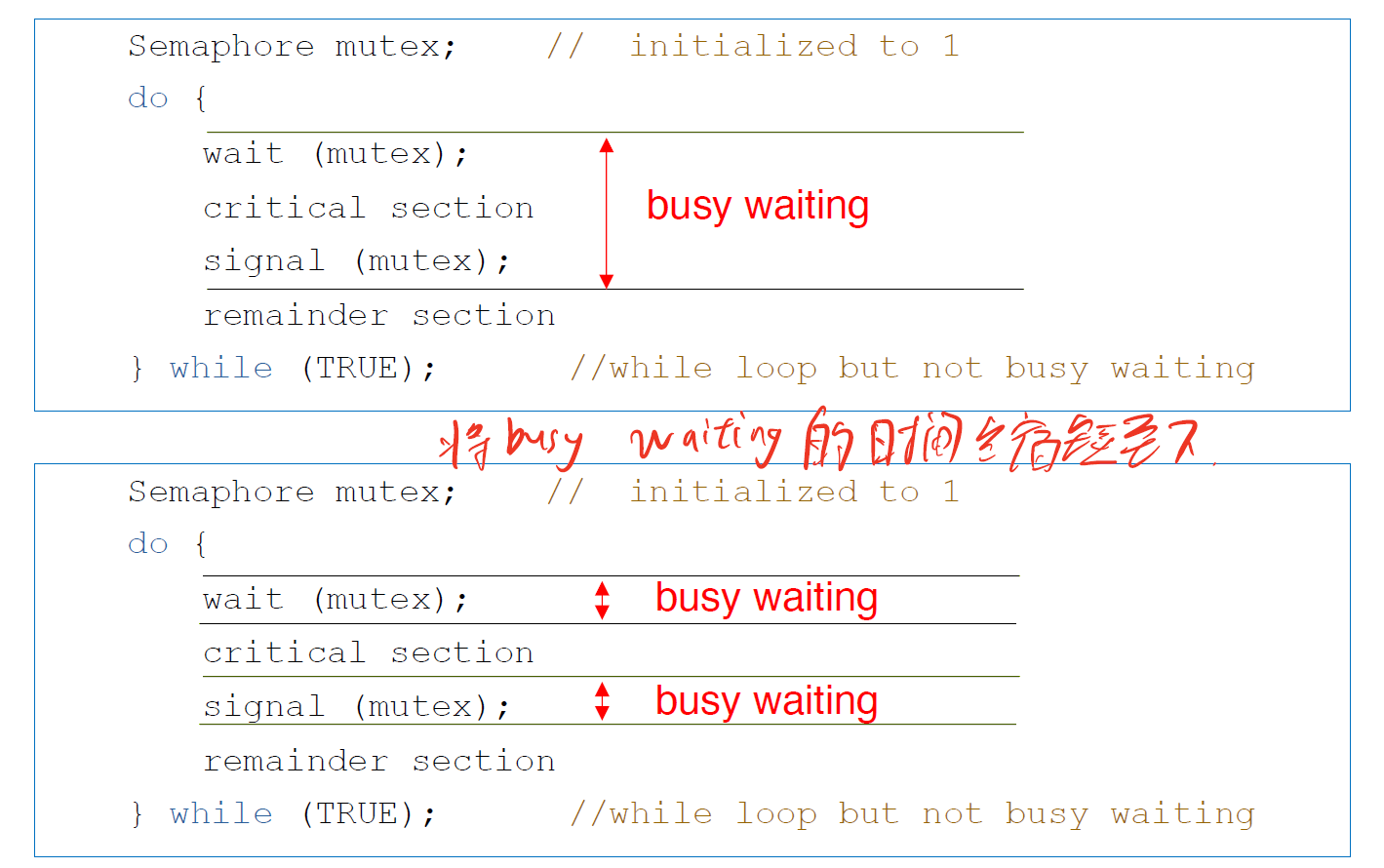
Deadlock
两个或多个进程无限地等待一个事件,而该事件只能由这些等待进程之一来产生。这里的事件是signal()操作的执行。当出现这样的状态时,这些进程就称为死锁(deadlocked)。
例如,一个由P1和P2组成的系统,每个都访问共享的信号量S和Q,S和Q初值均为1。
、
无限期阻塞(indefinite blocking)或饥饿(starvation):即进程在信号量内无限期等待。
优先级反转
因为一个高优先级的进程需要等待一个共享资源,这个共享资源被另一个低优先级的进程所占用,而这个低优先级的进程由于不断被中优先级的进程抢占,使其无法用到CPU,故该低优先级的进程一直无法执行,高优先级的进程也在一直等待(但实际上占用CPU的是中优先级的进程,此时也就是发生了优先级反转),当其等待时间过长时,就会发生重启解决方法:如果有高优先级在等一个共享资源,而这个共享资源被另一个低优先级的进程所占用,我们可以将该低优先级的进程的优先级提到与高优先级进程的优先级一样高(即优先级继承),等它执行完后,再恢复原来的优先级。
Lec 7 synchronization_examples
Lec 8 deadlock
由于考前时间有限,所以没时间整理了qwq,短时间内也没有完善计划

若有收获,就点个赞吧
0 人点赞
