1. transfer(jdk1.7)
void transfer(Entry[] newTable, boolean rehash) {//获取新哈希表的容量int newCapacity = newTable.length;//循环原哈希表for (Entry<K,V> e : table) {//循环原Entry线性链表while(null != e) {Entry<K,V> next = e.next;//根据是否启用rehash判断是否为每一个key生成新的哈希值//如果当前entry的key等于null,则重新设置当前entry的哈希值为0//如果不为null,则对当前entyr的哈希值根据哈希干扰因子(HashSeed)进行重//新计算赋值if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}//根据新的哈希值和新的容量计算该entry应该存放的数组下标位置int i = indexFor(e.hash, newCapacity);e.next = newTable[i];newTable[i] = e;e = next;}}}
我们对以上的语句使用一个示例进行解读:1.分析图解:
1:为了方便计算,假设hash算法为key mod链表长度;
2:初始时数组长度2,key = 3, 7, 5 ,初始在表table[1]节点;3:然后resize后,hash数组长度为4
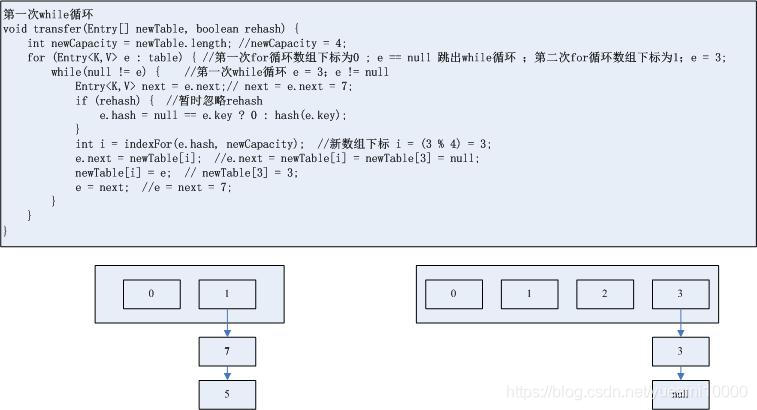
2.第一次while循环
void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length; //newCapacity = 4;for (Entry<K,V> e : table) { //第一次for循环数组下标为0 ; e == null 跳出while循环 ;第二次for循环数组下标为1;e = 3;while(null != e) { //第一次while循环 e = 3;e != nullEntry<K,V> next = e.next;// next = e.next = 7;if (rehash) { //暂时忽略rehashe.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity); //新数组下标 i = (3 % 4) = 3;e.next = newTable[i]; //e.next = newTable[i] = newTable[3] = null;newTable[i] = e; // newTable[3] = 3;e = next; //e = next = 7;}}}
3.第二次while循环
void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length; //newCapacity = 4;for (Entry<K,V> e : table) { //第一次for循环数组下标为0 ; e == null 跳出while循环 ;第二次for循环数组下标为1;e = 3;while(null != e) { // 第二次while 循环 e = 7; e != null;Entry<K,V> next = e.next;// next = e.next = 5;if (rehash) { //暂时忽略rehashe.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity); //新数组下标 i = (7 % 4) = 3;//e.next = newTable[i] = newTable[3] = 3;//这里要清楚newTable[3]的值已经是新数组中的3.//因此这一步的操作实际上是把当前的e(7)的next指针指向了3. -也就是常说的头部插入法e.next = newTable[i];newTable[i] = e; //newTable[3] = 7;e = next; //e = next = 5; 后面while循环及for循环以此类推}}}
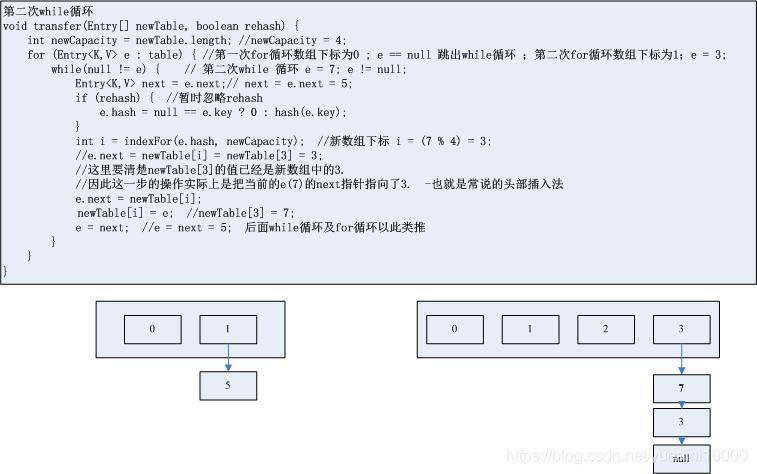
HashMap的转存使用头部插入法。
分析图解:
1:为了方便计算,假设hash算法为key mod链表长度;
2:初始时数组长度2,key = 3, 7, 5 初始在表table[1]节点;
3:然后resize后,hash数组长度为4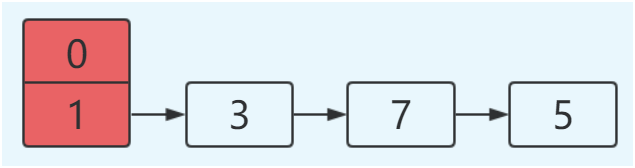
如果不发生异常,正常结果为: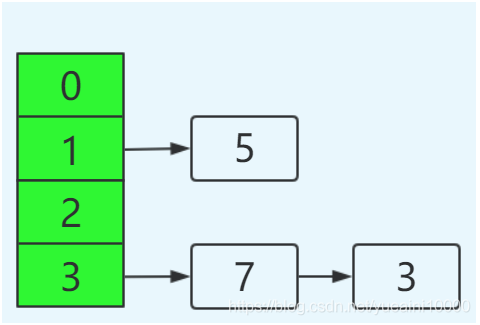
JDK1.7-Hashmap扩容死锁问题
JDK1.7—>-两个线程同时并发的对原数组扩容。由于链表都使用头插法,两个线程在用指针指向后,会形成循环链表。 然后再新数据进入的时候,会先从链表上找是否存在对应的key。然后在循环链表中一直死循环,如法插入。
1:假设线程A在某处挂起
void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;for (Entry<K,V> e : table) {while(null != e) {Entry<K,V> next = e.next;if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);e.next = newTable[i];//线程A在此处挂起newTable[i] = e;e = next;}}}
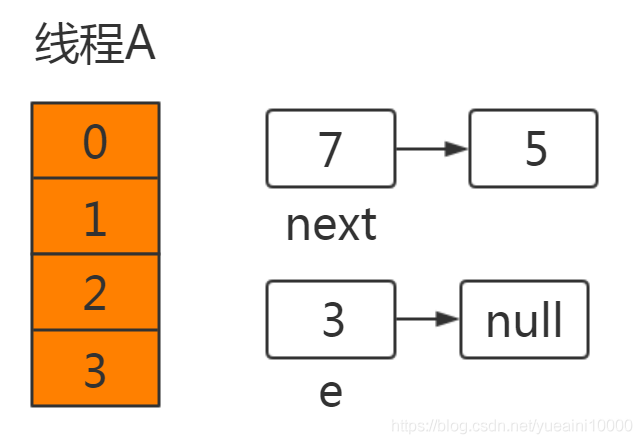
当A挂起后,线程B正常执行完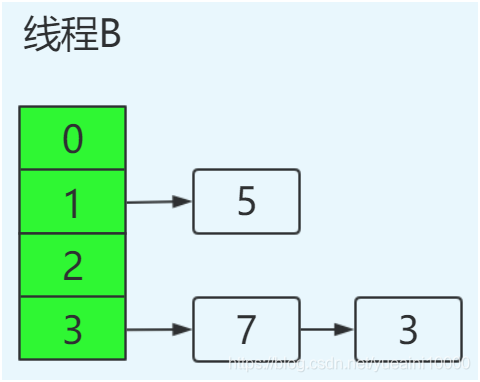
由于线程B已经执行完毕,根据Java内存模型,现在newTable和table中的Entry都是主存中最新值:7.next=3,3.next=null。
此时切换回线程A上,在线程A挂起时继续执行
newTable[i]=e ——> newTable[3]=3
e=next ——> e=7
继续下一次循环,e=7
next=e.next ——> next=3【从主存中取值】
e.next=newTable[3] ——> e.next=3【从主存中取值】
newTable[3]=e ——> newTable[3]=7
e=next ——> e=3
e不为空继续下一次循环 e=3
next=e.next ——> next=null
e.next=newTable[3] ——> e.next=7 即:3.next=7
newTable[3]=e ——> newTable[3]=3
e=next ——> e=null
此次循环后3.next = 7 但上一步 7.next =3 行成环行链表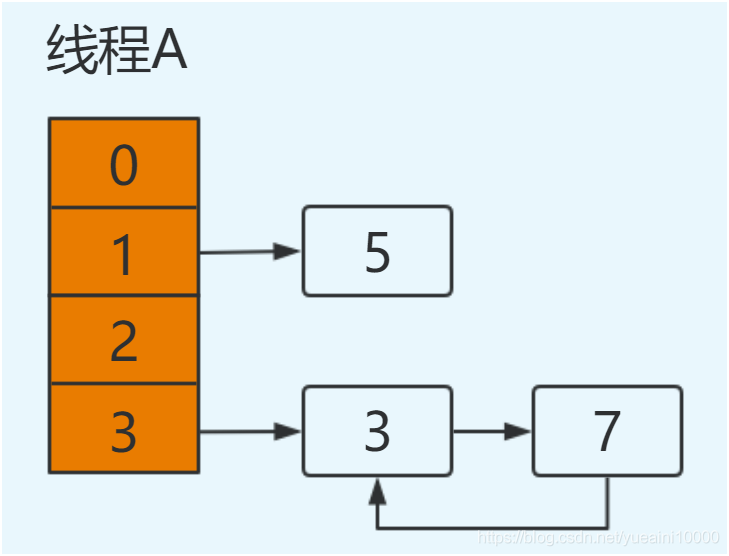
在后续操作中只要涉及轮询hashmap的数据结构,就会在这里发生死循环
JDK1.7-HashMap扩容死锁问题复现
import java.util.HashMap;import java.util.Map;import java.util.concurrent.atomic.AtomicInteger;/*** JDK1.7 HashMap死锁问题复现*/public class TestHashMapThread implements Runnable{//为了尽快扩容,设置初始大小为2private static Map<Integer,Integer> map = new HashMap<>(2);private static AtomicInteger atomicInteger = new AtomicInteger();@Overridepublic void run() {while (atomicInteger.get() < 1000000){map.put(atomicInteger.get(),atomicInteger.get());//往线程中插入值atomicInteger.incrementAndGet();//递增}}public static void main(String[] args){for(int i = 0; i < 10 ; i++){//启动十个线程去做处理new Thread(new TestHashMapThread()).start();}}}
2. JDK1.7-HashMap扩容数据丢失问题
其次,1.7中扩容还会出现数据丢失
模拟另外一种情况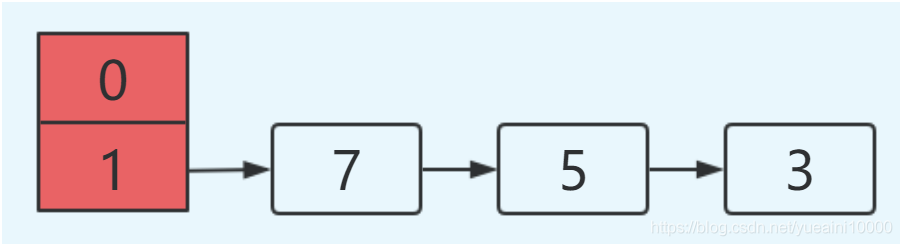
同样线程A在固定位置挂起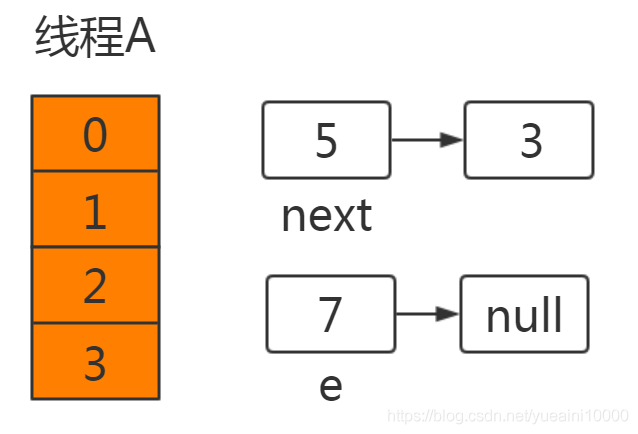
线程B完成扩容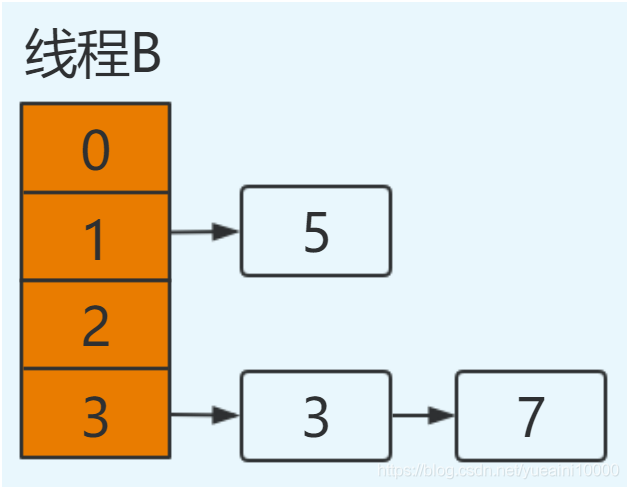
同样注意由于线程B执行完成,newTable和table都为最新值:5.next=null。
此时切换到线程A,在线程A挂起时:e=7,next=5,newTable[3]=null。
执行newtable[i]=e,就将7放在了table[3]的位置,此时next=5。接着进行下一次循环:
e=5
next=e.next ——> next=null,从主存中取值
e.next=newTable[1] ——> e.next=5,从主存中取值
newTable[1]=e ——> newTable[1]=5
e=next ——> e=null
将5放置在table[1]位置,此时e=null循环结束,3元素丢失,并形成环形链表。并在后续操作hashmap时造成死循环。

若有收获,就点个赞吧
0 人点赞
