万维网概述
万维网WWW(World Wide Web)并非某种特殊的计算机网络,万维网是一个大规模的、联机式的信息储藏所。万维网用链接的方法能非常方便地从互联网上的一个站点访问另一个站点,从而主动地按需获取丰富的信息
万维网的工作方式:
①万维网以客户-服务器方式工作
②浏览器就是在用户计算机上的万维网客户程序,万维网文档所驻留的计算机则运行服务器程序,因此这个计算机也称为万维网服务器
③客户程序向服务器程序发出请求,服务器程序向客户程序送回客户所要的万维网文档
④在一个客户程序主窗口上显示的万维网文档称为页面(page)
统一资源定位符URL
资源定位符URL是对可以从互联网上得到的资源的位置和访问方式的一种简洁表示,URL给资源的位置提供一种抽象的识别方法,并用这种方法给资源定位。只要能够对资源定位,系统就可以对资源进行各种操作。URL相当于一个文件名在网络范围的扩展,因此URL是与互联网相连的机器上的任何可访问对象的一个指针
URL的一般形式:由四个部分组成,并且URL中的字符对大小写没有要求:
<协议>://<主机>:<端口>/<路径>
(1)协议:指出使用什么协议来获取万维网文档。最常用的协议是http(超文本传送协议HTTP),其次是ftp(文件传送协议FTP)
(2)主机:指出万维网文档在哪一台主机上,这里的主机就是指该主机在互联网上的域名
(3)端口:有时可省略
(4)路径:有时可省略
使用HTTP的URL:
HTTP的URL的一般形式是:http://<主机>:<端口>/<路径>
HTTP的默认端口号是80,通常可省略。若在省略文件的<路径>项,则URL就指到互联网上的某个主页,可以是一下几个情况之一:
①一个WWW服务器的最高级别的页面
②某一个组织或部门的一个定制的页面或目录
③由某一个人自己设计的描述他本人情况的WWW页面
超文本传送协议HTTP
从层次的角度看,HTTP是面向事务的应用层协议,它是万维网上能够可靠地交换文件(包括文件、声音、图像等各种多媒体文件)的重要基础
万维网的工作过程: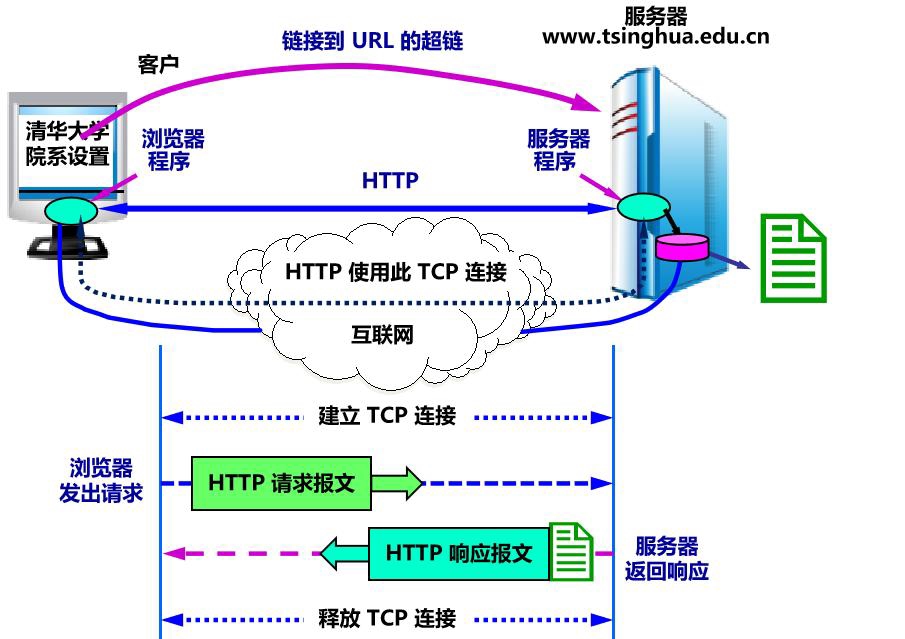
①每个万维网网点都有一个服务器进程,它不断的监听TCP的端口80,以便发现是否有浏览器向它发出连接建立请求
②一旦监听到连接建立请求并建立了TCP连接之后,浏览器就向万维网服务器发出浏览器某个页面的请求,服务器接着就返回所请求的页面作为相应
③最后,TCP连接就被释放了
④在浏览器和服务器之间的请求和响应的交互,必须按照规定的格式和遵循一定的规则,这些格式和规则就是超文本传送协议HTTP
HTTP的主要特点:
①HTTP使用了面向连接的TCP作为运输层协议,保证了数据的可靠传输
②HTTP协议本身也是可连接的,虽然它使用了面向连接的TCP向上提供的服务
③HTTP是面向事务的客户服务器协议
④HTTP1.0协议是无状态的(stateless)
HTTP1.1协议使用持续连接(persistent connection),两种工作过程:
①非流水线方式:客户在收到前一个响应后才能发出下一个请求。这比非持续连接的两倍RTT的开销节省了建立TCP连接的所需的一个RTT时间。但服务器在发送完一个对象后,其TCP连接就处于空闲状态,浪费了服务器资源
②流水线方式:客户在收到HTTP的响应报文之前就能够接着发送新的请求报文。一个接一个的请求报文到达服务器后,服务器就可连续发出响应报文。使用流水线方式时,客户访问所有的对象只需花费一个RTT时间,使TCP连接中的空闲时间减少,提高了下载文档效率
代理服务器:是一种网络实体,又称为万维网高速缓存。代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的请求相同,就返回暂存的响应,而不需要按URL的地址再次去互联网访问该资源
HTTP的报文结构:
HTTP请求报文和响应报文都是由三个部分组成,区别就是开始行不同
(1)开始行:用于区分是请求报文还是响应报文。在请求报文中的开始行叫做请求行(Request-Line),而在响应报文中的开始行叫做状态行(Status-Line)。在开始行的三个字段之间都以空格分隔开,最后的“CR”和“LF”分别代表“回车”和“换行”
(2)首部行:用来说明浏览器、服务器或报文主体的一些信息
(3)实体主体(entity body):在请求报文中一般不用这个字段,而在响应报文中也可能没有这个字段
①请求报文:从客户向服务器发送请求报文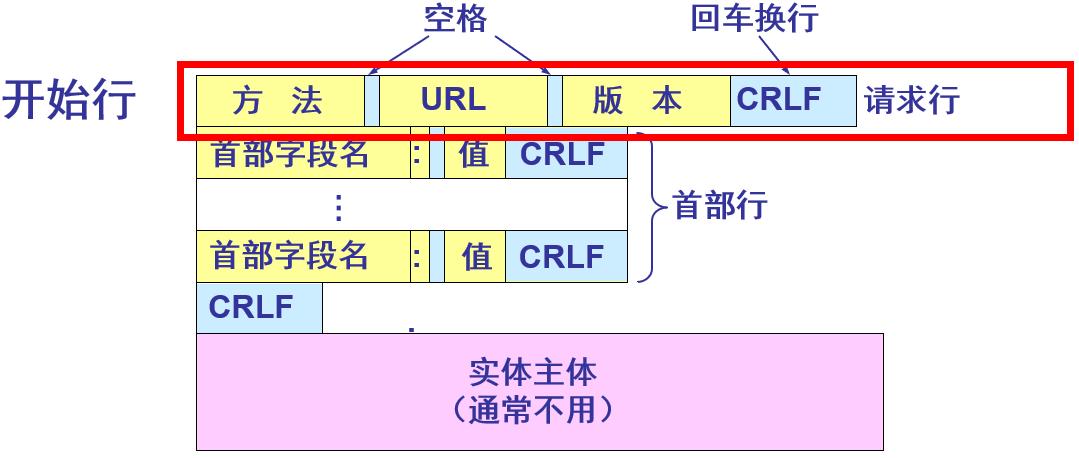
HTTP请求报文的一些方法
| 方法(操作) | 意义 | |
|---|---|---|
| OPTION | 请求一些选项的信息 | |
| GET | 请求读取由URL所标志的信息 | |
| HEAD | 请求读取由URL所标志的信息的首部 | |
| POST | 给服务器添加信息 | |
| PUT | 在指明的URL下存储一个文档 | |
| DELETE | 删除指明的URL所标志的资源 | |
| TRACE | 用来进行环回测试的请求报文 | |
| CONNECT | 用于代理服务器 |
②响应报文:从服务器到客户的回答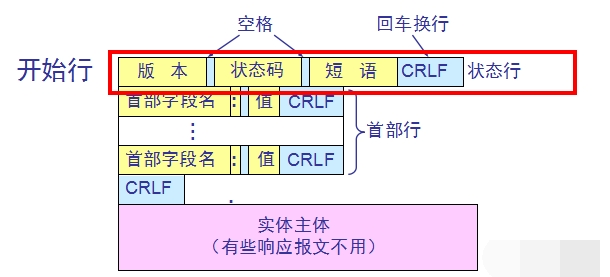
状态码都是三位数字,有五大类:
①1xx表示通知信息
②2xx表示成功
③3xx表示重定向,表示要完成请求还必须采取进一步的措施
④4xx表示客户的差错
⑤5xx表示服务器的差错
万维网的文档
(1)超文本标记语言HTML:HTML把各种标签嵌入到万维网的页面中,这样就构成了所谓的HTML文档,HTML文档是一种可以用任何文本编辑器创建的ASCII码文件
两种不同的链接:
①远程链接:超链的终点是其他网点上的页面
②本地链接:超链指向本计算机中的某个文件
XML(Extensible Markup Language)是可扩展标记语言,设计宗旨是传输数据,而不是显示数据,是对HTML的补充
CSS(Cascading Style Sheets)是层叠样式表,它是一种样式表语言,用于为HTML文档布局定义
CSS与HTML的区别:HTML用于结构化内容,而CSS则用于格式化结构化的内容
(2)动态万维网文档
①静态文档是指该文档创作完毕后就存放在万维网服务器中,在被用户浏览的过程中,内容不会改变
②动态文档是指文档的内容是在浏览器访问万维网服务器时才由应用程序动态创建
③动态文档和静态文档之间的主要差别体现在服务器一端,这主要是文档内容的生成方法不同。而从浏览器的角度看,这两种文档并没有区别
通用网关接口CGI:CGI(Common Gateway Interface)是一种标准,她定义了动态文档应如何创建输入数据应如何提供给应用程序,以及输出结果应如何使用
万维网服务器与CGI的通信遵循CGI标准:
①“通用”:CGI标准所定义的规则对其他任何语言都是通用的
②“网关”:CGI程序的作用像网关
③“接口”:有一些已经定义好的变量和调用等可供其他CGI程序使用
(3)活动万维网文档
活动文档(active document)技术把所有的工作都转移到浏览器端,每当浏览器请求一个活动文档时,服务器就返回一段程序副本在浏览器端运行,活动文档程序可与用户直接交互,并可连续地改变屏幕的显示
万维网的信息检索系统
在万维网中用来进行搜索的程序叫做搜索引擎,全文检索搜索引擎是一种纯技术型的检索工具,它的工作原理是通过软甲到互联网上的各网站收集消息,找到一个网站后可以从这个网站再链接到另一个网站。然后按照一定的规则建立一个很大的在线数据库供用户查询

若有收获,就点个赞吧
0 人点赞
