Task01:基于逻辑回归的分类预测(2天)
打卡截止:08月20日 23:59
天池链接:https://developer.aliyun.com/ai/scenario/9ad3416619b1423180f656d1c9ae44f7
打卡链接:https://shimo.im/forms/KRprat8nJyAETmPU/fill
打卡结果:https://shimo.im/sheets/L9kBMPRZXZFPNLqK/MODOC/
于 2020/8/20 11:15 开始
- 读下作业题目

逻辑回归的应用场景,目前还看不太懂
是一个理解数据的好工具,可以看出特征对结果的影响
可以看到这个教程先实践代码,再讲原理的
- 复习下之前看过的的李宏毅逻辑回归笔记
之前的遗留问题:

12:07 暂停
- 熟悉环境
现在是下午四点二十九分
- 实践
- 带注释
第一遍就先跟着注释,手把手的操作一遍。

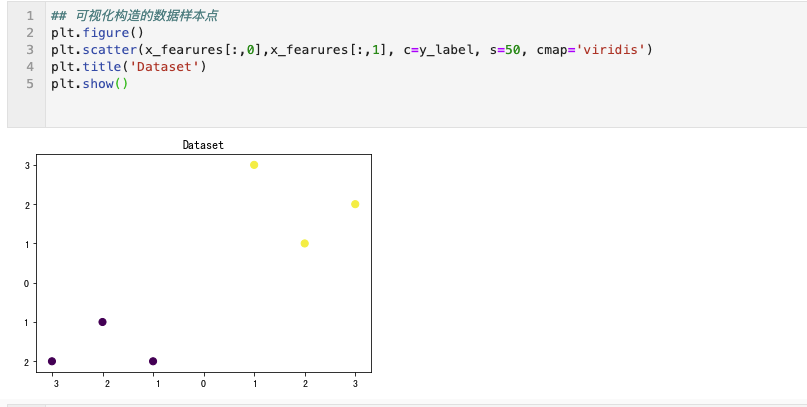



这里面给的例子可以先拷贝过去执行一下,看下效果。然后最好自己在手工的敲一遍。目的是把中间每一步都过一下,有没有不理解的。


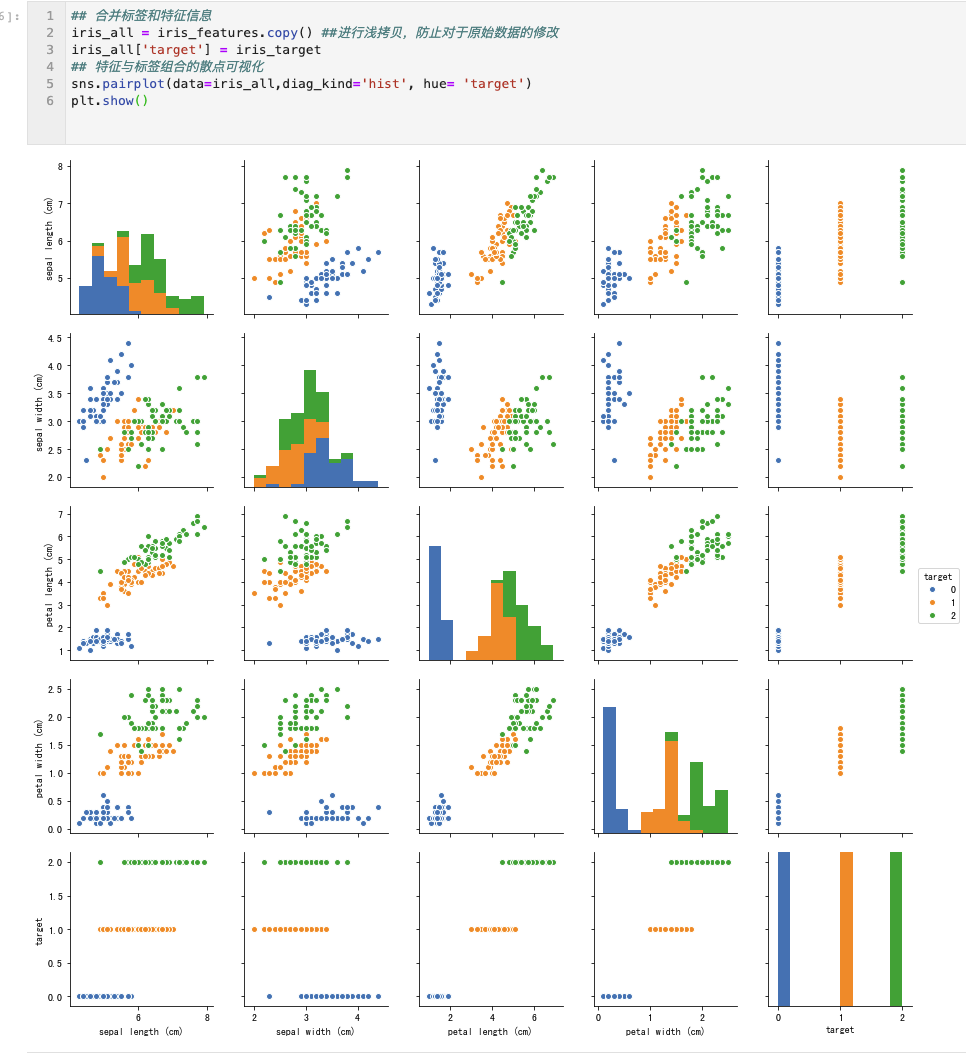

以上都是对现有数据的一些观察。绘图。

然后同样用sk learn的logistic regression。这个方法去训练。一个模型。这块对于模型的参数有了一些调整。
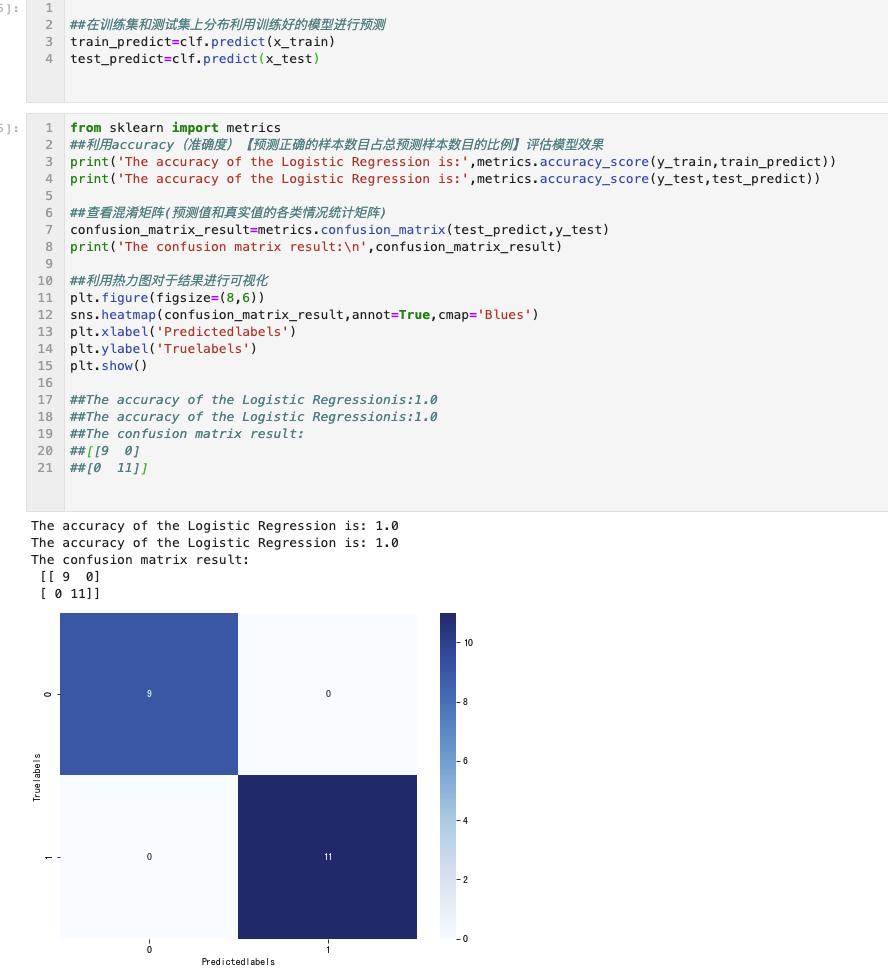
用了几种方法来检验一下测试的准确程度。一个是用accurancy这个方法。方法还有一个用混淆矩阵加热力图的方式。

- 不带注释,自己在本地环境里实现一边例程
[x] 看课件里的理论解释
问题记录:
1、为什么?有些基本的。numpy的用法。还是要在熟悉一下。
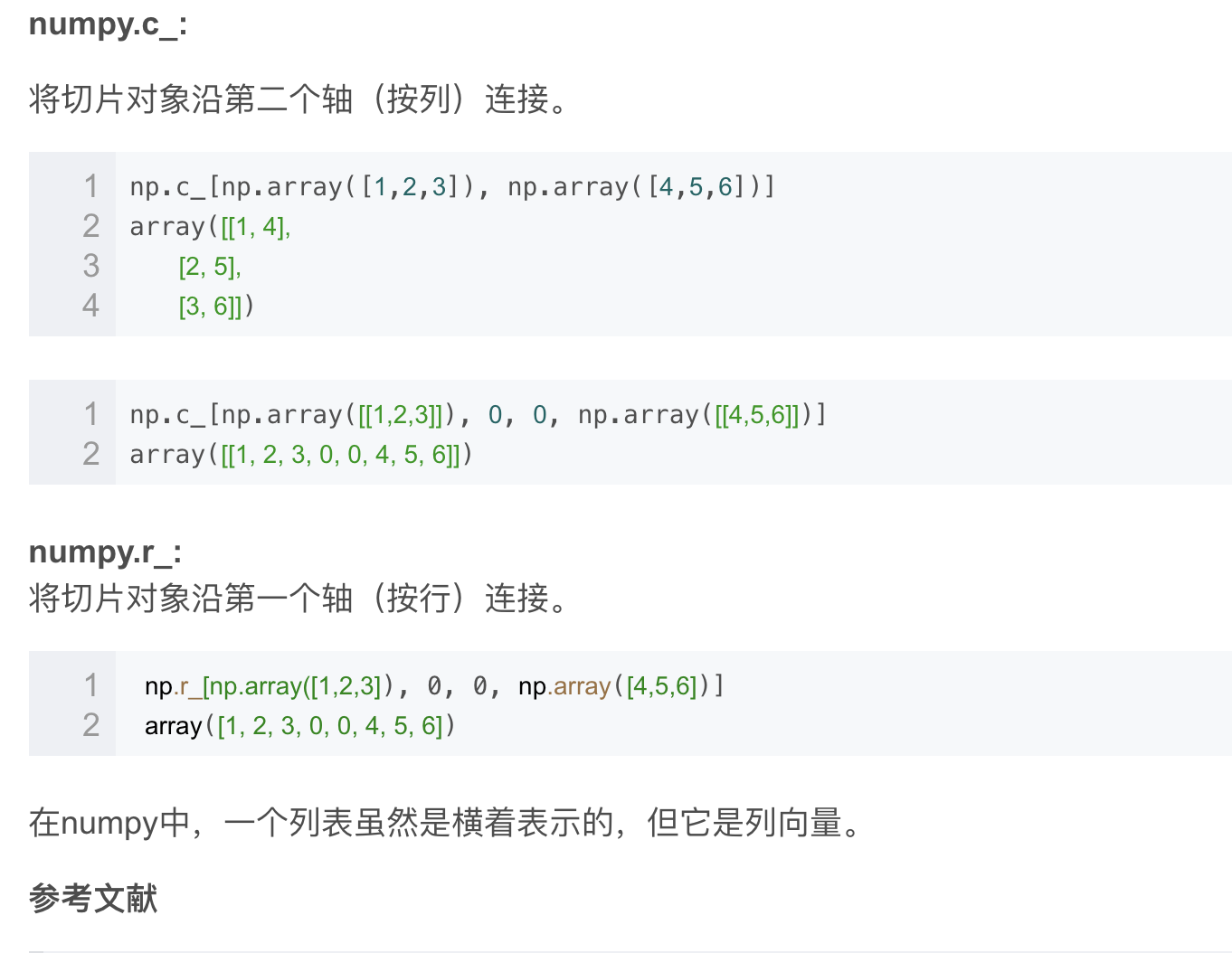
https://docs.scipy.org/doc/numpy-1.15.0/reference/generated/numpy.c_.html
2、需要再根据LogisticsRegression的文档理解下这里的参数的含义

那么这里的solver看起来像是一个优化函数的参数。那么问题就来了,什么时候要用lbfs?什么时候要用其他的

在这一步为什么要查看w和w0?能得出一些可直观理解的信息么?
3、如何看某个特征对决测结果的影响?
总结:
1、用sklearn自带的LogisticsRegression训练一个分类模型
2、可以用混淆矩阵来查看测试的准确程度。
3、用seaborn、matplotlib做数据可视化
数据可视化:
scatter的用法
contour 如何用等高线来画决策边界
seaborn基本用法
3d散点图

若有收获,就点个赞吧
0 人点赞
