Hive使用起来和MySQL差不多吗?
在执行插入数据的时候,发现插入速度极慢,sql执行时间很长,为什么?(在执行插入数据的时候,发现插入速度极慢,sql执行时间很长,为什么)
因为在hive中执行SQL,底层是通过MapReduce执行的,而MapReduce执行就必须从yarn获取资源,所以速度就会很慢
如何才能将结构化数据映射成为表?
在HDFS根目录下创建一个结构化数据文件user.txt,里面内容如下:

在hive中创建一张表t_user。注意:字段的类型顺序要和文件中字段保持一致。
使用HDFS命令将数据移动到表对应的路径下。

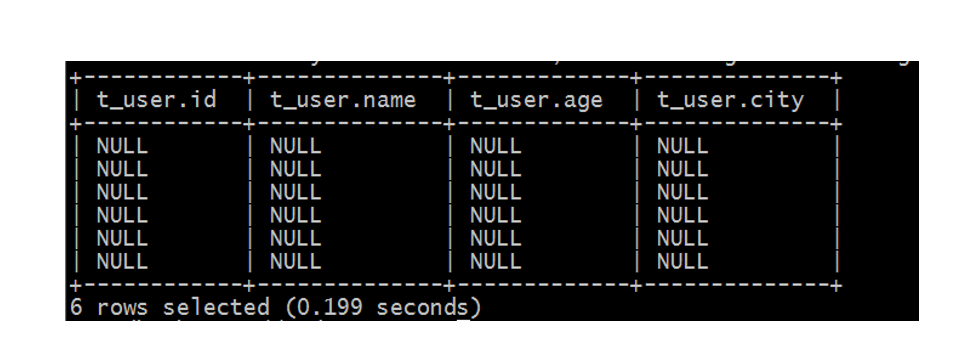
再次执行查询操作,显示如下,都是null好像表感知到结构化文件的存在,但是并没有正确识别文件中的数据。
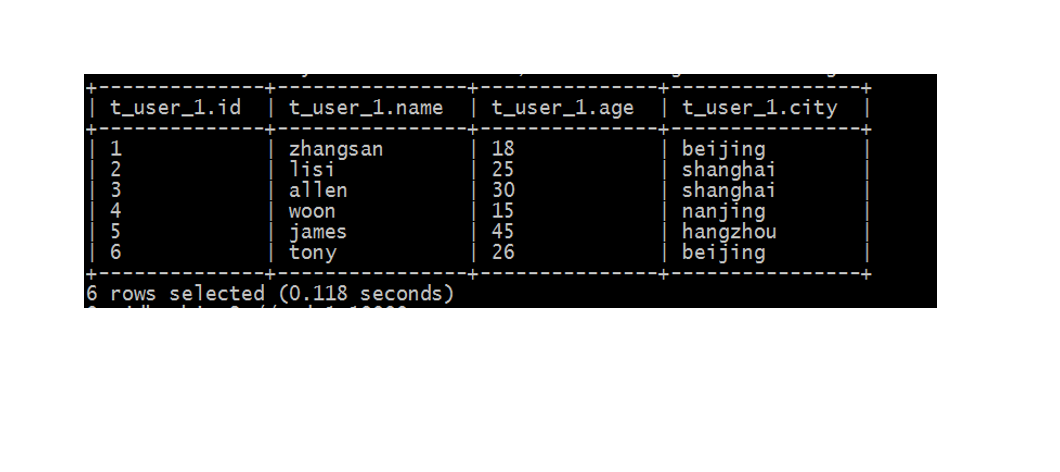
重建张新表,指定分隔符
--建表语句 增加分隔符指定语句create table t_user_1(id int,name varchar(255),age int,city varchar(255))row format delimitedfields terminated by ',';--把user.txt文件从本地文件系统上传到hdfshadoop fs -put user.txt /user/hive/warehouse/itcast.db/t_user_1/--执行查询操作select * from t_user_1;
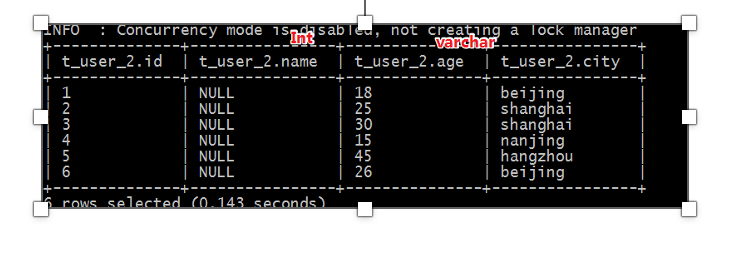
此时再创建一张表,保存分隔符语法,但是故意使得字段类型和文件中不一致。
此时发现,有的列显示null,有的列显示正常。
name字段本身是字符串,但是建表的时候指定int,类型转换不成功;age是数值类型,建表指定字符串类型,可以转换成功。说明hive中具有自带的类型转换功能,但是不一定保证转换成功。

若有收获,就点个赞吧
0 人点赞
