java基础
1.1 面向对象的特征:(了解)
```markdown
面向对象的特征有封装、继承、多态、抽象
封装:一般用private关键字修饰,就是把对象的属性和行为结合成一个独立的整体,并尽可能隐藏对象的内部细节,不让外界随意访问和修改,从而增加安全性
继承:把一些类的共有属性和行为抽取出来,放到一个类或者接口中,也就是我们说的父类或者父接口,子类继承了父类的这些属性和行为,同时可以根据自己的需要,改写扩展新的行为,从而提高了代码的复用性
多态:多态就是多种形态,是父类引用指向子类对象,也就是变量指向的是子类的对象,但是表现的是一个父类的形态,在代码执行期间判断引用对象的实际类型,然后根据实际的类型调用相应的方法;可以调用所有父类的方法,不能调用子类的特有方法;多态配合继承子类重写,实现了子类类型向父类类型向上转型的过程,提高了代码的复用性和扩展性
抽象:一般用abstract关键字来修饰,表示对一系列看上去不同,但是本质上相同的具体概念的抽象,抽象类本身不能实例化,想要实现只能通过继承子类。 ```
ArrayList
扩容机制
扩容是懒惰式的,在没有添加元素之前,即使指定了容量,也不会真正的创建数组;

fail-fast与fail-safe
ArrayList 使用迭代器遍历:快速失败
- 调用迭代器COWItr()的构造方法,然后初始化迭代器的成员变量,其中expectedMdCount是记录遍历开始之前list集合被修改了多少次(是根据集合中被添加了多少个元素);
- 然后调用hasNext()方法判断集合中有没有下一个元素,有就调用next()方法遍历下一个元素;
- 在next()方法中,首先检查mdCount,如果与遍历之前的值不一致,就抛出并发修改异常;
CopyToWriteArrayList使用迭代器遍历:安全失败
- 调用迭代器Itr()的构造方法,然后初始化迭代器的成员变量,在初始化时,将集合元素的数组es保存到snapshot变量中;
- 然后调用hasNext()方法判断集合中有没有下一个元素,有就调用next()方法遍历下一个元素;
- 在add()方法中,把原来的数组es复制一份,
es = Arrays.copyOf(es , len + 1)新数组的长度进行扩容len+1,将添加的新元素放到了复制出来的新数组的最后一位中;添加成功之后,将数组替换成了新数组,但是遍历的时候还是遍历的旧数组;

LinkedList

- 数据结构:数组内存分配上,需要一块连续的内存;而链表结构,不需要连续内存;
- 随机访问:ArrayList 实现了RandomAccess,随机访问根据下标进行访问;LinkedList 起始元素只能记录下一个元素的地址,访问只能通过迭代器的next()方法一个一个去找;
随机访问不等于查询;随机访问是随便根据索引挑一个,查询时根据元素内容去找;如果是根据内容找,随机访问和查询的时间复杂度是一样的;都不适合做查询;- 增删性能:ArrayList 在尾部增删元素性能不错,但是在其他部分插入,要做数据的移动,越靠近头部,元素移动越多,性能越差;LinkedList 头尾部增删快,要往中间插入,需要先通过next()方法查找,根据指针移动定位;所以总结来说,使用ArrayList更多;
- 内存占用:
- ArrayList 可以利用CPU缓存,局部性原理,将相邻的几个元素缓存;
- LinkedList 元素不连续,由一个个node对象组成,包括元素和上一个下一个元素的指针内存地址,内存占用比同容量的 ArrayList 要多;
HashMap
为什么要用红黑树?
因为链表过长之后,会影响整个性能;
链表的时间复杂度是O(n),红黑树的时间复杂度是O(log2n);2为底
为什么一上来不树化?
- 短链表的性能是高于红黑树的;链表短是没有必要转化成红黑树的;
- 链表的数据结构是node,红黑树的数据结构是treenode,treenode的成员变量要比node多很多,占用的内存空间也更多;
树化阈值为什么是8?
红黑树是一种不正常情况,正常情况是不可能超过8的;这种超长链表是被Dos恶意攻击的时候,为了防止链表超长,性能下降,而不是正常情况;树化应当是偶然情况;
- 对于链表,平均时间复杂度是O(n),
- hash值如果足够随机,在hash表中按泊松分布,在负载因子0.75的情况下,长度超过8的出现概率是亿分之6,选择8就是为了让树化几率小;

树化条件:
- 1、链表长度 > 8
- 2、数组长度 ≥ 64
当链表长度超过8,数组长度未达到64时,首先数组扩容;如果再添加元素,链表长度增加,数组还是未达到64,再次扩容;
链表长度是可以超过8的;
退化成链表的条件:
- 扩容时拆分树,如果树元素个数 < 6时,退化成链表;
- remove树节点时,在remove之前检查,如果根节点、根节点左节点、根节点右节点、根节点的左左节点、有一个为空,就会退化成链表;
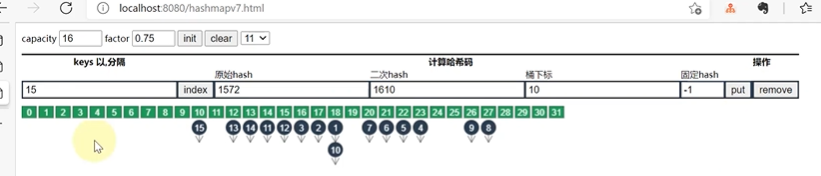
索引如何计算:二次哈希对容量取模
- 计算对象的哈希值,再调用hash()方法进行二次哈希,最后位与(容量-1)计算得到索引;
- 数组容量是2的n次幂时,计算索引,可以通过按位&(容量-1)得到索引,位与计算比普通的计算效率更高;
hashcode都有了,为什么还要hash()方法?
- 结合高位运算,让hash分布更均匀
数组容量为什么是2的n次幂?
- 数组容量采用2的n次幂时,可以采用位与运算,效率更高;

HashMap的put方法流程
- HashMap 是惰性创建数组,首次使用才创建数组;
- 计算索引(桶下标):根据key计算出hashcode,然后根据哈希值进行二次哈希,按位与计算得到桶下标;
- 如果桶下标还没人占用,创建node节点存储键值占位,然后返回;
- 如果已经有人占用:
- ①已经是TreeNode节点,走红黑树的添加或更新逻辑;找到了key就是更新,没有找到key就是添加;
- ②普通node节点,走链表的添加或更新逻辑;如果链表长度超过树化阈值,走树化逻辑;
- 添加完成后,返回前检查容量是否超过阈值,一旦超过阈值,进行扩容;
- 1.7和1.8的区别:
- 链表插入节点时,1.7是头插法,1.8是尾插法;
- 1.7是插入时,超过阈值,并且没有空位时才扩容;而1.8是大于阈值就扩容;
- 1.8在扩容计算node索引时,会优化;把hash和旧的容量做按位与,如果得到的结果为0,那么还在原位置,如果不等于0,那么新位置=旧位置+旧容量;

加载因子为何默认是0.75F
为了在空间占用和查询时间之间取得较好的平衡:
- 大于0.75,空间节省了,但是链表较长会影响性能;
- 小于0.75,链表很短,造成了很大的空间浪费;哈希冲突减少了,但是扩容会更频繁,空间占用会更多;

多线程下会有什么问题?
- 扩容死链(1.7)
- 数据错乱(1.7,1.8):并发丢失数据
key能否为null,作为key的对象有什么要求?
- HashMap 可以为null,但是map的其他实现不可以
String对象的哈希值是怎么设计的,为啥每次乘的都是31?
- 哈希值设计是为了达到比较均匀分布的散列效果,比较好的散列性,每个字符串的hash值足够独特;
- 31×h可以被优化为 32×h - h,从而转换为位右移运算 h <<5 - h;

设计模式 - 单例模式
单例模式的实现方式:饿汉单例、懒汉单例、
饿汉单例
饿汉模式的特点:
- 构造私有,保证不能在类的外部调用构造方法来创建实例对象;
- 提供静态的成员变量,自己调用私有构造创建出来一个唯一实例;类初始化时就创建实例;
- 静态变量私有,通过一个静态方法访问静态成员变量;
public class Singleton {// 1.将构造方法私有化,使其不能在类的外部通过new关键字实例化该类对象。private Singleton() {}// 2.在该类内部产生一个唯一的实例化对象,并且将其封装为private static类型的成员变量。private static final Singleton instance = new Singleton();// 3.定义一个静态方法返回这个唯一对象。public static Singleton getInstance() {return instance;}}
懒汉单例:
懒汉单例设计模式就是调用getInstance()方法时实例才被创建,先不急着实例化出对象,等要用的时候才实例化出对象。不着急,故称为“懒汉模式”;
注意:懒汉单例设计模式在多线程环境下可能会实例化出多个对象,不能保证单例的状态,所以加上关键字:synchronized,保证其同步安全;
//在方法上面加synchronizedpublic class Singleton {// 2.在该类内部产生一个唯一的实例化对象,并且将其封装为private static类型的成员变量。private static Singleton instance;// 1.将构造方法私有化,使其不能在类的外部通过new关键字实例化该类对象。private Singleton() {}// 3.定义一个静态方法返回这个唯一对象。要用的时候才例化出对象public static synchronized Singleton getInstance() {if(instance == null) {instance = new Singleton();}return instance;}}//双检锁public class Singleton {// 2.在该类内部产生一个唯一的实例化对象,并且将其封装为private static类型的成员变量。private static Singleton instance;// 1.将构造方法私有化,使其不能在类的外部通过new关键字实例化该类对象。private Singleton() {}// 3.定义一个静态方法返回这个唯一对象。要用的时候才例化出对象public static Singleton getInstance() {if(instance == null) {synchronized (Singleton.class){if(instance==null){instance = new Singleton();}}}return instance;}}
反射
# java代码代码状态 源码 -> 编译 -> 运行文件类型 java类 class文件 Class对象通过转换 编译器 类加载器 JVM# 反射反射是一种机制,利用该机制可以在程序运行过程中对类进行解剖并操作类中所有成员(成员变量,成员方法,构造方法)1. 是什么:运行时操作类1)类加载器:将字节码文件加载进内存,以此创建出Class对象反射就是操作Class对象的技术,类中所见皆可得那么Class对象有什么呢?主要有以下三部分内容1). 构造方法 Constructor2). 方法 Method3). 属性 Field2)使用反射操作类成员的前提:要获得该类字节码文件对象,就是Class对象Class对象的获取方式(三种方式)I.通过类名.class获取// 获得Student类对应的Class对象Class c1 = Student.class;II.通过对象名.getclass()获得// 创建学生对象Student stu = new Student();// 通过getClass方法Class c2 = stu.getClass();III.通过Class类的静态方法获取:static Class forName("类全名")每一个类的Class对象都只有一个// 通过Class类的静态方法获得: static Class forName("类全名")Class c3 = Class.forName("com.itheima._03反射.Student");3)Class类常用方法String getSimpleName(); 获得类名字符串:类名String getName(); 获得类全名:包名+类名T newInstance() ; 创建Class对象关联类的对象2. 为什么:作用:提高代码的复用性,解耦主要运用场景:编写框架3. 怎么做:1). 反射操作构造方法 (重要)//1. 获取Class对象//2. 获取此类的构造方法对象//3. 暴力反射: 访问一个类私有内容//4. 根据指定的参数创建对象2). 反射操作方法 (重要)3). 反射操作属性 (了解)
动态代理
# 动态代理
1. 是什么?
动态:在运行时动态的生成代理类;
底层是反射,通过类加载器,将字节码文件加载进内存,创建Class对象
代理:代理模式/装饰模式在,在不改变原有类的情况下,增强这个类的功能;
接口:obj和proxy要实现相同的接口
被代理类 obj :实际干活的对象
代理类 proxy :包装obj,增强obj,实际底层操作obj干活
2. 为什么?
动态创建代理对象原理:
1)第一步:loader + interfaces(继承+反射) -> 代理类Class对象
运行时:jvm底层会创建一个类,去实现interfaces中的所有接口;
重写接口中的所有抽象方法,每个方法都调用h.invoke方法,生成的是一个字节码文件;
通过类加载器loader将字节码文件加载到JVM内存中,创建代理类的Class对象
2)第二步:InvocationHandler h(多态+反射)
问题:JVM创建类实现接口,无法预知业务重写方法
通过反射创建了Class对象的实例
3. 怎么做?
1) 创建被代理对象
new 代理类();
2) 创建代理对象
3) 方法调用
MySQL
难点1:报表案例
行列转换
#语法:case when 条件 then 结果 end
难点2:子查询
- ```markdown
子查询:
- 子查询作为where条件存在 ,使用关键字:> = != in
- 子查询作为临时表存在,和其他表连接查询
子查询作为字段存在 1) 语法:
select 字段1,(select 字段 from 表1 where 表1.字段=表2.字段) from 表22) 解释说明:
表1.主键=表2.外键```
JDBC
1、jdbc
# jdbc开发步骤:
1. 注册驱动
2. 连接数据库,获取连接对象
DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/数据库名","用户名","用户密码")
3.
Mybatis
1、使用中遇到的问题:
//1、报错问题:
-- binding:报错绑定异常,接口名与映射文件不一致,方法名不一致等
-- setting driver:驱动错误(驱动名、jdbc.properties文件行后是否有空格)
-- use password :YES :密码错误
-- 配置文件找不到,空指针异常:
-- reflection exception ,There is no getter for property named 'name':映射文件的字段名与实体类的属性名不一致
-- SQL synax:SQL语法错误:检查SQL语句
2、介绍Mybatis框架
# Mybatis是什么?对比jdbc有什么特点?和Spring有什么区别?
1. 是什么:
Mybatis是一款优秀的持久层框架,一个ORM对象关系映射的半框架,支持定制化SQL、存储过程以及高级映射。避免了几乎所有的JDBC代码和手动设置参数以及获取结果集;
2. 对比jdbc:
1) 优点:
2) 缺点:
3. 对比Spring:
1) 优点:
2) 缺点:
1. 在Mybatis中,#{}和${}的区别是什么
- ```java // #{}是占位符,做预编译处理;${}是字符串替换;
/ Mybatis在处理#{}时,将sql中的#{}替换为?号,调用PreparedStatement的set方法来进行赋值操作; 可以有效防止SQL注入,提高系统安全性;/
//Mybatis在处理${}时,就是直接替换为变量的值
<a name="bbd1177b"></a>
#### 2. 在Mybatis中,resultType和resultMap的区别是什么?(必会)
-
```java
resultType:
/*如果数据库结果集中的列名和要封装的实体类的属性名完全一致,用resultType;*/
resultMap:
/*如果数据库结果集中的列名和要封装的实体类的属性名有不一致的情况用resultMap属性;通过resultMap手动建立对象关系映射,resultMap要配置一下表和类的一一对应关系,即使字段名和属性名不一致,也可以映射。*/
3. 在Mybatis中,动态SQL的标签有哪些?作用分别是什么?(必会)
- ```java 1、if标签:判断语句,用于进行逻辑判断,传入的值是否符合某种规则,如果为true,那么if标签的文本内容会参与SQL的拼接;
2、choose标签:分支选择,遇到成立的条件就停止,从多个when子标签的选择中选择一个进行SQL拼接,如果都不符合,则执行otherwise子标签;
3、where标签:用来做动态拼接查询条件,和if标签配合拼接多条件查询,能够添加where关键字,能够去除多余的and或者or关键字;
4、foreach标签:把传入的集合或者数组对象进行遍历,然后把每一项内容作为参数传到sql语句中;
5、include标签:把大量的重复代码整理起来,当使用的时候直接include,减少重复代码的编写;
6、set标签:适用于更新标签,搭配if条件使用,当匹配某个条件后,才会对该字段进行更新操作,可以自动添加一个set关键字,并且将动态sql最后多余的逗号去除;
<a name="dc573bc4"></a>
#### 4. foreach遍历使用
```markdown
//2、foreach语句
<foreach collection="list" item="item" separator="," open="(" close=")">
#{item.name},#{item.age}
</foreach>
5.Mybatis缓存机制(了解)
一级缓存:基础PerpetualCache的HashMap本地缓存,其存储作用域为Session,当Session flush或close之后,Session中的所有Cache就将清空
二级缓存其存储作用域为Mapper(Namespace),使用二级缓存属性类需要实现Serializable序列化接口
对于缓存数据更新机制,当某一个作用域(一级缓存Session/二级缓存Namespaces)的进行了C(增加)/U(更新)/D(删除)操作后,默认该作用域下所有select中的缓存将被clear,需要在setting全局参数中配置开启二级缓存;
//当我们的配置文件配置了cacheEnabled=true时,就会开启二级缓存,二级缓存是mapper级别的,如果你配置了二级缓存,那么查询数据的顺序应该为:二级缓存→一级缓存→数据库。
- <br />
<a name="MybatisPlus"></a>
## MybatisPlus
```markdown
能在controller层用service来写就用service调用方法
主要是单表操作
多表操作一定要在service层用mapper来写
因为涉及不同的事务,可以用MyBatisPlus操作,但是很麻烦,还是用MyBatis来写
# 查询操作:四个方法
单个查询用 get
1. getById(T t)
2. getOne(wrapper)
多个查询用list
1. listByIds(Conllections`<T>` t)
2. list(wrapper)
# 新增
# 更新
# 删除
web
怎么在浏览器显示的页面中输入信息?form表单用来设置提交表单的方式
- ```java //利用html表单标签,通过表单提交的方式,实现数据向服务器的发送;如果数据需要提交到服务器,负责收集数据的标签必须存放在表单标签体内。
//form表单用来设置提交表单的方式有两种:GET和POST 两者的区别: //1、GET是默认提交方式,提交的数据放在url中,post不是,而get提交的数据都会追加在请求路径后面,显示到浏览器的地址栏中,导致数据更不安全;(post也不安全,因为HTTP是明文传输,抓包就能获取数据内容,要想安全还要加密;
//2、get回退浏览器无害(get会保存在浏览器历史记录中,可以被缓存,方法回退后浏览器在缓存中拿结果,post不能缓存,方法回退后,会再次提交请求(post每次提交都会创建新资源);
//3、get提交的数据大小有限制(是浏览器对url的长度有限制,get本身没有限制),post提交是没有数据限制的;
4、get可以被保存为书签,可以分享,post不可以;
应用区别: 平时get和post通用,但是在提交文件时用post ```

若有收获,就点个赞吧
0 人点赞
