RedisCluster集群
redis数据结构: 5种 value hash list zset set
redis基于内存: 持久化: RDB AOF
redis结构: value 热点文章: zset hotlist 文章value score 得分 文章value score 得分 文章value score 得分
redis操作: Spring Data Redis RedisTemplate
redis基于内存(2G): redis key的淘汰机制
redis保证高可用: 主 (redis写) 从 读 从 读
哨兵模式: redis:2.8 哨兵模式 哨兵模式 哨兵模式
主 从 从
集群模式:cluster redis: 3.0
redis集群分析
为何要搭建 Redis 集群。Redis 是在内存中保存数据的,而我们的电脑一般内存都不大,
这也就意味着 Redis 不适合存储大数据,适合存储大数据的是 Hadoop 生态系统的 Hbase 或
者是 MongoDB。Redis 更适合处理高并发,一台设备的存储能力是很有限的,但是多台设备
协同合作,就可以让内存增大很多倍,这就需要用到集群。
目的:解决高并发和海量数据存储的问题
redisCluster总结
http://www.redis.cn/topics/cluster-tutorial.html
1、redis 3.0 之后版本支持 redis-cluster 集群
2、Redis-Cluster 采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。任何一个节点都是Redis的入口
3、redis中存储的每一个主节点(Master)的数据都是不同
4、redis的内部通信是redis 节点彼此互联(PING-PONG 机制),内部使用二进制协议优化传输速度
5、分布存储机制- 槽【16384】,默认是0-16383个槽
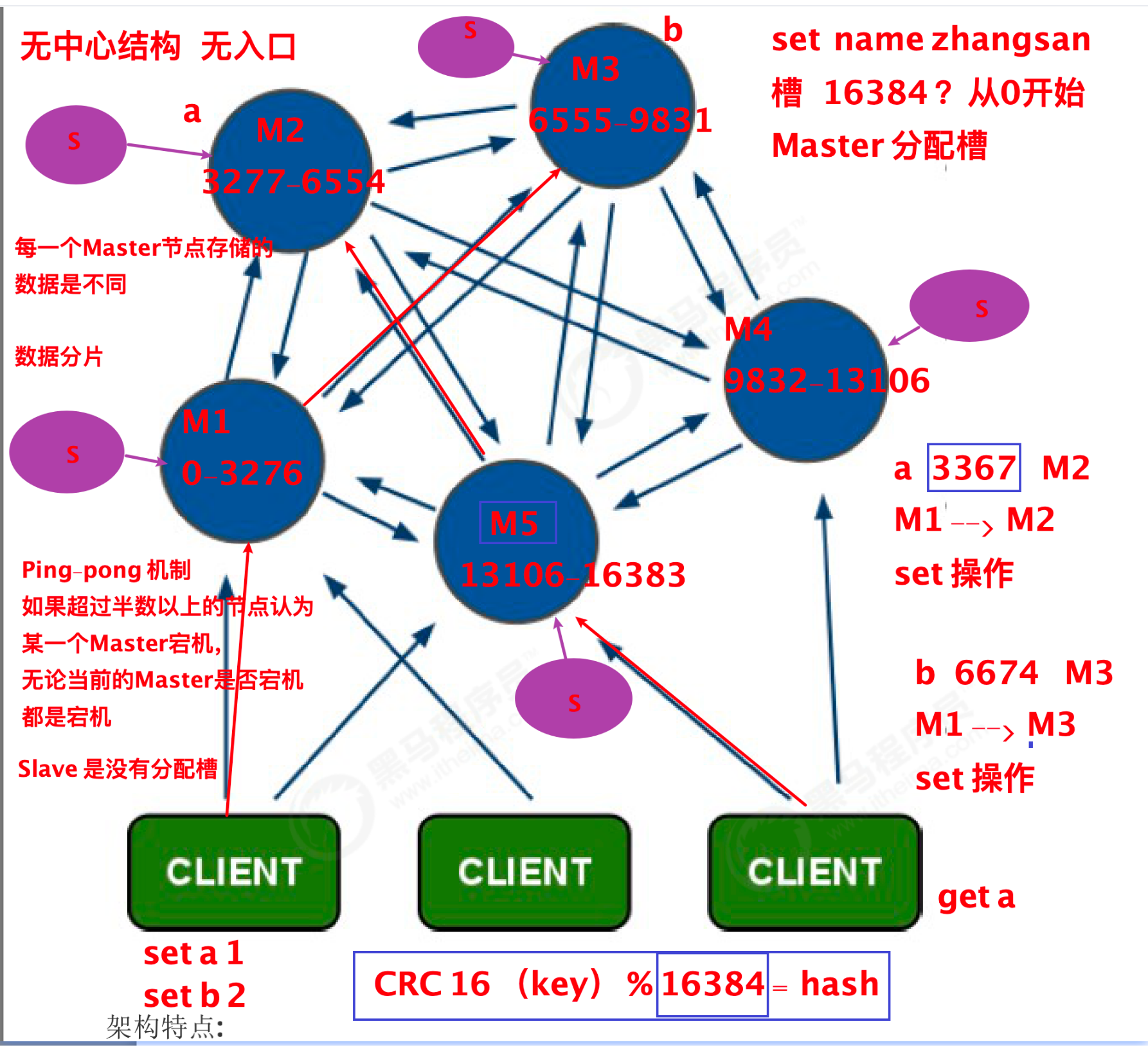

6、投票容错机制, 超过半数以上的节点认为某一台redis宕机, 那么无论当前redis节点是否宕机。都认为当前节点时宕机状态。所以redis中的分配槽时至少3台。建议是奇数台服务。保证redis的高可用所以我们每一个槽的redis服务都有一个从节点。此时至少6台。主写从读
master 单数 3 master 3 slave
(1)选举过程是集群中所有 master 参与,如果半数以上 master 节点与故障节点通信超过
(cluster-node-timeout),认为该节点故障,自动触发故障转移操作. 故障节点对应的从节点自动升级为主节点
(2)什么时候整个集群不可用(cluster_state:fail)?
如果集群任意 master 挂掉,且当前 master 没有 slave.集群进入 fail 状态,也可以理解成集
群的 slot 映射[0-16383]不完成时进入 fail 状态.
7、redis集群中从节点时不存在 槽的,只有主节点上可以分配槽

若有收获,就点个赞吧
0 人点赞
