1.SeaweedFS综述
1.1 功能概述
SeaweedFS是一款开源的分布式文件系统,其核心功能是文件存储,下面是我们需要关注的核心的功能:
- 对象存储接口,支持HTTP协议;
- 支持Amazon S3接口;
- 支持FUSE模式,可以将SeaweedFS挂载到本地目录下;
- 内嵌HTTP服务器,支持e-tag,last-modified,支持浏览器缓存;
- HTTP URL固定,方便CDN;
- 可以通过nginx做URL mapping;
- 支持断点续传;
- 支持大文件分块上传;
- 支持缩略图功能;
- 支持基于TTL的文件级别的老化,也支持collection对文件分类,可以按照collection进行老化;
- 支持JWT鉴权。
上述功能满足B+使用需求,可以作为B+的分布式文件系统使用。
1.2 设计理念和概念
SeaweedFS官方提到了两点设计目的:
- 存储百亿级别文件;
- 提供高效的文件存储服务。
从官方的说明来看,SeaweedFS主要针对小文件的存储进行了优化,其所有的理论基础来自FaceBook的论文:Facebook’s Haystack design paper以及f4: Facebook’s Warm BLOB Storage System。
SeaweedFS有两个重要的服务器角色概念分别是Master和Volume,为了降低Master负载,提升并发处理能力,Master仅仅存储文件和Volume的映射关系,文件本身和存储的元数据信息都是保存在各自的Volume上的。
下面我们来解释几个概念:
- Master:用于保存fid和volume的映射关系;
- DataCenter:对应物理机架,一个DC可能有多个机架;
- Rack:机架,即物理机架,一个机架上至少有一台服务器;
- Volume:这是一个逻辑概念,复制也是基于Volume的;
- Needle:存储的文件称作Needle,现在版本下一个needle最大4G;
- Filer:文件管理器,将文件上传到Volume Server并写入元数据;
- Mount:即FUSE;
- Collection:可以理解为文件的分类,在上传文件的时候指定collection即可。
对于一个机房来说,我们认为这是一个数据中心,那么可以画出一个简单的架构示意图:
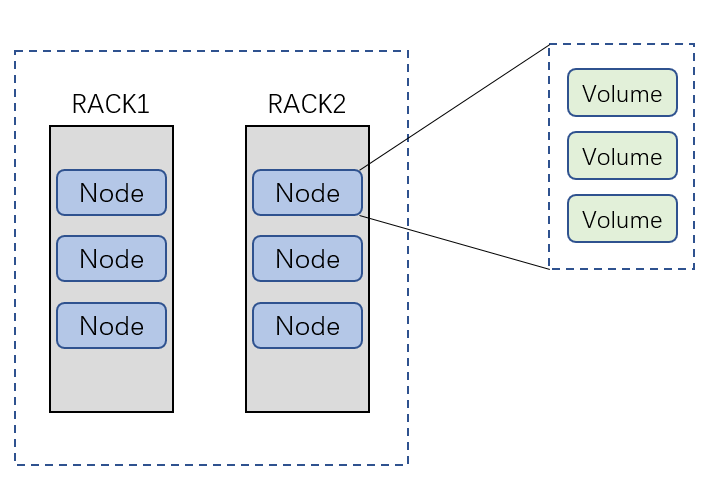
这里还有一个Master的概念,Master服务器主要的工作是分配fid和保存一些简单的fid和location的对应关系,因此保证Master的高可用也是很重要的。官方推荐了Master的集群方式进行部署,可以使用三个以上的奇数台机器组成Master的集群,保证leader宕机之后能够重新选出新的leader。
明确了上述概念之后我们可以大致得到SeaweedFS的工作步骤:

作为分布式文件系统,保证数据不丢失是最重要的要求。SeaweedFS支持基于Volume的复制,将数据保存几个副本,保证数据的安全性。
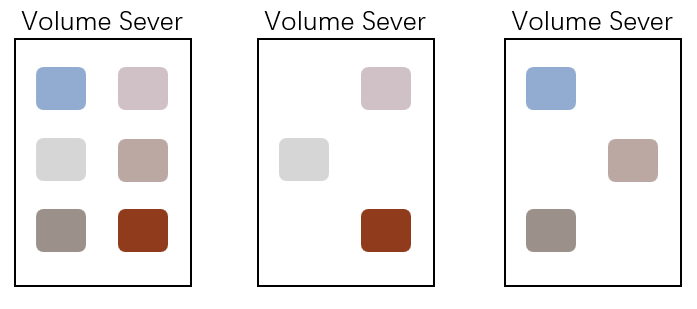
每个节点上都会有一个Volume的副本,因此当原本的Volume出现问题之后,或者当机器宕机的时候,其他的节点仍旧能够访问。
SeaweedFS支持不同的复制策略,官方用三个标志位表示(x,y,z):
- x:在其他数据中心的副本数;
- y:在同一数据中心内不同机架上的副本数;
- z:在同一机架内的副本数。
上图的复制示意图就是配置为001的复制,每个volume是一个色块,统一上传到最左边的服务器上,根据复制策略就会复制到不同的Volume Server上。所有三个标志位的取值都只有0,1,2三种,即一个Volume在一个复制单元内最多只能被复制2次。
在启动Master的时候指定复制策略即可自动开始复制操作,在上传文件或者申请fid的时候,也可以指定文件的复制策略,这是文件级别的复制策略而不是全局的,这是一个比较灵活的特性。
本文中,用于测试的集群有三台机器,Master和Volume Server角色各自有三台。
1.3 核心功能点
作为一款分布式文件系统,文件的管理是必须的功能,SeaweedFS支持文件的上传,下载,删除等基本功能。
上传文件
**
Master和Volume都提供了文件上传接口,filer还提供了带有路径的文件上传接口。可以在上传文件的时候指定各种特定,例如ttl,collection等等,详情参考6.1小节的API文档。
下载文件
Master,Volume和filer接口都提供了文件下载接口,对于图片文件,还提供了裁剪功能,可以在http请求中指定长宽参数,对图片进行裁剪。
缩略图部分,其官方文档并未提及如何实现,观察代码发现其利用了一个第三方组件,对图片进行了裁剪,裁剪后的内容并不会保存在SeaweedFS上,第三方组件参考连接:imaging。
删除文件
**
Master不提供删除文件接口,删除文件接口仅Volume提供,filer接口也提供该功能。
删除Collection
Master提供删除Collection的接口,Volume没有提供删除Collection接口。
2. SeaweedFS的部署
本小节中限于测试机器有限,因此只演示了如何在单一数据中心中部署一个机架的情况,实际生产中,至少应该保证双机房配置,每个机房至少一个机架。
下表中是服务器和端口规划:
| 服务器地址 | 角色 | 端口 |
|---|---|---|
| XA-DEV-SFS-001 | Master/VolumeServer/Filer | 9333/9222/8888 |
| XA-DEV-SFS-002 | Master/VolumeServer/Filer | 9333/9222/8888 |
| XA-DEV-SFS-003 | Master/VolumeServer/Filer | 9333/9222/8888 |
在每一台服务器上执行下面的命令,注意注释:
# 节点1上执行nohup weed master -ip=XA-DEV-SFS-001 -port=9333 -mdir=/usr/local/seaweedFs/data -peers=XA-DEV-SFS-001:9333,XA-DEV-SFS-002:9333,XA-DEV-SFS-003:9333 -defaultReplication=001 > /usr/local/seaweedFs/data/master.log &# 节点2上执行nohup weed master -ip=XA-DEV-SFS-001 -port=9333 -mdir=/usr/local/seaweedFs/data -peers=XA-DEV-SFS-001:9333,XA-DEV-SFS-002:9333,XA-DEV-SFS-003:9333 -defaultReplication=001 > /usr/local/seaweedFs/data/master.log &# 节点3上执行nohup weed master -ip=XA-DEV-SFS-001 -port=9333 -mdir=/usr/local/seaweedFs/data -peers=XA-DEV-SFS-001:9333,XA-DEV-SFS-002:9333,XA-DEV-SFS-003:9333 -defaultReplication=001 > /usr/local/seaweedFs/data/master.log &
这样以后我们可以在节点1的日志里看到如下的信息:

因为最开始只启动了一台节点,会将这台节点选为主,其他节点启动之后自动加入到集群中,并以节点1为主。
注意这里有一个复制选项:“-defaultReplication=001”,代表在本机架内进行复制,这个参数要和启动volume的时候的rack参数配合使用,下面的命令就是用于启动volume的:
# 节点1上执行nohup weed volume -dataCenter dc1 -rack rack1 -dir /usr/local/seaweedFs/volume -ip XA-DEV-SFS-001 -port 9222 -max 20 -ip.bind XA-DEV-SFS-001 -mserver XA-DEV-SFS-001:9333,XA-DEV-SFS-002:9333,XA-DEV-SFS-003:9333 -publicUrl XA-DEV-SFS-001:9222 > /usr/local/seaweedFs/data/volume.log &# 节点2上执行nohup weed volume -dataCenter dc1 -rack rack1 -dir /usr/local/seaweedFs/volume -ip XA-DEV-SFS-002 -port 9222 -max 20 -ip.bind XA-DEV-SFS-002 -mserver XA-DEV-SFS-001:9333,XA-DEV-SFS-002:9333,XA-DEV-SFS-003:9333 -publicUrl XA-DEV-SFS-002:9222 > /usr/local/seaweedFs/data/volume.log &# 节点3上执行nohup weed volume -dataCenter dc1 -rack rack1 -dir /usr/local/seaweedFs/volume -ip XA-DEV-SFS-003 -port 9222 -max 20 -ip.bind XA-DEV-SFS-003 -mserver XA-DEV-SFS-001:9333,XA-DEV-SFS-002:9333,XA-DEV-SFS-003:9333 -publicUrl XA-DEV-SFS-003:9222 > /usr/local/seaweedFs/data/volume.log &
启动volume的时候指定了rack,刚才的master中配置了复制选项,因此复制一定会在这三个节点内进行。
此时就可以开始使用postman等工具开始上传文件了,基本的步骤如下:
- 发送get请求,获得一个fid,一个url;
- 发送post请求,请求参数分别是上一步返回的url和fid,以及要上传的文件。
这样的话比较麻烦,因为多了一步assign的操作,SeaweedFS提供filer来解决这个问题。下面的步骤用于部署Filer。
首先要执行下面的命令生成配置文件:
weed scaffold -config=filer -output="."
此命令执行完之后会在当前目录下生成一个配置文件,将这个文件mv到/etc/seaweedfs下。这个文件默认会使用levelDB作为Filer元数据存储,我们可以利用更加熟悉的MySQL,只需要修改配置文件,将[levelDB]标签下的enable改成false:

开启和配置MySQL的选项(要在目标数据库服务器上新建需要的数据库和数据表):

注意: 生成的文件有一个bug,会导致错误,在文件的[redis]标签下,94行和96行,将这两行删掉,这个bug已经提了issue给作者,并且被作者fix了:

每一个节点都要执行这些操作,然后使用如下命令启动:
# 节点1上执行
nohup weed filer -dataCenter dc1 -master=XA-DEV-SFS-001:9333,XA-DEV-SFS-002:9333,XA-DEV-SFS-003:9333 -ip=XA-DEV-SFS-001 -port=8888 &
# 节点2上执行
nohup weed filer -dataCenter dc1 -master=XA-DEV-SFS-001:9333,XA-DEV-SFS-002:9333,XA-DEV-SFS-003:9333 -ip=XA-DEV-SFS-002 -port=8888 &
# 节点3上执行
nohup weed filer -dataCenter dc1 -master=XA-DEV-SFS-001:9333,XA-DEV-SFS-002:9333,XA-DEV-SFS-003:9333 -ip=XA-DEV-SFS-003 -port=8888 &
此时观察master的日志能看到下面的输出:

启动了Filer之后就能直接利用postman等工具进行上传操作了,不需要在执行assign操作:
## 官方样例
curl -F file=@report.js "http://XA-DEV-SFS-001:8888/javascript/"
返回如下:

这些数据可以记录到数据库中,作为元数据存储。
3. 鉴权机制
SeaweedFS支持基于JWT的鉴权机制。启动也相对简单,需要生成一个安全配置文件,修改其中关于JWT的部分即可。然后将这个安全配置文件分发到集群内的所有机器上去,就完成了安全配置。
- 请求fid的时候,response中的header部分会携带JWT,有效时间为10秒;
- 请求volume API的时候,request中要携带JWT,Volume Server校验通过后才能继续操作。
关于JWT安全机制的更多信息还需要参考官方的wiki:SeaweedFS安全配置。
3. FUSE支持
FUSE是用户态文件系统的简称(Filesystem in Userspace),可以用下面的命令简单的实现:
# 节点1上执行
nohup weed mount -filer=XA-DEV-SFS-001:8888 -dir=/usr/local/seaweedFs/mount &
# 节点2上执行
nohup weed mount -filer=XA-DEV-SFS-002:8888 -dir=/usr/local/seaweedFs/mount &
# 节点3上执行
nohup weed mount -filer=XA-DEV-SFS-003:8888 -dir=/usr/local/seaweedFs/mount &
原理来说,可以将SeaweedFS挂载到本地的任何一个目录下面,将其当做一个目录来使用,注意,这个功能不适用于Windows系统。
FUSE的性能可以用标准化的工具sysbench来测试,官方提供的测试样例是读写总共1GB大小的文件,这种测试样例可以测试出磁盘的IO能力。
这样之后也可以在文件系统上看到我们通过API上传上来的文件,也可以直接将文件放在该目录下,执行官方提供的sysbench,单线程随机读写结果如下:

如果将并发加到8,其随机读写结果如下:
其性能是有一定的提升的,但并非线性增长。
4. 运维
4.1 宕机情况模拟
4.1.1 Master宕机模拟
在正常情况下,Master集群之前,一定会存在一个nginx一类的中间件,实现负载均衡等功能。因此Master集群内部单台节点出现宕机,业务应该是没有感知的。
限于测试环境没有nginx,因此我们模拟其中一台宕机,检查日志的选举情况,确定Master集群能够容忍(n-1)/2个节点失效。
杀掉当前leader之后,集群会选举一个新的leader出来,打印如日志所示:
将杀死的节点重新启动之后,会出现下面的提示:
4.1.2 Volume宕机模拟
Master上保存的一般都是一些映射关系,真实的数据是保存在volume服务器上的,之前我们配置了复制,因此理论上一个volume会被复制到机架内的所有volume服务器上去。在这种假设下,我们上传的文件在允许的范围内是不会出现丢失的情况的。
这里需要格外注意一点,必须要用volume的API进行上传,才能在宕机的情况下从其他的节点读取到数据。
当然我们在下载文件的时候一般都会通过Master的API进行,而不是直接定位到Volume Server,在这种情况下,当一台Volume Server宕机时,只要其副本所在Volume Server仍然在线,那么通过Master的API是仍旧可以访问到该文件的。
因为复制机制的存在,宕机的情况并不会造成严重的影响,但是我们仍然应该关注宕机之后系统是否能够正常提服务,以及复制机制是否能正常运转。
下面我们模拟一次Volume Server的宕机过程,现在集群中的VolumeServer情况:
关闭一台Volume Sever后观察Master上的日志:

有一些volume被置为了只读状态,这是因为这些volume的副本所在机器宕机了,SeaweedFS会自动把这些副本通信有问题的volume置为只读,这是一种简单的方式,保证了volume的一致性。
但是此时是可以继续上传文件的。
基于上面的测试,我们可以得到下面一些结论:
- Volume Server宕机不会影响通过Master API访问文件;
- Volume Server宕机时可以通过Master API继续上传文件;
- Volume Server宕机时,副本通信中断的volume会被标记为只读。
4.2 备份和恢复
尽管有复制,但是备份也是必要的。SeaweedFS官方提供了备份的工具。SeaweedFS的备份是基于volume的,执行下面的命令就可以:
# port是volume服务器的端口
weed backup -server=master:port -dir=. -volumeId=6
备份的结果是volume的物理文件:

通过Volume的管理接口可以看到这个Volume的基本信息:

对Volume Server保存的文件以及备份好的文件做MD5值校验,发现连个数据文件的md5值是相等的:

恢复数据的时候只需要将备份出来的文件复制回Volume原先所在的目录即可。
但是随着使用时间变长,volume会越来越多,比较大的集群上这个规模是很可观的,因此这个工具并不能算是高效。可能需要开发一款比较高效的工具用于统一的备份操作。
作为一款分布式系统,并不能完全依赖备份工具来进行数据安全性的保证,而是要通过增加机房,机架和服务器来保证副本分散在不同的区域,从而保证数据的安全性。
4.3 监控
SeaweedFS支持Prometheus,只需要在master启动的时候添加-metrics选项即可开启,以下是官方给出的样例:
weed master -metrics.address=localhost:9091
之后配置好grafana就可以了:
https://grafana.com/grafana/dashboards/10423
4.4 扩容
集群的扩容是一项重要的工作。对于SeaweedFS来说,扩容主要是增加Volume Server来存储数据,其过程不过是启动一个进程,将matser信息指向原先的Master集群即可。
但是需要注意的是我们在向一个分布式集群添加新的存储节点时候,都需要考虑数据的再平衡过程。
SeaweedFS官方提供了一个基于命令行的管理工具套件weed shell,在服务器上输入“weed shell”即可打开管理命令行,之后输入“volume.balance”即可。
下面的实验,我向原先的集群中添加了一个新的Volume Server,启动之后观察新的Volume Server上的Volume:

此时新的节点上是没有volume的,这时候我们进行一次再平衡然后观察:

注意,这只是平衡计划,在这个命令执行结束之后观察新的节点中,是不会有任何数据的。只有当指定了force参数之后,才会立刻将volume平衡到新的节点上来。
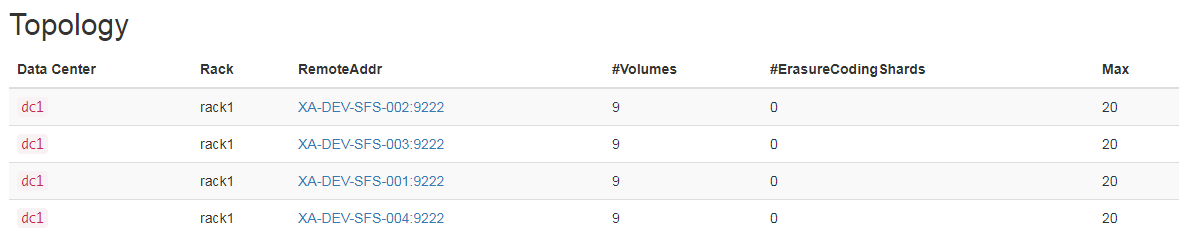
上图是平衡后的结果,可以看到最终集群达到了平衡,每个Volume Server上的Volume数量都是一样的。
4.5 大文件处理
利用HTTP的API上传超过256MB的文件会报错,此时的处理有两种办法:
- 利用weed命令行上传,而且要指定maxMB参数,对大文件要进行分块存储;
- 手动拆分成若干不大于256MB的文件后进行上传,下载时进行合并。
我们现在详细描述第二种办法:
- 利用拆分工具(Linux上可以使用split命令)将文件拆分为不大于256MB的子文件;
- 记录源文件的md5值;
- 利用上传接口上传所有子文件,记录下每一块上传成功后的返回值;
- 申请一个fid;
- 利用子文件上传后的返回值构造一个menifest文件;
- 上传menifest文件;
- 使用menifest文件的fid进行文件下载。
具体的样例作者已经合并到了wiki中,下面是链接:大文件处理。
4.6 文件老化机制
作为一个分布式文件系统,应当考虑文件老化特性。SeaweedFS支持基于TTL的老化,详情参见API文档,TTL是可选的。
根据代码和wiki可以得知ttl实际上是基于文件的,即上传文件的时候将ttl参数保存在Master服务器的元信息中,Master服务器负责在ttl时间后发起删除操作。
但是实际操作中仅依靠ttl机制还是不够的,需要多种灵活地策略,比较常见的就是基于分类的删除。SeaweedFS支持给文件分类,这个概念叫做collection,SeaweedFS同样也提供了基于collection级别的删除接口。不过这种删除并非自动的,官方也没有提供这种机制,我们还是需要自行编写工具对文件进行老化。
4.7 图形化管理
SeaweedFS提供了管理接口,可以列出节点机器管理的Volume等信息,当然也提供了管理界面,进行图形化管理,下面是Master角色的管理界面:
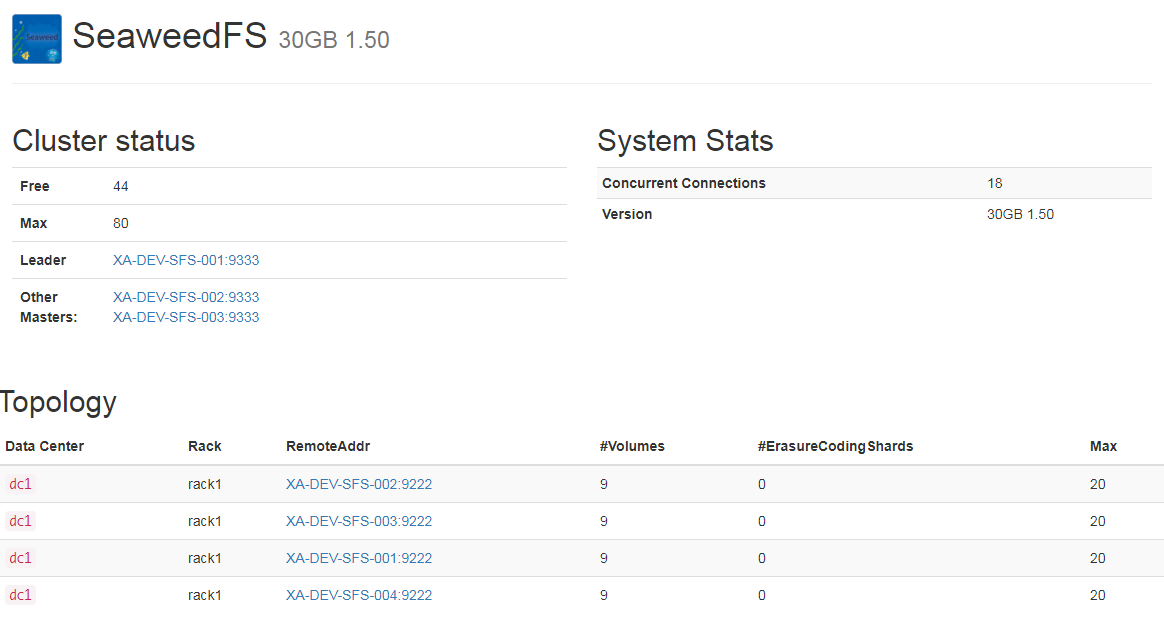
能简单的看出现在的Master集群的leader,同时能观察到DataCenter的结构。上图中,一共有一个DataCenter,一个数据中心内只有一个机架,一个机架上有4台数据节点机器。
所有的Volume Server也是可以点击进入管理界面的:

主要观察的信息是其承载了多少的Volume以及Volume的状态。
5. 性能测试
SeaweedFS提供了benchmark的功能,本测试也是基于该功能进行的。benchmark工具默认会开启16个并发,不限制CPU使用,持续写入1048576个文件,默认不进行复制。
以上参数对于测试机器来说已经可以说明问题,但是需要修改复制参数为001,即机架内复制一次。
benchmark会测试两个场景:
- 大量的小文件写入;
- 读取文件
下面是测试报告:
写入操作的速度平均是4.8MB/s左右,每秒能处理4658个请求。
读取操作速度比较快,平均为16MB/s左右,每秒能处理16485个请求。
测试机器为2核,4G内存。
根据测试中的观察,Master机器的负载并不是完全均匀的,这种情况受到其他因素影响较多,因为是直接在benchmark中指定参数来实现的。实际生产过程中,Master集群之前应该添加负载均衡中间件。
6. 附录
6.1 API文档
SeaweedFS的API分为Master,Volume和Filer三个种类,下面是用swagger编写的yaml版本的API文档,可以直接在Swagger中修改使用:
swagger: "2.0"
info:
description: "这是SeaweedFS的API文档"
version: "1.0.0"
title: "SeaweedFS API"
host: "10.1.20.96:9333"
tags:
- name: "master"
description: "SeaweedFS的Master接口"
- name: "volume"
description: "SeaweedFS提供的Volume接口"
- name: "filer"
description: "filer接口"
schemes:
- "http"
paths:
/dir/assign:
get:
tags:
- "master"
summary: "请求fid"
description: "请求fid接口,系统返回一个分配好的fid"
parameters:
- name: "collection"
in: "query"
description: "collection名称,非必填"
required: False
type: "string"
- name: "count"
in: "query"
description: "批量申请数量"
required: False
type: "integer"
- name: "replication"
in: "query"
description: "复制策略"
required: False
type: "string"
- name: "ttl"
in: "query"
description: "文件生存时间"
required: False
type: "string"
- name: "dataCenter"
in: "query"
description: "数据中心"
required: False
type: "string"
- name: "rack"
in: "query"
description: "机架"
required: False
type: "string"
- name: "writableVolumeCount"
in: "query"
description: "可写Volume数量"
required: False
type: "integer"
- name: "maxMB"
in: "query"
description: "分片大小"
required: False
type: "integer"
responses:
200:
description: "successful operation"
schema:
$ref: "#/definitions/Fid"
/submit:
post:
tags:
- "master"
summary: "直接上传文件,不用首先请求fid"
consumes:
- "multipart/form-data"
produces:
- "application/json"
parameters:
- name: "collection"
in: "query"
description: "collection名称,非必填"
required: False
type: "string"
- name: "count"
in: "query"
description: "批量申请数量"
required: False
type: "integer"
- name: "replication"
in: "query"
description: "复制策略"
required: False
type: "string"
- name: "ttl"
in: "query"
description: "文件生存时间"
required: False
type: "string"
- name: "dataCenter"
in: "query"
description: "数据中心"
required: False
type: "string"
- name: "rack"
in: "query"
description: "机架"
required: False
type: "string"
- name: "writableVolumeCount"
in: "query"
description: "可写Volume数量"
required: False
type: "integer"
- name: "maxMB"
in: "query"
description: "分片大小"
required: False
type: "integer"
- name: "file"
in: "formData"
description: "file to upload"
required: true
type: "file"
responses:
200:
description: "successful operation"
schema:
$ref: "#/definitions/DirectUploadResponse"
/{fid}:
post:
tags:
- "volume"
summary: "上传文件"
description: "使用预先分配的fid上传文件"
consumes:
- "multipart/form-data"
produces:
- "application/json"
parameters:
- name: "fid"
in: "path"
description: "ID of file to upload"
required: true
type: "string"
- name: "file"
in: "formData"
description: "file to upload"
required: true
type: "file"
responses:
200:
description: "successful operation"
schema:
$ref: "#/definitions/UploadResponse"
delete:
tags:
- "volume"
summary: "删除指定的文件"
description: "删除指定的文件"
operationId: "deleteFile"
produces:
- "application/json"
parameters:
- name: "fid"
in: "path"
description: "要删除的fid"
required: true
type: "string"
responses:
200:
description: "successful operation"
schema:
$ref: "#/definitions/DeleteResponse"
/path/to/file:
get:
tags:
- "filer"
summary: 通过filer下载文件
description: 可以直接通过路径下载文件
responses:
200:
description: OK
post:
tags:
- "filer"
summary: "通过filer上传文件"
description: "直接上传文件,不用预先分配fid"
consumes:
- "multipart/form-data"
produces:
- "application/json"
parameters:
- name: "ttl"
in: "query"
description: "文件生存时间,只有当元数据存储为redis或者Cassandra时才有效"
required: false
type: "string"
- name: "mode"
in: "query"
description: "文件属性,同Linux系统文件属性"
required: false
type: "string"
- name: "file"
in: "formData"
description: "file to upload"
required: true
type: "file"
responses:
200:
description: "successful operation"
schema:
$ref: "#/definitions/FilerUploadResponse"
definitions:
Fid:
type: "object"
properties:
fid:
type: "string"
url:
type: "string"
publicUrl:
type: "string"
count:
type: "integer"
UploadResponse:
type: "object"
properties:
name:
type: "string"
size:
type: "integer"
format: "int64"
eTag:
type: "string"
DeleteResponse:
type: "object"
properties:
size:
type: "integer"
format: "int64"
DirectUploadResponse:
type: "object"
properties:
fileName:
type: "string"
size:
type: "integer"
format: "int64"
eTag:
type: "string"
fileUrl:
type: "string"
fid:
type: "string"
FilerUploadResponse:
type: "object"
properties:
name:
type: "string"
size:
type: "integer"
format: "int64"
fid:
type: "string"
url:
type: "string"
基于上面的API,我们应该在完成了文件落盘操作以后将一些元信息存放在数据库中便于未来的访问,这就需要设计一张元数据表:
create table seaweedfs_meta
(
`id` bigint not null auto_increment primary key comment '自增主键,提升性能',
`fid` varchar(32) not null comment '文件Id',
`fileName` varchar(255) not null comment '文件名,选用Linux系统最长文件名',
`fileSize` int not null comment '文件大小',
`collection` varchar(32) comment '文件分类名,非必填',
unique key (fid)
)comment='SeaweedFS文件元数据表';

若有收获,就点个赞吧
0 人点赞
