磁盘IO
磁盘是持久化存储介质,大体分为两种:SSD和机械硬盘,其中机械硬盘因为容量大,价格低廉被大量采用。数据库(包括但不限于MySQL)最终都是将数据保存在磁盘上的。
机械硬盘的性质则导致从磁盘上进行随机读取非常缓慢,因此数据库一般都会设计缓冲池将数据缓存在内存中,以期提高读取效率。
机械硬盘由磁盘和机械臂组成,每次读取数据时,机械臂会运动到相应的位置,读取到需要的数据,这种原理导致机械磁盘顺序读取的速度远远大于随机读取。
数据库的最小存储单位是页(也有数据库称之为块),一个页保存了至少一行数据,但是每次读取数据时,都是以页为单位读取的。这也就是说,不管读取一行还是多行,总是将页读取出来的。
一个页被从磁盘读取出来并移动到数据库缓冲池需要的时间大约10ms,这还是理想情况下,这个时间随着磁盘的繁忙程度只会增加,即便是理想情况,10ms也是一个非常难以接受的时间。
现代的磁盘服务器都会提供缓冲区以降低响应时间,这个时间大约为1ms,然而未能命中缓冲区的磁盘IO,消耗的时间仍然是10ms。
刚才提到了机械磁盘的原理,如果要读取的页在物理上是连续的,那么此时的读取就是顺序读取,顺序读取的速度40MS/s,这也就意味着每个4KB的页平均读取时间降低到了0.1ms。
顺序读取有两大优势:
- 同时读取多个页意味着平均读取每个页的时间会变短;
- 由于DBMS事先知道要读取哪些页,可以在这些页被真正请求之前就将其读取出来,这种技术称为预读。
至此,我们大概可以理顺一个数据库查询优化的思路,就是将随机读变成顺序读或者降低随机读。
**
SQL处理过程
谓词
谓词即where子句中的列,或者说where子句由至少一个谓词组成。
实际上谓词是一个很学术化的词,有关谓词的解释可以参考《数据库系统概论》这本书,这里只是借用这个词。
索引片
索引片的概念是《数据库索引设计与优化》中单独提出的概念,在任何一个DBMS中都没有提及。索引片的描述方法是定义索引匹配列的数量。
索引片又被分为宽索引和窄索引,如果索引片较宽,则查询成本主要集中在对索引页的顺序扫描上;如果索引片较窄,则查询成本中对索引页的扫描会显著减少,但是成本主要集中在对表的二次IO上。
下图是一个查询对应的宽窄索引设计:
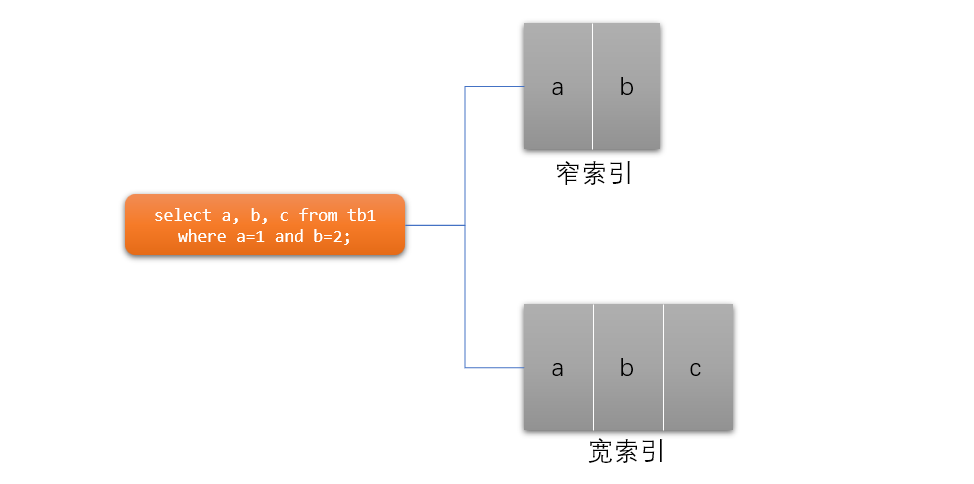
如果了解MySQL InnoDB的人,一眼就能看出来,用第二个索引会索引覆盖。这个索引实际上就是一个“三星索引”,至于三星索引的概念后面会提及。而如果这个表只有一个窄索引,那么查询会在命中索引之后进行回表检索,多了一次IO操作,实际的COST比利用宽索引要大。
对于MySQL的InnoDB引擎来说,任何一个二级索引(辅助索引)都会保存主键的值,命中了窄索引的查询会继续利用主键值进行回表检索,得到所有需要的结果。
过滤因子
其实这个概念在很多数据库中成为选择度。在什么列上建立索引是一个讲究的事情,因为我们知道索引是用来减少IO操作的,索引规模足够小,则扫描的效率越高。举一个例子,如果一个表存在性别(gender)列,那么这个列的选择无非是F(Femal),M(Male)或者不明,如果一个表的规模足够大,那么这个索引的规模也非常巨大,这个索引也就不是一个好的索引。
《数据库索引设计与优化》中提出了一个公式:
过滤因子(FF)= 结果集的数量/表行的数量
我们不能一直设计出三星索引,如上文所述,很多时候因为各种原因我们会设计出窄索引,这时回表检索是不可避免的,因此,让索引变得尽量“薄”,是我们追求的目标之一。
设想下面的SQL:
select price, color, dealernofrom carwhere make = :make and model = :modelorder by price;
索引为(make, model, year),那么这个索引就足够的薄,因为有两个匹配列。
如果是这样的SQL:
select price, color, dealerno
from car
where make = :make and year = :year
order by price;
那么之前的索引则只有一个匹配列,FF会比两个匹配列低很多,索引比较厚。
写到这里大概对薄厚有一个了解,即FF的大小,我们的目标是尽量降低FF,结果集也就足够小。
组合谓词的过滤因子
组合谓词的FF计算并不能简单的认为是组合谓词中每个元素的FF乘积,但是为了简化理解,可以这么认为。
下图直观说明了这种计算方法:
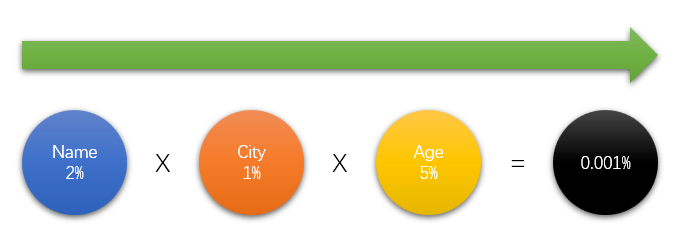
可以看出,如果匹配列越多,则FF越小,所得的结果集越小,效率越高。
索引过滤和过滤列
有时候即便where子句中有索引列,也不一定能命中,这是个很复杂的算法,尽管如此,这些索引列仍然能够减少回表次数,我们称这些列为过滤列。
这样一个SQL的where子句:
where A=:A and B>:B and C=:C
而索引是(A,B,C,D),那么上面的where子句中每个谓词都是索引的一部分。此时检索的步骤如下:
- where子句中,该列是否至少拥有足够简单的谓词与之对应,如果有,那么这个列就是匹配列,如果没有,则该列及其后面的列都是非匹配列;
- 如果该谓词是一个范围谓词,那么剩余的索引列都是非匹配列;
- 对于最后一个匹配列之后的索引列,如果拥有一个足够简单的谓词与之对应,则该列为匹配列。
回到例子中的子句,可以看到第一条是满足的,即A=:A,A是匹配列。接下来是B,这是一个范围谓词,不构成匹配列,后面也就不需要看了,一定不是匹配列。但是C可以减少回表,这是显而易见的,可以在索引上对C进行过滤。
其实熟悉Oracle的话,很好理解所谓匹配和过滤,匹配即执行计划中的access,过滤即执行计划中的filter。
创建理想索引
《数据库索引设计与优化》一书中提出了三星索引的概念,即一个索引如果满足三个要求,就能称之为三星索引,而三星索引无疑是最优解。
- 第一颗星,取出所有等值谓词的列,把这些列作为索引最开头的列
- 第二颗星,将Order By的列加入到索引中
- 第三颗星,将查询语句剩余的列加入到索引中
这里又将提及宽索引的概念,其实宽索引就是满足第三颗星的索引,即所有的列都在索引中,避免了回表检索,减少了随机IO的发生。需要注意的是,这三颗星并非按照难以程度区分的,往往第三颗星又是最容易获得的。
但是很可惜的是,我们并不能总是得到一个三星索引。观察下面的SQL:
select cno, fname
from cust
where lname between :lname1 and :lname2
and city=:city
order by fname;
首先考虑最简单的第三颗星,设计出来的索引应该是这样的:(city,lname,fname,cno);下面是第二颗星,避免排序,那么调整一下顺序,索引变成了这样:(city,fname,lname,cno),为了避免排序,我们只能把fname放在范围谓词lname的前面,不然就没有用了。
但是(city,fname,lname,cno)索引却不满足第一颗星,参考之前“索引过滤和过滤列”的内容。如果要满足第一颗星,我们需要将索引调整成(city,lname,fname,cno),这时又不满足第二颗星。
因此这种SQL无法设计出三星索引。这种情况在实际应用中是大量存在的,面对一个二选一的情况,我们只能说选择最佳的方案,却无法达到理想方案。
索引的代价
索引并不是没有代价的,如果熟悉Oracle,就知道在Oracle里索引也是一个segment,和表是一个等级的,甚至有的时候索引的规模还要大于表本身。索引主要的代价展现在两方面:
- 写入的代价,每次新添加记录或者修改记录,都要同步修改索引,这是一个IO操作;
- 磁盘负载,其实还是写入代价的问题;
- 磁盘空间,刚才也提到过,索引是实际存储的数据结构,是占用硬盘空间的,有时候规模甚至超过了表本身。

若有收获,就点个赞吧
0 人点赞
