STL标准库 语法
include
数据结构
vector——
https://www.yuque.com/yizhixiaoxiongzaifei/ug2d1v/fb6dd38a-cd1f-4658-a15c-ab71970f2a8a
1.push_back 在数组的最后添加一个数据 2.pop_back 去掉数组的最后一个数据 3.at 得到编号位置的数据 4.begin 得到数组头的指针 5.end 得到数组的最后一个单元 + 1 的指针 13.erase 删除(迭代器) 15.rbegin 将 vector 反转后的开始指针返回 (其实就是原来的 end-1) reverse_iterator 16.rend 将 vector 反转构的结束指针返回 (其实就是原来的 begin-1) 17.empty 判断 vector 是否为空 18.swap 与另一个 vector 交换数据
可以使用!= 和==判断两个列表是否包含的元素数量相同且相同位置元素值相同。
可以用for(auto& i:vec){i=…;} 改变vector内的值。
list——
- queue
- stack
- deque
- O(nlgn)
- map
- unordered_map
- set
- multiset
一般算法
- 数学计算
- accumulate
- power
- max
- min
- 基础数据处理
- swap
- iter_swap
- reverse
- itoa
- atoi
- 查找:
- find
- search
- binary_search
- lower_bound ——algorithm 大于等于目标值的第一个元素
- upper_bound ——algorithm 大于目标值的第一个元素
可以用cmp<函数,表示cmp(val,x)成立的第一个元素
//1. 头文件
include
using namespace std;
int main() { //2. 创建流 ifstream input;
//3. 打开文件,将流与文件相关联//2, 3步可以直接合并为:ifstream input("number.txt");input.open("number.txt");//4. 从文件读入数据int number1, number2, number3;input >> number1 >> number2 >> number3;cout << "number1: " << number1 << endl;cout << "number2: " << number1 << endl;cout << "number3: " << number1 << endl;//5. 关闭流input.close();return 0;
}
写文件```cpp#include <iostream>//1. 头文件<fstream>#include <fstream>using namespace std;int main(){//2. 创建流ofstream output;//3. 打开文件,将流与文件相关联,这里使用相对路径output.open("number.txt");//4. 向文件写入数据output << 1 << " " << 2 << " " << 3 << endl;//5. 关闭流output.close();return 0;}
专题
图论算法
欧拉路径
半欧拉图<->有欧拉通路<->所有点在一个连通分量上,除了两个点(起点和终点)外入度=出度,起点出度=入度+1,终点入度=出度+1
欧拉图<->有欧拉回路<->所有点在同一个强连通分量,所有点入度=出度
hierholzer 算法
从起点出发,进行深度优先搜索。
每次沿着某条边从某个顶点移动到另外一个顶点的时候,都需要删除这条边。
如果没有可移动的路径,则将所在节点加入到栈中,并返回。
原理:死胡同节点会先被入栈。
332. 重新安排行程
最短路径算法
单源点最短路径dijkstra的优先队列优化(正权)
vector<bool> visited(n);vector<int> distance(n,MAX);priority_queue<pair<int,int>,vector<pair<int,int>,cmp>> pq;pair<int,int> p(0,0);pq.push_back(p);while(!pq.empty()){pair<int,int>& t=pq.top();int x=t.first,d=t.second;if(visited[x]){continue;}visited[x]=true;distance[x]=t.second;pq.pop();for(map<int,int>::iterator it=edge[t].begin();u!=edges[t].end();it++){if(visited[u]) continue;int u=it.first;pair<int,int> q(u,d+it.second);pq.push(q);}}
负权单源点最短路径spfa(可检测负环)
struct Edge{int to,len;};bool spfa(const int &beg,//出发点const vector<list<Edge> > &adjlist,//邻接表,通过传引用避免拷贝vector<int> &dist,//出发点到各点的最短路径长度vector<int> &path)//路径上到达该点的前一个点//没有负权回路返回0//福利:这个函数没有调用任何全局变量,可以直接复制!{const int INF=0x7FFFFFFF,NODE=adjlist.size();//用邻接表的大小传递顶点个数,减少参数传递dist.assign(NODE,INF);//初始化距离为无穷大path.assign(NODE,-1);//初始化路径为未知list<int> que(1,beg);//处理队列vector<int> cnt(NODE,0);//记录各点入队次数,用于判断负权回路vector<bool> flag(NODE,0);//标志数组,判断是否在队列中dist[beg]=0;//出发点到自身路径长度为0cnt[beg]=flag[beg]=1;//入队并开始计数while(!que.empty()){const int now=que.front();que.pop_front();flag[now]=0;//将当前处理的点出队for(list<Edge>::const_iterator//用常量迭代器遍历邻接表i=adjlist[now].begin(); i!=adjlist[now].end(); ++i)if(dist[i->to]>dist[now]+i->len)//不满足三角不等式{dist[i->to]=dist[now]+i->len;//更新path[i->to]=now;//记录路径if(!flag[i->to])//若未在处理队列中{if(NODE==++cnt[i->to])return 1;//计数后出现负权回路if(!que.empty()&&dist[i->to]<dist[que.front()])//队列非空且优于队首(SLF)que.push_front(i->to);//放在队首else que.push_back(i->to);//否则放在队尾flag[i->to]=1;//入队}}}return 0;}
多源点最短路径
Floyed算法 O(n3)
cost[i][j]=min(cost[i][j],cost[i][k]+cost[k][j]);
cost初始化为初始路径,cost[i][i]=0,其他为最大。for(int k=0;k<n;k++){for(int i=0;i<n;i++){for(int j=0;j<n;j++){if(i!=j&&cost[i][k]!=MAX&&cost[k][j]!=MAX)cost[i][j]=min(cost[i][j],cost[i][k]+cost[k][j]);}}}
最小生成树
最小生成树能够保证整个拓扑图的所有路径之和最小,但不能保证任意两点之间是最短路径。
prim+优先队列
和dijkstra长得一模一样,就是入栈的pair为(节点编号,这条路的长度)
Kruskal+并查集
很熟,略了。
就是注意并查集不要漏find
强连通分量

拓扑排序
用队列,每次都弹出度为0的点就好了
// 有向无环图一定存在拓扑序void TopSort(){// 维护入度为0的节点,编号从小到大排序,保证编号小的节点的拓扑序小priority_queue<int, vector<int>, greater<int> > que;// 将入度为0的节点加入队列for(int i=1; i<=NumVertex; ++i){if(Graph[i][0] == 0) que.push(i);}// 循环处理入度为0的节点,并赋予拓扑序int cnt = 0;while(!que.empty()){int u = que.top();que.pop();// 将最较小拓扑序号赋给入度为0且当前编号最小的节点TopNum[u] = ++cnt;// 删除节点u出发的边,并调整其它节点的入度for(int i=1; i<Graph[u].size(); ++i){// 将调整后入度为0的节点加入队列if(--Graph[Graph[u][i]][0] == 0) que.push(Graph[u][i]);}}// 图中存在环则无拓扑序if(cnt != NumVertex) return;// 如果图并不一定是全联通的,那么判原图的某一连通域中是否存在环:for(int i=1; i<=NumVertex; ++i) if(Graph[i][0]) puts("somerwhere of the graph has a cycle");// 输出以拓扑序排列的节点编号for(int i=1; i<=NumVertex; ++i) NodeNum[TopNum[i]] = i;for(int i=1; i<=NumVertex; ++i) printf("%d%c", NodeNum[i], i==NumVertex?'\n':' ');}
花式DFS、BFS
并查集
set&&union代码略
685. 冗余连接 II
二分查找
- 第一个大于等于x的数 [0,n) mid=(l+r)/2
- a[mid]>=x then right=mid
- a[mid]<x then left=mid+1
- 最后一个小于x的数 (-1,n-1] mid=(l+r+1)/2
- a[mid]>=x then right=mid-1
- a[mid]<x then left=mid
- 154. 寻找旋转排序数组中的最小值 II
- 不明显的二分1482. 制作 m 束花所需的最少天数
分治
partition
merge
快排
贪心
最早截止期优先
记得这个只能在给出的条件是[开始时间,截止时间]的时候用,其他条件都需要改。
630. 课程表 III
这个题是有一些变化的EDF,给的是[持续时间,最晚截止时间],最早截止期优先+优先队列对持续时间排序贪心替换。
动态规划
- 最大子矩阵
- 最长上升子序列O(nlgn)算法
滑动窗口/双指针
位运算
装错信封的错排问题
f(n)=(n-1)*(f(n-1)+f(n-2))
极大极小算法
- dfs
- bfs
高精度
int lcm(int a,int b){ return a*b/gcd(a,b); } ```
- 摩尔投票求众数
- 两个堆求数据流中的中位数
- 快速幂√
线性代数
Cross Product 向量叉乘
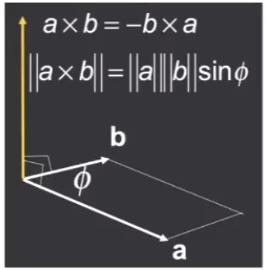
方向由右手螺旋定则确定,大小为形成的平行四边形面积。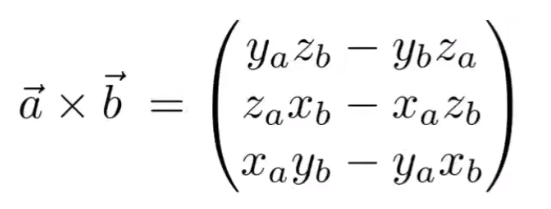
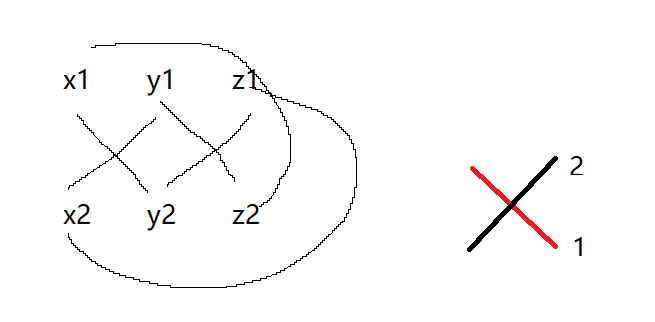
可以简单记为除去自己所在axis的其他axis对角线相乘的差。
a×b=-b×a向量点乘dot

个人常见bug汇总
笔误
张冠李戴,把一个变量写成另一个

第一次写的时候把arr.size()写成了n,tmp[0]也写成了n
这里需要返回的是在新的列表中的顺序,计算时候也应该使用新的列表的数量。
符号写反
min,max相关错误

min初始值应该为MAX,max初始值应该为MIN
注意min max不要写反。
&&||写反
if(s[i]>’9’||s[i]<’0’){return false;}//不是数字不是点
写成了&&
边界情况没有仔细考虑

这里的目标是将一个n维向量降为ceil(n/2)大小的向量,这里只考虑到单数情况下需要将中间值直接插入的情况,但忘记了普遍的偶数情形中最后一个位置仍需要普通的处理流程。
等价情况考虑不全
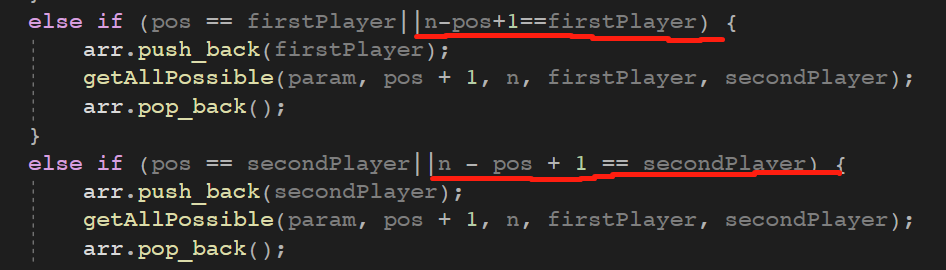
写漏了
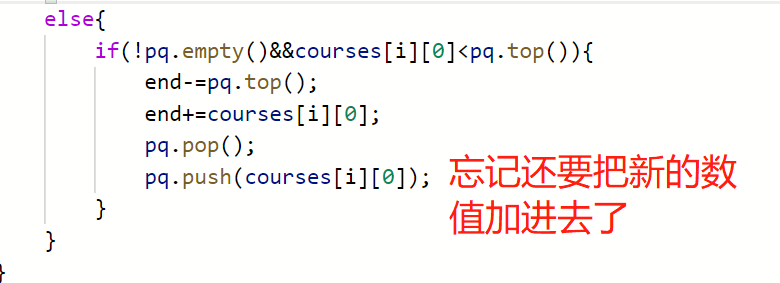 替换的时候只记得删不记得增
替换的时候只记得删不记得增
剪不断理还乱想不明白非常爆炸
二分法
mid只会==left是不可能等于right的
所以当nums[mid]==nums[r]的时候,只可能是左边有和右边nums[r]一样大的,直接把右边去了比较好。
[2,1,1]
为什么left会出错?
nums[mid]>nums[left]同样证明在左边,nums[mid]
如果把右边r左移了,可能会出现最小的数直接失踪的情况,如果把左边l移动了,也可能 左边的l就是mid,也丢了orz
感觉是很难写明白的。

若有收获,就点个赞吧
0 人点赞
