



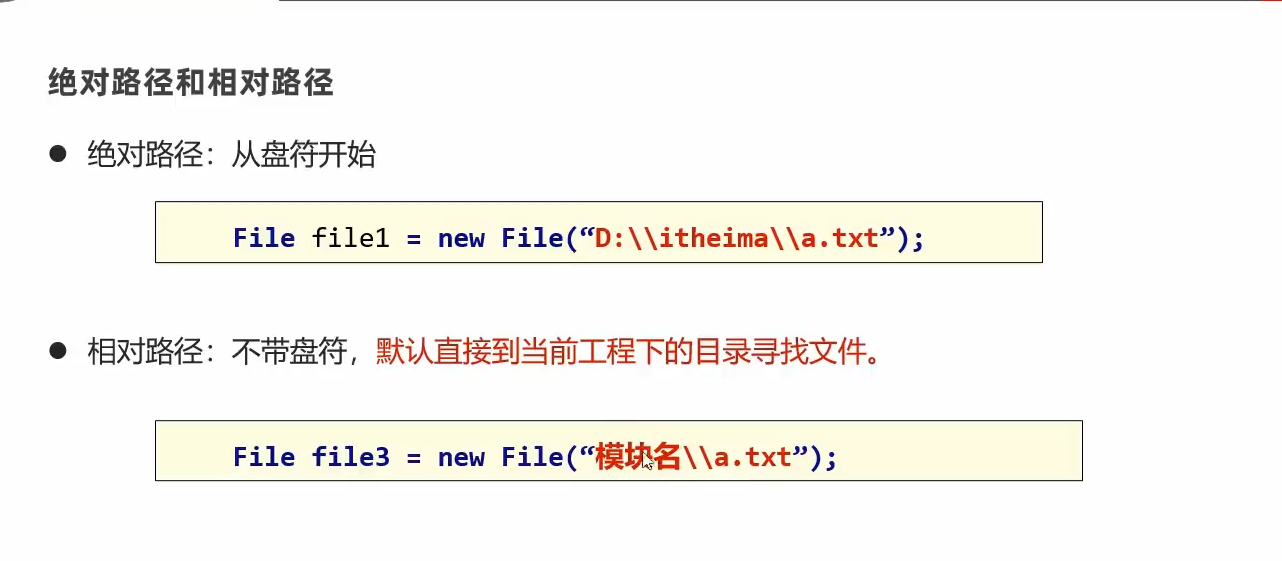
File类概述


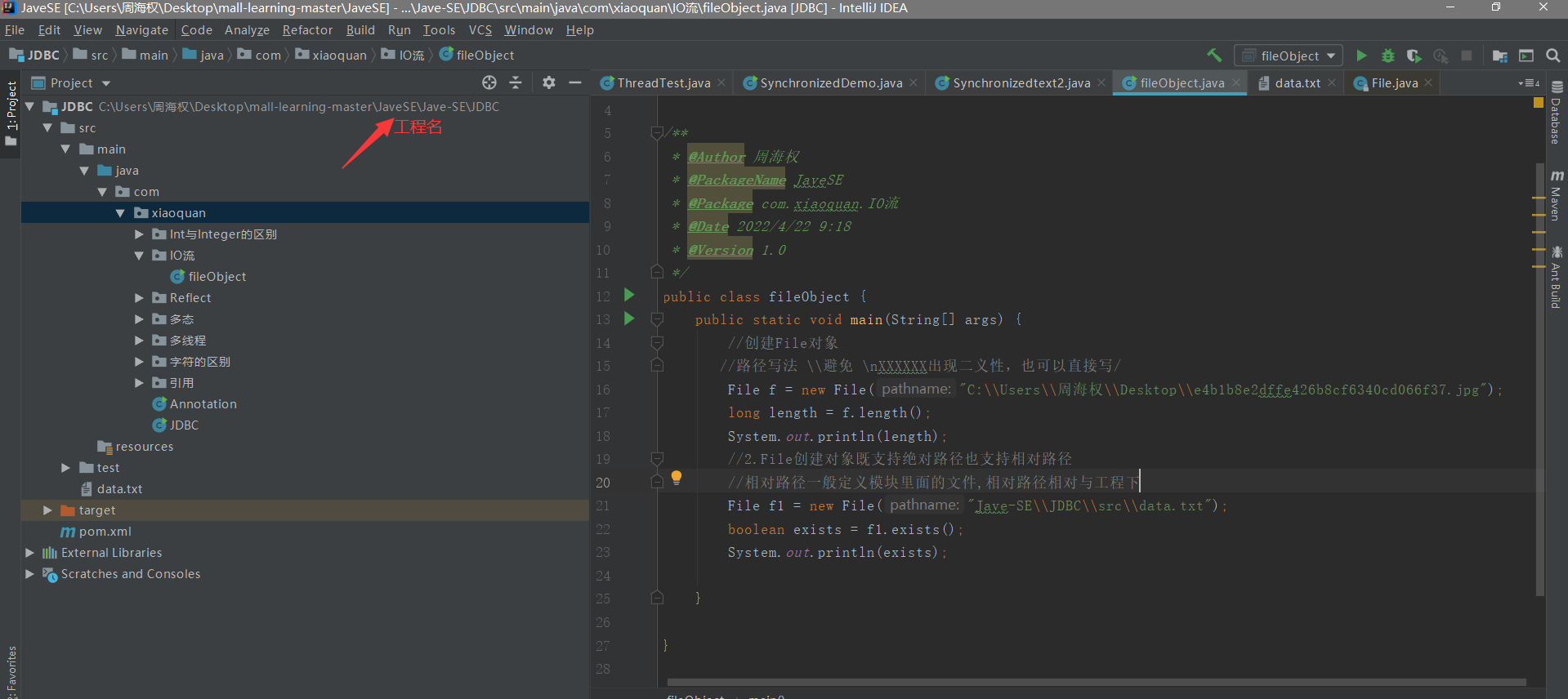
public class fileObject {public static void main(String[] args) {//创建File对象//路径写法 \\避免 \nXXXXXX出现二义性,也可以直接写/File f = new File("C:\\Users\\周海权\\Desktop\\e4b1b8e2dffe426b8cf6340cd066f37.jpg");long length = f.length();System.out.println(length);//2.File创建对象既支持绝对路径也支持相对路径//相对路径一般定义模块里面的文件,相对路径相对与工程下File f1 = new File("Jave-SE\\JDBC\\src\\data.txt");boolean exists = f1.exists();System.out.println(exists);}}
File类常用API
判断文件类型,获取文件信息

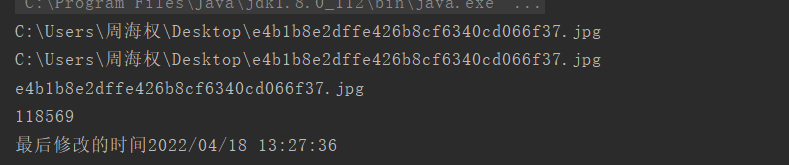
//创建File对象//路径写法 \\避免 \nXXXXXX出现二义性,也可以直接写/File f = new File("C:\\Users\\周海权\\Desktop\\e4b1b8e2dffe426b8cf6340cd066f37.jpg");//a,获取文件的绝对路径System.out.println(f.getAbsolutePath());//获取文件定义时使用的路径System.out.println(f.getPath());//获取文件的名称带后缀System.out.println(f.getName());//获取文件的大小字节个数System.out.println(f.length());//获取文件的最后修改时间long time = f.lastModified();System.out.println("最后修改的时间"+new SimpleDateFormat("yyyy/MM/dd HH:mm:ss").format(time));
创建文件、删除文件功能

遍历文件夹

//创建一个空的文件File f3 = new File("Jave-SE\\JDBC\\src\\data2.txt");boolean newFile = f3.createNewFile();System.out.println(newFile);//创建一级目录File f4 = new File("D:\\java基础\\aaa");System.out.println(f4.mkdir());//创建多级目录File f5 = new File("D:\\java基础\\bbb\\ccc\\ddd");System.out.println(f5.mkdirs());//删除文件或者文件夹System.out.println(f5.delete());//只能删除空的文件夹
字符集
常见字符集介绍
字符集基础知识
- 计算机底层是不可以直接存储字符的。计算机中底层只能存储二进制(0,1)
- 二进制是可以转换成十进制的

结论:计算机底层可以表示十进制编号。计算机可以给人类字符进行编号存储,这套编号规则就是字符集。
ASCII字符集
- ASCII:包括了数字、英文、符号
- ASCII使用一个字节存储一个字符,一个字节是8位,总共可以表示128个字符信息,对于英文,数字来说够用。
01100001=97=>a
01100010=98=>b
GBK
windows系统默认的码表。兼容ASCII码表,也包含几万个汉字,并支持繁体汉字以及部分日韩文字。
注意:GBK知中国的码表,一个中文以两个字节的形式存储。但不包含世界上所有国家的文字。
2^16位=35536基本够用
Unicode码表:
- unicode(又称统一码,万国码、单一码)是计算机科学领域里的一项业界字符编码标准。
- 容纳世界上大多数国家的所有常见文字和符号
- 由于Unicode先通过UTF-8,UTF-16以及UTF-32的编码成二进制后在存储到计算机,其中最常见的是UTF-8

字符集的编码、解码操作
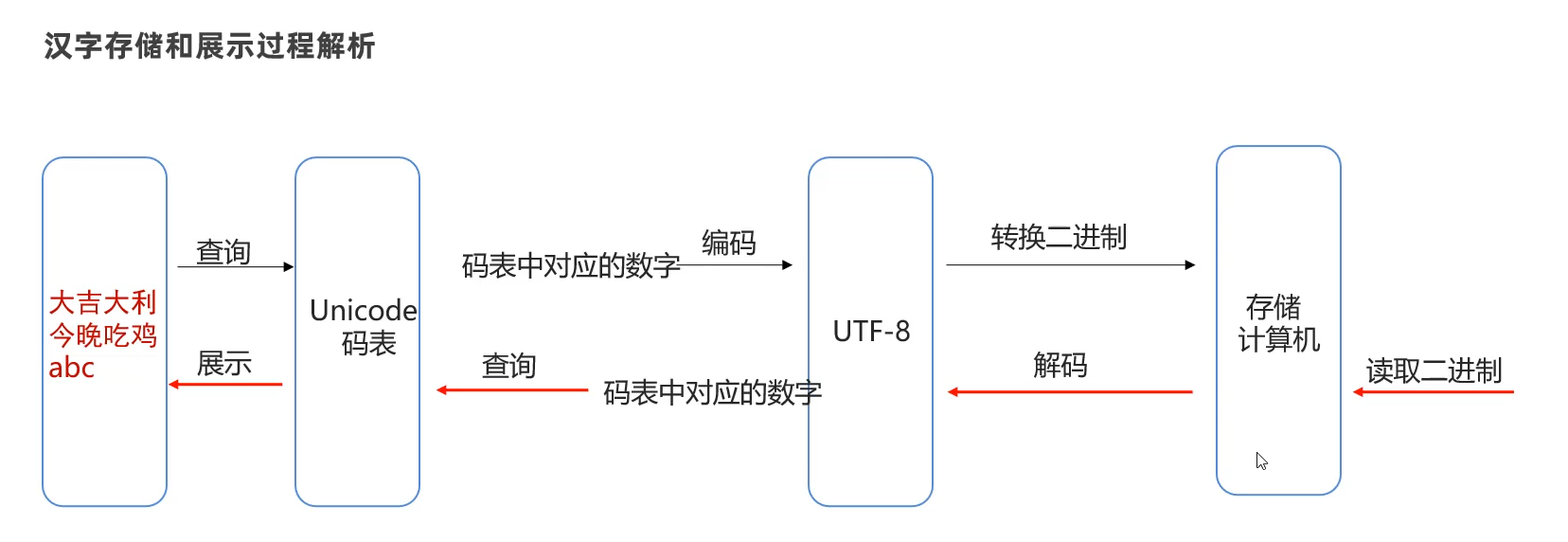
为什么编码解码就能直到3个字节就是汉字呢,那是因为负数开头就是汉字,可以直接检测到。
总结:
1.字符串常见的字符串底层组成是什么样的?
- 英文和数字等在任何国家的字符集中都占1个字节
- GBK字符中一个中文字符占2个字节
- UTF-8编码中中文占3个字节
2.编码前的字符集和解码好的字符集有什么要求?
必须一致,否则会出现中文乱码
英文和数字不会乱码
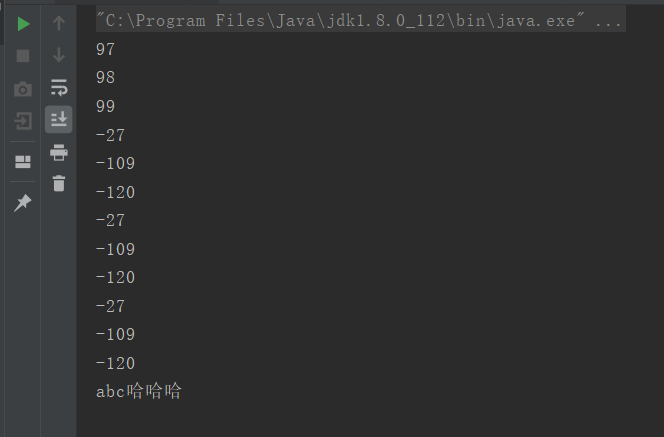
public class codeencode {public static void main(String[] args) {String str = "abc哈哈哈";//编码成数字 byte就是代表字节byte[] bytes = str.getBytes();String a = new String(bytes);for (byte b:bytes)System.out.println(b);System.out.println(a);}}
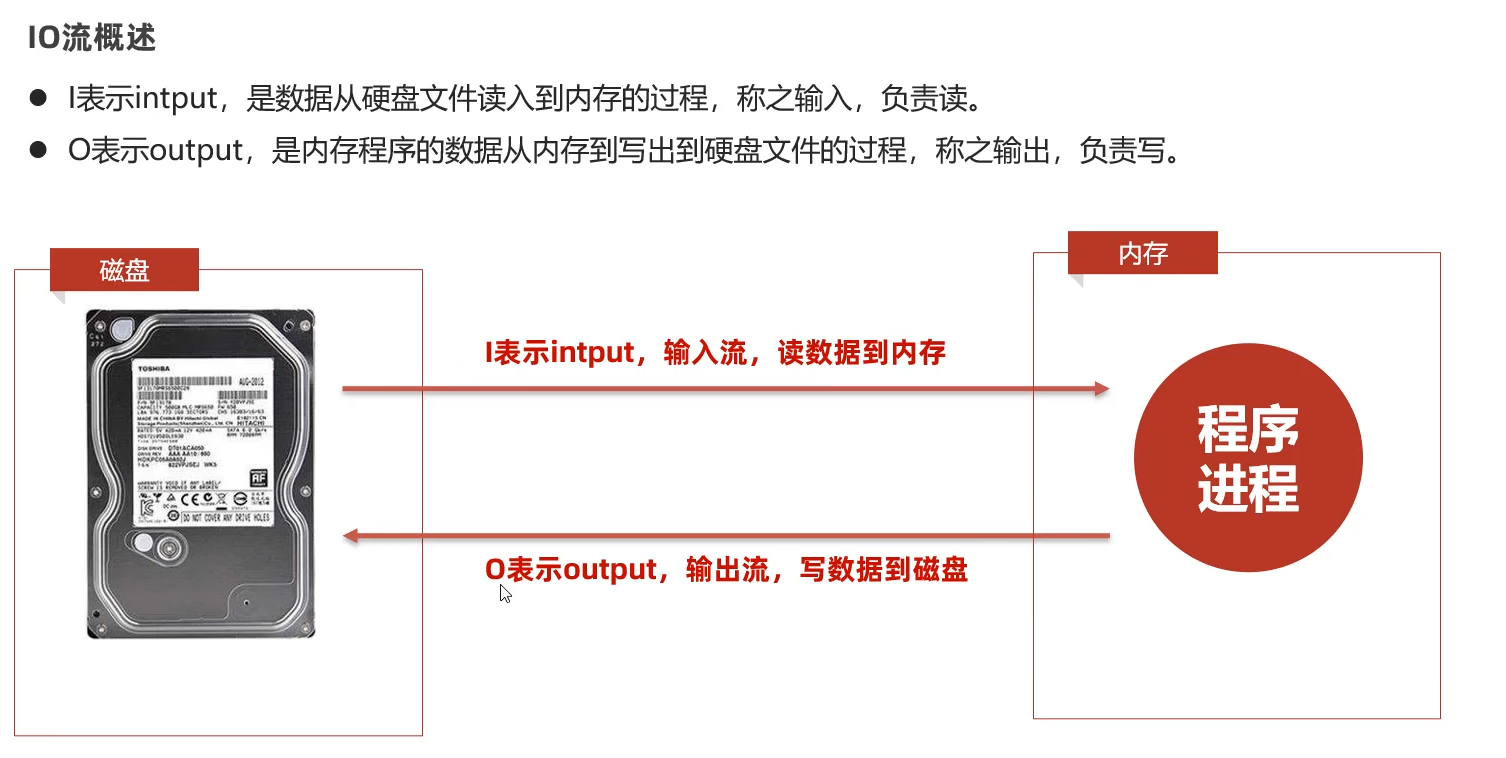
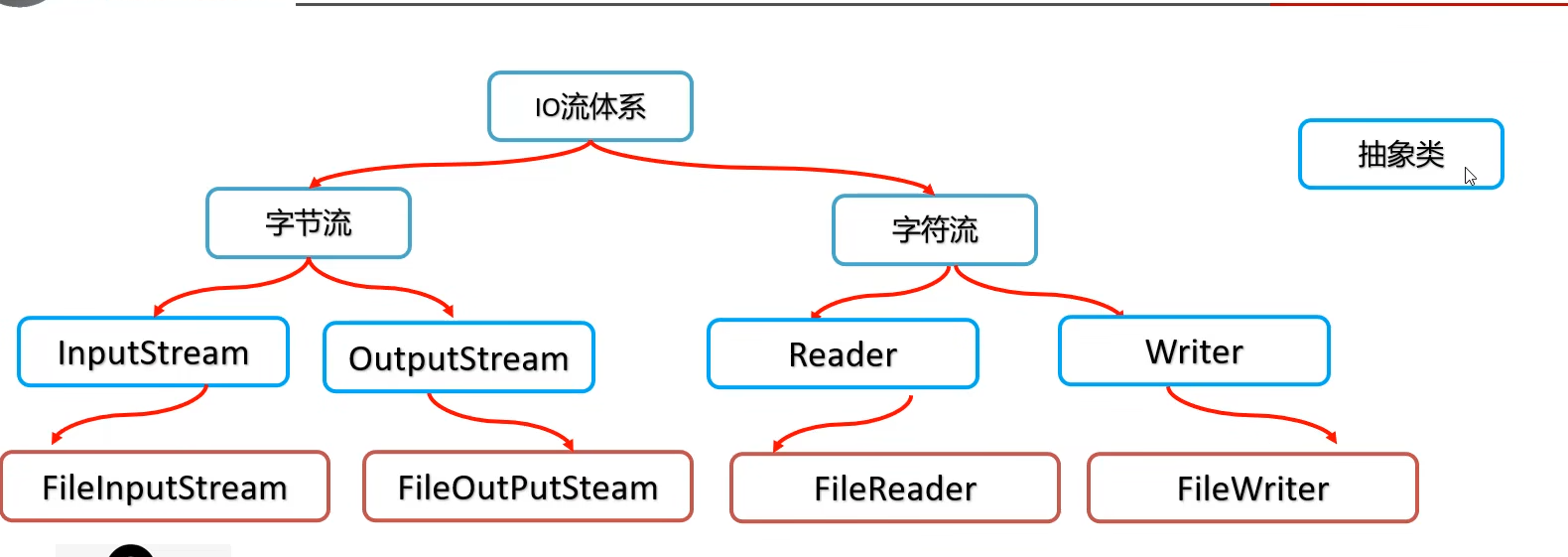
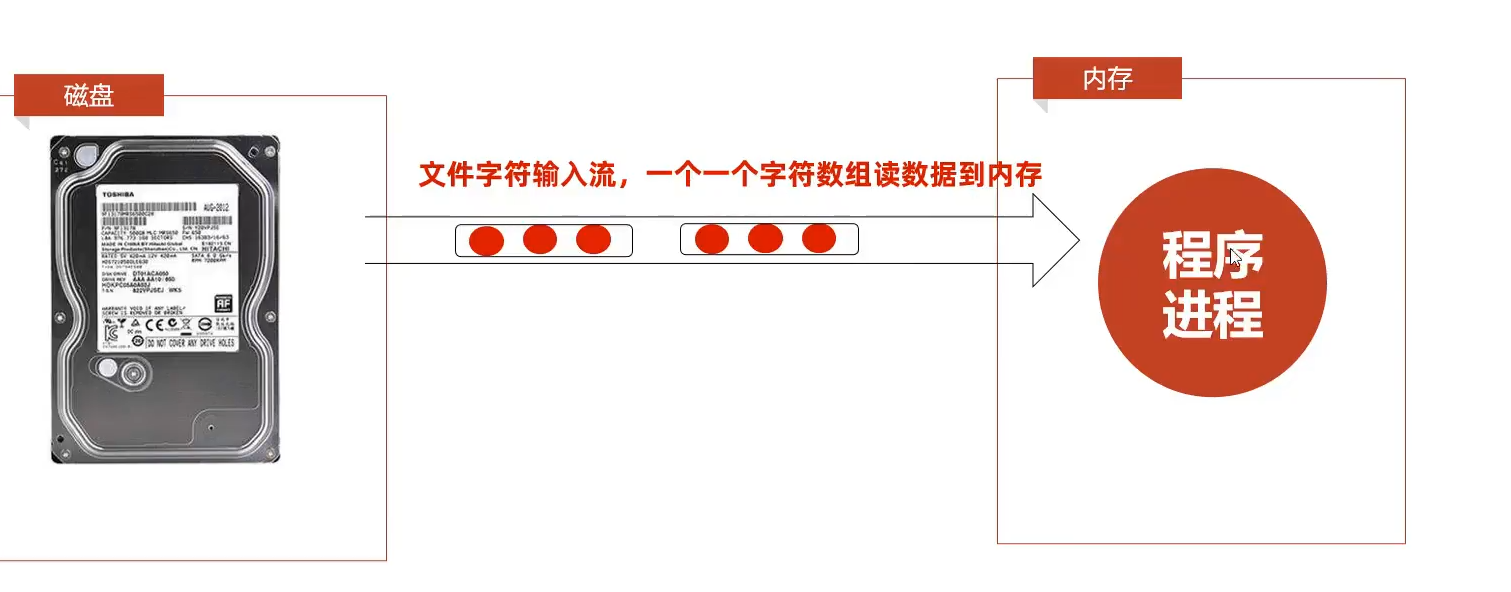
IO流概述
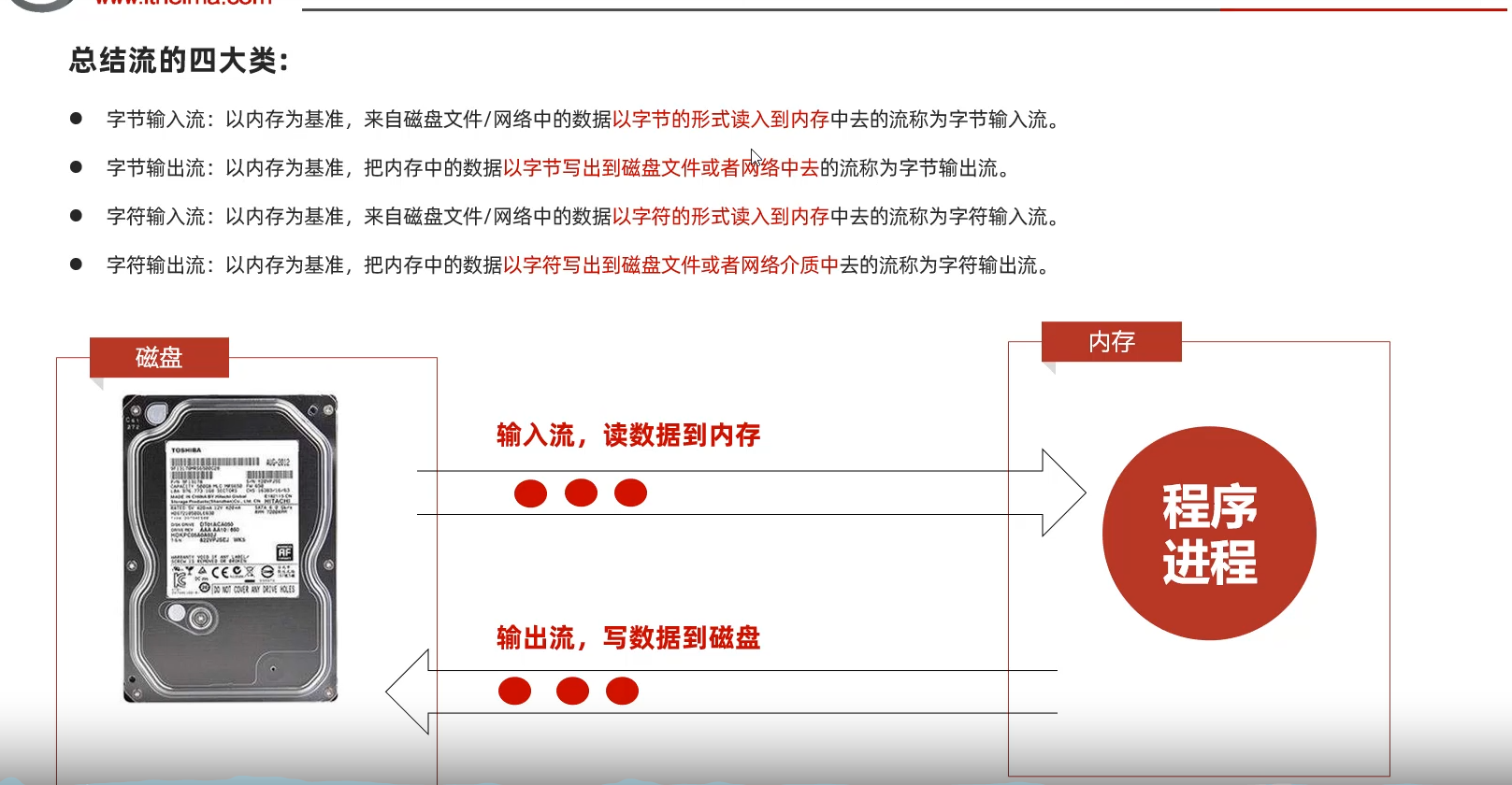
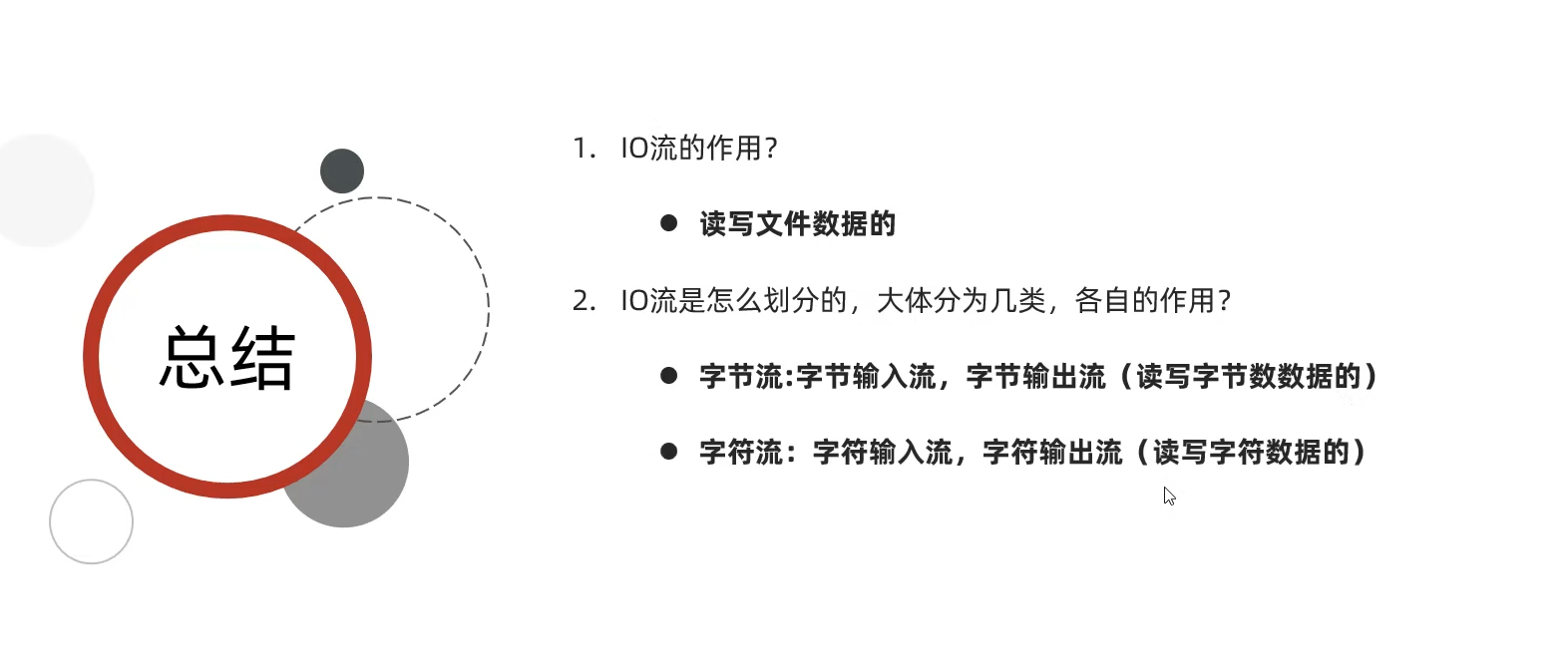
IO流也称为输入、输出流,就是用来读写数据的
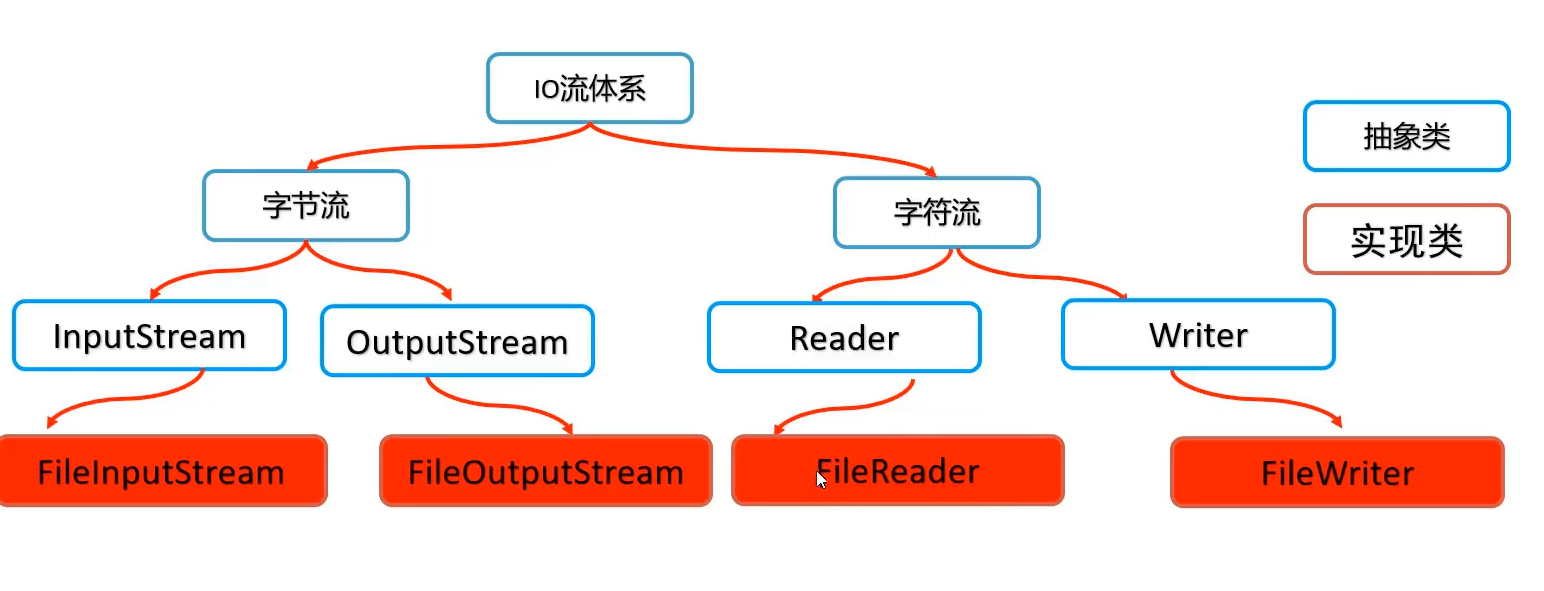
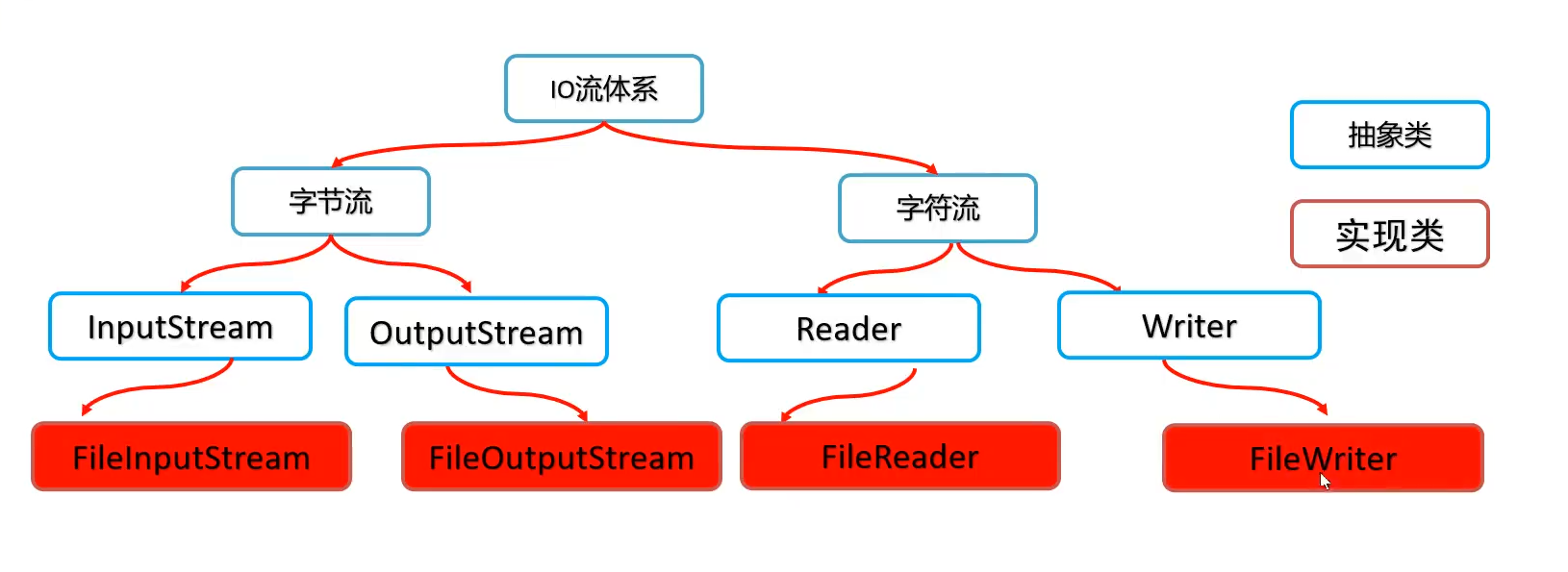
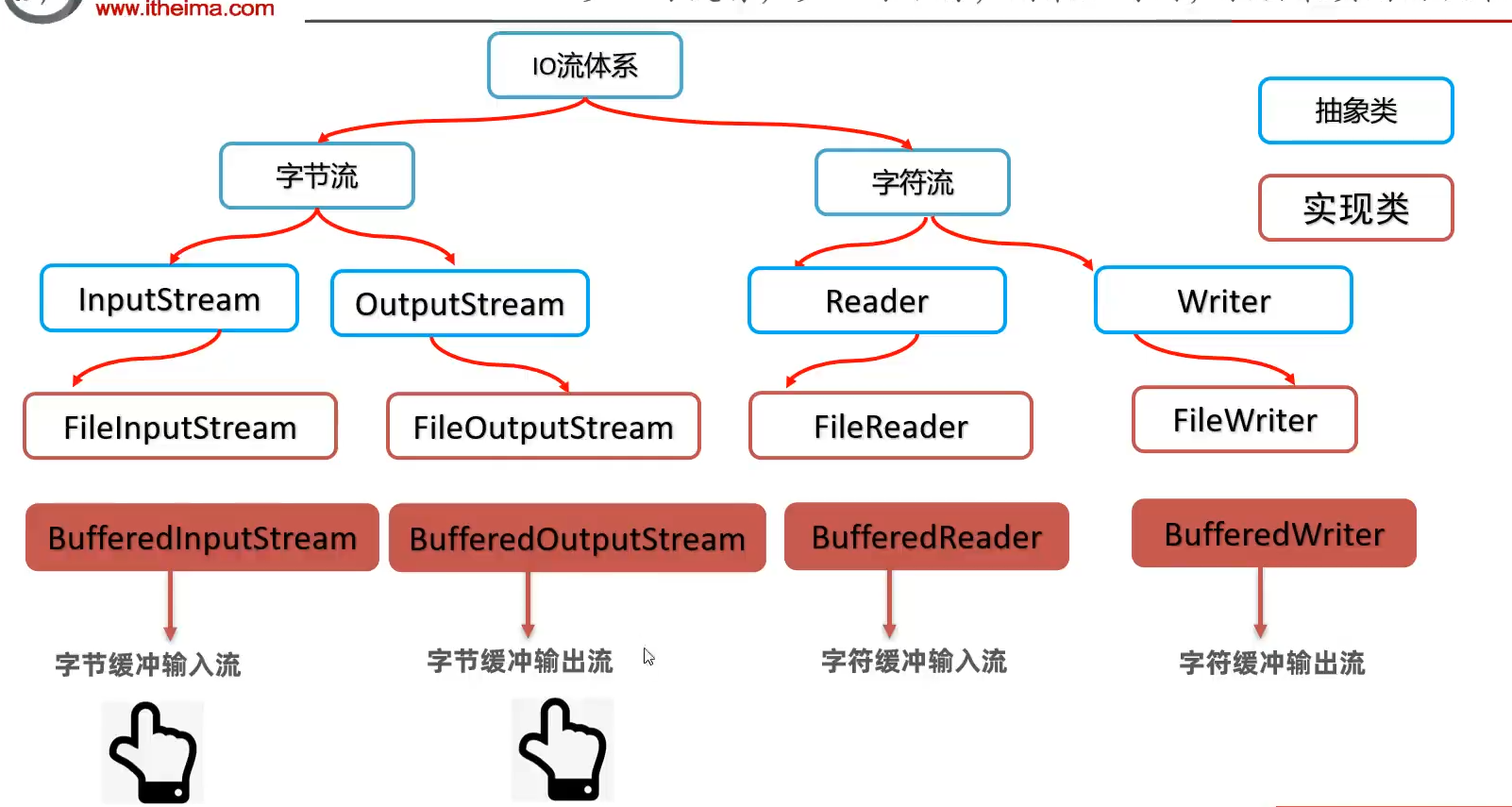
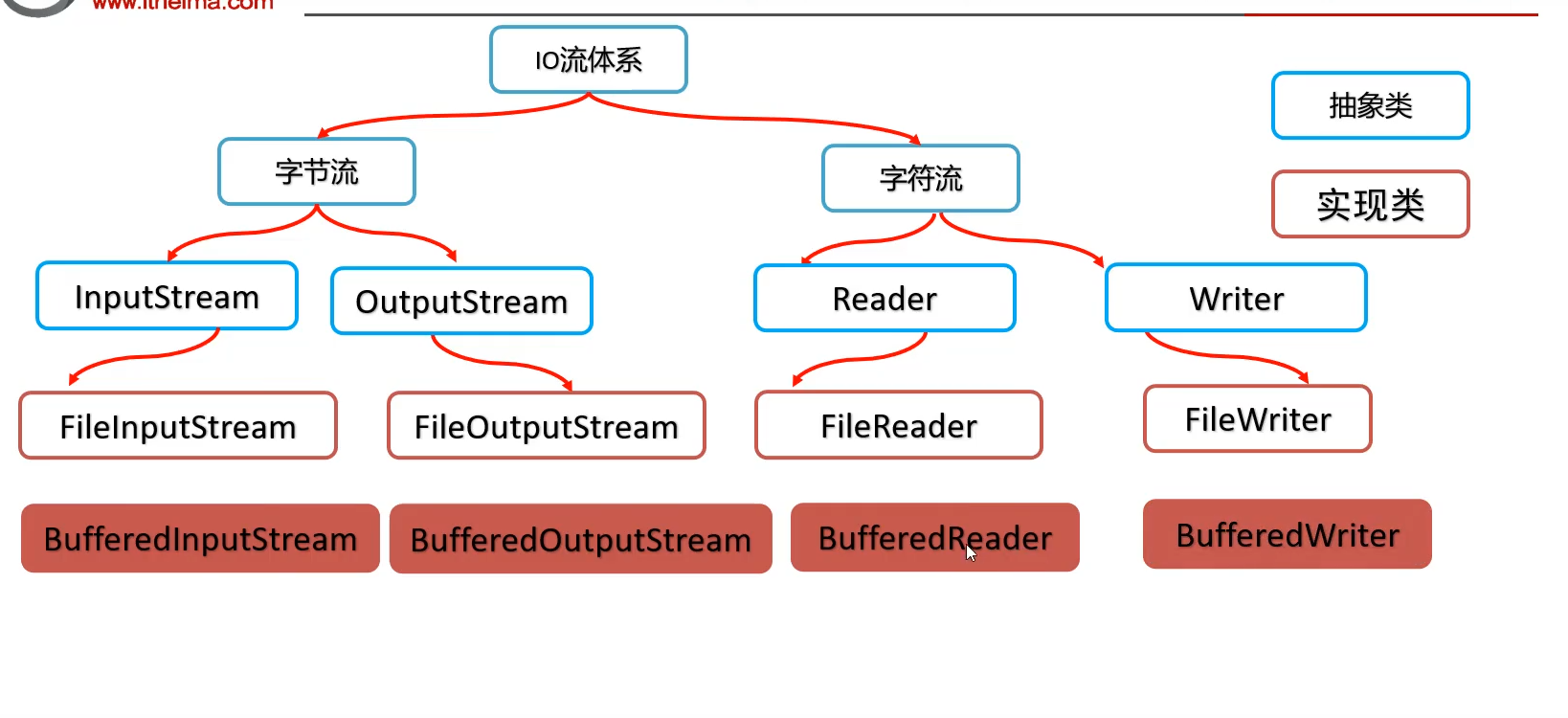
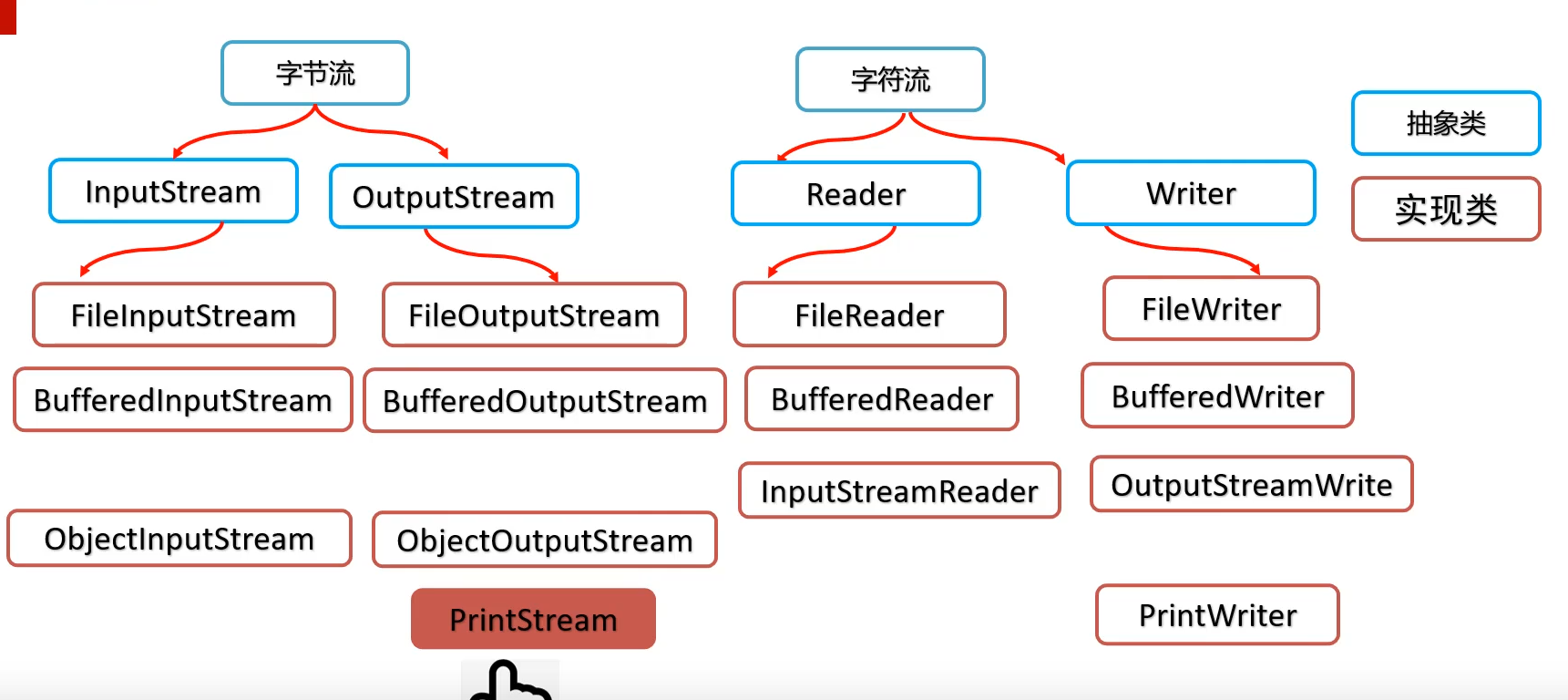
IO流的分类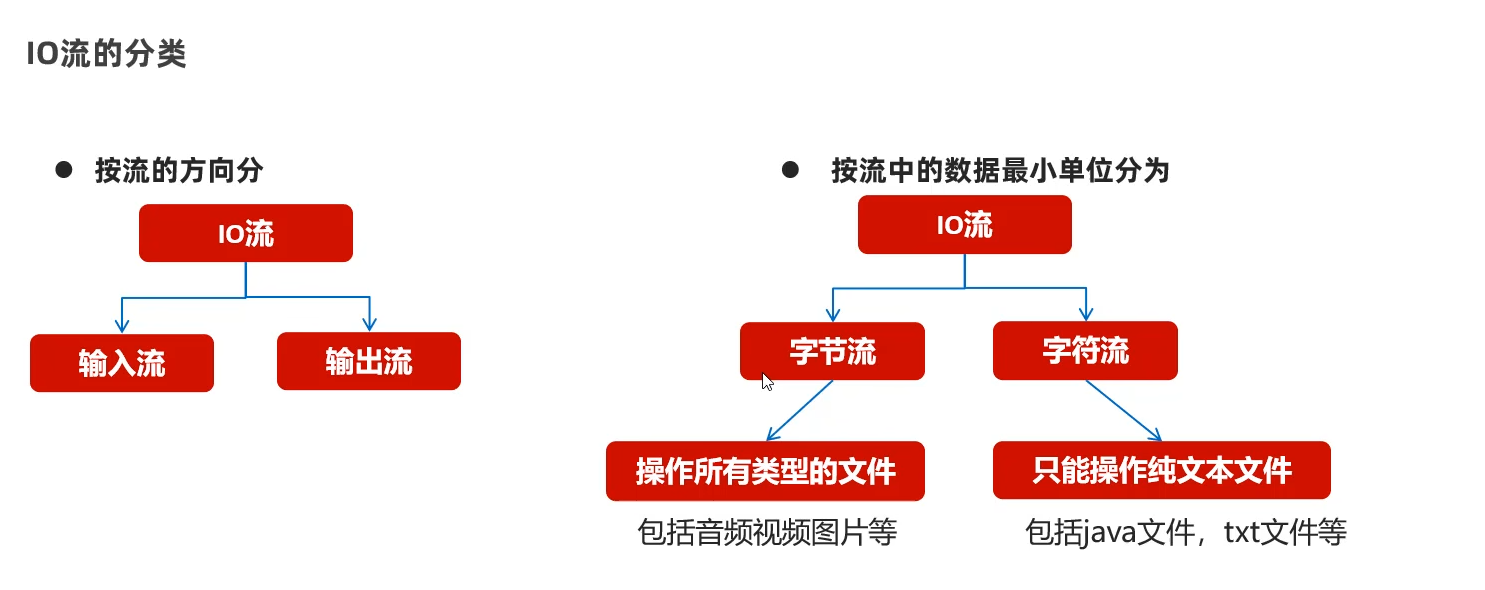
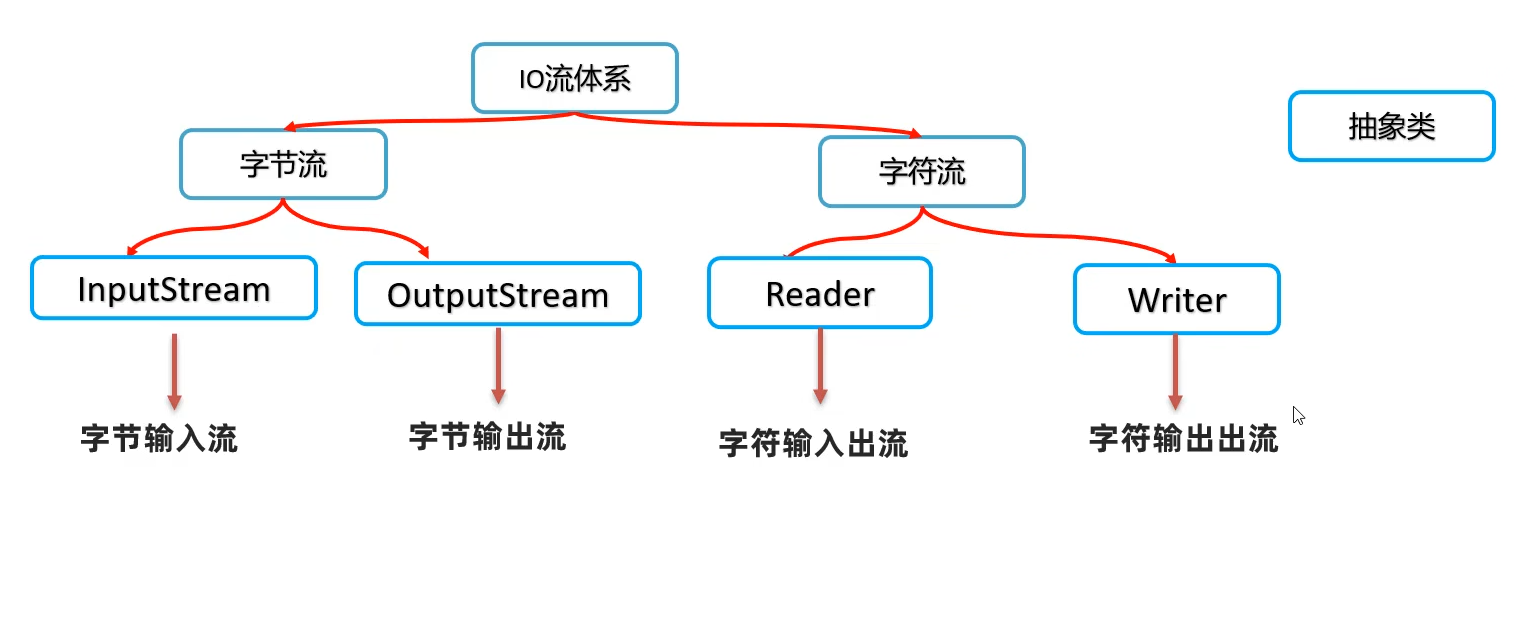
字节流的使用

public static void main(String[] args) throws IOException {//1.创建一个文件字节输入流管道与源文件相通InputStream is = new FileInputStream("JavaSE/src/data.txt");//读取一个字节返回(每次读取一滴水)int b1 = is.read();System.out.println((char) b1);int b2 = is.read();System.out.println((char)b2);int b3 = is.read();System.out.println((char) b3);int b4 = is.read();System.out.println(b4);//读取完毕返回-1int b;while ((b=is.read())!=-1){System.out.print((char)b);}//一次只能读取一个字节不能读取中文,有乱码}

文件字节输入流:一次读取一个字节数组
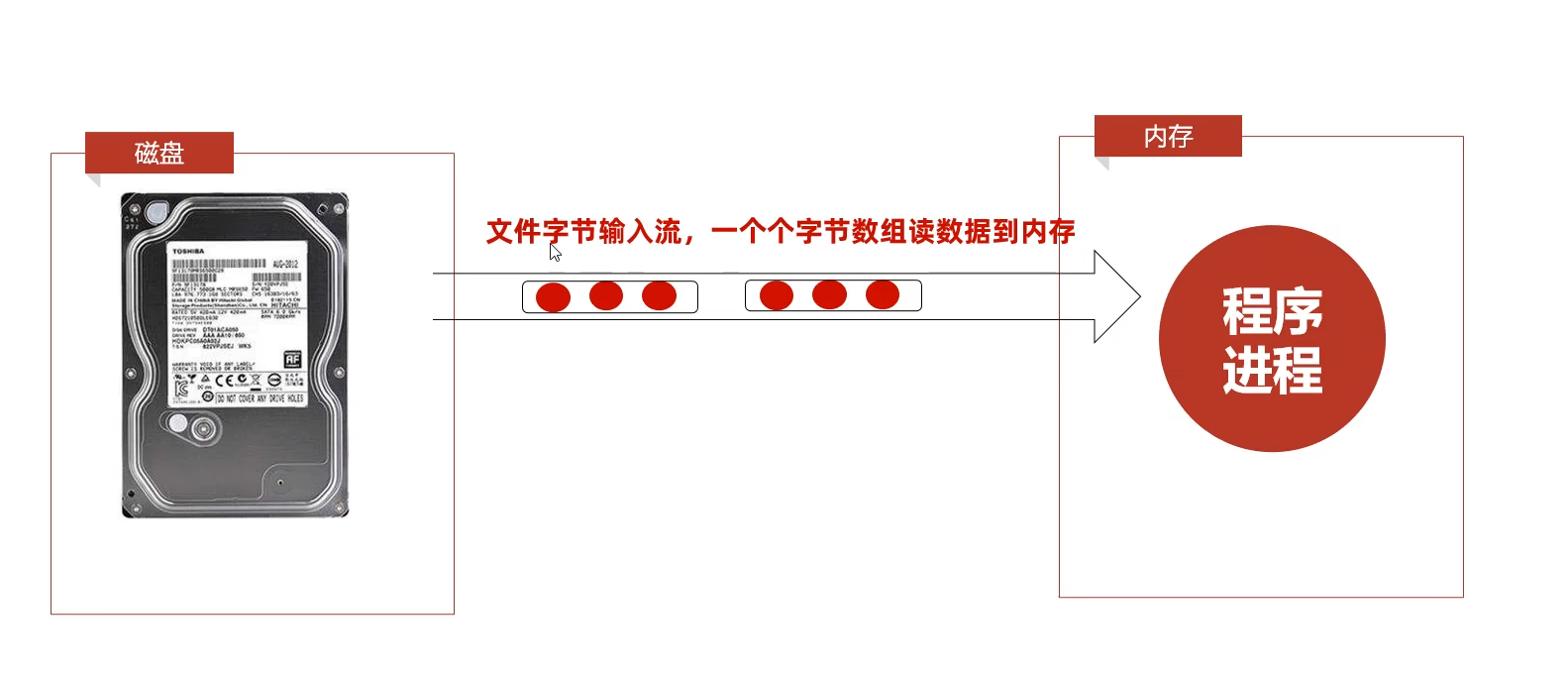

public static void main(String[] args) throws IOException {//1.创建一个文件字节输入流管道与源文件接通InputStream is = new FileInputStream("JavaSE/src/data2.txt");//2.一次读取三个字节byte[] buffer = new byte[3];int len;while ((len = is.read(buffer))!=-1){//读到buffer里面了//读字节是采用追加的方式进行的比如abcab,一次性读3个字节第一次buffer abc 都二次的结果就是abc,而不是ab,所以解码的时候需要指定长度String str = new String(buffer,0,len);//解码System.out.print(str);}}
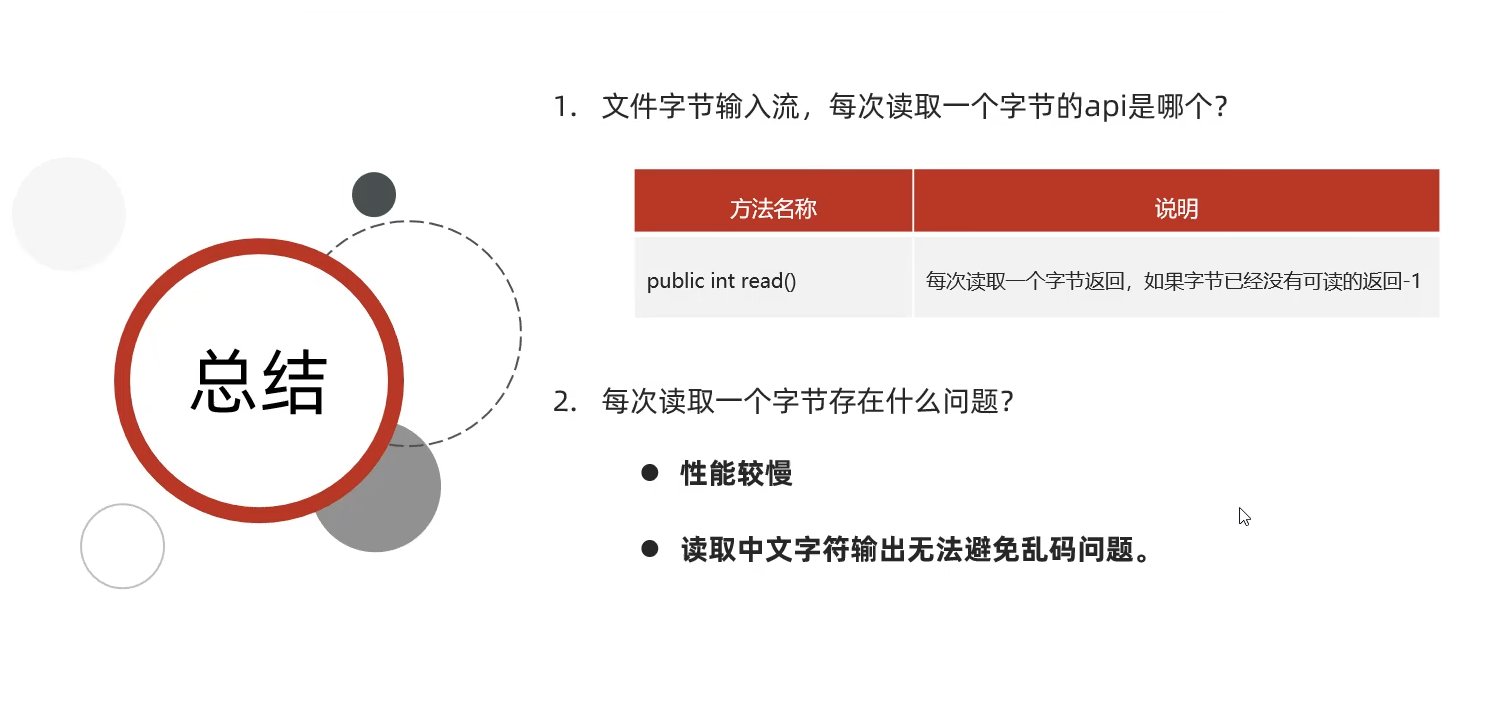
思考:如何使用字节输入流读取中文内容输出不乱码呢?
- 定义一个与文件一样大的字节数组,一次性读取完文件的全部字节。
直接把文件数据读取到一个字节数组可以避免乱码,是否存在问题?
- 如果文件过大,字节数组可能引起内存溢出。


字节输出流 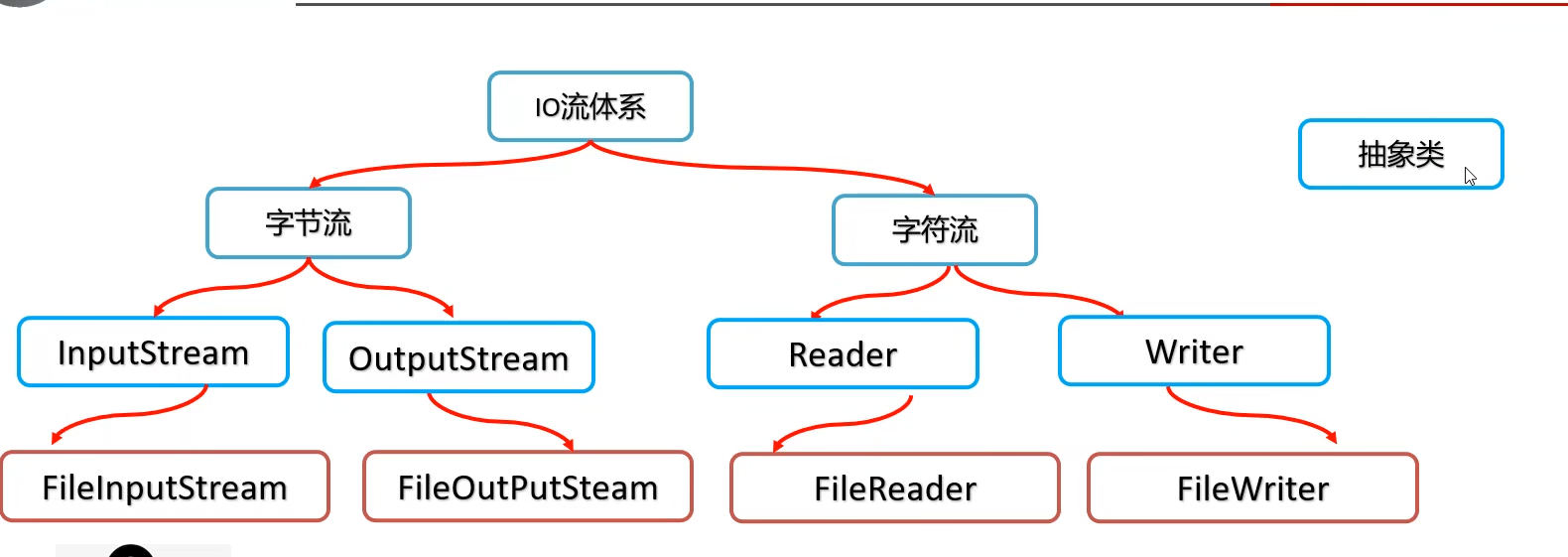



文件拷贝
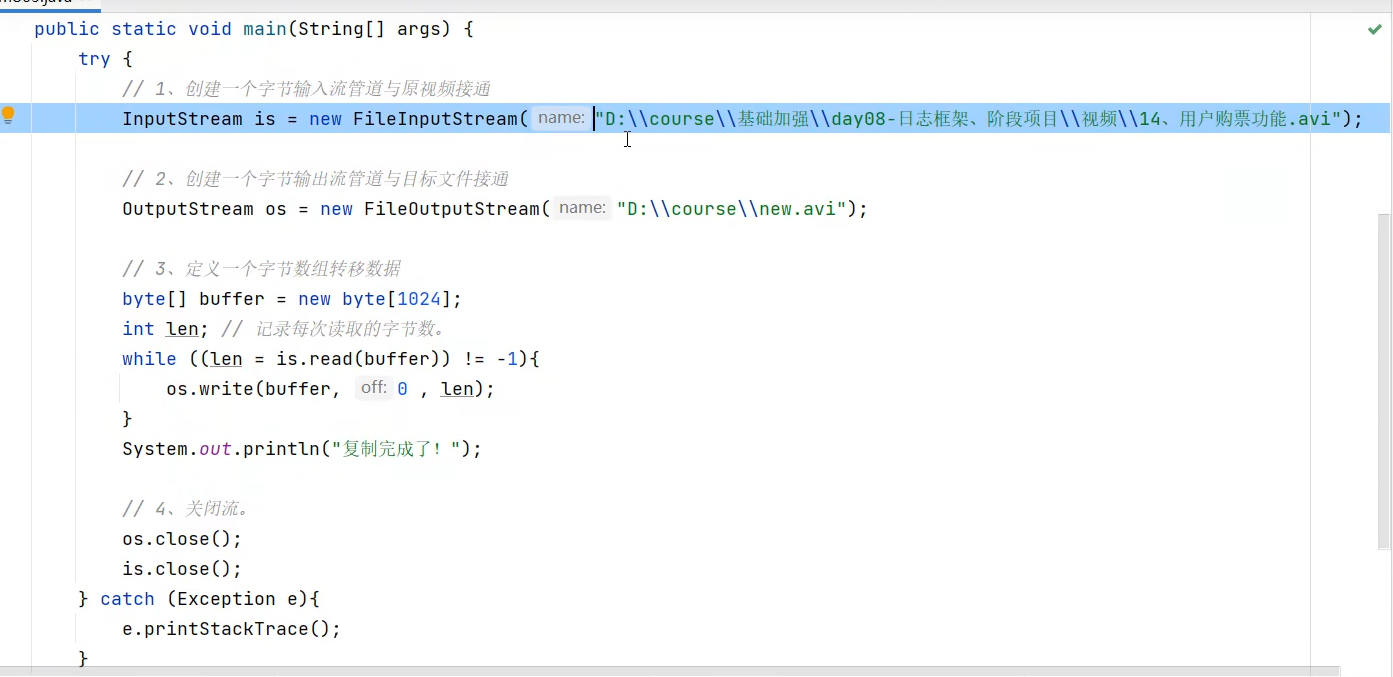

资源释放的方式
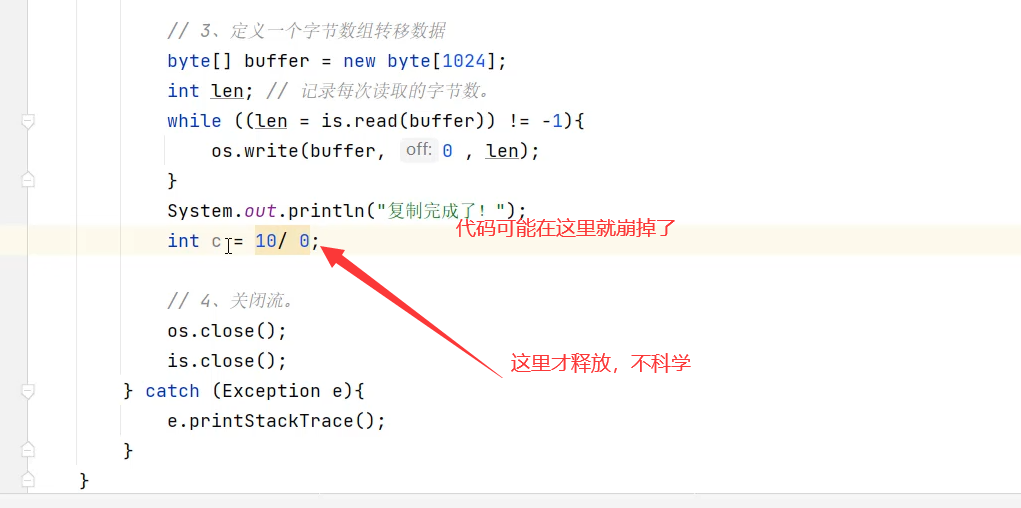
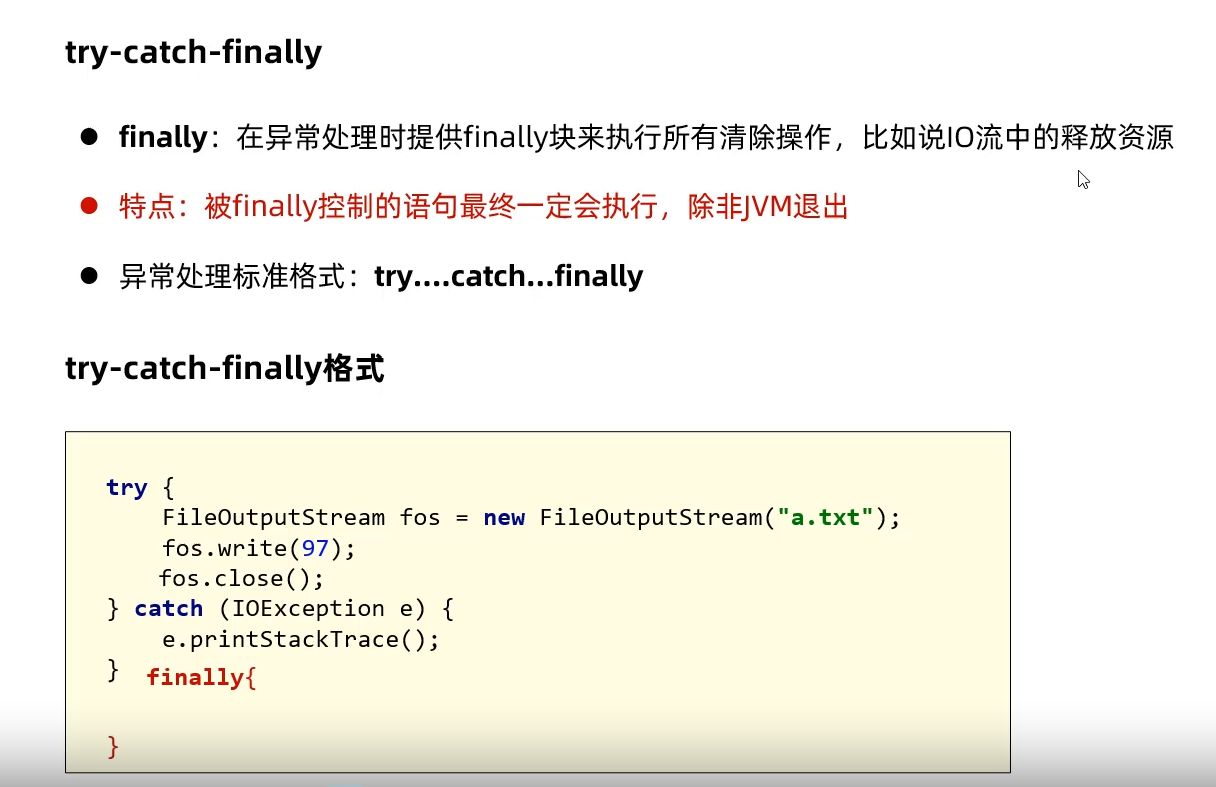
try-catch-final

try-with-resource


总结
字符流的使用
文件字符输入流-一次读取一个字符


//目标每次读取一个字符//1.创建一个字符输入流管道,与原文件接通Reader fr = null;try {fr = new FileReader("JavaSE/src/data.txt");int len ;while ((len=fr.read())!=-1){System.out.print((char) len);}}catch (Exception e){e.printStackTrace();}finally {fr.close();}}}

文件字符输入流-一次读取一个字符数组

//目标每次读取一个字符//1.创建一个字符输入流管道,与原文件接通Reader fr = null;try {fr = new FileReader("JavaSE/src/data.txt");char[] srt = new char[5];int len ;//读取一个字符返回,如果没有就返回-1while ((len=fr.read(srt))!=-1){System.out.print(srt);}}catch (Exception e){e.printStackTrace();}finally {fr.close();}}}

文件字符输出流
Writer rw = null;try {rw = new FileWriter("JavaSE/src/out05.txt",true);rw.write("我爱你中国");rw.write("你好中国");}catch (Exception e){e.printStackTrace();}finally {rw.close();}}

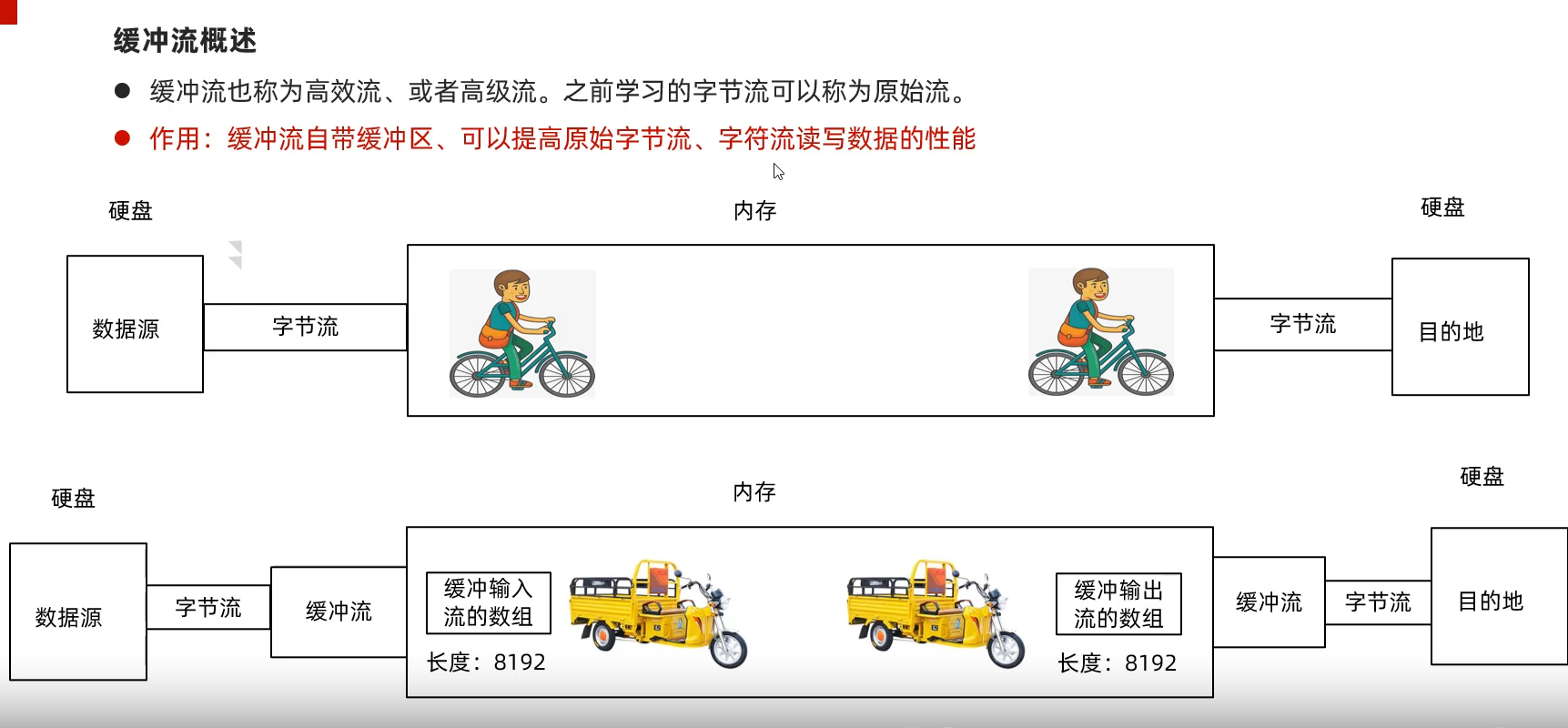
缓冲流
缓冲流概述
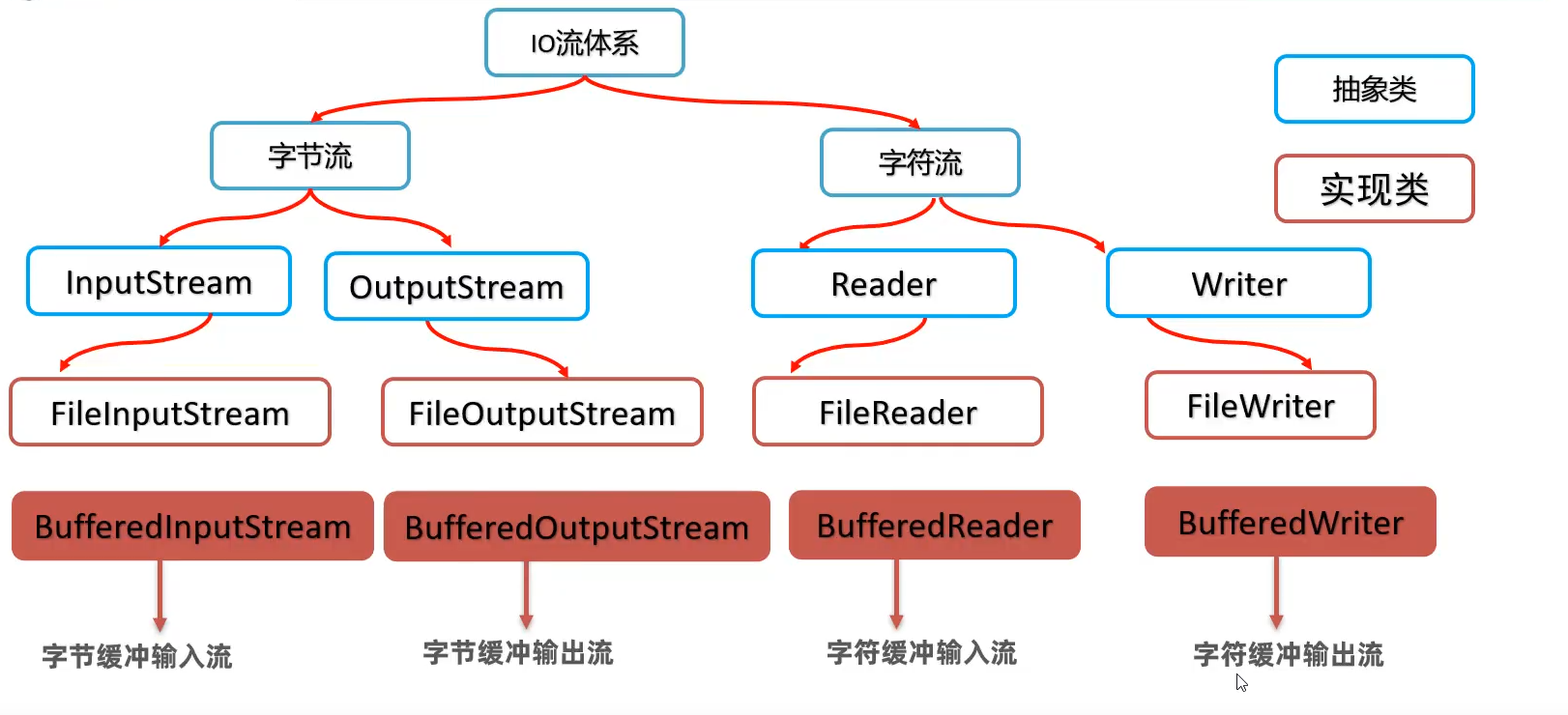
字节缓冲流
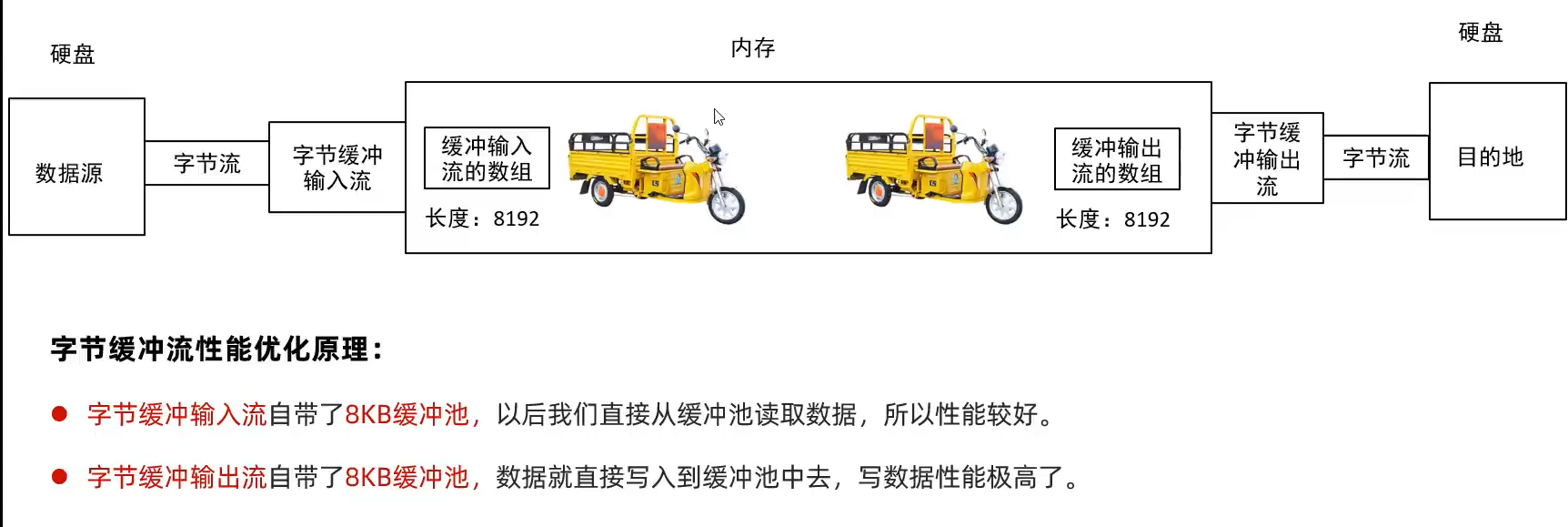


字符缓冲流

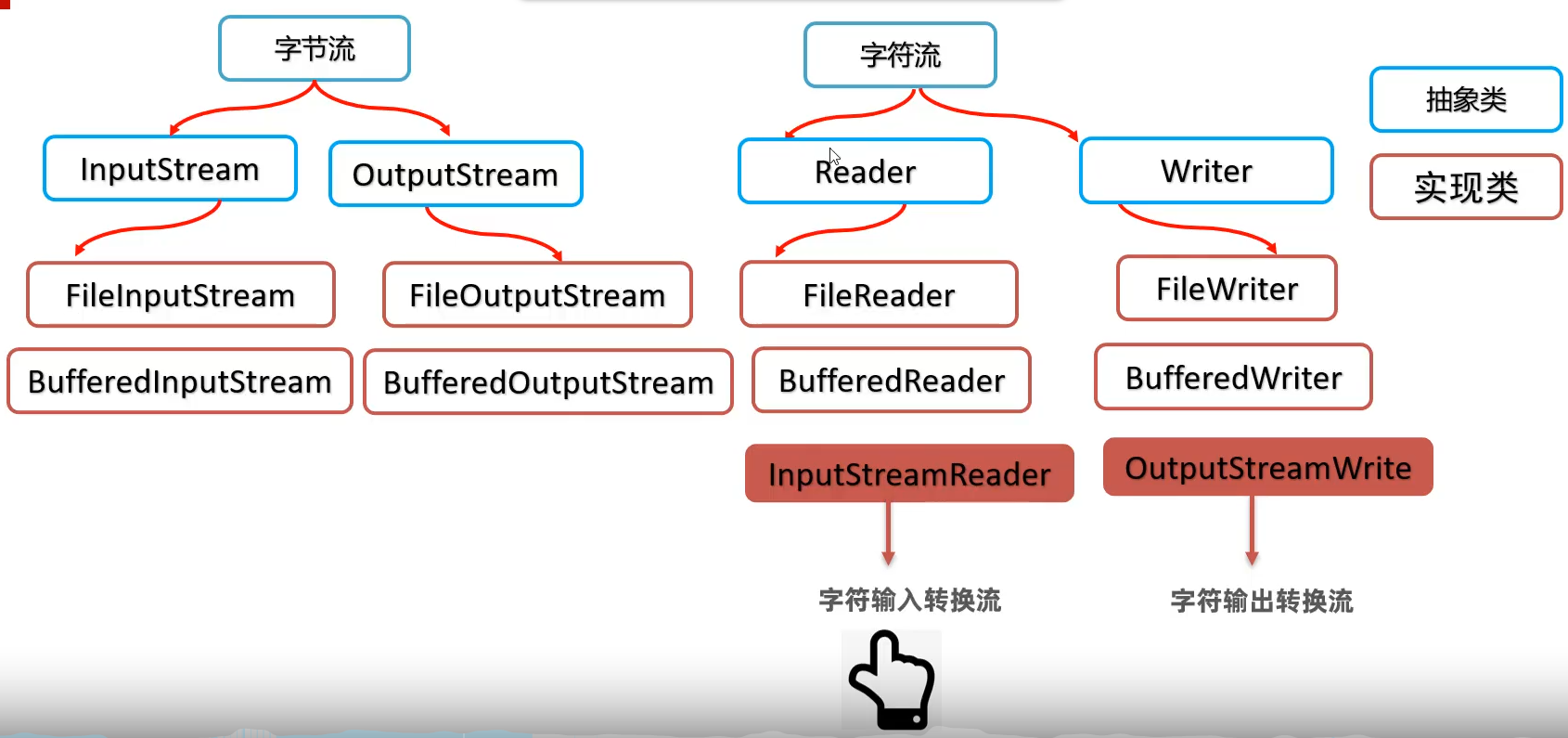
转换流
1.之前我们使用字符流读取中文是否有乱码?
没有的,因为代码编码和文件编码都是UTF-8
2.如果代码编码和文件编码不一致,使用字符流直接读取还能不乱吗?
会乱码
文件编码和读取的编码必须一致才不会乱码。
如何解决呢?
- 使用字符输入转换流
- 可以提取文件GBK的原始字节流,原始字节不会存在问题
- 然后把字节流以指定编码转换成字符输入流,这样字符输入流中的字符就不会乱码了

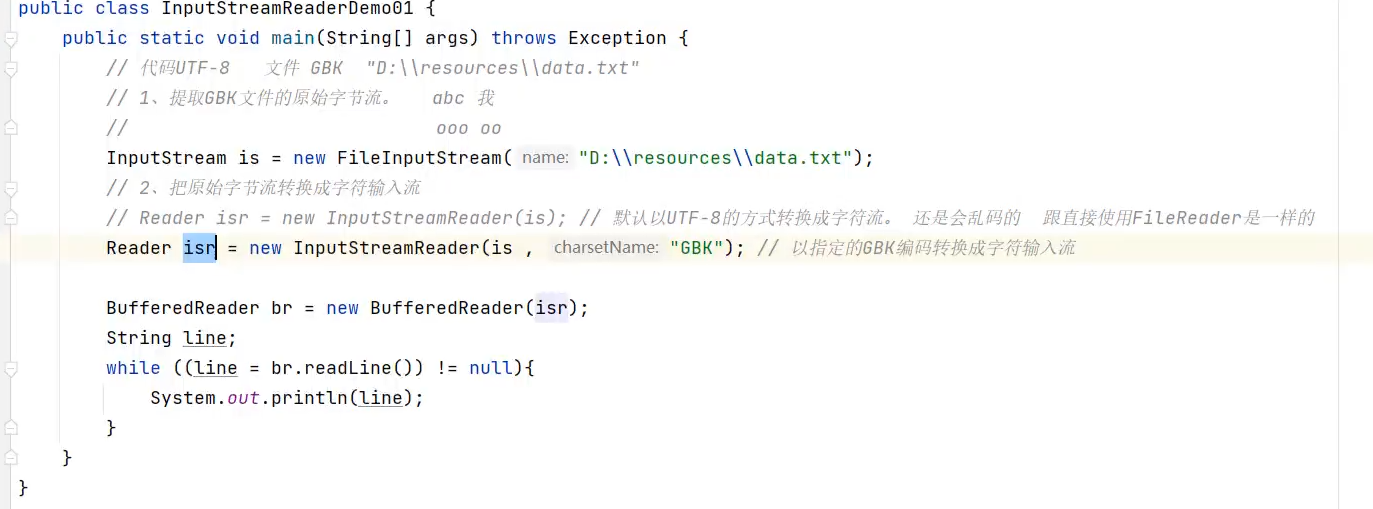
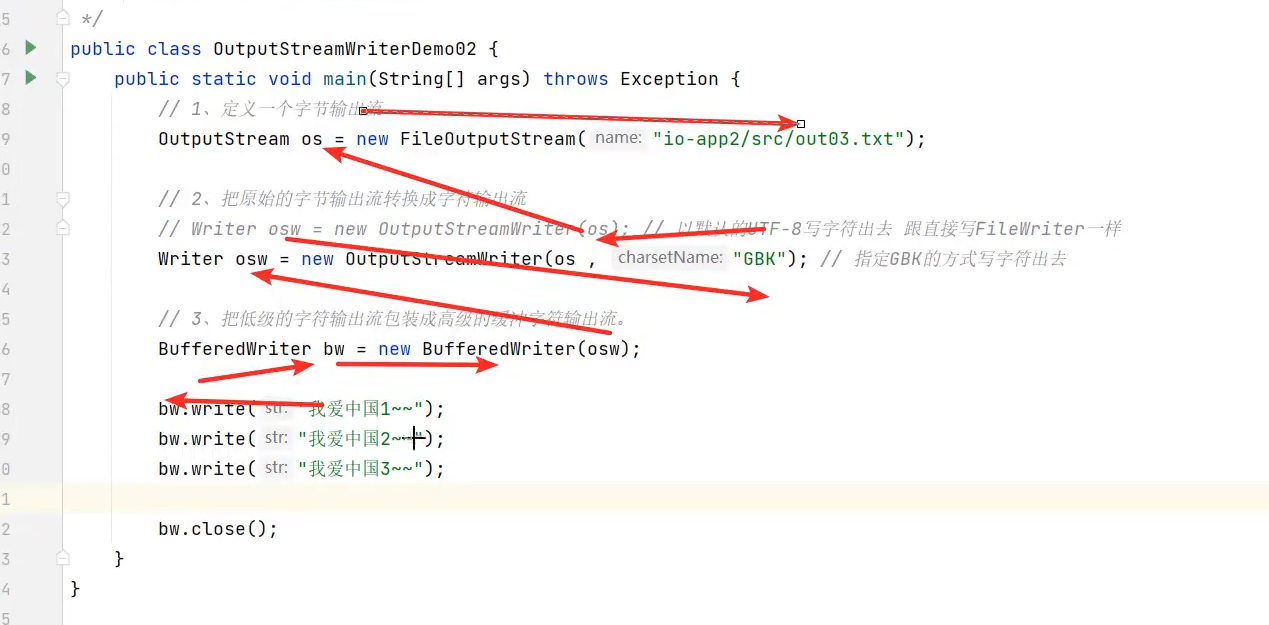
字符输出转换流

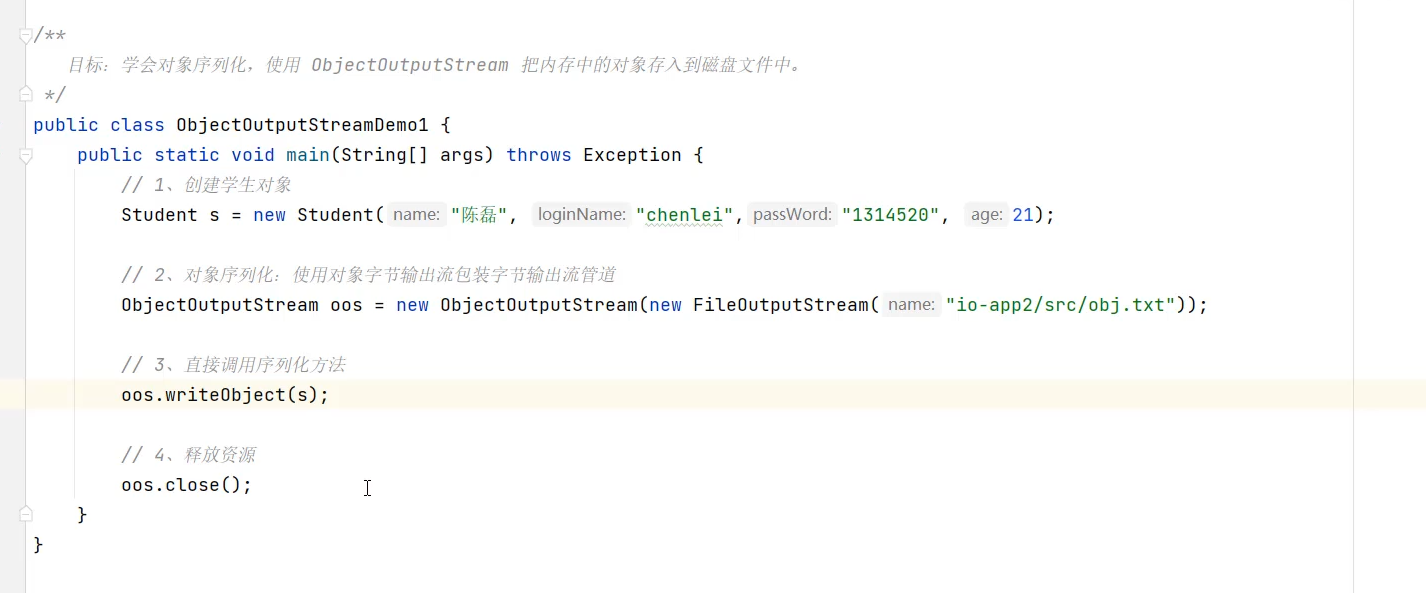
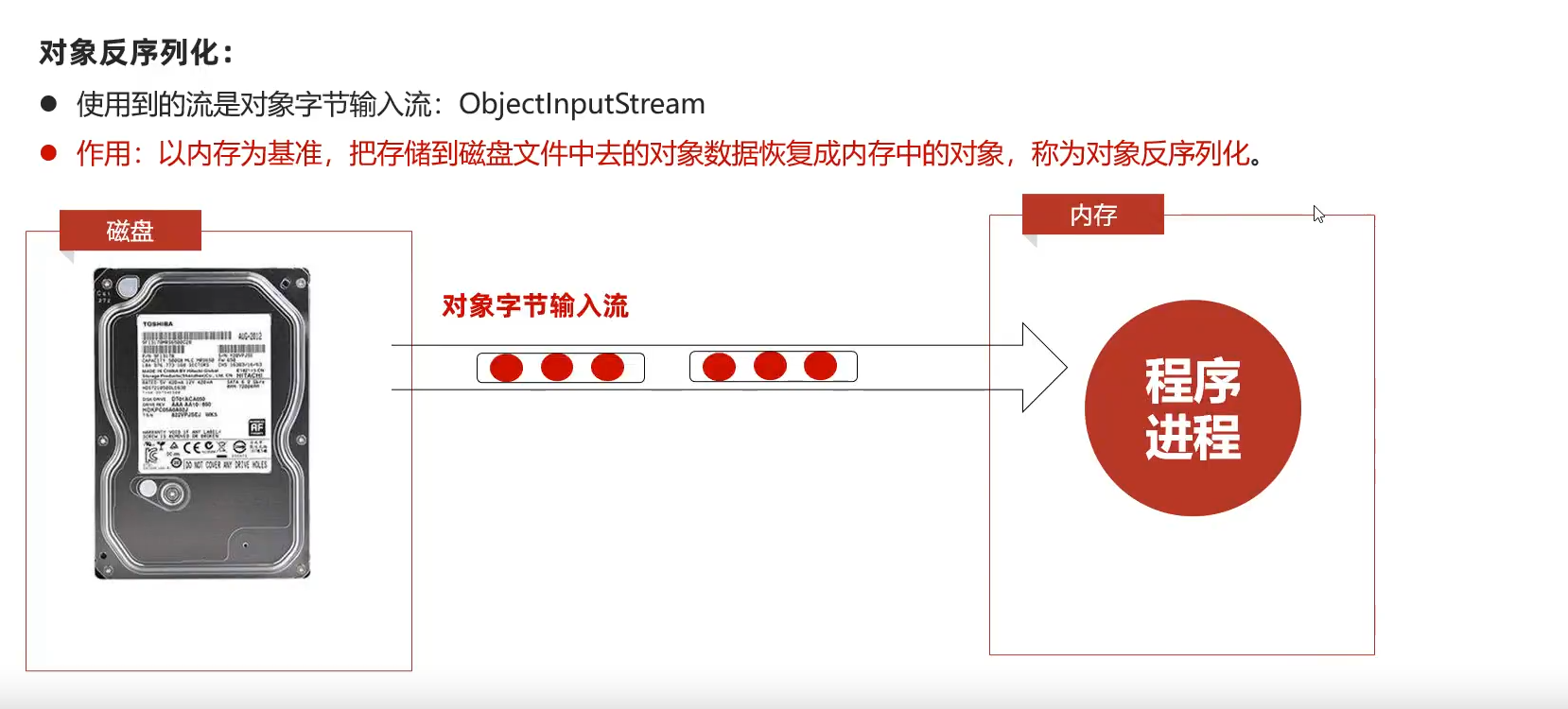
序列化对象





打印流
PrintStream、PrintWriter

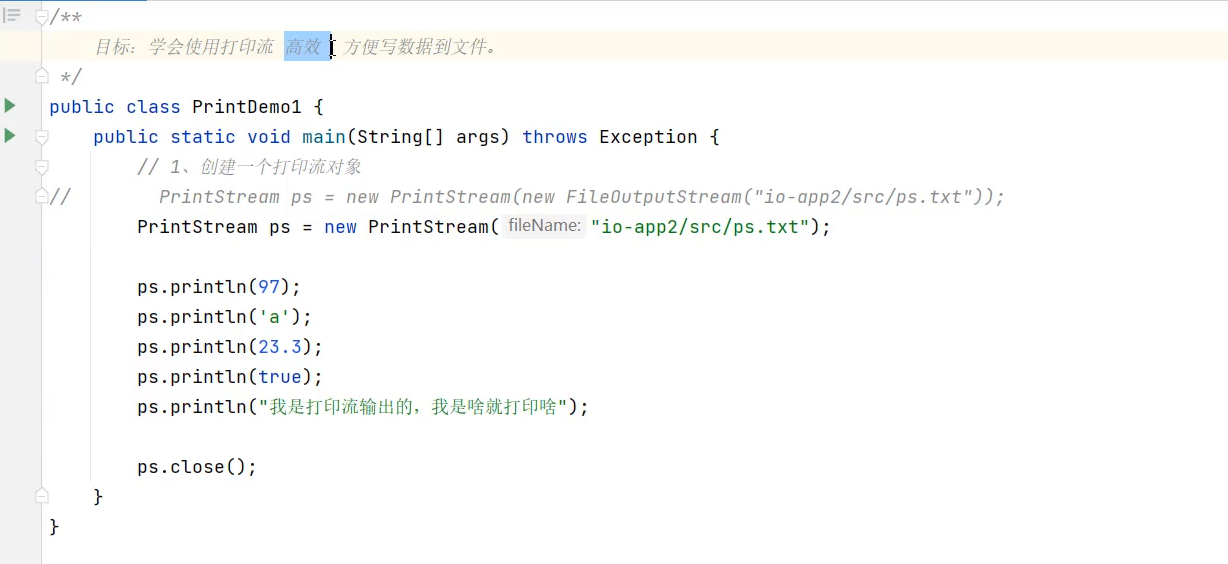


输出语句的重定向

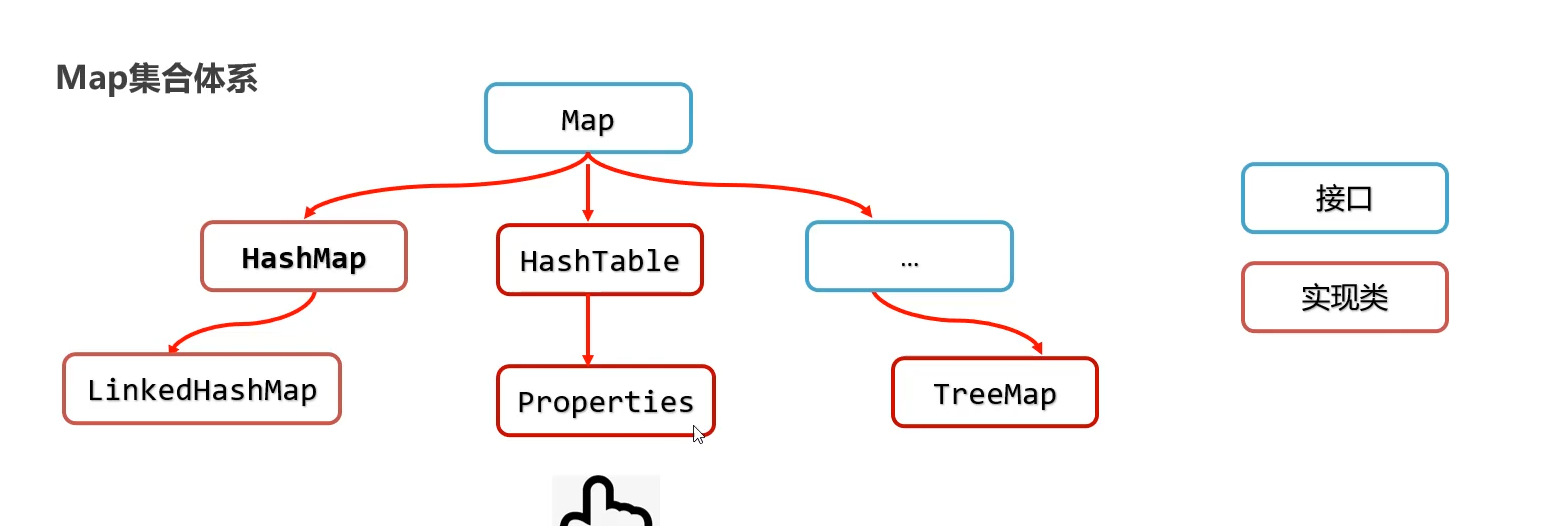
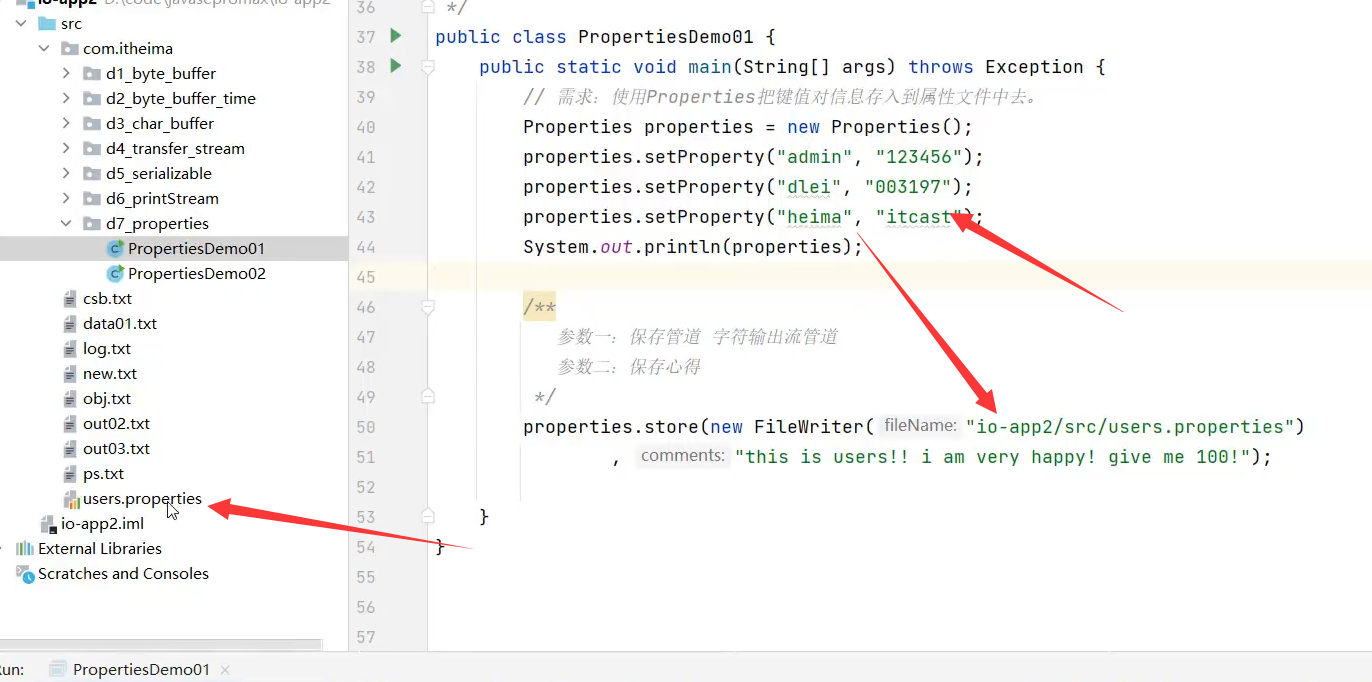
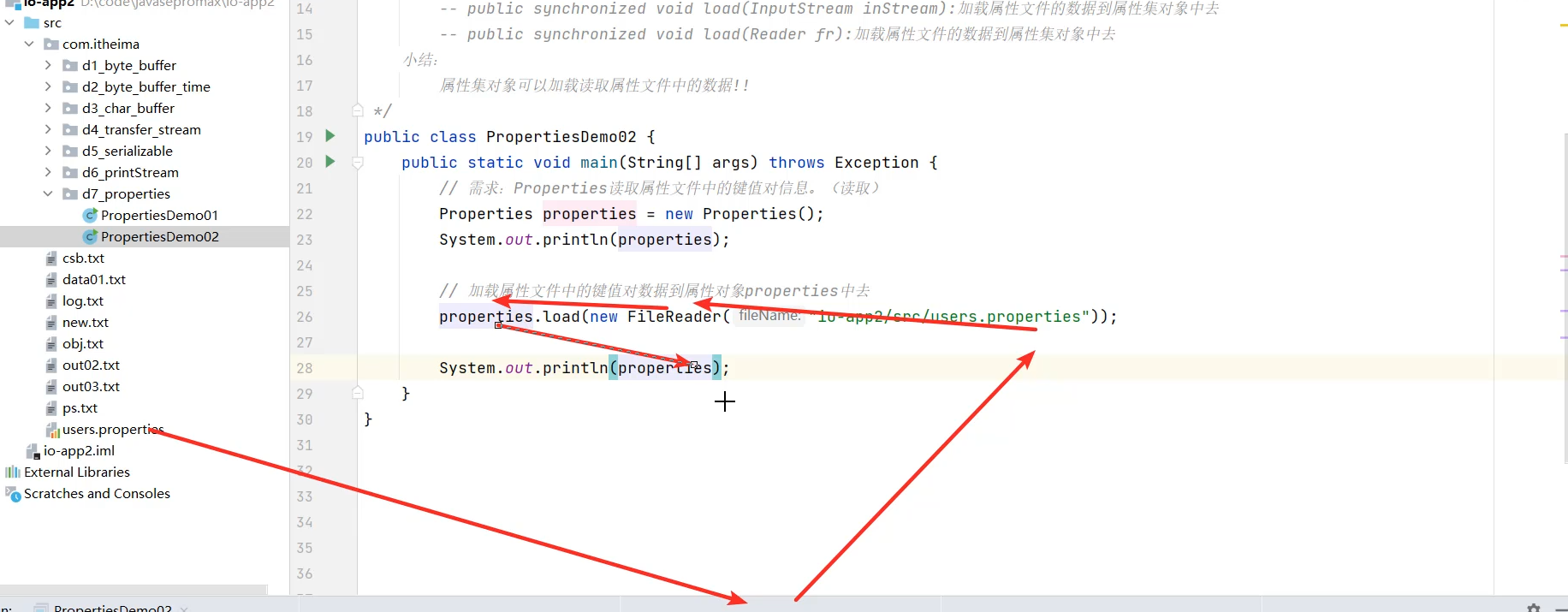
补充知识:Properties




若有收获,就点个赞吧
0 人点赞
