Session 7 Black-Box Testing — Boundary Value Analysis
Introduction of Black-Box Testing
- 黑盒测试设计技术
- Boundary Value Analysis 边界值分析
- Equivalence Patitioning 等价类划分
- Decision Table 判定表
- Cause-Effect Graph 因果图
- Combinatiorial Test 组合测试
- Boundary Value Analysis 边界值分析
需要黑盒测试的原因
基本思想
- 错误往往聚集在边界上
- 对所有输入的变量取
- min
- min+,略微比下界大
- nom(nominal, typical)
- max-,略微比上界小
- max
- min
- 错误往往聚集在边界上
- 例如:数组,循环,≤
- 输入的值必须在0-100中间
- 测试用例
- 0, 1, 56, 99, 100
- 0, 1, 56, 99, 100
- 输入的值必须在0-100中间
- Robustness Testing 健壮性测试
- 是对边界值分析的简单扩展
- max+和min-的测试用例
- 是对边界值分析的简单扩展
- 基于单缺陷假设 Single fault assumption (即假设只有一个参数会出错)
- Normal Boundary Values 基本边界值分析
- Robustness Boundary Values 健壮性边界值分析
- Normal Boundary Values 基本边界值分析
- 考虑多个变量取极端值
- Multiple Variable of Boundary Values (Worst-Case Testing) 多变量的边界值分析
- Robust Multiple Variable of Boundary Values (Robust Worst-Case Testing) 多变量的健壮性边界值分析
- Multiple Variable of Boundary Values (Worst-Case Testing) 多变量的边界值分析
Example
- 函数F,变量x和y
a <= x <= bc <= y <= d
- Normal Boundary Values 一般边界值
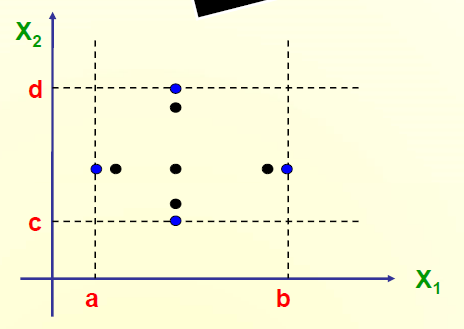
- 针对n个变量,4n+1个测试用例
Robustness Boundary Values 健壮边界值
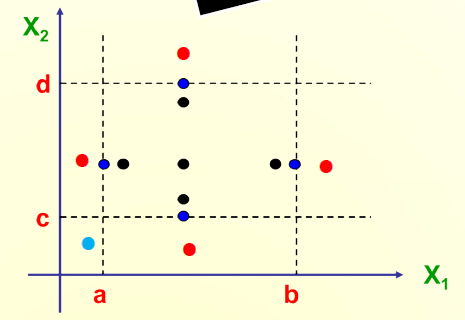
- 针对n个变量,6n+1个测试用例
浅蓝色的点不能取
Multiple Variable of Boundary Values 多变量的边界值
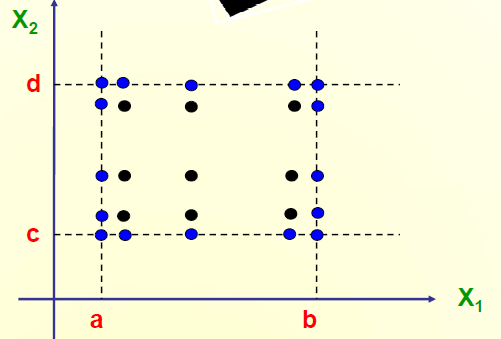
- 针对n个变量,5n个测试用例
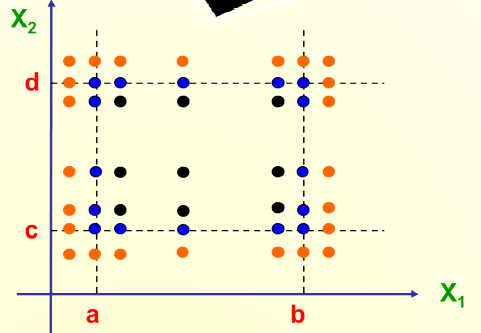
Robust Multiple Variable of Boundary Values 健壮的多变量边界值
输入的字母数范围为[1,255]
- 边界值:1,255
- 边界值:1,255
- CD-R读写(一次性的光盘刻录)
- 边界值:空文件,满文件
- 边界值:空文件,满文件
打印机
输入三个整数a, b, c作为三条边的长度
1<=a<=2001<=b<=2001<=c<=200
- 基本边界值分析需要4n+1= 13个测试用例 | a | b | c | Equilateral | Isosceles | scalene | NotATriangle | | —- | —- | —- | —- | —- | —- | —- | | 1 | 100 | 100 | | True | True | | | 2 | 100 | 100 | | True | True | | | 199 | 100 | 100 | | True | True | | | 200 | 100 | 100 | | | | True | | 100 | 1 | 100 | | True | True | | | 100 | 2 | 100 | | True | True | | | 100 | 199 | 100 | | True | True | | | 100 | 200 | 100 | | | | True | | 100 | 100 | 1 | | True | True | | | 100 | 100 | 2 | | True | True | | | 100 | 100 | 199 | | True | True | | | 100 | 100 | 200 | | True | True | True | | 100 | 100 | 100 | True | True | | |
The NextDate Problem
- 输入三个整型变量 month, day, year
1 <= month <= 121 <= day <= 311812 <= year <= 2012
- 输出这个日期的第二天
测试用例
假设所有参数是独立的
- 忽略参数的语义信息
-
✨Advantages of BVA
给定边界后,设计测试用例很简单廉价
- N个变量可以生成4n+1, 6n+1, 5n, 7n个测试用例
-
Exercise 1
There are three integer inputs x, y, z, corresponding to the length, width and height of a rectangle respectively. All of these three inputs are in the range of [2, 20], the output is the volume of the rectangle.
List the number of test cases that needed by four types of boundary value analysis respectively
- normal : 4n+1 = 13
- robustness: 6n+1 = 19
- mutiple: 5^n = 125
- robustness mutiple: 7^n = 49*7 = 343
- normal : 4n+1 = 13
- Design the test cases by Robustness Boundary Value Analysis. | x | y | z | volume | | —- | —- | —- | —- | | 1 | 11 | 11 | 121 | | 2 | 11 | 11 | 242 | | 3 | 11 | 11 | 363 | | 19 | 11 | 11 | 19121 | | 20 | 11 | 11 | 20121 | | 21 | 11 | 11 | 21*121 | | 11 | 1 | 11 | | | 11 | 2 | 11 | | | 11 | 3 | 11 | | | 11 | 19 | 11 | | | 11 | 20 | 11 | | | 11 | 21 | 11 | | | 11 | 11 | 1 | | | 11 | 11 | 2 | | | 11 | 11 | 3 | | | 11 | 11 | 19 | | | 11 | 11 | 20 | | | 11 | 11 | 21 | | | 11 | 11 | 11 | |
Exercise2
找零钱最佳组合:假设商店货品价格(R)皆不大于100元(且为整数),若顾客付款在100元内(P),求找给顾客的最少货币个(张)数?货币面值50元,10元,5元,1元四种
1)输入情况有R>100, 0
| 编号 | R | P | 预期输出结果 |
|---|---|---|---|
| 1 | 101 | 102 | 非法输入 |
| 2 | 101 | 101 | 非法输入 |
| 3 | 101 | 100 | 非法输入 |
| 4 | 101 | 99 | 非法输入 |
| 5 | 100 | 101 | 非法输入 |
| 6 | 100 | 100 | n50=0,n10=0,n5=0,n1=0 |
| 7 | 100 | 99 | 非法输入 |
| 8 | 50 | 101 | 非法输入 |
| 9 | 50 | 100 | n50=1,n10=0,n5=0,n1=0 |
| 10 | 50 | 99 | n50=0,n10=4,n5=1,n1=4 |
| 11 | 50 | 75 | n50=0,n10=2,n5=1,n1=0 |
| 12 | 50 | 51 | n50=0,n10=0,n5=0,n1=1 |
| 13 | 50 | 50 | n50=0,n10=0,n5=0,n1=0 |
| 14 | 50 | 49 | 非法输入 |
| 15 | 0 | 101 | 非法输入 |
| 16 | 0 | 100 | 非法输入 |
| 17 | 0 | 50 | 非法输入 |
| 18 | 0 | 0 | 非法输入 |
| 19 | 0 | -1 | 非法输入 |
| 20 | -1 | 101 | 非法输入 |
| 21 | -1 | 100 | 非法输入 |
| 22 | -1 | 50 | 非法输入 |
| 23 | -1 | -1 | 非法输入 |
| 24 | -1 | -2 | 非法输入 |
Session 8 Equivalence Partitioning
- 等价类划分
-
Equivalence Class 等价类
利用等价类中的一种测试用例来代表整个等价类
- 来检测是否有缺陷
- 来检测是否有缺陷
- 等价类应该是成对不相交的(没有重叠,减少测试的冗余性)
-
Motivation
如果等价类中的一个测试用例检测到了缺陷,那么跟它在一个等价类中的其他测试用例也很有可能会检测到相同的缺陷
- 反之也成立
Steps of EC Paritioning Testing
- 确认输入和输出的参数
识别这些参数的特征
比如说输入的范围,变量之间的关系
每一种特征被划分为一个等价类
挑选一种组合等价类的策略
强测试还是弱测试
找出等价类的不可行的组合
- 生成测试用例
Equivalence Class Testing 等价类测试
- 弱一般等价类测试
- Weak Normal Equivalence Class Testing
- Weak Normal Equivalence Class Testing
- 强一般等价类测试
- Strong Normal Equivalence Class Testing
- Strong Normal Equivalence Class Testing
- 弱健壮等价类测试
- Weak Robust Equivalence Class Testing
- Weak Robust Equivalence Class Testing
- 强健壮等价类测试
- Strong Robust Equivalence Class Testing
- Strong Robust Equivalence Class Testing
- Strong ECTesting
- 所有变量的迪卡尔积
- ECx × ECy = {(x1,y1),(x1,y2),(x2,y1),(x2,y2),(x3,y1),(x3,y2)}
- 所有变量的迪卡尔积
Weak ECTesting
Simple Fault 一个变量
- Pair-wise interaction fault 两个变量
int x, y;
input(x, y);
if(x>=0){ // 这里应该是 x+1>=0
output(2y);
}else{
output(3y);
}
则弱测试就足够检测出程序中的问题
int x, y;
input(x, y);
if(x&&y){ // 这里应该是 x||y
output(f(x,y));
}else{
output(g(x,y));
}
需要强测试才能检测出fault
强测试的缺陷:会产生很多不可能的,赘余的,没有用的测试用例
- 弱一般等价类测试
- 每次取一个等价类的变量
- 每次取一个等价类的变量
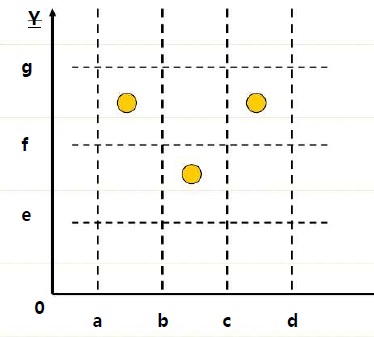
- 强一般等价类测试
- 当变量之间会相互影响的时候很有效
- 可以反映出一些特定组合情况下才会出现的财务偶
- 当变量之间会相互影响的时候很有效
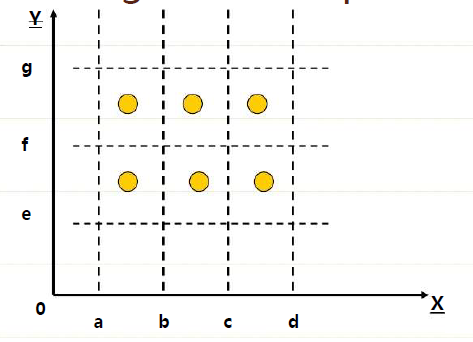
- 弱健壮等价类测试
- 对于有效的输入,等同于弱一般等价类测试
- 对于无效的输入,必须只有一个无效的值,其余的值还是有效的
- 对于有效的输入,等同于弱一般等价类测试
强健壮等价类测试
- 考虑所有无效输入的值
混合路径 Hybrid approach
- 强一般+弱健壮
测试用例数量的计算
- 有n个变量
- 有效的等价类
无效的等价类
Valid ECs:
- V1 = {
- V2 = {
- V3 = {
- V1 = {
- Invalid ECs:
- IV1 = {
- IV2 = {
- IV3 = {
- IV4 = {
- IV1 = {
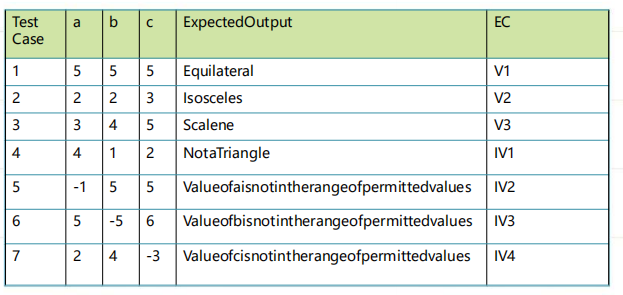
- 针对2,没有测试不同的等腰
- 针对4,没有测试上边界
- 针对5,6,7,没有测试超上边界的值
// possible error
if(a==b && b==c)
output(“Equilateral”)
else if (a==b)
output(“Isosceles”);
else
output(“Scalene”);
定义测试用例的指南
- 如果输入是范围,那么应该定义一个有效输入,两个无效输入的等价类
- 如果输入是一个特定的值,那么应该定义一个有效的一个无效的等价类
- 如果输入是一组数据,那么应该定义一个有效的和一个无效的等价类
- 如果输入的是一个布尔值,那么应该定义一个有效和一个无效的等价类
- 递归
Design EC tests cases for the nextDate Problem based on input
- 弱一般等价类,1条
- 强一般等价类,1条
- 弱健壮等价类,7条
- 强健壮等价类,27条
- 合法
- 1999.10.8
- 1999.10.8
- 日非法
- 1912.1.-1
- 1912.1.31
- 1912.1.-1
- 月非法
- 1912.-1.1
- 1912.13.1
- 1912.-1.1
- 年非法
- 1000.1.1
- 3000.1.1
- 1000.1.1
- 日月非法
- 1912.-1.-1
- 1912.13.32
- 1912.-1.32
- 1912.13.-1
- 1912.-1.-1
- 日年非法
- 1000.1.-1
- 1000.1.32
- 3000.1.-1
- 3000.1.32
- 1000.1.-1
- 月年非法
- 1000.-1.1
- 1000.13.1
- 3000.-1.1
- 3000.13.1
- 1000.-1.1
- 日月年非法
- 1000.-1.-1
- 1000.-1.32
- 1000.13.-1
- 1000.13.32
- 3000.-1.-1
- 3000.-1.32
- 3000.13.-1
- 3000.13.32
- 1000.-1.-1
- 合法
- 弱一般
- 4条
- 2000.1.1
- 1999.1.29
- 2001.3.30
- 2004.5.31
- 4条
- 强一般
- 3x4x3
- 3x4x3
- 弱健壮
- 4+2+2+2
- 4+2+2+2
- 强健壮
- 5x6x5
- 5x6x5
- 混合
- 3x4x3+2+2+2
- 3x4x3+2+2+2

- 有效等价类
- 用户名
- 首字符数字,大于4位,小于16位,且字符全部合法
- 首字符为字母,大于4位,小于16位,且字符全部合法
- 首字符数字,大于4位,小于16位,且字符全部合法
- 密码
- 6位到16位,且字符全部合法
- 6位到16位,且字符全部合法
- 确认密码
- 和密码相同
- 和密码相同
- 用户名
- 无效等价类
- 用户名
- 长度小于等于4位
- 长度大于等于16位
- 首字符不是字母和数字
- 包含非法字符
- 长度小于等于4位
- 密码
- 长度小于6位
- 长度大于16位
- 包含非法字符
- 长度小于6位
- 确认密码
- 和密码不同
- 和密码不同
- 用户名

- 有效等价类
- 地区码
- 空白
- 三位数字
- 空白
- 前缀
- 非‘0’或‘1’开头的三位数
- 非‘0’或‘1’开头的三位数
- 后缀
- 四位数字
- 四位数字
- 地区码
- 无效等价类
- 地区码
- 1-2位数字
- 大于等于4位的数字
- 包含非数字
- 1-2位数字
- 前缀
- 包含非数字
- 0开头的三位数
- 1开头的三位数
- 1-2位数
- 大于等于4位的数字
- 包含非数字
- 后缀
- 包含非数字
- 1-3位数字
- 大于等于5位的数字
- 包含非数字
- 地区码
- 对于4个有效等价类
- 满足1,3,4
- 满足2,3,4
- 满足1,3,4
- 对于11个无效等价类,要有11个测试用例
等价类划分和边界值的区别和联系
- 实例:整型参数输入1-99为合法
- BVA
- 一般边界值
- 1,2,50,98,99
- 1,2,50,98,99
- 健壮性边界值
- 0,1,2,50,98,99,100
- 0,1,2,50,98,99,100
- 一般边界值
- EP
- 有效等价类
- 一位正整数
- 两位正整数
- 一位正整数
- 无效等价类
- 不在1-99范围内的整数
- 1-99范围内的浮点数
- 非数值型数据
- 不在1-99范围内的整数
- 有效等价类
- 两者的异同
- 等价类划分法
- 将测试过程中的输入、输出、操作等相似内容分组,从每组中挑选具有代表性的内容作为测试用例,划分有效等价类和无效等价类
- 将测试过程中的输入、输出、操作等相似内容分组,从每组中挑选具有代表性的内容作为测试用例,划分有效等价类和无效等价类
- 边界值分析法
- 确认输入、输出的边界,然后取刚好等于、大于、小于边界的参数作为测试用例测试
- 确认输入、输出的边界,然后取刚好等于、大于、小于边界的参数作为测试用例测试
- 联系
- 等价类划分和边界值要一起考虑,边界值分析法属于等价类划分法的补充,任何等价区间都有边界,有边界就有等价区间。
- 等价类划分和边界值要一起考虑,边界值分析法属于等价类划分法的补充,任何等价区间都有边界,有边界就有等价区间。
- 等价类划分法

- 有效等价类
- 身高
- 1.2m以下
- 1.2m-1.4m
- 1.4m以上
- 1.2m以下
- 年龄
- 18岁以下
- 18岁-59岁
- 60岁-69岁
- 70岁及以上
- 18岁以下
- 身份
- 在校学生(不含在校学生,电大学生)
- 在职学生
- 电大学生
- 革命烈士家属
- 现役军人
- 在校学生(不含在校学生,电大学生)
- 身高
- 无效等价类
- 身高
- 负数
- 非数值型
- 负数
- 年龄
- 负数
- 非数值型
- 负数
- 身份
- 非以上几类人
- 非以上几类人
- 身高
- 边界值分析

Session 9 Decision Table
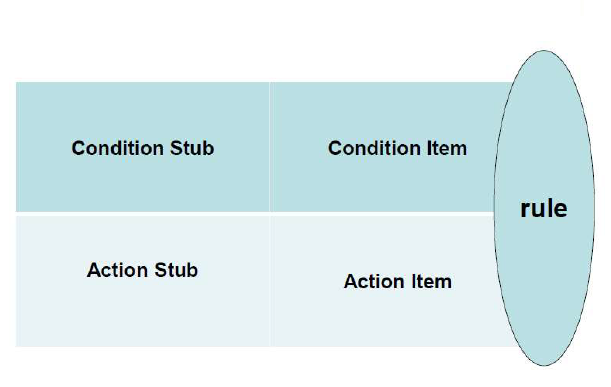
Extended Entry Decision Tables
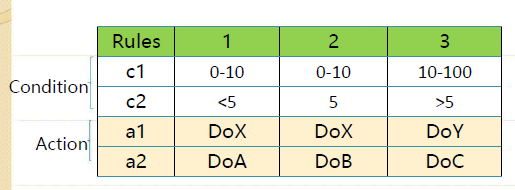

- 列出所有的条件和行为
- 填充条件
- 填充行为,建立初始表
- 验证 Verification
验证
- 完整性 Completeness
- 合并 Combination
- 冗余 Redundancy
-
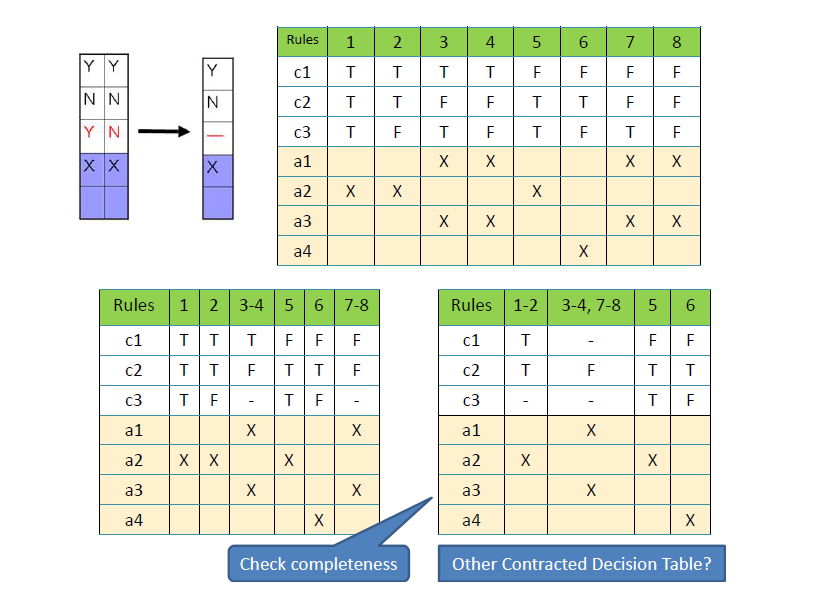
Completeness
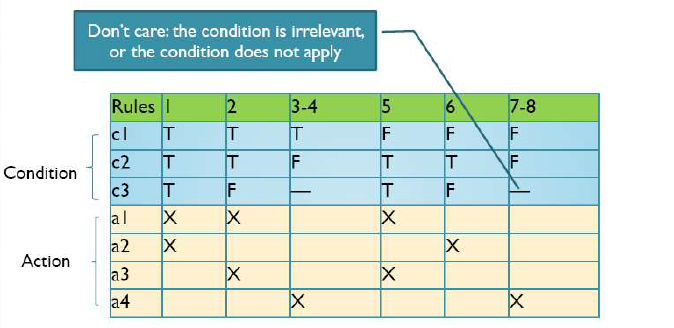
判定表里需要包含输入的所有组合
对于有限条目,如果是n个条件,那么应该有2n个规则
- 对于每个无关项
- 需要两个规则,即0和1
- 需要两个规则,即0和1
- 对于每个无关项
扩展条目
输入相似,输出相同
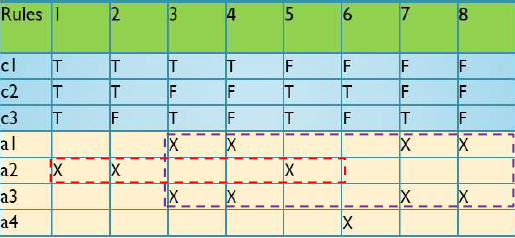
redundant
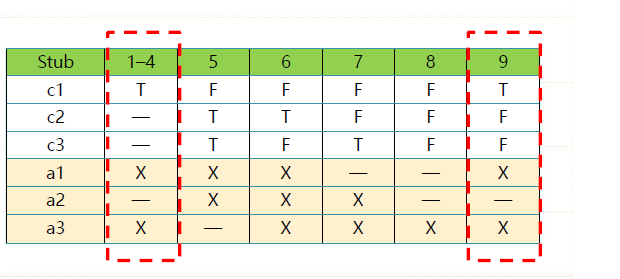
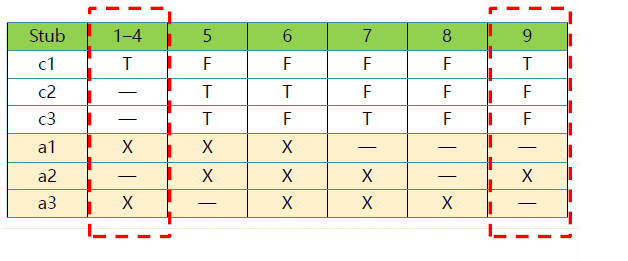
例子
- Triangle problem
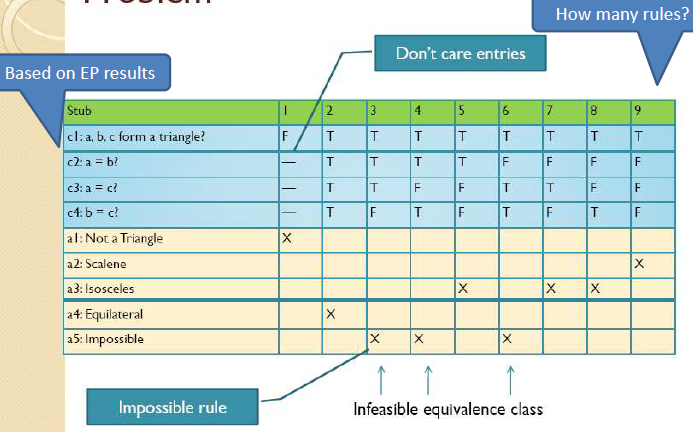
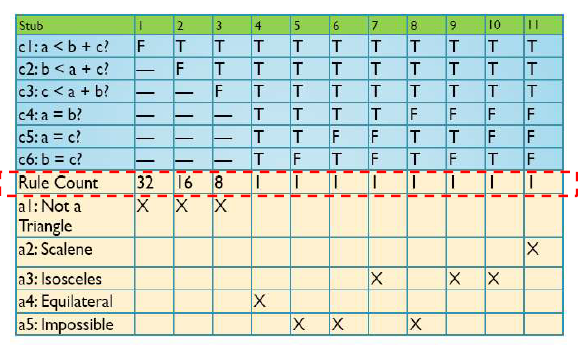
✨BVA VS EP VS DT
- 边界值分析
- 基于取值域,不识别数据或逻辑关系;
- 很容易自动化实现,设计工作量小;
- 生成的测试用例数比较多,测试用例执行时间长。
- 基于取值域,不识别数据或逻辑关系;
- 等价类划分
- 考虑数据依赖关系,标识等价类时需要更多的判断和技巧;
- 等价类标识出以后的处理也是机械的;
- 设计工作量和测试用例数属中等。
- 考虑数据依赖关系,标识等价类时需要更多的判断和技巧;
- 决策表
- 考虑数据的逻辑依赖关系;
- 所得测试用例可以是完备的,测试数量在一定意义上讲是最少的;
- 需要通过多次迭代,设计工作量很大。
- 考虑数据的逻辑依赖关系;
练习
- 某公司的对客户分类标准如下:
- 顾客每次订货额在1000元以上(含1000元)
- 信誉好的,订单设“优先”标志;
- 信誉不好,但是老客户的,订单设“优先”标志;
- 信誉不好,但是新客户的,订单设“正常”标志;
- 信誉好的,订单设“优先”标志;
- 每次订货额在1000元以下,订单设“正常”标志。
- 顾客每次订货额在1000元以上(含1000元)
请绘制相应的决策表。
| Stub | 1 | 2 | 3 | 4 | | —- | —- | —- | —- | —- | | c1:订货额是否在1000元以上 | T | T | T | F | | c2:信誉是否好 | T | F | F | — | | c3:是否是老客户 | — | T | F | — | | a1:订单设优先标志 | X | X | | | | a2:订单设正常标志 | | | X | X |NextDate problem
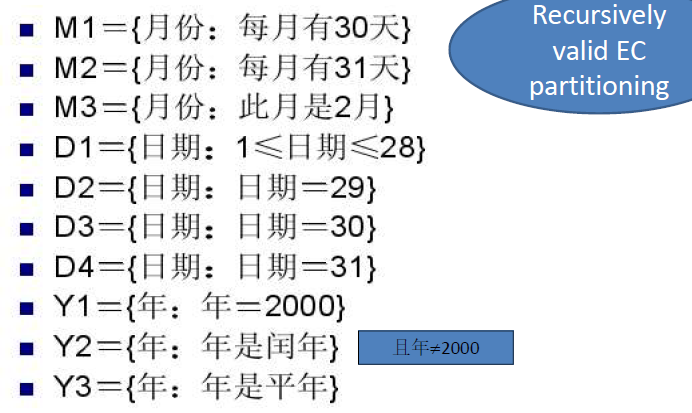
- 输入等价类划分
- M1 = { month: month has 30 days}
- M2 = { month: month has 31 days}
- M3 = { month: month is February}
- D1 = {day: 1<= day <= 28}
- D2={day: day=29}
- D3={day: day=30}
- D4={day: day=31}
- Y1={year: leap year}
- Y2={year: not leap year}
- M1 = { month: month has 30 days}
- 输出等价类划分
- A1: impossible day
- A2: incremented day value
- A3: date reset
- A4: incremented month value
- A5: month reset
- A6: incremented year value
- A1: impossible day
- Limited Entry Decision Table

- 扩展条目+考虑了2000年
- 等价类划分
- M1={Month: 30 days}
- M2={Month: 31 days}
- M3={Month: February}
- D1={Date: 1<=Date<=28}
- D2={Date: Date=29}
- D3={Date: Date=30}
- D4={Date: Date=31}
- Y1={Year: year=2000}
- Y2={Year: is leap year and !=2000}
- Y3={Year: is not leap year}
- M1={Month: 30 days}
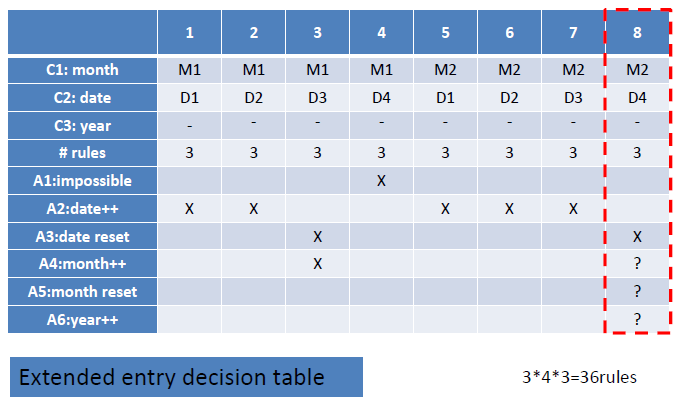
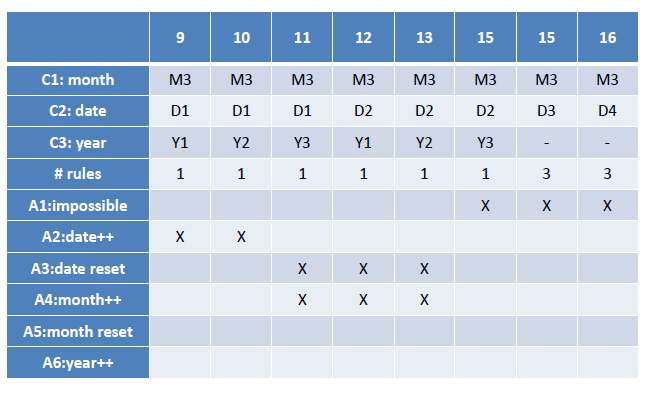
- 等价类划分(月 日 年)
- M1={Month: 30 days}
- M2={Month: 31 days, except Deceber}
- M3={Month: December}
- M3={Month: Feburary}
- D1={Date: 1<=Date<=28}
- D2={Date: Date=29}
- D3={Date: Date=30}
- D4={Date: Date=31}
- Y1={Year: year=2000}
- Y2={Year: is leap year and !=2000}
- Y3={Year: is not leap year}
| Stub | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | | —- | —- | —- | —- | —- | —- | —- | —- | —- | —- | —- | | C1: month | M1 | M1 | M1 | M1 | M1 | M2 | M2 | M2 | M2 | M2 | | C2: date | D1 | D2 | D3 | D4 | D5 | D1 | D2 | D3 | D4 | D5 | | C3: year | — | — | — | — | — | — | — | — | — | — | | rules_count | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | | A1: impossible | | | | | ✔ | | | | | | | A2: date++ | ✔ | ✔ | ✔ | | | ✔ | ✔ | ✔ | ✔ | | | A3: date reset | | | | ✔ | | | | | | ✔ | | A4: month++ | | | | ✔ | | | | | | ✔ | | A5: month reset | | | | | | | | | | | | A6: year++ | | | | | | | | | | |
- M1={Month: 30 days}
| Stub | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C1: month | M3 | M3 | M3 | M3 | M3 | M4 | M4 | M4 | M4 | M4 | M4 | M4 |
| C2: date | D1 | D2 | D3 | D4 | D5 | D1 | D2 | D2 | D3 | D3 | D4 | D5 |
| C3: year | — | — | — | — | — | — | Y1 | Y2 | Y1 | Y2 | — | — |
| rules_count | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 2 | 2 |
| A1: impossible | ✔ | ✔ | ✔ | |||||||||
| A2: date++ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||||||
| A3: date reset | ✔ | ✔ | ✔ | |||||||||
| A4: month++ | ✔ | ✔ | ||||||||||
| A5: month reset | ✔ | |||||||||||
| A6: year++ | ✔ |
- 等价类划分(日 月 年)
- D1={Date: 1<=Date<=28}
- D2={Date: Date=29}
- D3={Date: Date=30}
- D4={Date: Date=31}
- M1={Month: 30 days}
- M2={Month: 31 days, except Deceber}
- M3={Month: December}
- M3={Month: Feburary}
- Y1={Year: year=2000}
- Y2={Year: is leap year and !=2000}
- Y3={Year: is not leap year}
| Stub | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | | —- | —- | —- | —- | —- | —- | —- | —- | —- | —- | —- | | C1: date | D1 | D2 | D2 | D2 | D3 | D3 | D3 | D4 | D4 | D4 | | C2: month | — | M1,M2,M3 | M4 | M4 | M1,M2,M3 | M4 | M4 | M1 | M2,M3 | M4 | | C3: year | — | — | Y1 | Y2 | — | Y1 | Y2 | — | — | — | | rules_count | 8 | 6 | 1 | 1 | 6 | 1 | 1 | 2 | 4 | 2 | | A1: impossible | | | | | | | ✔ | | | ✔ | | A2: date++ | ✔ | ✔ | ✔ | | ✔ | | | | ✔ | | | A3: date reset | | | | ✔ | | ✔ | | ✔ | | | | A4: month++ | | | | | | | | ✔ | | | | A5: month reset | | | | | | | | | | | | A6: year++ | | | | | | | | | | |
- D1={Date: 1<=Date<=28}
| Stub | 11 | 12 | 13 |
|---|---|---|---|
| C1: date | D5 | D5 | D5 |
| C2: month | M1,M4 | M2 | M3 |
| C3: year | — | — | — |
| rules_count | 4 | 2 | 2 |
| A1: impossible | ✔ | ||
| A2: date++ | |||
| A3: date reset | ✔ | ✔ | |
| A4: month++ | ✔ | ||
| A5: month reset | ✔ | ||
| A6: year++ | ✔ |
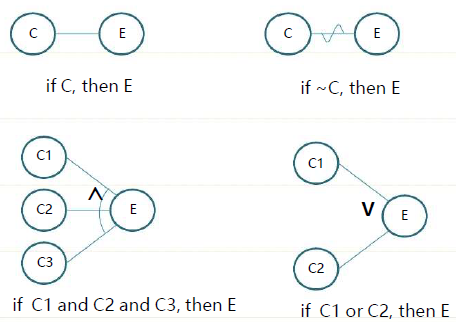
Session 10 Cause-Effect Graph
- 因果图,类似于判定表
- 更重视对需求规格说明的解读
- 根据需求去确定测试案例的最小数
- 针对程序中可以表达为布尔表达式的输入输出之间的逻辑关系进行建模
结点
原因结点 Cause
- 影响输出的条件
side>0, side1!=side2, month=feb
- 影响输出的条件
结果结点 Effect
- 在特定输入条件下的输出
error message displayed on the screen a new window is displayed database is updated
- 在特定输入条件下的输出
流程
- 确定 原因 和 结果
- 建立原因和结果之间的联系
- 标注原因和结果的不可能的组合(增加约束)
- 根据图画出判定表
-
标记
约束
Exclusive:不能同时为真
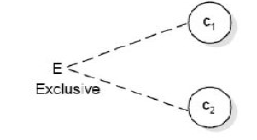
- Inclusive:至少有一个为真
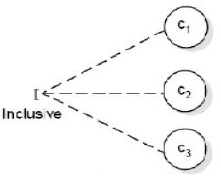
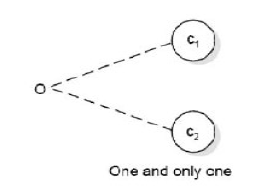
- One and only one:只能有一个为真
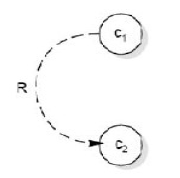
- Requirement:c1为真时,c2也要为真
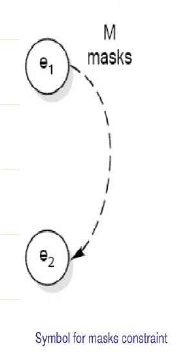
- Mask:e1为真时,e2必须为假
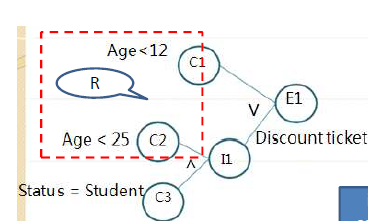
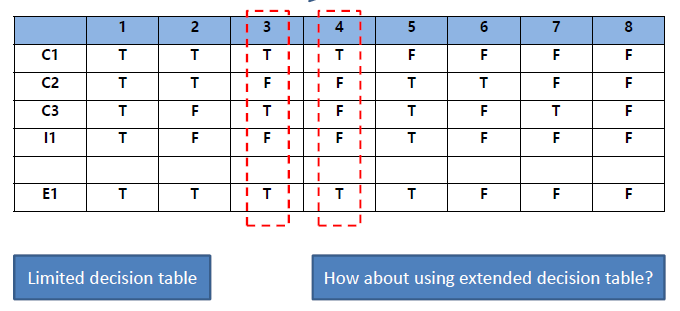
例一
- 乘客中年龄小于12岁的人和小于25岁的学生可以得到优惠票
- C1:age<15
- C2:age<25
- C3:status = student
- I1:He/She is a student below 25
- E1:Passanger can get a discount ticket
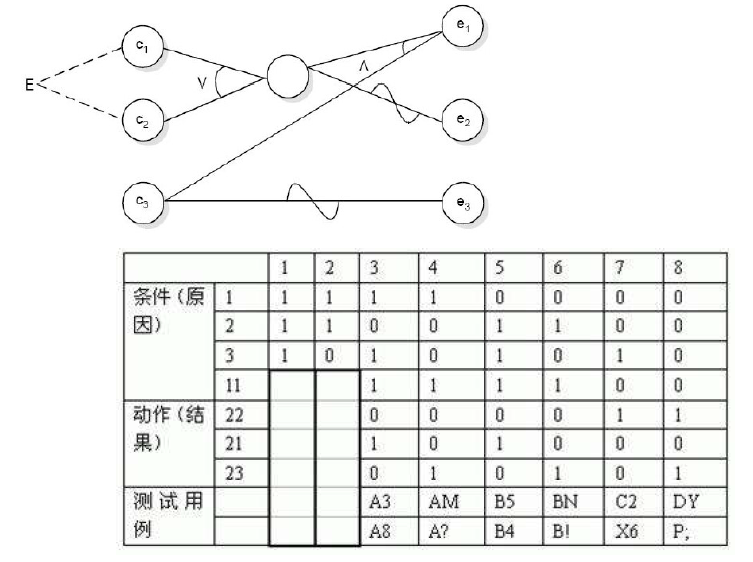
例二
- 第一列字符必须是A或者B
- 第二列字符必须是一个数字
- 两列字符合法则成功更新文件
- 如果第一列字符错误,就输出 message x
- 如果第二列字符不是数字,就输出 message y
- C1:第一列字符为A
- C2:第二列字符为B
- C3:第二列字符是数字
- E1:成功更新文件
- E2:输出message x
- E3:输出message y
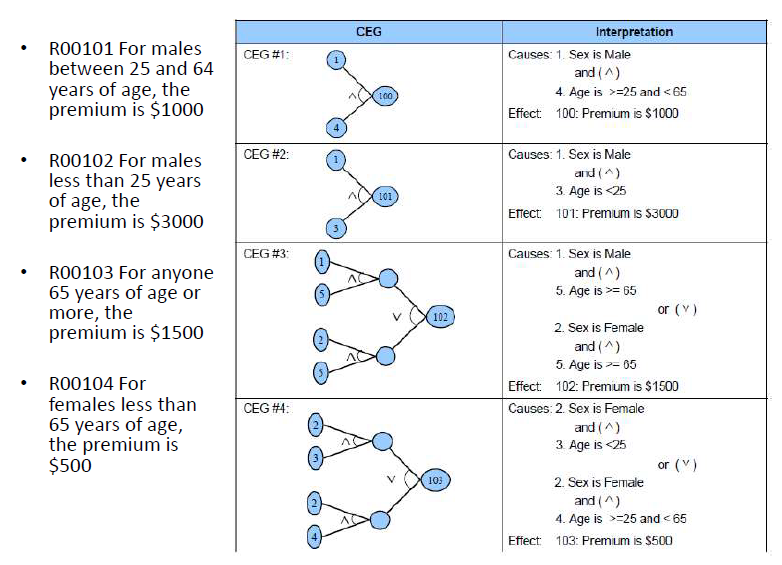
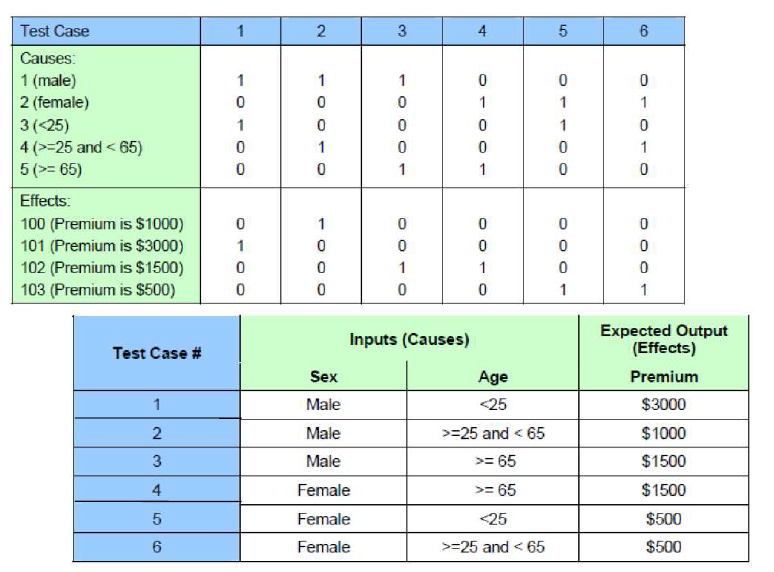
例三
- causes
- 男性
- 女性
- 年龄<25
- 年龄>=25且年龄<65
- 年龄>=65
- 男性
- effects
- 保险费1000元
- 保险费3000元
- 保险费1500元
- 保险费500元
- 保险费1000元
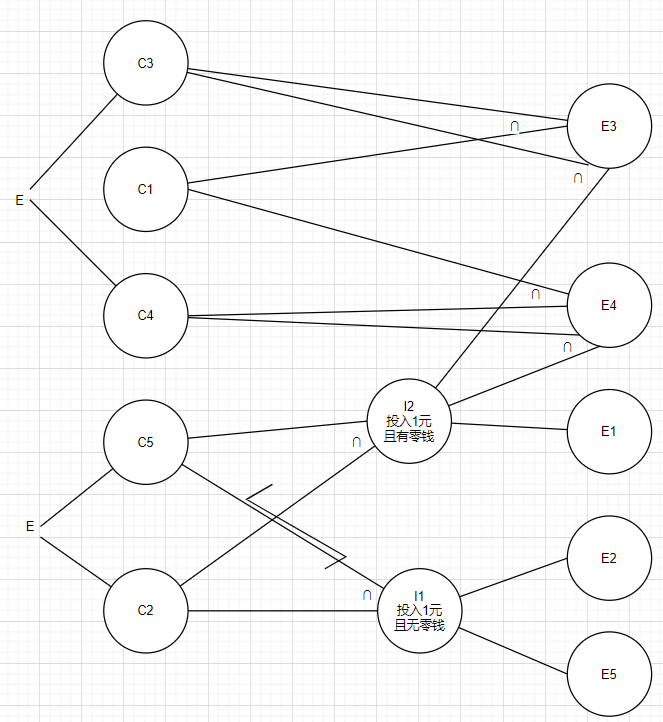
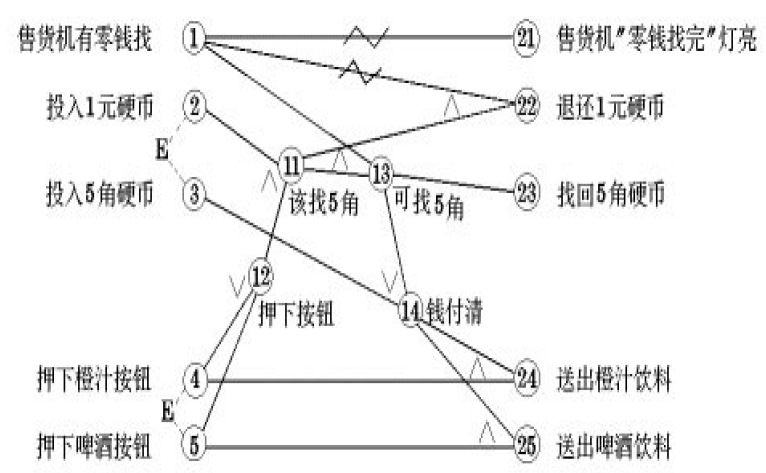
例四
- 自动售货机
- 投入5毛或1元,按下橙汁或啤酒,送出相应饮料
- 若售货机没有零钱找
- 就显示“零钱找完”的红灯亮
- 这时投入1元硬币并按下按钮后,饮料不送出且1元硬币也退出来
- 就显示“零钱找完”的红灯亮
- 若有零钱找
- 就显示“零钱找完”灭
- 在送出饮料的同时退还5毛
- 就显示“零钱找完”灭
- 投入5毛或1元,按下橙汁或啤酒,送出相应饮料
- 条件
- C1:投入5毛
- C2:投入1元
- C3:按下橙汁
- C4:按下啤酒
- C5:有无零钱
- C1:投入5毛
- 结果
- E1:找5毛
- E2:退1元
- E3:送出橙汁
- E4:送出啤酒
- E5:红灯亮
- E1:找5毛
参考答案

Exercise2
有一个处理单价为1元5角钱的盒装饮料的自动售货机。若投入1元5角硬币,按下“可乐”、“雪碧”或“红茶”按钮,相应的饮料就送出来。若投入的是2元硬币,在送出饮料的同时退还5角硬币。
- 原因
- C1:投入1元5角
- C2:投入2元
- C3:按下可乐
- C4:按下雪碧
- C5:按下红茶
- C1:投入1元5角
- 结果
- E1:送出可乐
- E2:送出雪碧
- E3:送出红茶
- E4:退还5角硬币
- E1:送出可乐
- 中间状态
- I1:钱付清
- I2:按下按钮
- I1:钱付清
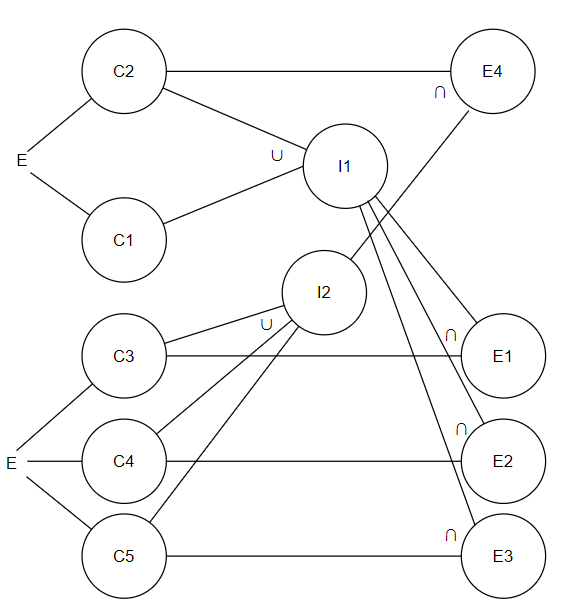
- 参考判定表
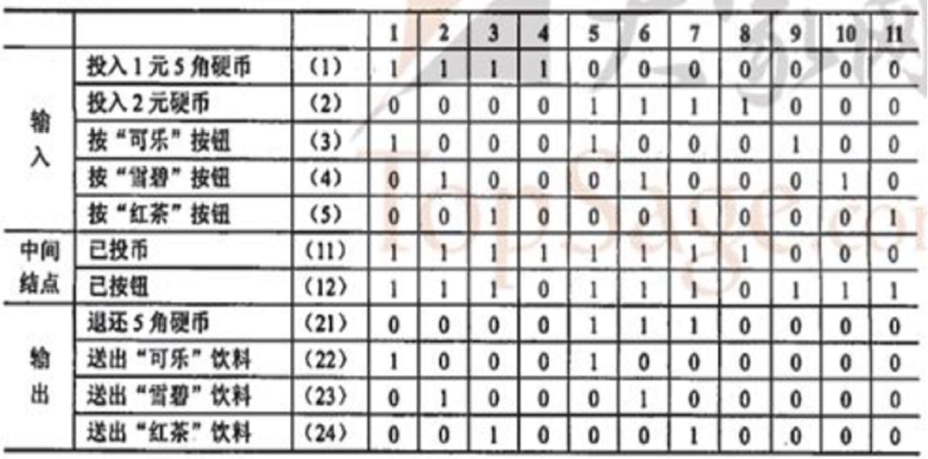
某年期末考试题
| Stub | 1 | 2 | 2 | 3 | 4 | 6 |
|---|---|---|---|---|---|---|
| C1: class | economy | economy | — | economy | business | business |
| C2: airline | domestic | domestic | EU and USA | other international | domestic | other international |
| C3: flying time | > 2 hours | <= 2hours | — | — | — | — |
| count | 1 | 1 | 4 | 2 | 2 | 2 |
| A1: meals | ✔ | ✔ | ✔ | ✔ | ✔ | |
| A2: entertainments | ✔ | ✔ |
Session 11 Combinatorial Test
- Movitation
- 因素间的复杂关系
- 输入输出测试
- 配置测试
- 兼容性测试
- 输入输出测试
- 在实际的软件项目中,输入条件多,每个条件有多个取值,组合爆炸问题
- 因素间的复杂关系
如何解决组合爆炸的问题?
组合测试:抽样,优化组合
从大量数据中挑选适量的有代表性的点,从而合理地安排实验的一种科学实验设计方法
- 设计步骤
- 确定影响因素
- 确定每个因素的水平
- 选择正交表
- 根据确定的因素和水平,选择合适的正交表
- 如果没有合适的正交表可用或需要的测试用例个数太多,则要对因素和水平进行调整
- 根据确定的因素和水平,选择合适的正交表
- 设计测试用例
- 确定影响因素
正交表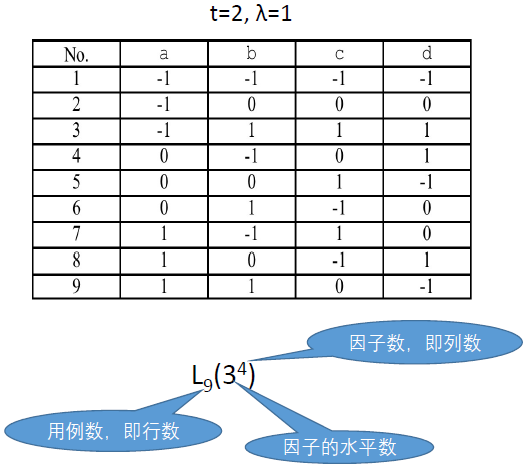
- 正交表是什么
- 任意t个输入变量间
- 每个t元输入取值组合排列方式齐全而且均衡(出现次数λ相等)
- 任意t个输入变量间
- 优势
- 对组合的覆盖
- 空间分布均匀
- 对组合的覆盖
- 劣势
- 正交表构造困难
- 难以判定存在性
- 正交表构造困难
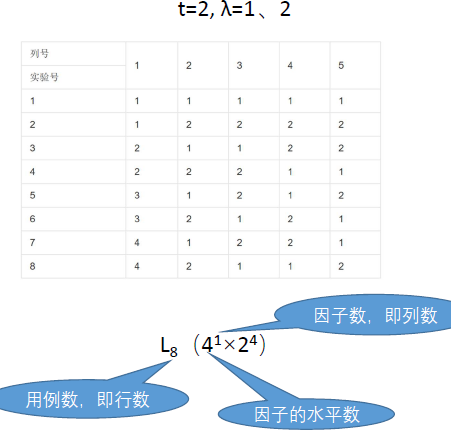
组合覆盖表
- 组合覆盖表是什么
- 任意t个输入变量间
- 每个t元输入取值组合出现至少一次
- 任意t个输入变量间
- 优势
- 对组合的覆盖
- 覆盖表必然存在
- 覆盖表便于构造
- 对组合的覆盖
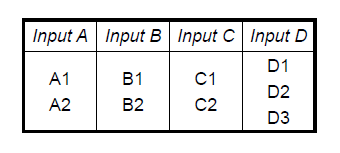
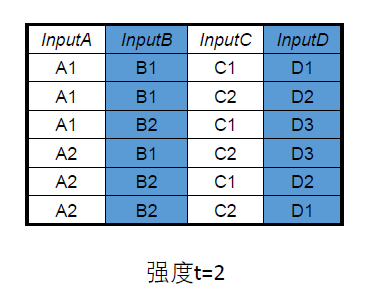
- 两因素组合测试(配对测试、全对偶测试) Pair-wise
- 测试集可以覆盖任意两个变量的所有取值组合
- 理论上可以暴露所有由两个变量共同作用而引发的缺陷
- 测试集可以覆盖任意两个变量的所有取值组合
- 多因素(t-way,t>2)
- 测试集可以覆盖任意t个变量的所有取值组合
- 理论上可以发现所有t个因素共同作用引发的缺陷
- 测试集可以覆盖任意t个变量的所有取值组合
基于选择的覆盖
两因素组合测试,将所有因素的水平按照两两组合的原则而产生
- 基于两个假设
- 每一个维度都是正交的,即每一个维度互相都没有交集
- 根据数学统计分析,73%的缺陷是由单因子或双因子相互作用产生的,19%的缺陷是由3个因子相互作用产生的
- 每一个维度都是正交的,即每一个维度互相都没有交集
- 示例

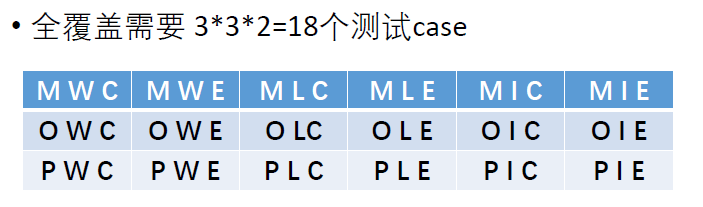
- 从尾部开始删
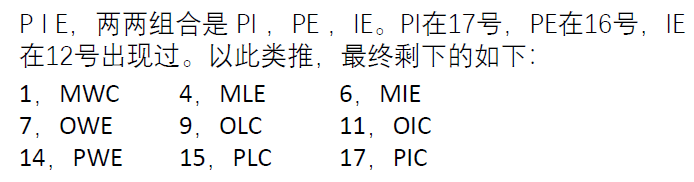
从头开始删
例如MWC,我们发现出现MWE覆盖了MW,OWC覆盖了WC,MLC覆盖了M*C,所以可以删掉MWC
最终剩余
基于选择的覆盖
- 选出一个基础的组合,且基础组合中包含每个参数的基础值
- 基于基础组合,每次只改变一个参数值,来生成新的组合用例
- 选出一个基础的组合,且基础组合中包含每个参数的基础值
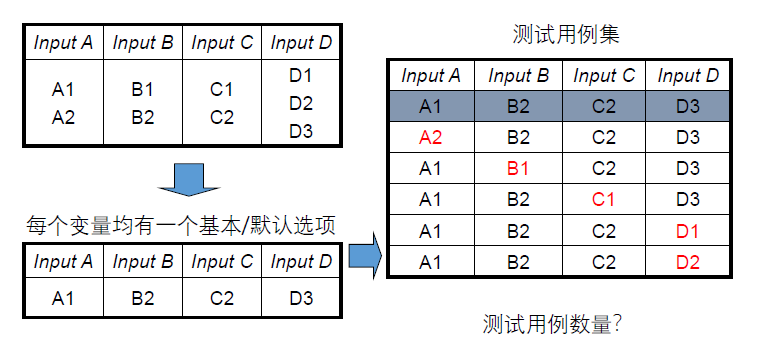
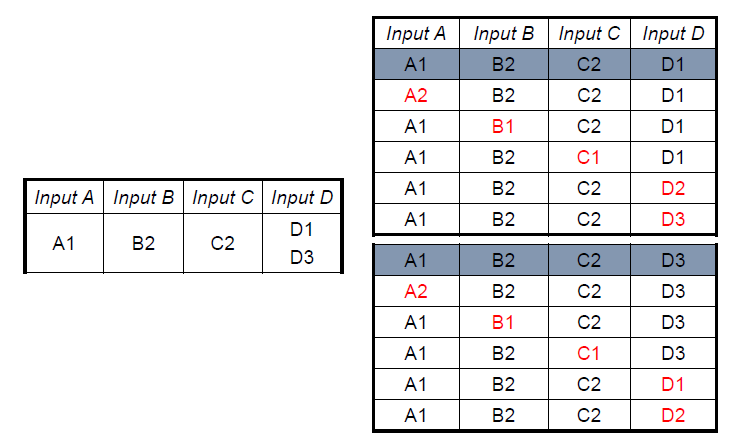
- 如果一个变量有多个默认取值
约束问题
- 强制约束
- 取值组合为非法
- 取值组合为非法
- 非强制约束
- 取值组合无需覆盖
- 取值组合无需覆盖
Boolean fun(Boolean a, Boolean b, Boolean c, Boolean d){
if(a&& !b){
return false; // 强制约束 a=true, b=false
}
return (a&&c||b&&d);
}
Boolean fun(Boolean a, Boolean b, Boolean c, Boolean d){
a = true;
b = false; // 非强制约束a=true, b=false
return (a&&c||b&&d);
}
- 如何处理非强制约束问题
- 直接忽略
- 算法预处理
- 直接忽略
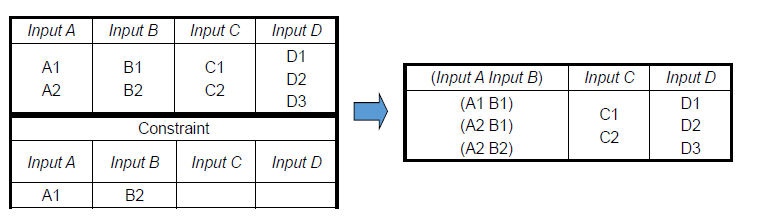
- 如何处理强制约束问题
- 合并输入变量
- 合并输入变量
- 重构输入区域
- 重构输入区域
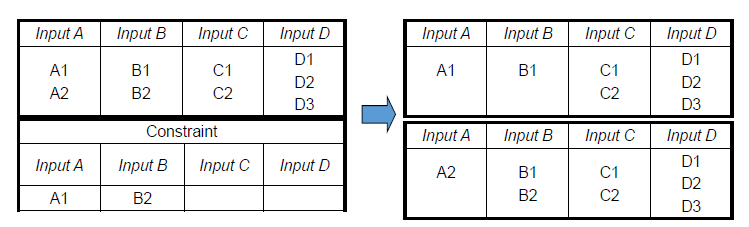
- 修改测试用例
- 修改测试用例
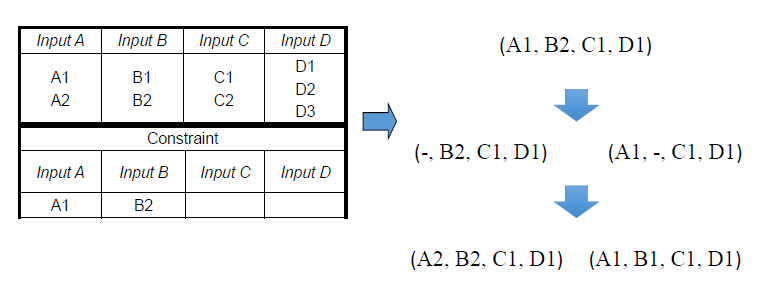
- Pairwise vs 单因素
- pairwise能够覆盖到两个维度的组合,能适当减少遗漏的测试
- pairwise能够覆盖到两个维度的组合,能适当减少遗漏的测试
- Pairwise vs 全覆盖设计法 vs 正交表法
- 全覆盖设计法测试用例太多,成本高
- 正交表法是对组合的等概率覆盖,构造困难
- pairwise较之全覆盖设计法,减少了测试用例,较之正交表法,构造相对简单,提高了测试效率
- 全覆盖设计法测试用例太多,成本高

若有收获,就点个赞吧
0 人点赞
