Session 12 UISA
- 大部分的开发团队都采取增量的测试
- Unit testing
- verification of isolated software units
- verification of isolated software units
- Integration testing
- verification of the interaction among software units
- verification of the interaction among software units
- System testing
- verification of the behavior of a whole system
- verification of the behavior of a whole system
- Unit testing
-
Unit testing
Why we need Unit testing
1000行代码中有2-6个错误
- 测试和维护的开销占到了整体开销的30%-60%
-
What is Unit testing
应用的最小的可以测试部分(units),被单独地检查是否符合正确操作
a unit
发现在编码过程中产生的错误
- 检验代码是否和设计一致
- 回溯需求和设计的实现
- 发现设计和需求的错误
单元测试的目标和任务
静态测试 static testing
- 主要是检查代码和文档中的句法错误
- 可以由开发人员来完成
- peer reviews 同行评审
- walkthroughs 走查
- inspections 审查
- 主要是检查代码和文档中的句法错误
动态测试 dynamic testing
一次检查200-400行代码
- 努力达到一个合适的检查速度,一小时300-500行
- 有足够的时间,适当的速度,仔细地检查,不超过60-90分钟
- 复审前,代码作者应该对代码进行注释
- 使用检查表 checklist 能改进双方的结果
-
Walkthroughs 走查
定义
- 采用讲解、讨论和模拟运行的方式进行的查找错误的活动
- 采用讲解、讨论和模拟运行的方式进行的查找错误的活动
注意点
以会议形式,制定目标、流程和规则
- 按缺陷检查表逐项检查
- 发现问题适当记录,避免现场修改
- 发现重大缺陷,改正后会议需要重开
走查 vs 审查
单元测试检查表 示例
关键测试项是否已纠正
- 有无任何输入参数没有使用?有无任何输出参数没有产生?
- 有无任何数据类型不正确或不一致?
- 有无任何算法与PDL或功能需求中的描述不一致?
- 有无任何局部变量使用前没有初始化?
- 有无任何外部接口编码错误?即调用语句、文件存取、数据库错误。
- 有无任何逻辑路径错误?
- 该单元是否有多个入口或多个正常的出口?
额外测试项
- 该单元中有任何地方与PDL与PROLOG中的描述不一致?
- 代码中有无任何偏离本项目标准的地方?
- 代码中有无任何对于用户来说不清楚的错误提示信息?
- 如果该单元是设计为可重用的,代码中是有可能妨碍重用的地方?
Unit testing enviroment
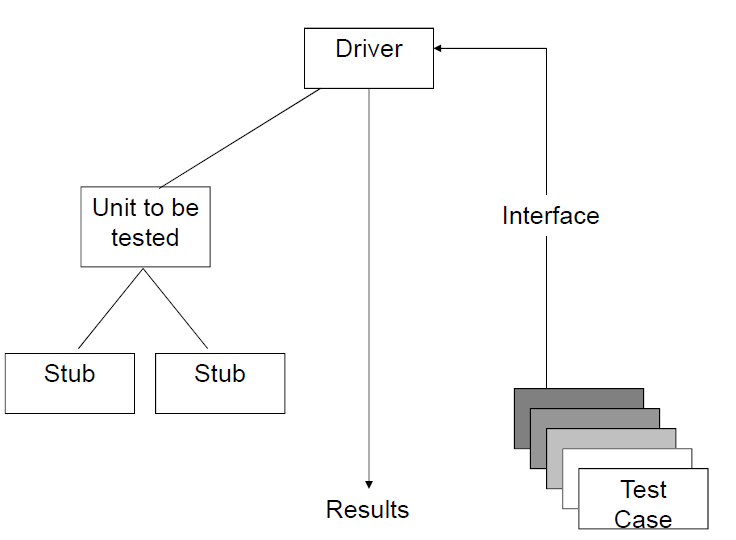
Unit testing strategies
- 驱动 Driver
- 用来调用测试模组的外层模组 superior module
- 用来调用测试模组的外层模组 superior module
- 桩 Stub
- 用来调用测试模组中的调用模组 calling modules
- 用来调用测试模组中的调用模组 calling modules

- 前置条件和后置条件
- 前置条件示例
Contract.Requires( x!=null );
- 后置条件实例
Contract.EnsuresOnThrow<T>( this.F > 0 );Contract.Result<T>();
- 前置条件示例
单元测试工具
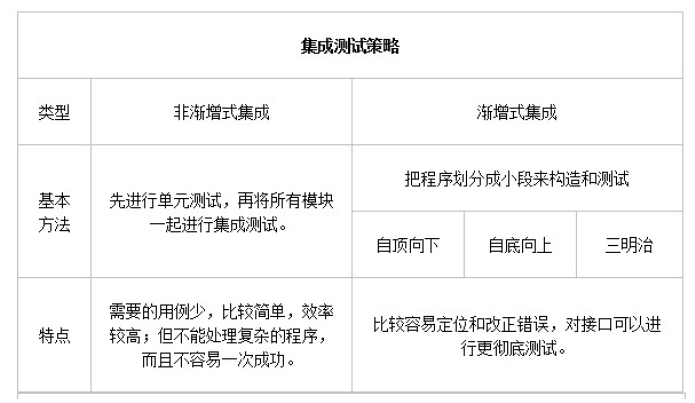
集成测试
基于分解的集成—更关注结点
- Big bang(大爆炸) integration
- Top-down (自顶向下)integration
- Bottom-up (自底向上)integration
- Sandwich(三明治) integration
- Big bang(大爆炸) integration
- 基于调用图的集成—更关注边
- 成对集成
- 相邻集成
- 成对集成
- 其他集成策略
- 核心系统先行集成
- 高频集成
- 核心系统先行集成
如何组合系统内的模块
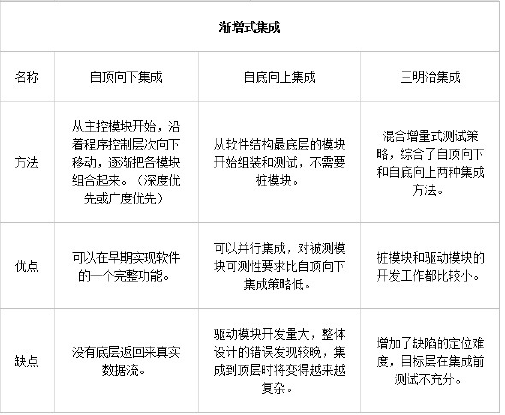
Big bang integration 大爆炸
- Top-down integration 自顶向下
- Bottom-up integration 自底向上
-
Big ban integration 大爆炸式集成
属于一种非增量式的集成方法,它一次性集成了系统的所有组件,不考虑组件的独立性和可能的风险
- 在单元测试阶段,先对每一个子模块进行测试
- 然后将所有模块一次性的全部集成起来进行集成测试
- 优点
- 可以很快完成且只需要很少的桩模块(stubs)和驱动模块(drivers)
- 许多测试人员平行工作,并且人力资源和物料资源利用率高
- 可以很快完成且只需要很少的桩模块(stubs)和驱动模块(drivers)
- 缺点
- 如果出现了错误,定位和纠错(localization and debug)更加困难
- 直到系统测试(system testing)才能发现接口的错误(interface errors)
- 如果出现了错误,定位和纠错(localization and debug)更加困难
适用范围
流程
- 先关注最高级的组件,然后逐渐测试底部的组件
- 使用DFS和BFS策略
- 采取回归测试的方法,去排除集成可能引起的错误
- 所有模块都能被集成到系统时结束测试,否则回到2
- 先关注最高级的组件,然后逐渐测试底部的组件
- dfs策略
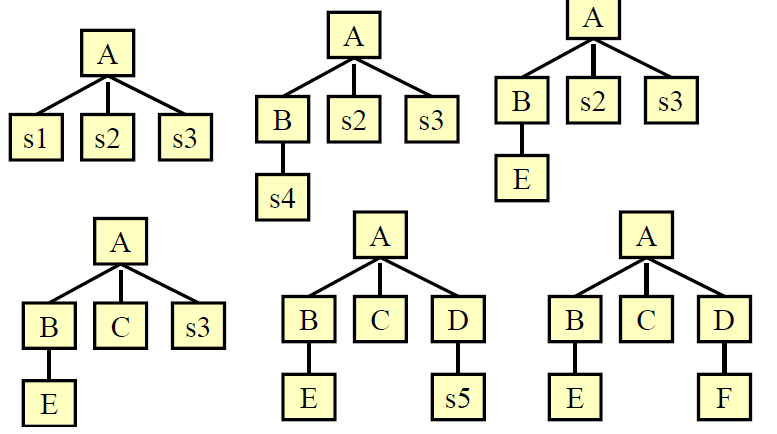
-
Bottom-up integration 自底向上式集成
从底部的小的独立的组件开始,根据依存结构(dependency structure),逐层向上集成,来检测整个系统
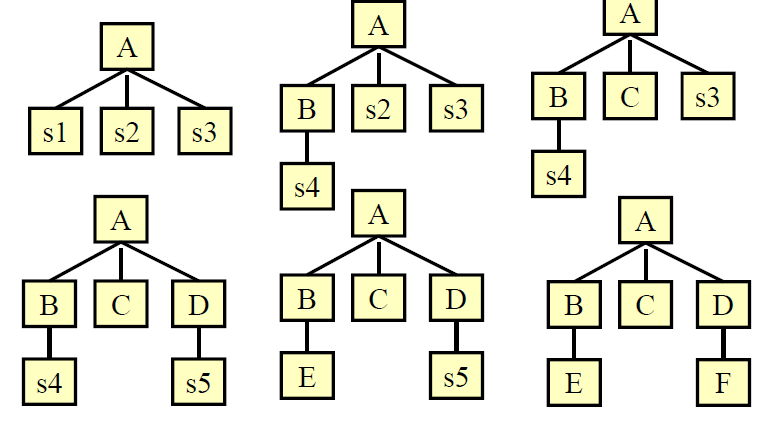

Sandwich integration 三明治式集成
- 结合自顶向下和自底向上策略的优点
- 在真正集成之前每一个独立的模块没有完全测试过
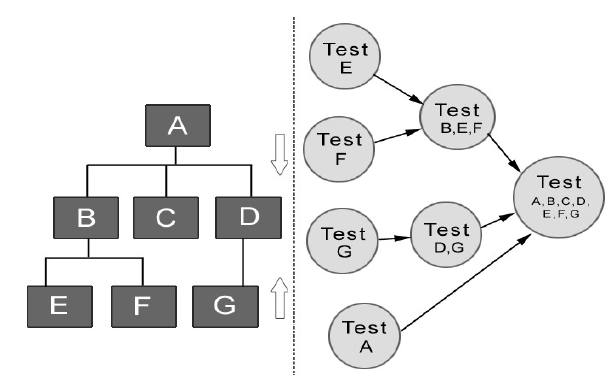
- 保证每个模块得到单独的测试,使测试进行得比较彻底
- 集成测试总结
- 基于分解的集成
- 更关注结点
- 更关注结点
基于调用图的集成
成对集成
- 免除桩/驱动模块的开发工作,使用实际代码
- 为避免大爆炸式集成,限制在调用图的一对单元上
- 对调用图中的每条边有一个集成测试过程
- 免除桩/驱动模块的开发工作,使用实际代码
- 相邻集成
- 利用拓扑学中的邻接的概念
- 在有向图中,结点邻居包括所有所有直接前驱节点和所有直接后继节点
- 对应结点的桩核驱动模块集合
- 利用拓扑学中的邻接的概念
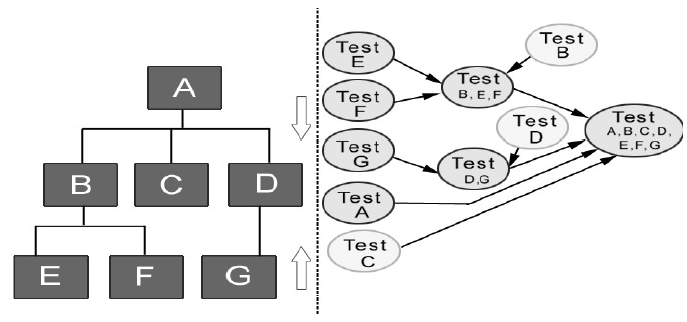
- 成对集成示例
- 40次集成测试会话
- 40次集成测试会话
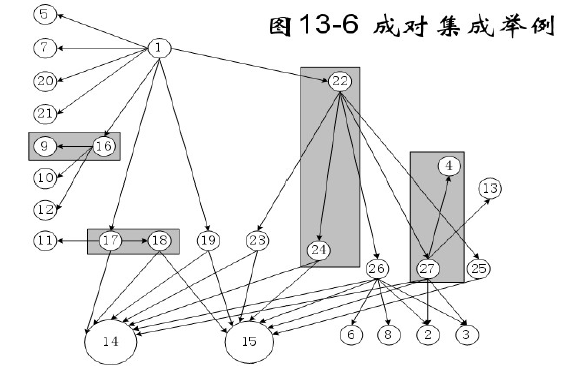
- 相邻集成示例
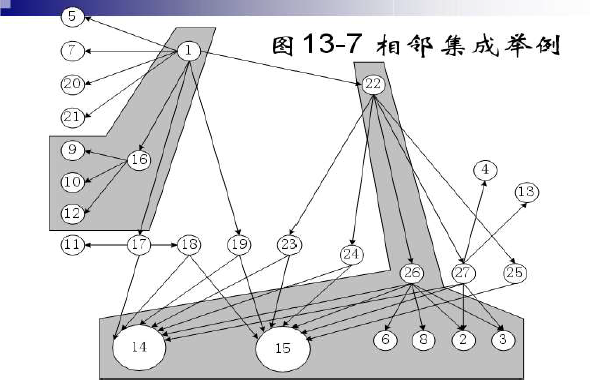
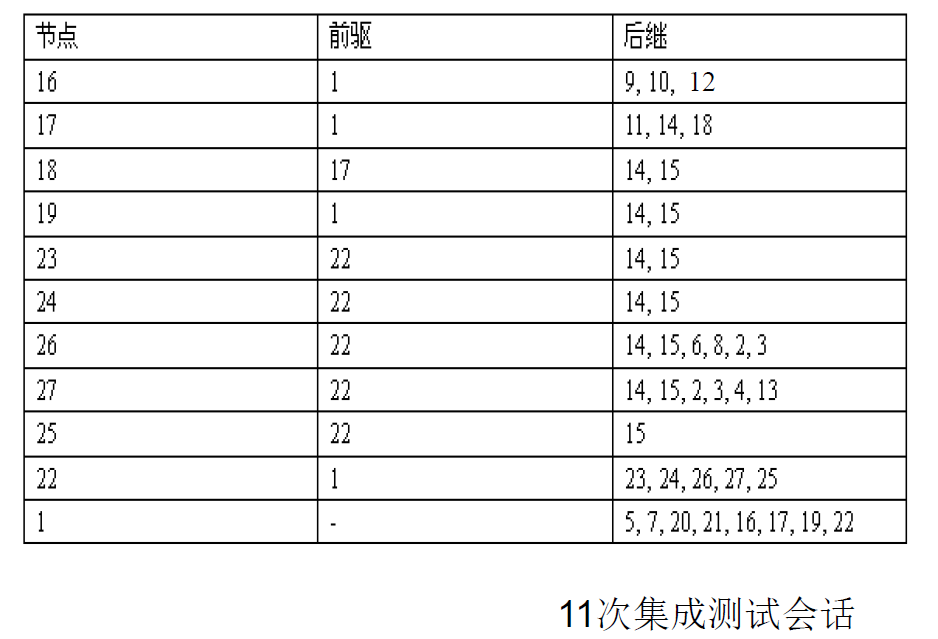
- 例题
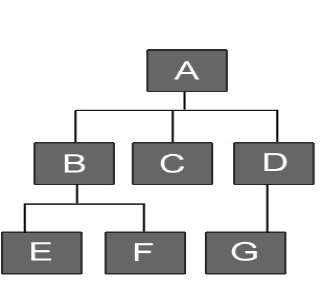
- 成对集成
- A-B
- A-C
- A-D
- B-E
- B-F
- D-G
- A-B
- 相邻集成
- A-B-E,F
- A-C
- A-D-G
- A-B-E,F
调用图的集成测试
基于功能优先级的集成
- 依据功能的优先级,逐一将某个功能上的各个模块集成起来
- 核心系统先行集成测试
- 依据功能的优先级,逐一将某个功能上的各个模块集成起来
基于进度的集成
- 将最早获得的模块进行集成,以最大程度保持与开发的并行性
- 高频集成
- 高频集成测试是指同步于软件开发过程,每隔一段时间对开发团队的现有代码进行一次集成测试。
- 该集成测试方法频繁地将新代码加入到一个已经稳定的基线中,以免集成故障难以发现,同时控制可能出现的基线偏差。
- 使用高频集成测试的条件
- 可以持续获得一个稳定的增量,并且该增量内部已被验证没有问题;
- 大部分有意义的功能增加可以在一个相对稳定的时间间隔(如每个工作日)内获得;
- 测试包和代码的开发工作必须是并行进行的,并且需要版本控制工具来保证始终维护的是测试脚本和代码的最新版本;
- 必须借助于使用自动化工具来完成。
- 可以持续获得一个稳定的增量,并且该增量内部已被验证没有问题;
- 优点
- 能在开发过程中及时发现代码错误,能直观地看到开发团队的有效工程进度
- 能在开发过程中及时发现代码错误,能直观地看到开发团队的有效工程进度
- 缺点
- 高频集成测试是指同步于软件开发过程,每隔一段时间对开发团队的现有代码进行一次集成测试。
- 将最早获得的模块进行集成,以最大程度保持与开发的并行性
关键模块(key modules)必须被充分测试
- 20%-80%
- 20%-80%
- 所有的接口(all interfaces)必须被测试
- 当一个接口被改变的时候,所有相关接口必须用回归测试再测试一遍
- 集成测试是为了计划(plan)和避免随机测试(random testing)而被采用的
集成测试的策略需要集成质量,造价和进步之间的关系
有些内容只能在系统级别被验证
- 可以引入一些用户来测试
-
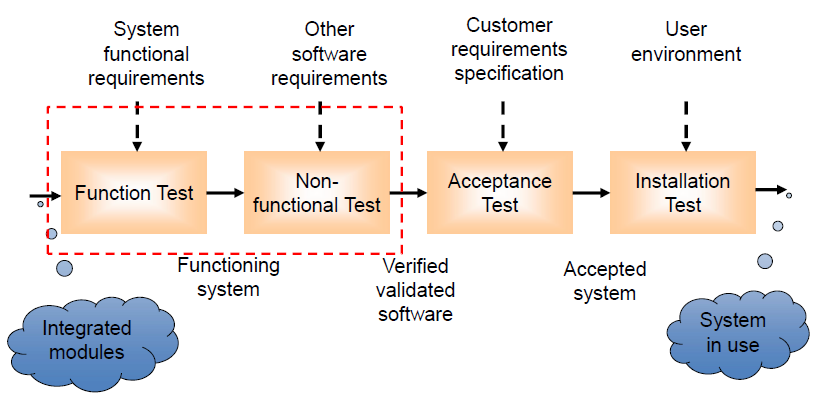
What is System testing?
系统测试是测试全面集成的系统来验证它是否满足特定需求(specified requirements)
系统测试也决定了系统是否能和商业流程(business procedures)以及环境(environment)所集成
System Testing process
System Tesitng methods
performance testing
- load testing
- volume testing
-
Acceptance testing
验收测试;交付测试
- 是一种正式的测试,决定了软件是否符合在SDLC(软件开发周期 software development lifecycle)阶段顾客(customer)所规定的验收准则(acceptance criteria)
- 最终用户(end user)或者顾客(customer)可以去进行验收测试,来验证是否接受产品
- 两类验收测试
- Alpha testing
- Alpha testing 是在靠近开发团队的内部站点(in-house site)上进行的模拟(simulated)或实际操作测试
- 帮助评价软件,来确定它是否满足需求分析阶段明确的所有需求
- Alpha testing 是在靠近开发团队的内部站点(in-house site)上进行的模拟(simulated)或实际操作测试
- Beta testing
- 在一个远离开发人员或者顾客地点,包括了所有操作的测试
- 在一个远离开发人员或者顾客地点,包括了所有操作的测试
- Alpha testing
- α测试
- 早期的、不稳定的软件版本所进行的验收测试,受控的实验室测试
- 早期的、不稳定的软件版本所进行的验收测试,受控的实验室测试
- β测试
- 晚期的、更加稳定的软件版本所进行的验收测试,不受控的非实验室测试
- 局限性
- 通常不是专业测试人员,问题往往停留在可用性上
- 环境不可控,使用不当引起的问题居多
- 为了评价软件或者获得软件而参与测试
- 反馈信息简单,经常无法重视
- 通常不是专业测试人员,问题往往停留在可用性上
- 众包测试/群体智能的兴起
- 晚期的、更加稳定的软件版本所进行的验收测试,不受控的非实验室测试
测试步骤 Testing life cycle
level
- action
- actor
-
Session 13 RT
Regression Testing
-
Why?
修复了一个bug,可能会有新的bug
-
What?
只要是软件发生变更,就需要进行回归测试,避免变更对软件已有的功能产生负面影响(adversely affect)
有必要执行回归测试的时间
需要重新测试多少
- 全部重测?
- 选定的一些测试用例集合
- 当前报错的测试用例,以后的回归测试需要重新测试
- 需要进行影响分析(impact analysis)来找出修补缺陷会影响的区域。根据影响分析,选择一些测试用例来检验受影响的区域。
- 全部重测?
- 回归测试过程
- Test Suite Minimisation Problem
挑选一部分代表性的测试用例,可以满足所有的测试需求 - Test Case Selection Problem
在总的测试集中选择一个子集,来对修改后的程序进行测试 - Test Case Priotisation Problem
在测试集中挑选出一部分优先级最高的测试用例
Test case minimization
- 目标是去掉测试集中冗余的测试用例,来减小测试集的规模
- 假设每一个需求ri都能被一个单独的测试用例所满足,则可以看作是实现了最小测试集
- 实际上做不到
- 实际上做不到

- 四种贪心策略
- Greedy
挑选可以满足需要数最大的测试用例,直到覆盖全部需求 - Additional Greedy
按照满足未满足需求个数的优先级,来进行测试用例的选取 - Greedy Essenstial
先挑选出必要的测试用例,再使用AG - Greedy Redundant Essential
先去掉全部冗余的测试用例,使得全部的测试用例都是必要的,然后再执行GE
- Greedy
- 测试集最小化的有效性
- (1 - 减少后的测试用例数/原测试用例数)* 100%
- (1 - 减少后的测试用例数/原测试用例数)* 100%
在错误检测方面,最小化测试用例集的影响
减少测试用例的数量来满足测试的需求
- 只是减少数量,保有原来的检测能力/测试开销/代码覆盖能力
- 只是减少数量,保有原来的检测能力/测试开销/代码覆盖能力
- 挑选原则
- 错误检测能力
- 代码覆盖率
- 执行时间
- 历史检错
- 错误检测能力
- 把测试用例分成五类
- 原测试集中的三类
- Reusable
- 会执行程序中没有改变的部分的测试用例
- 会执行程序中没有改变的部分的测试用例
- Re-testable
- 会执行程序中改变的部分的测试用例
- 会执行程序中改变的部分的测试用例
- Obsolete 丢弃
- 输入或者输入根据需求改变了
- 由于程序的改变,无法按照原来设计的目的来测试
- 一些结构性(structurally)的测试用例,对程序的结构覆盖已经没有用了
- 输入或者输入根据需求改变了
- Reusable
- 需要新生成的两类测试用例
- New-structual
- 为了结构性覆盖新程序中被修改的部分而设计的测试用例
- 为了结构性覆盖新程序中被修改的部分而设计的测试用例
- New-specification
- 根据新的需求而被设计的测试用例
- 根据新的需求而被设计的测试用例
- New-structual
- 原测试集中的三类
- 部分选项
- Fault-revealing
- 执行后会有错误的输出
- impossible to compute
- 执行后会有错误的输出
- Modification-revealing
- 有不同的输出
- hard to compute
- 有不同的输出
- Modification-traversing
- 能够执行到代码修改的部分
- easy to compute
- 能够执行到代码修改的部分
- Retest all
- Fault-revealing

- 挑选测试用例的三种程度
- Inclusive
- 从原测试用例集里,挑选的modification revealing的测试用例的比例
- 从原测试用例集里,挑选的modification revealing的测试用例的比例
- Safe
- 挑选所有modification revealing的测试用例,即100%inclusive
- 挑选所有modification revealing的测试用例,即100%inclusive
- Precision
- 描述的是挑选的忽略了non modification revealing测试用例的比例
- 描述的是挑选的忽略了non modification revealing测试用例的比例
- Inclusive
例题
// P0
func(int a, int b){
int result = 0;
if(b>5){
result = a^2;
}
return result;
}
// P1
func(int a, int b){
int result = 0;
if(b>5){
result = 2*a^2;
}
return result;
}
// P2
func(int a, int b){
int result = 0;
if(b>5){
result = a^3;
}
return result;
}
| a | b | P0 | P1 | P2 | P0-P1 | P0-P2 | P1-P2 |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 0 | 0 | 0 | |||
| 1 | 6 | 1 | 2 | 1 | MR->(FR) | MT | MR->(FR) |
| 2 | 6 | 4 | 8 | 8 | MR->(FR) | MR->(FR) | MT |
| 3 | 6 | 9 | 18 | 27 | MR->(FR) | MR->(FR) | MR->(FR) |
Evaluation Models
经常会检测出缺陷的
- 核心功能会被执行到,确保核心功能正确运行
- 执行到很多的最近的变更
- 所有的集成测试用例
- 所有的复杂的测试用例
- 边界值测试用例
- 成功的测试用例的样本 sample
-
Test case Prioritization
测试人员需要找到最佳的测试顺序,以防测试被挂起
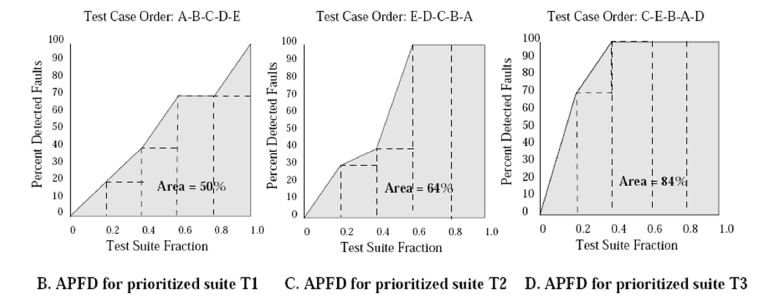
APFD Average Percentage of Fault Detection
- 计算折线图的面积
- m个fault,n个测试用例
- TFn = 第n个fault是由哪个测试案例找出来的
- m个fault,n个测试用例

-
When to do Regression Testing
日常执行
- 每天,每周,每月
- 每天,每周,每月
- 根据规定执行
- 每次变更后,重要变更后,在一个重要版本发布前
- 每次变更后,重要变更后,在一个重要版本发布前
结束时间
re-testing 和 regression testing
- retesting指测试功能或bug,来保证代码是被修正的,如果没被修正,就会重新开始一项defect,如果被就修正了,就会关闭defect
- regression testing指当代码发生变化时,对软件应用进行测试,来确保新的代码没有影响软件的其他部分
- retesting指测试功能或bug,来保证代码是被修正的,如果没被修正,就会重新开始一项defect,如果被就修正了,就会关闭defect
- 冒烟测试 smoke test,可用性测试 sanity test,BVT build verification test
- 冒烟测试和可用性测试都是通过快速确定应用是否有太多缺陷而不值得进行严格测试,以此来节省时间和精力
- 冒烟测试和可用性测试都是通过快速确定应用是否有太多缺陷而不值得进行严格测试,以此来节省时间和精力
- 冒烟测试 smoke testing
- 确保程序的关键功能运行良好
- 在软件构建过程中,每次细节的功能或回归测试之前都要被执行
- 目的是为了拒绝一个严重损坏的应用,这样QA团队就不需要浪费时间安装和测试软件
- 典型的冒烟测试
- 验证应用是否能够成功加载
- 确认GUI界面是否有反应
- hello world
- 验证应用是否能够成功加载
- 确保程序的关键功能运行良好
- 可用性测试 sanity testing
- 在收到一个构建完的软件之后,通过代码或功能上的微小改变,来确定bug都被修复了并且这些操作没有产生新的影响
- 如果可用性测试失败了,软件会被拒绝,以此来节省后续完整测试的时间和开销
- 目标并不是完全地确认新功能,而是要确定开发人员是否在开发软件的时候采取了理智(apply some rationality)
- 比如
- 一个科学计算器算出来2+2=5,那么再去计算sin30+cos50就没有任何意义了
- 一个科学计算器算出来2+2=5,那么再去计算sin30+cos50就没有任何意义了
- 在收到一个构建完的软件之后,通过代码或功能上的微小改变,来确定bug都被修复了并且这些操作没有产生新的影响
Smoke Testing Vs Sanity Testing | Smoke Testing | Sanity Testing | | —- | —- | | 确保关键功能正确 | 检查新功能或bug被修复 | | 目标是验证系统的稳定性 stability | 目标是验证系统的理性 rationality | | 开发者或测试人员 | 测试人员 | | 有案可查或者是用脚本 | 不会记录且不用脚本 | | 是验收测试的子集 | 是回归测试的子集 | | 测试整个系统 | 测试系统的特定部分 | | shallow and wide | narrow and deep |
一些要点
软件测试主要是由单元测试、集成测试、系统测试、验收测试等过程组成,和软件开发周期相关
- 单元测试是测试的第一项工作,重点是测试模块的正确性,是软件能正确运行的基础
- 桩模块、驱动模块
- 桩模块、驱动模块
- 集成测试是按某种策略,将通过单元测试的模块集成起来进行的正确性测试, 重点是测试模块间的接口
- 各种集成策略
- 各种集成策略
- 系统测试是将经过集成测试后的软件和其运行环境,支撑环境和人组成一个完整系统的测试,重点测试软件的功能、性能、行为等方面
- 性能测试
- 性能测试
- 验收测试更多的是从用户的角度对经过系统测试的软件在运行一段时间后再对其功能、性能等方面的测试,考察其是否满足原先的需求
- α/β测试
- α/β测试
- 回归测试是一项面广量大的测试工作,测试效率非常重要
- TC-M,TC-S,TC-P
- TC-M,TC-S,TC-P
从单元测试到验收测试,有测试任务、参与人员、测试技术、测试数据等方面的变化
Session 14 Performance testing
什么是性能测试
为了获取系统性能相关指标或发现系统性能问题而进行的测试
- 一般在真实环境、特定负载条件下,通过工具模拟实际软件系统的运行及其操作,同时监控性能的各项指标,最后对测试结果进行分析来确定系统的性能状况
观察系统在给定的一个环境和场景中的性能表现是否和预期目标一致,评判系统是否存在性能缺陷,并根据测试结果识别性能瓶颈,改善系统性能的完整的过程
性能测试目标
获取系统性能的某些指标数据
- 为了验证系统是否达到用户提出的性能指标
-
性能测试类型
性能验证测试:验证系统是否满足事先定义的系统性能指标和需求
- 性能基准测试:在系统标准配置下获得相关性能指标数据,作为将来性能改进的基准线
性能规划测试:在多种特定环境下,获得不同性能指标,从而决定在部署时采用什么样的软硬件配置
性能指标
用户角度
- 响应时间
- 响应时间
运营商和开发商角度
并发性能测试
- 逐渐增加并发虚拟用户数负载,直到系统出现性能瓶颈或崩溃为止
- 属于破坏性压力测试,通过不断加载的手段,快速造成系统的崩溃,尽早暴露问题
- 逐渐增加并发虚拟用户数负载,直到系统出现性能瓶颈或崩溃为止
- 疲劳强度测试
- 系统稳定运行情况下持续长时间运行,以发现性能问题
- 系统稳定运行情况下持续长时间运行,以发现性能问题
- 大数据量测试
- 致命错误:导致系统崩溃,数据丢失,数据损坏等
- 严重错误:功能或特性没有实现,主要功能部分丧失,次要功能完全丧失等
- 一般性错误:操作性错误,错误结果,遗漏功能
-
优先级 Priority
指缺陷被修复的紧急程度
优先级 立即解决:缺陷导致系统几乎不能使用或测试不能继续,需要立即修复
- 高优先级:缺陷严重,影响测试,需要优先考虑
- 正常排队:缺陷需要正常排队等待修复
- 低优先级:缺陷可以在开发人员有时间的时候被纠正
其他属性
- ID 缺陷标识
- type 缺陷类型,例如功能,UI,性能,文档
- frequency 缺陷产生可能性/可再现的概率
- source 缺陷来源:需求,设计,编码
- cause 缺陷原因:数据格式,计算错误,接口参数,变量定义与引用
基本的缺陷信息
- 步骤
- 期望结果
-
软件缺陷报告
缺陷项目列表
可跟踪信息
- 缺陷 ID
- 缺陷 ID
- 缺陷基本信息
- 缺陷状态
- 标题
- 严重程度
- 优先级
- 产生频率
- 提交人
- 提交时间
- 所属模块
- 指定解决人
- 指定解决时间
- 验证人
- 验证结果
- 验证时间
- 缺陷状态
- 详细描述
- 步骤
- 期望结果
- 实际结果
- 步骤
- 测试环境
-
缺陷描述的基本要求
单一准确
- 可以再现
- 完整统一
- 短小简练
- 特定条件
- 补充完善
- 不做评价
优秀的缺陷报告
- 缺陷趋势报告:按各种状态将缺陷计数作为时间的函数显示,累计/非累计
缺陷分布报告:将缺陷计数作为函数的参数来显示,生成缺陷数量与缺陷属性的函数
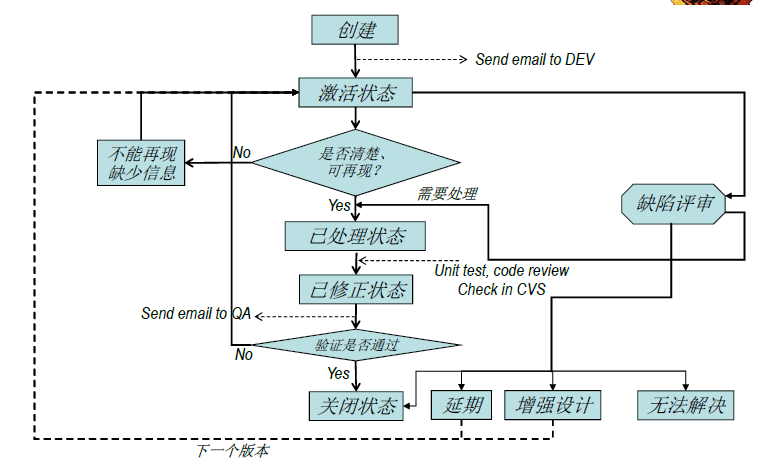
软件缺陷生命周期值的是一个软件缺陷被发现、报告到这个缺陷被修复、验证直至关闭的完整过程
- 缺陷生命周期是各类开发人员一起参与、协同测试的过程
软件缺陷一旦被发现,就会被监控,知道这个缺陷的生命周期的中介,这就可以保证
发现->打开:测试人员找到软件缺陷并把缺陷交给开发人员打开->修复:开发人员再现、修复缺陷,然后提交给测试人员验证-
复杂的缺陷生命周期
实际的缺陷生命周期
Session 16 Testing Metrics
在书写软件测试和质量分析报告之前
是否完成了测试计划要求的各项测试内容?
- 测试用例是否经过开发人员、产品经理的严格评审?
- 需要执行的测试用例是否百分之百地完成了?
- 单元测试的代码行覆盖率是否达到所设定的目标?
- 集成测试是否全面验证了所有接口及其参数?
- 系统测试是否包含了性能、兼容性、安全性、恢复性等各项测试?如果执行了,又是怎么进行的、结果如何?
-
Types of Testing Metrics
Size Measurements
- Complexity Measurements
-
Size Measurements
Size 是一个基础的度量,大部分的可以收集到的度量都是通过 size 指标来标准化的,提供了独立于软件项目规模的分析。
通常利用以下三种方式来计算软件的 Size Lines of Code (LOC) 代码行
- Function Points (FPs) 功能点
- 独立于编程语言和代码行
- 可以在早期被测量
- 独立于编程语言和代码行
Tokens 程序中的操作符和操作数
关注的是软件的内在特征
- 提供了包括可靠度和可维护性等关键信息
-
Metrics Unique to Test
DRE
Defect Removal Efficiency:缺陷清除率
- DRE = 发布前发现的缺陷数 / (发布前发现的缺陷数 + 发布后发现的缺陷数)

DD
- Defect Density:缺陷密度
- DD = 缺陷数量 / 软件规模 (LOC 代码行, FP, Token)
- 用于评价哪一个模块质量好
MTTF
- Mean Time to Failure:平均无故障时间,从一个故障出现到下一个故障出现的时间
- MTTR——Mean Time To Repair,即平均恢复时间。就是从出现故障到恢复中间的这段时间。MTTR越短表示易恢复性越好。
- MTTF——Mean Time To Failure,即平均无故障时间/故障前平均时间。系统的可靠性越高,平均无故障时间越长。
- MTBF——Mean Time Between Failure,即平均失效间隔。包括故障时间以及检测和维护设备的时间。MTBF = MTTF + MTTR。因为MTTR通常远小于MTTF,所以MTBF近似等于MTTF,通常由MTTF替代。
软件产品的质量度量
软件的度量是对软件所包含的各种属性的量化表示,定性=>定量软件度量的作用
- 深入了解软件的过程和产品的衡量指标
- 组织能更好地做出决策以达成目标
- 用数据指标表明验收标准
- 监控项目进度和预估风险
- 分配资源时进行量化均衡
- 预计和控制产品的过程、成本和质量
比如学分制就是用数据来表示验收标准
- 用数据指标表明验收标准
度量相关概念
- 测量 measurement :确定一个测量的行为
- 度量 metric:某个给定的属性的度的一个定量测量
- 指标 indicator:具体测量的属性以及其给定值,或组合值
举例
- 测量:文档页数;发现错误数;每个人的准备时间
- 度量
- prepation rate = 总的准备时间 / 文档页数
- fault density = 错误数 / 文档页数
- prepation rate = 总的准备时间 / 文档页数
指标
规模度量:代码行数,功能点和对象点等
- 复杂度度量:软件结构复杂度指标
- 缺陷度量:帮助确定产品缺陷变化的状态,并指示修复缺陷活动所需的工作量,分析产品缺陷分布的情况
- 工作量度量
- 进度度量
- 生产率度量:代码行数/人·月,测试用例数/人·日;
-
有效软件度量的属性
简单,可计算的
- 经验和直觉上有说服力
- 一致的,客观的
- 在单位和维度上的使用是有意义的
- 独立于编程语言
- 质量反馈的有效机制
软件度量的过程
- 识别目标
分析出度量的工作目标和列表,并由管理者审核确认。 - 定义度量过程
定义其收集要素、收集过程、分析和反馈过程、IT支持体系,为具体的收集活动、分析、反馈活动和 IT 设备、工具开发提供指导。 - 搜集数据
应用 IT 支持工具进行数据收集工作,并按指定的方式审查和存储。 - 数据分析和反馈
根据数据收集结果,按照定义的分析方法进行数据分析,完成规定格式的图标,进行反馈 - 过程改进
根据度量的分析报告,管理者基于度量数据做出决策
软件质量的度量
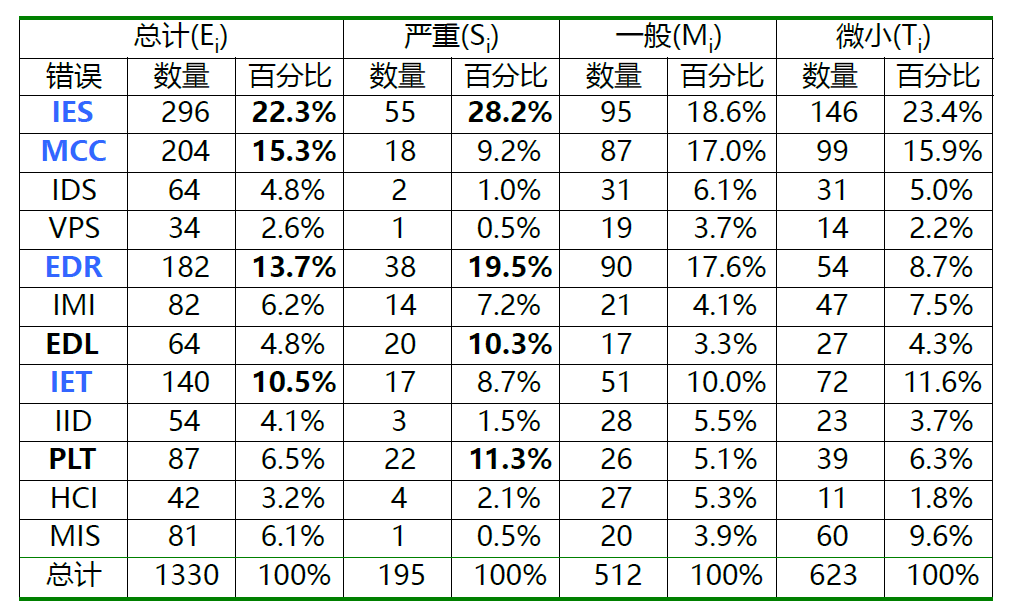
基于质量模型,使用带加权因子的回归公式来度量软件质量
- 说明不完整或说明错误(IES)
- 与客户交流不够所产生的误解(MCC)
- 故意与说明偏离(IDS)
- 违反编程标准(VPS)
- 数据表示有错(EDR)
- 模块接口不一致(IMI)
- 设计逻辑有错(EDL)
- 不完整或错误的测试(IET)
- 不准确或不完整的文档(IID)
- 将设计翻译成程序设计语言中的错误(PLT)
- 不清晰或不一致的人机界面(HCI)
- 杂项(MIS)
质量度量计算
阶段错误度量,区分错误的严重程度
总体质量度量
i = 1, 2, 3, 4, 5 代表需求分析,设计,编程,测试,发布
基于覆盖的质量评估
- 基于需求的测试覆盖评估
- 基于代码的测试覆盖评估
软件测试评估的主要目的
- 已执行的测试覆盖 =
- 是已经执行的测试过程数或测试用例数
- 是测试需求的总数
- 是已经执行的测试过程数或测试用例数
成功的测试覆盖 =
已执行的测试覆盖 =
| 条目 | 目标 | 低水平 |
|---|---|---|
| 缺陷清楚效率 | >95% | <70% |
| 原有缺陷密度 | 每个功能点<4 | 每个功能点>7 |
| 做出风险之外的成本 | 0% | >=10% |
| 全部程序文档 | 每个功能点页数<3 | 每个功能点页数>6 |
| 员工离职率 | 每年 1%-3% | 每年 > 5% |
基于缺陷率的估算方法
- F 为描述软件规模用的功能点
- D1 为软件开发过程中发现的所有缺陷数
- D2 为软件发布后发现的缺陷数
- D = D1 + D2 为发现的总缺陷数
- 缺陷注入率(缺陷密度) = D/F
- 整体缺陷清除率 = D1/D

种子公式

- N = S * n / s
- 其中n是所进行实际测试时发现的Bug总数。
- 如果n = N, 可以推测为所有的Bug已找出来,说明做的测试足够充分。
问题
if (a&&b) c=1 …
if (a||b) c=0 …
- 为了 kill 这个变异
- 测试数据必须对变异和原始程序引起不同状态的覆盖
- c 的值应该传播到程序输出,并且被测试检查
- 测试数据必须对变异和原始程序引起不同状态的覆盖
- 弱编译覆盖满足1;强编译覆盖满足1和2;
- 通过变异测试来模拟被测软件的真实缺陷,从而对研究人员提出的测试方法的有效性进行辅助评估
- 变异测试旨在找出有效的测试用例,发现程序中真正的错误。传统的变异测试旨在寻找这些错误的子集,能尽量充分地近似描述这些BUG。
- 变异测试则提供了基于缺陷的对测试充分性进行度量的角度,针对测试用例集的充分性进行评估和改进。
- 该理论基于两个假设
- Competent Programmer Hypothesis(CPH)
假设编程人员是有能力的,他们尽力去更好地开发程序,达到正确可行的结果,而不是搞破坏。 - Coupling Effect(CE)
关注在变异测试中错误的类别。复杂变异体往往是由诸多简单变异体组合而成。
- Competent Programmer Hypothesis(CPH)
变异测试的流程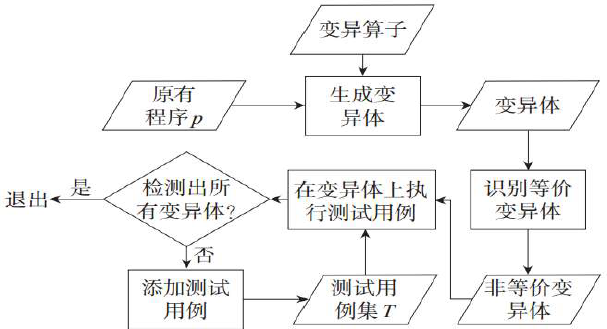
- 变异算子
- 在符合语法规则前提下, 变异算子定义了从原有程序生成差别极小程序(即变异体) 的转换规则。
if(a+b>c)变异体为if(a-b>c)
- 在符合语法规则前提下, 变异算子定义了从原有程序生成差别极小程序(即变异体) 的转换规则。
- 常见变异算子
- statement deletion
- statement duplication or insertion
- replacement of boolean subexpressions with
trueandfalse - replacement of some arithmetic operations with others,
+with*,-with/ - replacement of some boolean relations with others,
>with>=,==and<= - replacement of variables with others from the same scope 同范围内的变量替换
- statement deletion
- 根据执行变异算子的次数,变异体分为一阶变异体和高阶变异体。
- 可杀死变异体
- 若存在测试用例,在变异体和原程序上的执行结果不一致,则称该变异体相对于测试用例集是可杀死变异体
- mutation score = number of mutants killed / total number of mutants
- 若存在测试用例,在变异体和原程序上的执行结果不一致,则称该变异体相对于测试用例集是可杀死变异体
- 可存活变异体
- 不存在测试用例可以使变异体和原程序的执行结果不一致,则称该变异体相对于测试用例集是可存货变异体
- 一部分可存活变异体通过设计新的测试用例可以转化成可杀除变异体,剩余的可存活变异体则可能是等价变异体。
- 不存在测试用例可以使变异体和原程序的执行结果不一致,则称该变异体相对于测试用例集是可存货变异体
- 等价变异体
- 等价变异体和原程序p在语法上有差异,但在语义上保持一致
// 原程序
for (int i = 0;i<10;i++){
//…
}
for (int i = 0;i!=10;i++){
//…
}
- 等价变异体检测
- 不可判定问题,需要测试人员手工完成
- 等价变异体一般占比 10%-40%
- 变异体选择优化策略
- 不可判定问题,需要测试人员手工完成
- 主要关注如何从生成的大量变异体中选择出典型变异体
随机选择法
- 生成变异体,定义比例,随机选择
聚类选择法
- 首先对被测程序 p 应用变异算子生成所有的一阶变异体
- 选择某一聚类算法根据测试用例的检测能力对所有变异体进行聚类分析,使得每个聚类内的变异体可以被相似测试用例检测到
- 最后从每个聚类中选择出典型变异体,丢弃其他变异体
变异算子选择法
- 从变异算子选择角度出发, 希望在不影响变异评分的前提下, 通过对变异算子进行约简来大规模缩小变异体数量, 从而减小变异测试和分析开销。
- 结果表明, 变异算子选择法相对于随机选择法来说并不存在明显优势。
高阶变异体优化法
- 基于假设
- 执行一个k 阶变异体相当于一次执行k 个一阶变异体;
- 高阶变异体中等价变异体的出现概率较小。
- 执行一个k 阶变异体相当于一次执行k 个一阶变异体;
实证研究表明, 采用二阶变异体可以有效减少50%的测试开销, 但却不会显著降低测试的有效性。
缺陷损耗的估算方法
缺陷潜伏期是一种特殊类型的缺陷分布度量。
- 缺陷损耗是使用阶段潜伏期和缺陷分布来度量缺陷消除活动的有效性的一种度量
- 缺陷损耗 = 缺陷数量*发现的阶段潜伏期加权值 / 缺陷总量
- 缺陷损耗 = 缺陷数量*发现的阶段潜伏期加权值 / 缺陷总量
- 一般缺陷损耗越低,说明缺陷的发现过程越有效
- 用缺陷损耗来度量测试有效性的长期趋势(递减)时,它就会显示出自己的价值。
例题
- 计算 DRE 和 DD

total size = 483 FP
缺陷清除率 DRE = (50+30+20+25)/ (50+30+20+25+10)
缺陷密度 DD = (50+30+20+25+10)/483 - 计算 MTTF
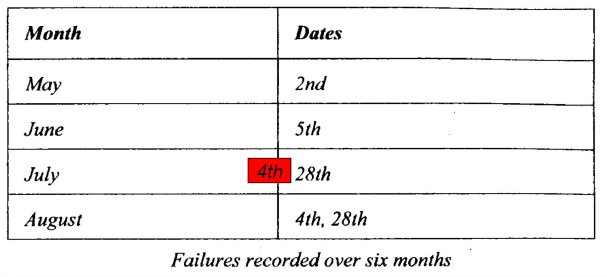
MTTF June = (7.4-5.2)/2
MTTF July = (8.4-7.5)/3
MTTF August = (8.28-7.28)/2 - 缺陷损耗估算
缺陷潜伏期的度量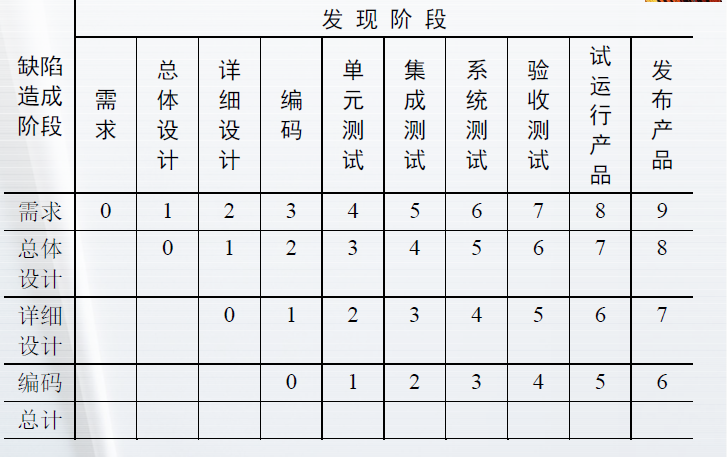
缺陷的实际分布
缺陷损耗值计算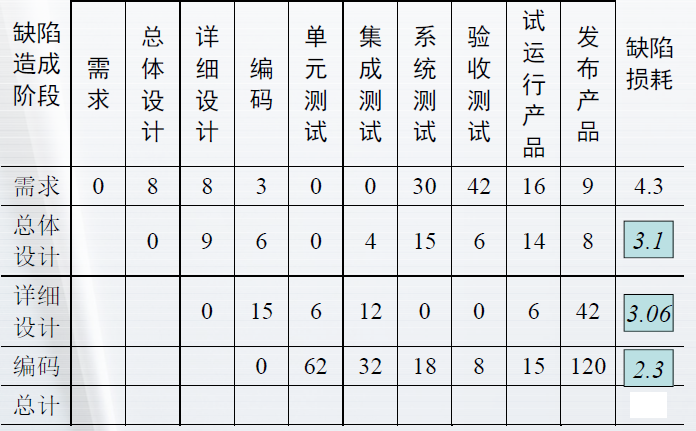
测试报告的具体内容
国标
- 产品标识;
- 用于测试的计算机系统
- 使用的文档及其标识
- 产品描述、用户文档、程序和数据的测试结果;
- 与要求不符的清单;
- 针对建议的要求不符的清单,产品未作符合性测试的说明;
- 测试结束日期。
IEEE 标准
- 测试总结报告标识符
- 总结
- 差异
- 综合评估
- 结果总结 5.1 已解决的意外事件 5.2 未解决的意外事件
- 评价
- 建议
- 活动总结
- 审批

若有收获,就点个赞吧
0 人点赞
