泛型
概念
泛型由来:模拟数组数据类型检查功能
数组优点:数组在编译时期就检查数据类型,只要不是规定类型,就会在编译器中提示,不需要运行程序就可以看到错误信息。
泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。
泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
格式:、<?>、
作用
- 约束集合中元素类型,没有约束的集合没数据类型太过自由,可以提前报错时机,编译时就会提示错误信息,在向集合添加元素时,先检查类型,与规定类型不同就会报错。
示例代码
```java package cn.tedu.generic;
import java.util.ArrayList; import java.util.List;
/**
- 测试泛型的优点 */
public class TestGeneric1 { public static void main(String[] args) { / 泛型由来 模拟数组数据类型检查功能 数组优点:数组在编译时期就检查数据类型,只要不是规定类型, 就会在编译器中提示,不需要运行程序就可以看到错误信息 / String[] a = new String[5]; a[0] = “埼玉”; a[1] = “杰诺斯”; / 不符合类型,报错 a[3] = 1; a[4] = 1.6; a[2] = ‘a’; /
/*泛型通常与集合一起使用*/List list = new ArrayList();//不会报错,没有限制数据类型,无限制,数据类型太自由list.add("索尼克");list.add(1.8);list.add(1);list.add('a');/*引入泛型的目的:用于约束集合中元素类型优点,可以提前报错时机,编译时就会提示错误信息,在向集合添加元素时,先检查类型,与规定类型不同会报错*/List<String> list1 = new ArrayList<>();list1.add("King");/*报错,泛型限制了数据类型,与规定类型不同会报错list1.add(1);list1.add(1.2);list1.add('a');*//*<type>---根据业务类型自定义,必须为引用类型,不能为基本类型*/List<Integer> list2 = new ArrayList();list2.add(100);list2.add(200);list2.add(300);list2.add(400);System.out.printf(String.valueOf(list2));}
}
2. 使代码更加通用<a name="a57e6b13"></a>#### 示例代码:```javapackage cn.tedu.generic;/*** 测试泛型的优点*/public class TestGeneric2 {public static void main(String[] args) {Integer[] a = {1,2,3,4,5,6,7,8,9,10};print(a);String[] b = {"老大","老二","老三","老四","老五","老六","老七","老八"};print(b);Double[] c = {6.0,6.6,6.66,6.666,6.6666};print(c);}/*泛型可以写出更加通用的代码,E表示Element:元素语法要求:必须两处同时出现,方法参数为泛型,返回值类型前为泛型<E>,这两处一起表示这是一个泛型方法*/private static <E> void print(E[] a) {/*普通for循环for (int i = 0;i < a.length;i++){System.out.print(a[i] + " ");}System.out.println();*//*增强for循环使用场景,只需要对数据进行一次遍历优点:比普通for循环语法简单,效率高缺点:不可以按照下标操作元素,只能由头至尾进行遍历语法:for(数据类型2 变量名3 : 数据1){}1:需要遍历的数据2:指本轮循环遍历得到的具体元素类型3:遍历得到的元素名称*/for (E i : a) {System.out.print(i + " ");}System.out.println();}/*方法重载private static void print(String[] a) {for (String s : a) {System.out.print(s + " ");}System.out.println();}private static void print(Double[] a) {for (Double d : a) {System.out.print(d + " ");}}*/}
规则
- 所有泛型方法声明都有一个类型参数声明部分(由尖括号分隔),该类型参数声明部分在方法返回类型之前()。
- 每一个类型参数声明部分包含一个或多个类型参数,参数间用逗号隔开。一个泛型参数,也被称为一个类型变量,是用于指定一个泛型类型名称的标识符。
- 类型参数能被用来声明返回值类型,并且能作为泛型方法得到的实际参数类型的占位符。
- 泛型方法体的声明和其他方法一样。注意类型参数只能代表引用型类型,不能是原始类型(像
int,double,char等)。
泛型声明
泛型可以在接口、类、方法上使用
public class TestStudy<Student>{}public interface Collection<E>{}public <E> void prit(E e){}
常用名称
| 名称 | 意义 |
|---|---|
| E | Element(在集合中使用,集合中存放的为元素) |
| T | Type(java类) |
| K | Key(键) |
| V | Value(值) |
| N | Number(数值类型) |
| ? | 表示不确定的java类型 |
增强for循环
使用场景,只需要对数据进行一次遍历
优点:比普通for循环语法简单,效率高
缺点:不可以按照下标操作元素,只能由头至尾进行遍历
语法格式
for(数据类型2 变量名3 : 数据1){}1:需要遍历的数据2:指本轮循环遍历得到的具体元素类型3:遍历得到的元素名称
示例代码
private static void print(String[] a) {for (int i = 0;i < a.length;i++){System.out.print(a[i] + " ");}System.out.println();for (String s : a) {System.out.print(s + " ");}System.out.println();}
集合
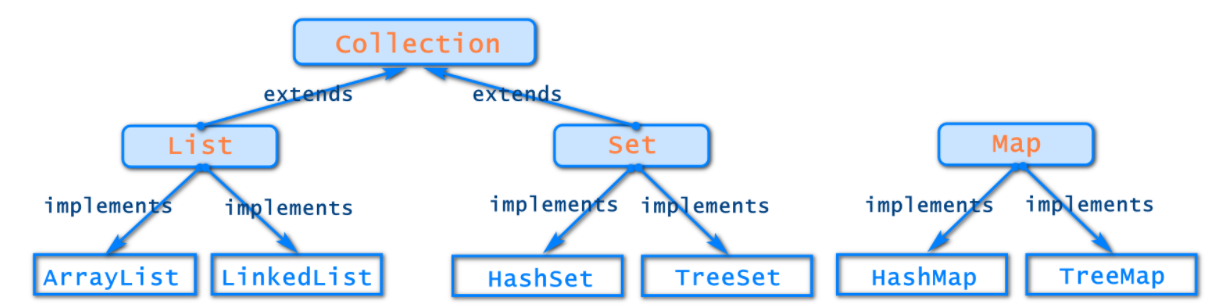
集合长度可变,数组长度不可变
常用的集合类有List集合,Set集合,Map集合,其中List集合与Set集合继承了Collection接口,各个接口提供了不同的实现类.
集合的英文名称是Collection,是用来存放对象的数据结构,而且长度可变,可以存放不同类型的对象,并且还提供了一组操作成批对象的方法.Collection接口层次结构 中的根接口,接口不能直接使用,但是该接口提供了添加元素/删除元素/管理元素的父接口公共方法.
由于List接口与Set接口都继承了Collection接口,因此这些方法对于List集合和Set集合是通用的.
常用集合关系
collection常用方法
普通方法
| 方法 | 返回值类型 | 方法描述 |
|---|---|---|
add(E e) |
boolean |
将制定对象添加到集合中 |
clear() |
void |
删除集合中所有元素 |
hashCode() |
int |
返回此集合的哈希码值。 |
equals(Object o) |
boolean |
将指定的对象与此集合进行比较 |
isEmpty() |
boolean |
判断集合是否为空 |
size() |
int |
返回此集合中的元素数。 |
remove(Object o) |
bollean |
从该集合中删除指定元素 |
contains(Object o) |
bollean |
判断集合中是否含有指定元素 |
toArrsy() |
Object[] |
返回一个包含此集合中所有元素的数组。 |
toString() |
返回该集合 |
多集合间的操作
| 方法 | 返回值类型 | 方法描述 |
|---|---|---|
addAll() |
boolean |
将指定集合中的所有元素添加到此集合的末尾。 |
containsAll() |
boolean |
如果此集合包含指定 集合中的所有元素,则返回true。 |
removeAll() |
boolean |
删除指定集合中包含的所有此集合的元素 |
retainAll() |
boolean |
仅保留此集合中包含在指定集合中的元素(取交集) |
迭代集合/遍历集合
过程:
- 获取集合的迭代器——
c.iterator() - 判断集合中是否有下一个可迭代的元素—-
it.hasNext() - 获取当前迭代到的元素——
it.next()
语法:
Iterator<Integer> it = c.iterator();while (it.hasNext()){Integer num = it.next();System.out.println(num);
示例代码
package cn.tedu.collection;import java.util.ArrayList;import java.util.Arrays;import java.util.Collection;import java.util.Iterator;/*** 测试Collection接口*/public class TestCollection {public static void main(String[] args) {/*Collection c = new Collection();报错,Collection为接口不可实例化*/Collection<Integer> c = new ArrayList<>();c.add(100);c.add(200);c.add(300);c.add(400);c.add(500);System.out.println(c);//可直接打印查看集合的元素/*c.clear();清空当前集合System.out.println(c);*/System.out.println(c.hashCode());//获取集合对象哈希码值System.out.println(c.toString());//打印集合的具体元素System.out.println(c.equals(200));//falseSystem.out.println(c.contains(200));//true,c集合中是否含有指定元素200System.out.println(c.isEmpty());//true,判断集合是否为空System.out.println(c.remove(100));//true,移除集合中指定元素System.out.println(c.size());//4,返回集合的元素个数System.out.println(Arrays.toString(c.toArray()));//返回一个包含此集合中所有元素的数组。//多个集合间的操作Collection<Integer> c2 = new ArrayList<>();c2.add(2);c2.add(4);c2.add(5);System.out.println(c2);c.addAll(c2);//将c2集合的所有元素添加到c集合中System.out.println(c);//c2集合的元素追加到了c集合末尾System.out.println(c2);//c集合本身没有任何变化System.out.println(c.containsAll(c2));//当前集合是否包含c2集合的所有元素System.out.println(c.removeAll(c2));//删除指定集合中包含的所有此集合的元素System.out.println(c.add(5));System.out.println(c.retainAll(c2));//取交集/*迭代集合、遍历集合1.获取集合的迭代器----c.iterator()2.判断集合中是否有下一个可迭代的元素---it.hasNext()3.获取当前迭代到的元素----it.next()*/Iterator<Integer> it = c.iterator();while (it.hasNext()){Integer num = it.next();System.out.println(num);}}}
List接口
有序的colletion(也称为序列).此接口的用户可以对列表中的每个元素的插入位置进行精确的控制,用户可以根据元素的整数索引(在列表中的位置)来访问元素,并搜索列表中的元素.
特点
- 元素都有下标
- 数据是有序的
- 允许存放重复的元素
常用方法
| 方法 | 返回值类型 | 作用 |
|---|---|---|
add(String item) |
void |
``将指定的项目添加到滚动列表的末尾。 |
equals() |
boolean |
``集合对象与String类型不符合 |
isEmpty() |
boolean |
判断集合是否为空 |
clear() |
void |
已弃用截至JDK 1.1版,由removeAll()。清空集合。 |
remove(int position) |
void |
``从此滚动列表中移除指定位置的元素。 |
removeAll() |
void |
``从此列表中删除所有项目。 |
size() |
int |
获取集合元素个数 |
add(index int elecent ) |
void |
向指定位置添加元素 |
indexOf() |
int |
获取指定元素第一次出现的索引 |
lastIndexOf() |
int |
获取指定元素最后一次出现的索引 |
get() |
获取指定索引处元素 | |
set() |
改指定索引处元素值,返回被修改的元素 | |
addAll() |
void |
将集合插入指定集合末尾 |
addAll(index,list1) |
void |
将集合插入指定位置 |
containsAll() |
void |
仅保留此集合中包含在指定集合中的元素(取交集) |
remove() |
在集合中删除指定集合中的所有元素 |
示例代码
package cn.tedu.collection;import java.util.ArrayList;import java.util.Arrays;import java.util.List;/*** 测试List接口*/public class TestList {public static void main(String[] args) {/*创建List多态对象,List为接口,不可实例化*/List<String> list = new ArrayList<String>();list.add("小火龙");list.add("妙蛙种子");list.add("杰尼龟");list.add("火球鼠");list.add("菊草叶");list.add("小锯鳄");list.add("小智");System.out.println(list);/*测试继承方法list.clear();清空集合System.out.println(list);*/System.out.println(list.contains("小火龙"));//true,判断集合中是否包含该元素System.out.println(list.equals("小火龙"));//false;集合对象与String类型不符合System.out.println(list.isEmpty());//false,判断集合是否为空System.out.println(list.remove("妙蛙种子"));//一处集合中指定元素System.out.println(list.size());//获取集合元素个数System.out.println(Arrays.toString(list.toArray()));//将集合转换为数组/*测试List接口特有方法,List为有序集合,可以根据索引操作集合的元素*/list.add("小刚");//追加在末尾list.add(1,"火恐龙");//在指定下标处添加元素System.out.println(list);System.out.println(list.indexOf("小火龙"));//获取指定元素第一次出现的索引System.out.println(list.lastIndexOf("小智"));//获取指定元素最后一次出现的索引System.out.println(list.remove(5));//删除指定索引处的元素,并返回被删除的元素System.out.println(list.get(3));//获取指定索引处元素System.out.println(list.set(6,"小霞"));//修改指定索引处元素值,返回被修改的元素System.out.println(list);System.out.println("--------------莫得感情的分界线-------------");/*集合间的操作*/List<String> list1 = new ArrayList<>();list1.add("1");list1.add("2");list1.add("3");list1.add("4");System.out.println(list1);System.out.println(list.addAll(list1));System.out.println(list.addAll(1,list1));//将list1添加到指定集合的指定位置System.out.println(list);System.out.println(list.containsAll(list1));System.out.println(list.removeAll(list1));}}
集合迭代方式
- for循环
- 增强for循环
格式:for(元素类型 元素名 : 需要遍历的集合名){循环体} iterator
格式:Iterator<泛型> 变量名 = 集合名.iteratorwhile(变量名.hasNext){变量名.next()}listIterator
示例代码
package cn.tedu.collection;import java.util.ArrayList;import java.util.Iterator;import java.util.List;import java.util.ListIterator;/*** 测试List接口*/public class TestList2 {public static void main(String[] args) {List<String> list = new ArrayList<>();list.add("喜羊羊");list.add("美羊羊");list.add("沸羊羊");list.add("懒羊羊");list.add("慢羊羊");list.add("肥羊卷");System.out.println(list);/*集合迭代方式1.for循环2.增强for3.iterator4.listIterator*///forfor (int i = 0;i < list.size();i++){System.out.print(list.get(i) + " ");}System.out.println();//增强forfor (String l : list){System.out.print(l + " ");}System.out.println();//iteratorIterator<String> s = list.iterator();while (s.hasNext()){System.out.print(s.next() + " ");}System.out.println();/*listIteratorList接口独有的迭代器Iterator<E>---父接口 listIterator<E>----子接口listIterator除了父接口的功能还具有自己的特有功能,例如逆序便利、添加元素,但是不常用public interface ListIterator<E> extends Iterator<E>*/ListIterator<String> iterator = list.listIterator();while (iterator.hasNext()){System.out.print(iterator.next() + " ");}}}
ArrayList
概述
- 存在
java.util包中 - 内部是用数组结构存放数据,封装数组的操作,每个对象都有下标
- 内部数组默认的初始容量是10,如果不够会以1.5倍的容量增长
- 查询快,增删数据效率会低
ArrayList()构造一个初始容量为10的空序列,每次扩容都会扩大原先的1.5倍ArrayList类是一个可以动态修改的数组,与普通数组的区别就是ArrayList没有固定大小的限制,可以添加或删除元素。ArrayList继承了AbstractList,并实现了 List 接口。
常用方法
| 方法 | 描述 |
|---|---|
| add() | 将元素插入到指定位置的 arraylist 中 |
| addAll() | 添加集合中的所有元素到 arraylist 中 |
| clear() | 删除 arraylist 中的所有元素 |
| clone() | 复制一份 arraylist |
| contains() | 判断元素是否在 arraylist |
| get() | 通过索引值获取 arraylist 中的元素 |
| indexOf() | 返回 arraylist 中元素的索引值 |
| removeAll() | 删除存在于指定集合中的 arraylist 里的所有元素 |
| remove() | 删除 arraylist 里的单个元素 |
| size() | 返回 arraylist 里元素数量 |
| isEmpty() | 判断 arraylist 是否为空 |
| subList() | 截取部分 arraylist 的元素 |
| set() | 替换 arraylist 中指定索引的元素 |
| sort() | 对 arraylist 元素进行排序 |
| toArray() | 将 arraylist 转换为数组 |
| toString() | 将 arraylist 转换为字符串 |
| ensureCapacity () |
设置指定容量大小的 arraylist |
| lastIndexOf() | 返回指定元素在 arraylist 中最后一次出现的位置 |
| retainAll() | 保留 arraylist 中在指定集合中也存在的那些元素 |
| containsAll() | 查看 arraylist 是否包含指定集合中的所有元素 |
| trimToSize() | 将 arraylist 中的容量调整为数组中的元素个数 |
| removeRange() | 删除 arraylist中指定索引之间存在的元素 |
| replaceAll() | 将给定的操作内容替换掉数组中每一个元素 |
| removeIf() | 删除所有满足特定条件的 arraylist元素 |
| forEach() | 遍历 arraylist中每一个元素并执行特定操作 |
示例代码
package cn.tedu.list;import java.util.ArrayList;import java.util.Iterator;import java.util.ListIterator;/*** ArrayList相关测试*/public class TestArrayList {public static void main(String[] args) {ArrayList<Integer> list = new ArrayList<>();list.add(100);list.add(200);list.add(300);list.add(400);list.add(400);list.add(300);System.out.println(list);/*list.clear();清空集合System.out.println(list);*/System.out.println(list.contains("100"));//false,类型不统一,Integer集合中不包含String类型元素System.out.println(list.isEmpty());//falseSystem.out.println(list.get(1));//200System.out.println(list.indexOf(400));//3System.out.println(list.lastIndexOf(400));//4System.out.println(list.remove(1));//200/*System.out.println(list.remove(300));数组下标越界*//*List中存在两个重载的remove(),传入的为int类型,会自动默认为index索引,所以要删除Integer类型指定元素需要使用Integer.valueOf()将int类型装箱为Integer*/System.out.println(list.remove(Integer.valueOf(300)));//true,System.out.println(list.set(2,666));//修改指定索引处元素值System.out.println(list.size());//集合迭代for (int i = 0; i < list.size();i++){System.out.print(list.get(i) + " ");}System.out.println();for (Integer i :list){System.out.print(i + " ");}System.out.println();Iterator<Integer> i = list.iterator();while (i.hasNext()){System.out.print(i.next() + " ");}System.out.println();ListIterator<Integer> it = list.listIterator();while (it.hasNext()){System.out.print(it.next() + " ");}}}
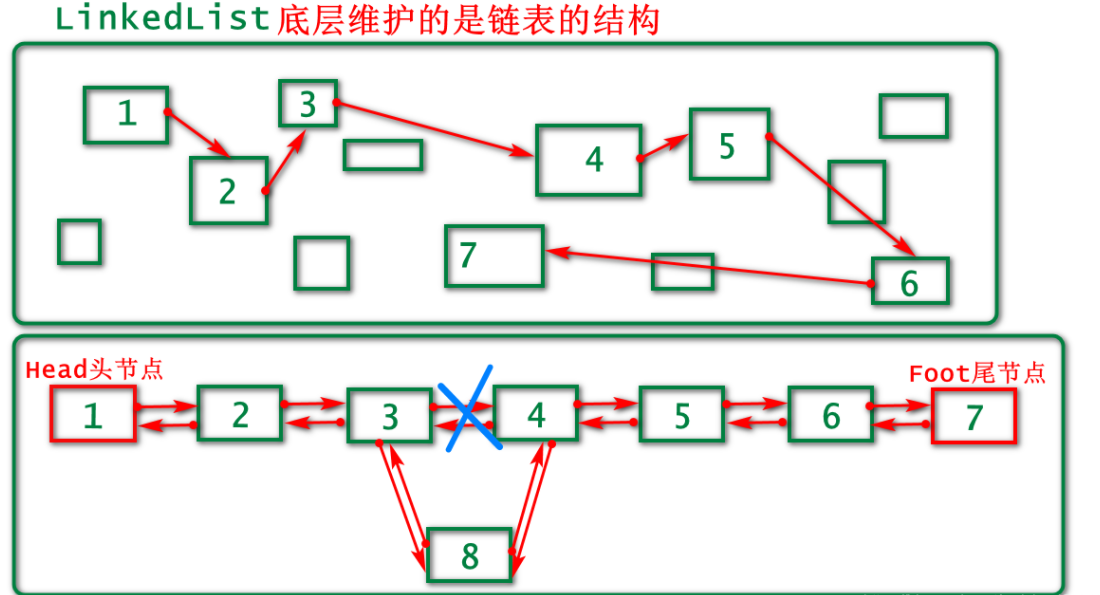
LinkedList
概述
链表,两端效率高,底层为链表
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的地址。
链表可分为单向链表和双向链表。查询慢,增删快,适用于增删较多的场合,或需要频繁访问头节点或尾结点的场合。
常用方法
示例代码
package cn.tedu.list;import java.util.LinkedList;/*** 测试LinkedList*/public class TestLinkedList {public static void main(String[] args) {LinkedList<String> list = new LinkedList<>();list.add("张辽");list.add("张郃");list.add("于禁");list.add("乐进");list.add("徐晃");System.out.println(list);list.addFirst("曹操");//添加首元素list.addLast("典韦");//添加尾元素System.out.println(list);System.out.println(list.getFirst());//获取首元素System.out.println(list.getLast());//获取尾元素System.out.println(list.removeFirst());//删除首元素System.out.println(list.removeLast());//删除尾元素System.out.println(list);LinkedList<String> list1 = new LinkedList<>();list1.add("关羽");list1.add("张飞");list1.add("赵云");list1.add("马超");list1.add("黄忠");System.out.println(list1);System.out.println(list1.element());//获取但不移除集合中的首元素System.out.println(list1.peek());//获取但不移除集合中的首元素System.out.println(list1.peekFirst());//获取但不移除集合中的首元素System.out.println(list1.peekLast());//获取但不移除集合中的尾元素System.out.println(list1.offer("刘备"));//追加操作System.out.println(list1.offerFirst("诸葛亮"));//添加到首位置System.out.println(list1.offerLast("姜维"));//添加到尾部位置System.out.println(list1);System.out.println(list1.poll());//移除首元素System.out.println(list1.pollFirst());//移除首元素System.out.println(list1.pollLast());//移除尾元素System.out.println(list1);}}
Set
概述
- Set是一个不包含重复数据的Collection
- Set集合中的数据是无序的(因为Set集合没有下标)
- Set集合中的元素不可以重复 – 常用来给数据去重
特点
- 数据无序且数据不允许重复
- HashSet : 底层是哈希表,包装了HashMap,相当于向HashSet中存入数据时,会把数据作为K,存入内部的HashMap中。当然K仍然不许重复。
TreeSet: 底层是TreeMap,也是红黑树的形式,便于查找数据
HashSet
底层是哈希表,包装了HashMap,相当于向HashSet中存入数据时,会把数据作为K存入内部的HashMap中,其中K不允许重复,允许使用null.
示例代码
package cn.tedu.list;import java.util.Arrays;import java.util.HashSet;import java.util.Iterator;import java.util.Set;public class HomeWork {public static void main(String[] args) {Set<Object> set = new HashSet<>();set.add("咸阳");set.add("长安");set.add("西安");set.add("洛阳");set.add("开封");System.out.println(set);Set<Student> s2 = new HashSet<>();Student t1 = new Student("张三",22);Student t2 = new Student("李四",22);Student t3 = new Student("李四",22);s2.add(t1);s2.add(t2);s2.add(t3);System.out.println(s2);System.out.println(set.contains("济南"));//查询集合中是否包含指定元素System.out.println(set.equals("洛阳"));//判断集合是否与指定对象相等System.out.println(set.hashCode());//获取集合的哈希码值System.out.println(set.isEmpty());//判断集合是否为空System.out.println(set.remove("开封"));//移除集合指定元素System.out.println(set.size());//获取当前集合元素个数System.out.println(Arrays.toString(set.toArray()));//将集合元素存入数组中//集合间的操作Set<String> set1 = new HashSet<>();set1.add("剑门关");set1.add("山海关");set1.add("函谷关");set1.add("嘉峪关");System.out.println(set1);System.out.println(set.addAll(set1));//将指定集合的所有元素添加至选定集合中System.out.println(set.containsAll(set1));//判断当前集合是否包含指定集合中所有元素System.out.println(set.removeAll(set1));//将当前集合中所有指定集合中的元素全部移除set.clear();//清除集合中所有元素//迭代Iterator<String> s = set1.iterator();while (s.hasNext()){System.out.print(s.next() + " ");}}}
Student类
package cn.tedu.list;import java.util.Objects;public class Student {String name;int age;public Student(String name, int age) {this.name = name;this.age = age;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age && Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(name, age);}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +'}';}}
Map
概述
类型参数 : K - 表示此映射所维护的键 V – 表示此映射所维护的对应的值
也叫做哈希表、散列表. 常用于键值对结构的数据.其中键不能重复,值可以重复
特点
- Map可以根据键来提取对应的值
- Map的键不允许重复,如果重复,对应的值会被覆盖
- Map存放的都是无序的数据
- Map的初始容量是16,默认的加载因子是0.75
常用方法
| 变量和类型 | 方法 | 描述 |
|---|---|---|
void |
add(int index, E element) |
将指定元素插入此列表中的指定位置。 |
boolean |
add(E e) |
将指定的元素追加到此列表的末尾。 |
boolean |
addAll(int index, Collection<? extends E> c) |
从指定位置开始,将指定集合中的所有元素插入此列表。 |
boolean |
addAll(Collection<? extends E> c) |
将指定集合中的所有元素按指定集合的迭代器返回的顺序附加到此列表的末尾。 |
void |
addFirst(E e) |
在此列表的开头插入指定的元素。 |
void |
addLast(E e) |
将指定的元素追加到此列表的末尾。 |
void |
clear() |
从此列表中删除所有元素。 |
Object |
clone() |
返回此 LinkedList的浅表副本。 |
boolean |
contains(Object o) |
如果此列表包含指定的元素,则返回 true。 |
Iterator<E> |
descendingIterator() |
以相反的顺序返回此双端队列中元素的迭代器。 |
E |
element() |
检索但不删除此列表的头部(第一个元素)。 |
E |
get(int index) |
返回此列表中指定位置的元素。 |
E |
getFirst() |
返回此列表中的第一个元素。 |
E |
getLast() |
返回此列表中的最后一个元素。 |
int |
indexOf(Object o) |
返回此列表中第一次出现的指定元素的索引,如果此列表不包含该元素,则返回-1。 |
int |
lastIndexOf(Object o) |
返回此列表中指定元素最后一次出现的索引,如果此列表不包含该元素,则返回-1。 |
ListIterator<E> |
listIterator(int index) |
从列表中的指定位置开始,返回此列表中元素的列表迭代器(按正确顺序)。 |
boolean |
offer(E e) |
将指定的元素添加为此列表的尾部(最后一个元素)。 |
boolean |
offerFirst(E e) |
在此列表的前面插入指定的元素。 |
boolean |
offerLast(E e) |
在此列表的末尾插入指定的元素。 |
E |
peek() |
检索但不删除此列表的头部(第一个元素)。 |
E |
peekFirst() |
检索但不删除此列表的第一个元素,如果此列表为空,则返回 null。 |
E |
peekLast() |
检索但不删除此列表的最后一个元素,如果此列表为空,则返回 null。 |
E |
poll() |
检索并删除此列表的头部(第一个元素)。 |
E |
pollFirst() |
检索并删除此列表的第一个元素,如果此列表为空,则返回 null。 |
E |
pollLast() |
检索并删除此列表的最后一个元素,如果此列表为空,则返回 null。 |
E |
pop() |
弹出此列表所代表的堆栈中的元素。 |
void |
push(E e) |
将元素推送到此列表所表示的堆栈上。 |
E |
remove() |
检索并删除此列表的头部(第一个元素)。 |
E |
remove(int index) |
删除此列表中指定位置的元素。 |
boolean |
remove(Object o) |
从该列表中删除指定元素的第一个匹配项(如果存在)。 |
E |
removeFirst() |
从此列表中删除并返回第一个元素。 |
boolean |
removeFirstOccurrence(Object o) |
删除此列表中第一次出现的指定元素(从头到尾遍历列表时)。 |
E |
removeLast() |
从此列表中删除并返回最后一个元素。 |
boolean |
removeLastOccurrence(Object o) |
删除此列表中最后一次出现的指定元素(从头到尾遍历列表时)。 |
E |
set(int index, E element) |
用指定的元素替换此列表中指定位置的元素。 |
int |
size() |
返回此列表中的元素数。 |
Spliterator<E> |
spliterator() |
在此列表中的元素上创建late-binding 和故障快速 [Spliterator](https://www.runoob.com/manual/jdk11api/java.base/java/util/Spliterator.html)。 |
Object[] |
toArray() |
以适当的顺序(从第一个元素到最后一个元素)返回包含此列表中所有元素的数组。 |
<T> T[] |
toArray(T[] a) |
以适当的顺序返回包含此列表中所有元素的数组(从第一个元素到最后一个元素); 返回数组的运行时类型是指定数组的运行时类型。 |
示例代码
package cn.tedu.list;import java.util.*;/*** 测试Map接口*/public class TestMap {public static void main(String[] args) {/*Map中的数据要符合映射规则,即同时指定k,v(键值对)k,v类型却决于需求*/Map<Integer,String> map = new HashMap<>();map.put(1,"西游记");map.put(2,"红楼梦");map.put(3,"水浒传");map.put(4,"封神榜");map.put(5,"封神榜");map.put(5,"三国演义");/*Map中存放的都是无序数据Map中的Value可以重复Map中的Key不可重复,若重复,后面的value会覆盖前面的value*/System.out.println(map);//方法//map.clear();清空集合System.out.println(map.hashCode());System.out.println(map.equals("水浒传"));System.out.println(map.isEmpty());System.out.println(map.size());System.out.println(map.containsKey(1));//判断当前map集合是否包含指定的keySystem.out.println(map.containsValue("封神榜"));//判断当前map集合中是否包含指定的valueSystem.out.println(map.get(2));//根据key获取对应valueSystem.out.println(map.remove(3));//根据kay值删除对应键值对System.out.println(map.containsKey(3));//将map集合中的所有value放入collection中Collection<String> values = map.values();System.out.println(values);/*迭代map本身没有迭代器,需要先将map转换为set集合Set<Key>:把map中所有key值存入到set集合中,keySet()将map中的key存入set集合中,集合的泛型就是key的类型Integer*/Set<Integer> keySet = map.keySet();Iterator<Integer> it = keySet.iterator();while (it.hasNext()){Integer key = it.next();String value = map.get(key);System.out.print("{" + key + "=" + value + "}" + " ");}System.out.println();/*将map集合转换为set集合,即将map中的一对键值对key&value作为一个Entry<K,V>整体放入Set集合一对k,v即为一个Entry*/Set<Map.Entry<Integer, String>> entrySet = map.entrySet();Iterator<Map.Entry<Integer,String>> iterator = entrySet.iterator();while (iterator.hasNext()){Map.Entry<Integer, String> next = iterator.next();//本轮遍历到的一对Entry对象Integer key = next.getKey();String value = next.getValue();System.out.print("{" + key + "=" + value + "}");System.out.print(next + " ");}}}
字符串统计
package cn.tedu.list;import java.util.HashMap;import java.util.Map;import java.util.Scanner;/*** 字符串字符个数统计*/public class TestMap2 {public static void main(String[] args) {System.out.print("请输入要统计的字符串:");String str = new Scanner(System.in).nextLine();/*统计的为字幕出现次数,单个字符为char类型,对应类型为characterInteger为value,可重复不能作为key,Character为key不可重复*/Map<Character,Integer> map = new HashMap<>();for (int i = 0;i < str.length();i++){char key = str.charAt(i);/*for循环int num = 0;for (int j = 0;j < str.length();j++){if (key == str.charAt(j)){num++;}}map.put(key,num);*/Integer value = map.get(key);if (value == null){map.put(key,1);}else {map.put(key,value+1);}}System.out.println(map);}}
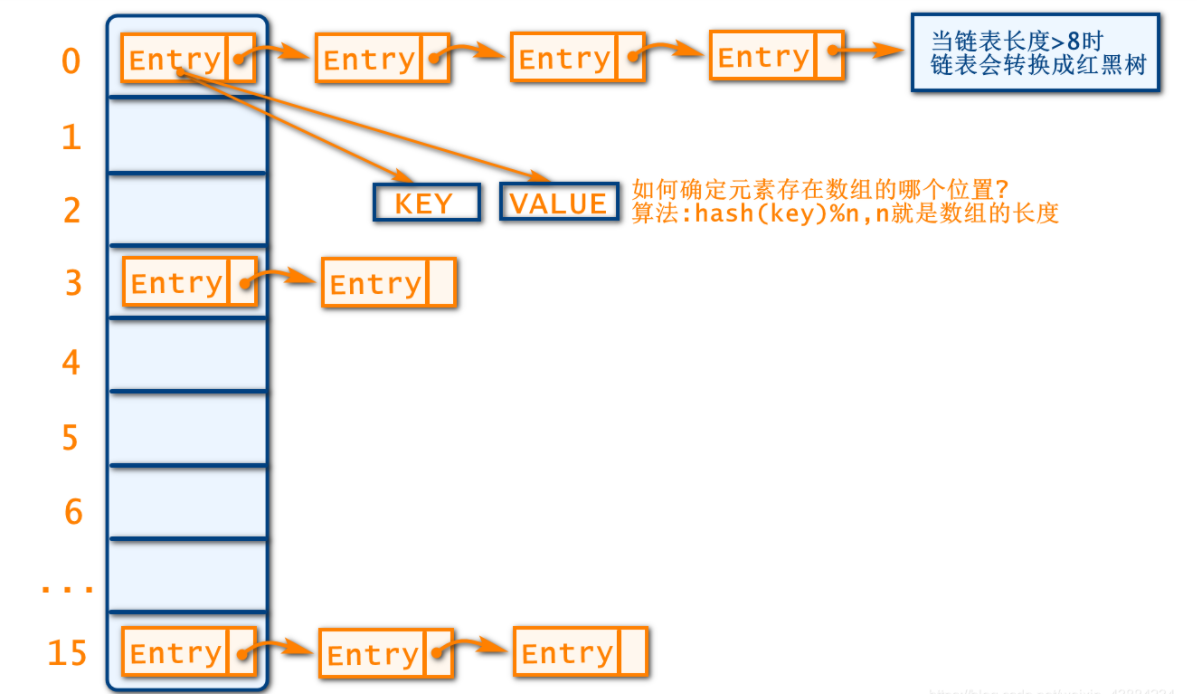
HashMap
概述
HashMap的键要同时重写hashCode()和equlas()
hashCode()用来判定二者的hash值是否相同,重写后根据属性生成
equlas()用来判断属性的值是否相同,重写后,根据属性判断
–equlas()判断数据如果相等,hashCode()必须相同
–equlas()判断数据如果不等,hashCode()尽量不同
HashMap底层是一个Entry[ ]数组,当存放数据时,会根据hash算法来计算数据的存放位置
算法:hash(key)%n , n就是数组的长度,其实也就是集合的容量
当计算的位置没有数据的时候,会直接存放数据
当计算的位置,有数据时,会发生hash冲突/hash碰撞,解决的办法就是采用链表的结构,在数组中指定位置处已有元素之后插入新的元素,也就是说数组中的元素都是最早加入的节点
图解

若有收获,就点个赞吧
0 人点赞
