对于任何INSERT、DELETE、UPDATE、SELECT ... LOCK IN SHARE MODE、SELECT ... FOR UPDATE语句来说,InnoDB存储引擎都不会加表级别的S锁或者X锁(这里不讨论表级意向锁的添加),只会加行级锁。所以即使对于全表扫描的加锁读语句来说,也只会对表中的记录进行加锁,而不是直接加一个表锁。
为一个语句需要加什么锁受到很多方面的影响。我们分析的只是InnoDB加的事务锁,即为了避免脏写、脏读、不可重复读、幻读这些现象带来的一致性问题而加的锁,并不是为了在多线程访问共享内存区域时而加的锁(比方说两个不同事务所在的线程想读写同一个页面时,需要进行加锁保护),也不包括server层添加的MDL锁。
1.事务锁到底是什么
锁是一个内存结构,InnoDB中用lock_t这个结构来定义:
![MySQL[十九]InnoDB是怎么加锁的 - 图1](/uploads/projects/yinhuidong@mysql/fab69670221491cfcd9144e037abd89d.webp)
不论是行锁,还是表锁都用这个结构来表示。
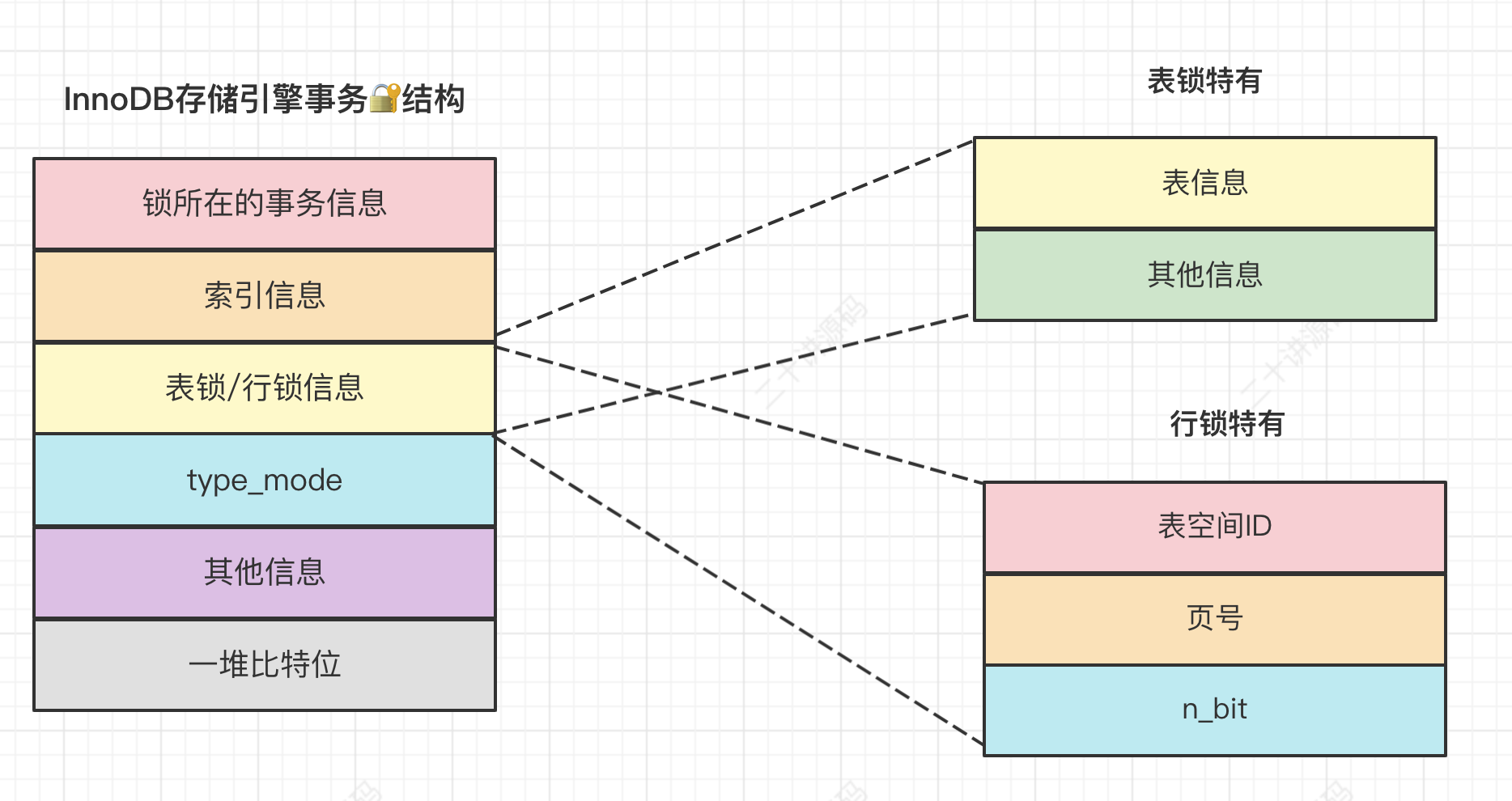
其中的type_mode是用于区分这个锁结构到底是行锁还是表锁,如果是表锁的话是意向锁、直接对表加锁、还是AUTO-INC锁,如果是行锁的话,具体是正经记录锁、gap锁还是next-key锁。
在InnoDB的实现中,InnoDB的行锁是与记录一一对应的。即使是对于gap锁来说,在实现上也是为某条记录生成一个锁结构,然后该锁结构的类型是gap锁而已,并不是专门为某个区间生成一个锁结构。该gap锁的功能就是每当有别的事务插入记录时,会检查一下待插入记录的下一条记录上是否已经有一个gap锁的锁结构,如果有的话就进入阻塞状态。
平时所说的加锁就是在内存中生成这样的一个锁结构(除了生成锁结构,还有一种称作隐式锁的加锁方式,不用生成锁结构)。当然,如果为1条记录加锁就要生成一个锁结构太浪费了!InnoDB提出了一种优化方案,即同一个事务,在同一个页面上加的相同类型的锁都放在同一个锁结构里。
2.准备工作
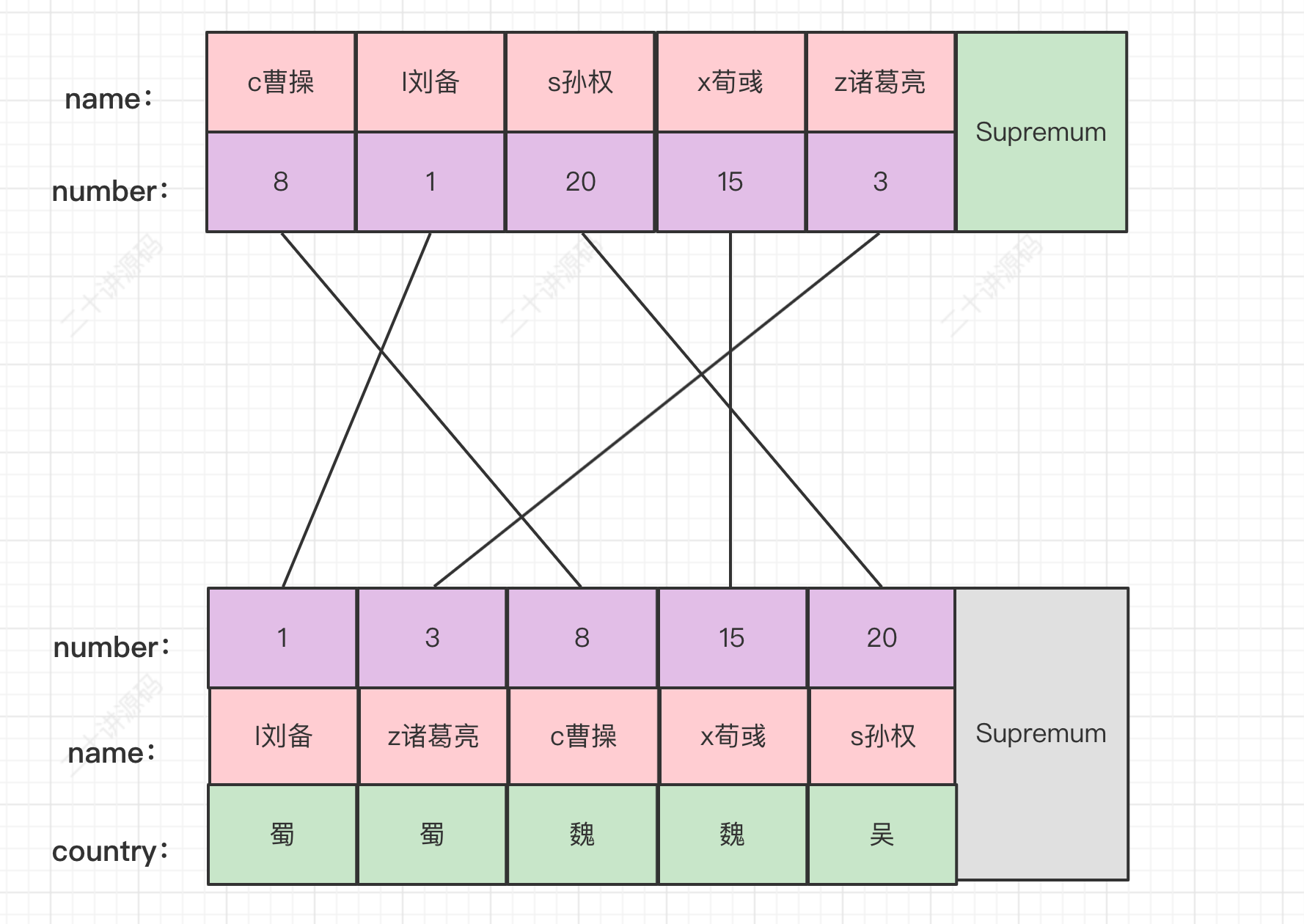
我们先创建一个表hero:
CREATE TABLE hero ( number INT, name VARCHAR(100), country varchar(100), PRIMARY KEY (number), KEY idx_name (name)) Engine=InnoDB CHARSET=utf8;
然后向这个表里插入几条记录:
INSERT INTO hero VALUES (1, 'l刘备', '蜀'), (3, 'z诸葛亮', '蜀'), (8, 'c曹操', '魏'), (15, 'x荀彧', '魏'), (20, 's孙权', '吴');
然后现在hero表就有了两个索引(一个二级索引,一个聚簇索引)。
3.加锁受哪些因素影响
一条语句加什么锁受多种因素影响。
- 事务的隔离级别
- 语句执行时使用的索引类型(比如聚簇索引、唯一二级索引、普通二级索引)
- 是否是精确匹配
- 是否是唯一性搜索
- 具体执行的语句类型(SELECT、INSERT、DELETE、UPDATE)
- 是否开启innodb_locks_unsafe_for_binlog系统变量
- 记录是否被标记删除
3.1扫描区间
比方说下边这个查询:
SELECT * FROM hero WHERE name <= 'l刘备' AND country = '魏';
MySQL可以使用下边两种方式来执行上述查询:
- 使用二级索引idx_name执行上述查询,那么就需要扫描name值在
(-∞, 'l刘备']这个区间中的所有二级索引记录,针对获取到的每一条二级索引记录,都需要执行回表操作来获取相应的聚簇索引记录。 - 直接扫描所有的聚簇索引记录,即进行全表扫描。此时相当于扫描number值在
(-∞, +∞)这个区间中的所有聚簇索引记录。
优化器会计算上述二种方式哪个成本更低,选用成本更低的那种来执行查询。
当优化器使用二级索引执行查询时,我们把(-∞, 'l刘备']称作扫描区间,意味着需要扫描name列值在这个区间中的所有二级索引记录,我们也可以把形成这个扫描区间的条件name <= 'l刘备'称作是形成这个扫描区间的边界条件;当优化器使用全表扫描执行查询时,我们把(-∞, +∞)称作扫描区间,意味着需要扫描number值在这个区间中的所有聚簇索引记录。
在执行一个查询的过程中,可能会用到多个扫描区间,如下所示:
SELECT * FROM hero WHERE name < 'l刘备' OR name > 'x荀彧';
如果优化器采用二级索引idx_name执行上述查询时,那么对应的扫描区间就是(-∞, l刘备)以及('x荀彧', +∞),即需要扫描name值在上述两个扫描区间中的记录。
每当InnoDB需要扫描一个扫描区间中的记录时,都需要分两步:
- 先通过索引对应的B+树,从根页面开始一路向下定位,直到定位到叶子节点中在扫描区间中的第一条记录。
- 之后就可以不需要继续从根节点定位了,而是通过记录的
next_record属性直接找到扫描区间的下一条记录即可(页面之间通过双向链表连接,找完一个页面中的记录后,可以顺着双向链表再去下一个页面中去找属于同一个扫描区间的记录)。
也就是说在扫描某个扫描区间的记录时,只有定位第1条记录的时候稍微麻烦点儿,其他记录只需要顺着链表(单个页面中的记录连成一个单向链表,不同的页面之间是双向链表)扫描即可。
3.2精确匹配
对于形成扫描区间的边界条件来说,如果是等值匹配的条件,我们就把对这个扫描区间的匹配模式称作精确匹配。比方说:
SELECT * FROM hero WHERE name = 'l刘备' AND country = '魏';
如果使用二级索引idx_name执行上述查询时,扫描区间就是['l刘备', 'l刘备'],形成这个扫描区间的边界条件就是name = 'l刘备'。我们就把在使用二级索引idx_name执行上述查询时的匹配模式称作精确匹配。
而对于下边这个查询来说显然就不是精确匹配了。
SELECT * FROM hero WHERE name <= 'l刘备' AND country = '魏';
3.3唯一性搜索
如果在扫描某个扫描区间的记录前,就能事先确定该扫描区间最多只包含1条记录的话,那么就把这种情况称作唯一性搜索。我们看一下代码中判定扫描某个扫描区间的记录是否是唯一性搜索的代码是怎么写的:
![MySQL[十九]InnoDB是怎么加锁的 - 图4](/uploads/projects/yinhuidong@mysql/d3924b43fbe5e4eb94808e27e48e46ad.webp)
其中:
- 匹配模式是精确匹配
- 使用的索引是聚簇索引或唯一二级索引
- 如果索引中包含多个列,则每个列在生成扫描区间时都应该被用到
- 如果使用的索引是唯一二级索引,那么在搜索时不能搜索某个索引列为NULL的记录(因为对于唯一二级索引来说,是可以存储多个值为NULL的记录的)。
上边几点都比较好理解,解释一下第3点。比方说我们为某个表的a、b两列建立了一个唯一二级索引uk_a_b(a, b),那么对于搜索条件a=1形成的扫描区间来说,不能保证该扫描区间最多只包含一条记录;对于搜索条件a=1 AND b= 1形成的扫描区间来说,才可以保证该扫描区间中仅包含1条记录(不包括记录的delete_flag=1的记录)。
4.row_search_mvcc
MySQL其实是分成server层和存储引擎层两部分,每当执行一个查询时,server层负责生成执行计划,即选取即将使用的索引以及对应的扫描区间。这里以InnoDB为例,针对每一个扫描区间,都会:
- server层向InnoDB要扫描区间的第1条记录
- InnoDB通过B+树定位到扫描区间的第1条记录(如果定位的是二级索引记录并有回表需求则回表获取完整的聚簇索引记录),然后返回给server层
- server层判断记录是否符合搜索条件,如果符合则发送给客户端,不符合则跳过。继续向InnoDB要下一条记录。
此处将记录发送给客户端其实是发送到本地的网络缓冲区,缓冲区大小由net_buffer_length控制,默认是16KB大小。等缓冲区满了才真正发送网络包到客户端。
- InnoDB根据记录的单向链表以及页面之间的双向链表找到下一条记录(如果定位的是二级索引记录并有回表需求则回表获取完整的聚簇索引记录),返回给server层。
- server层处理该记录,并向InnoDB要下一条记录
- 不停执行上述过程,直到InnoDB读到一条不符合边界条件的记录为止
可见一般情况下,server层和存储引擎层是以记录为单位进行通信的,而InnoDB读取一条记录最重要的函数就是row_search_mvcc:
![MySQL[十九]InnoDB是怎么加锁的 - 图5](/uploads/projects/yinhuidong@mysql/c61b7926445405fe53d19436d3a7c2ba.png)
在row_search_mvcc里,对一条记录进行诸如多版本的可见性判断,要不要对记录进行加锁的判断,要是加锁的话加什么锁的选择,完成记录从InnoDB的存储格式到server层存储格式的转换等等十分繁杂的工作。
其实对于UPDATE、DELETE语句来说,执行它们前都需要先在B+树中定位到相应的记录,所以它们也会调用row_search_mvcc。
InnoDB对记录的加锁操作主要是在row_search_mvcc中的,像SELECT ... LOCK IN SHARE MODE、SELECT ... FOR UPDATE、UPDATE、DELETE这样的语句都会调用row_search_mvcc完成加锁操作。SELECT ... LOCK IN SHARE MODE会为记录添加S型锁,SELECT ... FOR UPDATE、UPDATE、DELETE会为记录添加X型锁。
InnoDB每当读取一条记录时,都会调用一次row_search_mvcc,在做了足够长的铺垫之后,我们看一下在row_search_mvcc函数中是怎么对某条记录进行加锁的。
5.语句到底是怎么加锁的
首先看一个十分重要的变量:
![MySQL[十九]InnoDB是怎么加锁的 - 图6](/uploads/projects/yinhuidong@mysql/5ed0f862cb27df55781eb49532a8f562.webp)
set_also_gap_locks表示是否要给记录添加gap锁(next-key锁可以看成是正经记录锁和gap锁的组合),它的默认值是TRUE,表示默认会给记录添加gap锁。
set_also_gap_locks可能会在下边这个地方发生变化:
![MySQL[十九]InnoDB是怎么加锁的 - 图7](/uploads/projects/yinhuidong@mysql/c7fdff1a07bfcbd3ecfd32271d1f8c02.webp)
即如果当前执行的是SELECT … LOCK IN SHARE MODE或者SELECT … FOR UPDATE这样的加锁读语句(非DELETE或UPDATE语句),并且隔离级别不大于READ COMMITTED 时,将set_also_gap_locks设置为FALSE。
其中prebuilt->select_lock_type表示加锁的类型,LOCK_NONE表示不加锁,LOCK_S表示加S锁(比方说执行SELECT … LOCK IN SHARE MODE时),LOCK_X表示加X锁(比方说执行SELECT … FOR UPDATE、DELETE、UPDATE时)。
0.对普通的SELECT的处理和意向锁的添加
再往后看:
![MySQL[十九]InnoDB是怎么加锁的 - 图8](/uploads/projects/yinhuidong@mysql/f0b1024b7d54c6946b3a2a8b1826cdc7.webp)
其中:
- 标号1的箭头是对普通的SELECT的处理,在查询开启前需要生成ReadView。
具体的讲就是对于Repeatable Read隔离级别来说,只在首次执行SELECT语句时生成Readview,之后的SELECT语句都复用这个ReadView;对于Read Committed隔离级别来说,每次执行SELECT语句时都会生成一个ReadView。这一点并不是在上边截图中的代码里实现的。
- 标号2的箭头是对加锁读的语句的处理,在首次读取记录(prebuilt->sql_stat_start表示是否是首次读取)前,需要添加表级别的意向锁(IS或IX锁)。
下边是真正处理记录并给记录加锁的流程,我们给这些流程编个号。
1. 定位扫描区间的第一条记录
下边开始通过B+树定位某个扫描区间中的第一条记录了(对于一个扫描区间来说,只执行一次下述函数,因为只要定位到扫描区间的第一条记录之后,就可以沿着记录所在的单向链表进行查询了):
![MySQL[十九]InnoDB是怎么加锁的 - 图9](/uploads/projects/yinhuidong@mysql/aca85b330daec670e183c3095524f53f.png)
其中btr_pcur_open_with_no_init是用于定位扫描区间中的第一条记录的函数。
2. 对于ORDER BY … DESC条件形成的扫描区间的第一条记录的处理
在B+树的每层节点中,记录是按照键值从小到大的方式进行排序的。对于某个扫描区间来说,InnoDB通常是定位到扫描区间中最左边的那条记录,也就是键值最小的那条记录,然后沿着从左往右的方式向后扫描。
但是对于下边这个查询来说:
SELECT * FROM hero WHERE name < 's孙权' AND country = '魏' ORDER BY name DESC FOR UPDATE ;
如果优化器决定使用二级索引idx_name执行上述查询的话,那么对应的扫描区间就是(-∞, 's孙权')。由于上述查询要求记录是按照从大到小的顺序返回给用户,所以InnoDB定位到扫描区间中的第一条记录应该是该扫描区间中最右边的那条记录,也就是键值最大的那条记录(在执行btr_pcur_open_with_no_init时就定位到最右边的那条记录),我们看一下idx_name二级索引示意图:
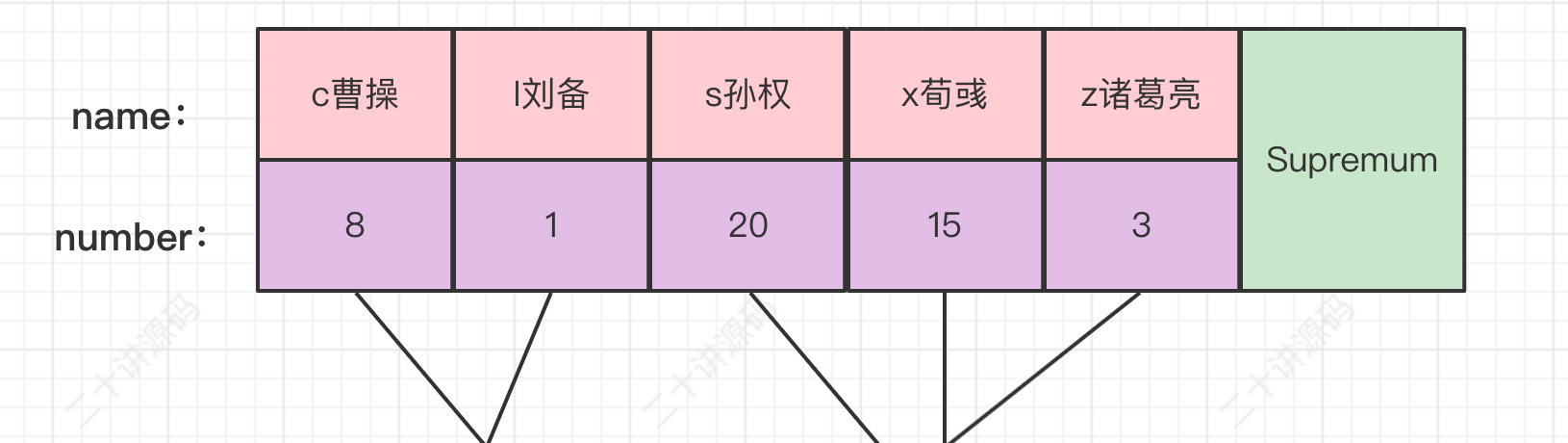
很显然,name值为'l刘备'的二级索引记录是扫描区间(-∞, 's孙权')中最右边的记录。
对于从右向左扫描扫描区间中记录的情况,针对从扫描区间中定位到的最右边的那条记录,需要做如下处理:
![MySQL[十九]InnoDB是怎么加锁的 - 图11](/uploads/projects/yinhuidong@mysql/8502af136c039fe78805b1ae0ef259cf.webp)
其中sel_set_rec_lock就是对一条记录进行加锁的函数。
可以看到,对于加锁读来说,在隔离级别不小于REPEATABLE READ并且也没有开启innodb_locks_unsafe_for_binlog系统变量的情况下,会对扫描区间中最右边的那条记录的下一条记录加一个类型为LOCK_GAP的锁,这个类型为LOCK_GAP的锁其实就是gap锁。
在本例中,假设事务的隔离级别是REPATABLE READ。扫描区间(-∞, 's孙权')中最右边的那条记录就是name值为'l刘备'的二级索引记录,接下来就应该为该记录的下一条记录,也就是name值为's孙权'的二级索引记录加一个gap锁。
其实这样加锁主要是为了阻止幻读。另外,这一步骤的加锁仅仅针对从右向左的扫描区间中的最右边的那条记录,之后扫描该扫描区间中的其他记录时就不做这一步的操作了。
3. 对Infimum和Supremum记录的处理
步骤1是用来定位扫描区间中的第一条记录,针对一个扫描区间只执行1次。
步骤2是针对从右向左扫描的扫描区间中最右边的那条记录的下一条记录进行加锁,针对一个扫描区间也执行1次。
从第3步骤开始以及往后的步骤,扫描区间中的每一条记录都要经历。
先看一下如果当前记录是Infimum记录或者Supremum记录时的处理:
![MySQL[十九]InnoDB是怎么加锁的 - 图12](/uploads/projects/yinhuidong@mysql/8998d92d79f2cbfa5be3a80da5a64568.webp)
从上边的代码中可以看出,如果当前读取的记录是Infimum记录,则啥也不做,直接去读下一条记录。
如果当前读取的记录是Supremum记录,则在下边这些条件成立的时候就会为记录添加一个类型为LOCK_ORDINARY的锁,其实也就是next-key锁:
- set_also_gap_locks是TRUE(这个变量只在前边设置过,当隔离级别不大于READ COMMITTED的SELECT语句的加锁读会设置为FALSE,否则为TRUE)
- 未开启
innodb_locks_unsafe_for_binlog系统变量并且事务的隔离级别不小于REPEATABLE READ。 - 本次读取属于加锁读
- 所使用的不是空间索引。
其实由于Supremum记录本身是一条伪记录,别的事务并不会更新或删除它,所以给它添加next-key锁起到的效果和给它添加gap锁是一样的。
Infimum记录和Supremum记录是InnoDB自动为B+树中的每个页面都添加的两条虚拟记录,也可以被称作伪记录。Infimum记录和Supremum记录分别占用13字节的存储空间,被放置在页面中固定的位置。其中Infimum记录被看作最小的记录,Supremum记录被看作最大的记录,Infimum记录属于页面中的记录单向链表的头节点,Supremum记录属于页面中的记录单向链表的尾节点。
4. 对精确匹配的特殊处理
如果当前记录不是Infimum记录或者Supremum记录,下边进入对匹配模式是精确匹配的一个特殊处理:
![MySQL[十九]InnoDB是怎么加锁的 - 图13](/uploads/projects/yinhuidong@mysql/4f3a17d07f658ed4e5016c5dff8d4656.webp)
可以看到,对于匹配模式是精确匹配的扫描区间来说,如果执行本次row_search_mvcc获取到的记录不在扫描区间中(0 != cmp_dtuple_rec(search_tuple, rec, offsets)),则需要进行一些特殊处理,即:
对于加锁读来说,如果事务的隔离级别不小于Repeatable Read并且未开启innodb_locks_unsafe_for_binlog系统变量,那么就对该记录加一个gap锁,并且直接返回(代码中直接跳转到normal_return处),就不进行后续的加锁操作了。
我们举一个例子,比方说当前事务的隔离级别为Repeatable Read,执行如下语句:
SELECT * FROM hero WHERE name = 's孙权' FOR UPDATE;
如果使用二级索引idx_name执行上述查询,那么对应的扫描区间就是['s孙权', 's孙权']。该语句会首先对name值是's孙权'的记录进行加锁,不过该记录是在扫描区间中的,上述代码并不处理这种正常情况,关于正常情况的加锁我们稍后分析。
当读取完's孙权'的记录后,InnoDB会根据记录的next_record属性找到下一条二级索引记录,即name值为'x荀彧'的二级索引记录,该记录不在扫描区间['s孙权', 's孙权']中,即符合 0 != cmp_dtuple_rec(search_tuple, rec, offsets)条件,那么就执行上述代码的加锁流程 —— 对name值为'x荀彧'的二级索引记录加一个gap锁。另外,err被赋值为DB_RECORD_NOT_FOUND,这意味着向server层报告当前扫描区间的记录都已经扫描完了,server层在收到这个信息后就会停止向Innodb索要下一条记录的请求,即结束本扫描区间的查询。
这一步骤是对精确匹配的扫描区间的一个特殊处理,即当server层收到InnoDB返回的扫描区间的最后一条记录,server层仍会向InnoDB索要下一条记录。InnoDB仍会沿着记录所在的链表向后读取,此次读取到的记录就不在扫描区间中了,如例子中的name值为’x荀彧’的二级索引记录就不在扫描区间[‘s孙权’, ‘s孙权’]中。如果这是一个精确匹配的扫描区间,那么就进行如步骤4所示的特殊处理,如果不是的话,就继续执行第5步,也就是走正常的加锁流程。
5. 真正的加锁流程
![MySQL[十九]InnoDB是怎么加锁的 - 图14](/uploads/projects/yinhuidong@mysql/ab4fcab11f21b85f913005dbdeaa4ba5.webp)
我们在代码中画了2个红框,这两个红框是对记录是不对记录加gap锁的场景。
对于1号红框来说:
- set_also_gap_locks是FALSE(这个变量只在前边设置过,当隔离级别不大于READ COMMITTED的SELECT语句的加锁读会设置为FALSE,否则为TRUE)
- 开启
innodb_locks_unsafe_for_binlog系统变量 - 事务的隔离级别不大于READ COMMITTED
- 唯一性搜索并且该记录的delete_flag不为1
- 该索引是空间索引
也就是说只要上边任意一个条件成立,该记录就不应该被加gap锁,而应该添加正经记录锁。其余情况就应该加next-key锁(gap锁和正经记录锁的合体)了。
紧接着2号红框就又叙述了一个不加gap锁的场景:
对于**>= 主键**的这种边界条件来说,如果当前记录恰好是开始边界,就仅需对该记录加正经记录锁,而不需添加gap锁。
1号红框的内容比较好理解,我们举个例子看一下2号红框是在说什么。比方说下边这个查询:
SELCT * FROM hero WHERE number >= 8 FOR UPDATE;
我们假设这个语句在隔离级别为REPEATABLE READ。
很显然,优化器会扫描[8, +∞)的聚簇索引记录。首先要通过B+树定位到扫描区间[8, +∞)的第一条记录,也就是number值为8的聚簇索引记录,这条记录就是扫描区间[8, +∞)的开始边界记录。按理说在REPEATABLE READ隔离级别下应该添加next-key锁,但由于2号红框中代码的存在,仅会给number值为8的聚簇索引记录添加正经记录锁。
2号方框的优化主要是基于“主键值是唯一的”这条约束,在一个事务执行了上述查询之后,其他事务是不能插入number值为8的记录的,这也用不着gap锁了。
除了1号方框和2号方框的场景,其余场景都给记录加next-key锁。
6. 判断索引条件下推的条件是否成立
如果是使用二级索引执行查询,并且有索引条件下推(Index Condition Pushdown,简称ICP)的条件的话,判断下推的条件是否成立:
![MySQL[十九]InnoDB是怎么加锁的 - 图15](/uploads/projects/yinhuidong@mysql/a1ceb6c6dffe85057171a024d1d230f3.webp)
在使用二级索引执行查询,对于非精确匹配的扫描区间来说,形成扫描区间的边界条件也会被当作ICP条件下推到存储引擎判断,比方说下边这个查询:
mysql> EXPLAIN SELECT * FROM hero WHERE name > 's孙权' AND name < 'z诸葛亮' FOR UPDATE;+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+| 1 | SIMPLE | hero | NULL | range | idx_name | idx_name | 303 | NULL | 1 | 100.00 | Using index condition |+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+1 row in set, 1 warning (0.03 sec)
可以看到优化器决定使用idx_name执行上述查询,对应的扫描区间就是('s孙权', 'z诸葛亮'),形成这个扫描区间的边界条件就是name > 's孙权' AND name < 'z诸葛亮'。在执行计划的Extra列中出现了Using index condition,表明将边界条件name > 's孙权' AND name < 'z诸葛亮'作为ICP条件下推到了存储引擎。
不下推不要紧,一下推的话row_search_idx_cond_check就会判断当前记录是否已经不在扫描区间中了,如果不在扫描区间中的话,该函数就会返回ICP_OUT_OF_RANGE。这样的话,err被赋值为DB_RECORD_NOT_FOUND,这意味着向server层报告当前扫描区间的记录都已经扫描完了,server层在收到这个信息后就会停止向Innodb索要下一条记录的请求,即结束本扫描区间的查询。
当然,如果本次查询没有ICP条件,row_search_idx_cond_check直接返回ICP_MATCH,那就没有上述的麻烦事儿,继续向下走。
7. 回表对记录加锁
如果row_search_mvcc读取的是二级索引记录,则还需进行回表,找到相应的聚簇索引记录后需对该聚簇索引记录加一个正经记录锁:
![MySQL[十九]InnoDB是怎么加锁的 - 图16](/uploads/projects/yinhuidong@mysql/f3212f35348d711736b09844f2f4c3ac.webp)
其中,row_sel_get_clust_rec_for_mysql便是用于回表的函数。
注意,即使是对于覆盖索引的场景下,如果我们想对记录加X型锁(也就是使用SELECT … FOR UPDATE、DELETE、UPDATE语句时)时,也需要对二级索引记录执行回表操作,并给相应的聚簇索引记录添加正经记录锁。
![MySQL[十九]InnoDB是怎么加锁的 - 图17](/uploads/projects/yinhuidong@mysql/0cfdfd69d8020f77a93c739ecd39663a.webp)
8. row_search_mvcc返回,判断是否已经到达边界
每当处理完一条记录后,还需要判断一下这条记录还在不在扫描区间中,如果当前记录还在扫描区间中,就给server层正常返回,如果不在了,就给server层返回一个HA_ERR_END_OF_FILE信息,表示当前扫描区间的记录都已经扫描完了,server层在收到这个信息后就会停止向Innodb索要下一条记录的请求,即结束本扫描区间的查询。
之前在处理精确匹配以及ICP条件时可能把err变量赋值为DB_RECORD_NOT_FOUND,其实后续代码会将这种情况也转换为给server层返回HA_ERR_END_OF_FILE信息。
9. 处理下一条记录
server层收到InnoDB的一条记录后,如果收到InnoDB通知的本扫描区间已经扫描完毕的信息,则结束本扫描区间的查询;否则继续向InnoDB要下一条记录,也就是需要继续执行一遍row_search_mvcc函数了。
不过此时并不是定位扫描区间中的第一条记录,而是根据记录所在的链表去取下一条记录即可,所以直接从步骤3开始执行就好了,又开始了新的一条记录的加锁流程。。。
循环往复,直到server层收到本扫描区间所有记录都扫描完了的信息为止。
6.一些释放锁的场景
在步骤8判断当前记录是否已经不再扫描区间中时可以看到,如果当前记录不在扫描区间中,会执行一个unlock_row的函数,这个函数主要是用于在隔离级别不大于READ COMMITTED时释放当前记录上的锁(如果是二级索引记录还要释放相应的聚簇索引记录上的锁)。
释放锁的场景并不是只有这么一个,在row_search_mvcc中也有几处释放锁的场景。
7.总结
其实回头看row_search_mvcc里的关于加锁的代码就会发现,其实流程还是很简单的:
- 定位扫描区间的第一条记录。
- 如果扫描区间是从右到左扫描,那么需要给扫描区间最右边的记录的下一条记录添加一个gap锁(在隔离级别不小于
REPEATABLE READ并且也没有开启innodb_locks_unsafe_for_binlog系统变量的情况下)。 - 对于
Infimum记录是不加锁的,对于Supremum记录加next-key锁(在隔离级别不小于REPEATABLE READ并且也没有开启innodb_locks_unsafe_for_binlog系统变量的情况下)。 - 对于精确匹配的扫描区间来说,当扫描区间中的记录都被读完后,需对扫描区间后的第一条记录加一个gap锁即可,并且向server层返回可结束本扫描区间的查询的信息(在隔离级别不小于
REPEATABLE READ并且也没有开启innodb_locks_unsafe_for_binlog系统变量的情况下)。 - 事务的隔离级别不大于READ COMMITTED,开启
innodb_locks_unsafe_for_binlog系统变量,唯一性搜索并且该记录的delete_flag不为1,对于>= 主键的这种边界条件来说,当前记录恰好是开始边界记录,则对记录加正经记录锁,否则添加next-key锁。 - 判断ICP条件是否成立。如果当前记录是二级索引记录,并且已经不在扫描区间中,则向server层返回可结束本扫描区间的查询的信息。
- 如果对二级索引记录进行加锁,还需要对相应的聚簇索引记录加
正经记录锁(使用覆盖索引,并且加S型锁的记录可跳过此步骤)。 - 判断当前记录是否已不在扫描区间中,如果不在的话,则向server返回可结束本扫描区间的查询的信息。
- 如果server层收到可结束本扫描区间的查询的信息,则结束本扫描区间的查询,否则继续向InnoDB要下一条记录,InnoDB根据记录所在的链表获取到下一条记录后,从
步骤3开始新一轮的轮回。
到现在为止解释清楚了为什么最开始说的即使是全表扫描的加锁读,加的也是行锁而不是表锁了。在使用InnoDB存储引擎时,当进行全表扫描时,其实就是相当于扫描主键值在(-∞, +∞)这个扫描区间中的聚簇索引记录,针对每一条聚簇索引记录,都需要执行一次row_search_mvcc函数,都需要进行如上所述的各种判断,最后决定给扫描的记录加什么锁。

若有收获,就点个赞吧
0 人点赞
