COUNT函数的参数可以是任意表达式,该函数用于统计在符合搜索条件的记录中,指定的表达式不为NULL的行数有多少。
1.MySQL中COUNT是怎样执行的
以下边这个语句为例:
SELECT COUNT(*) FROM t;
这个语句是要去查询表t中共包含多少条记录。由于聚簇索引和二级索引中的记录是一一对应的,而二级索引记录中包含的列是少于聚簇索引记录的,所以同样数量的二级索引记录可以比聚簇索引记录占用更少的存储空间。如果我们使用二级索引执行上述查询,即数一下idx_key1中共有多少条二级索引记录,是比直接数聚簇索引中共有多少聚簇索引记录可以节省很多I/O成本。所以优化器会决定使用idx_key1执行上述查询:

在执行上述查询时,server层会维护一个名叫count的变量,然后:
- server层向InnoDB要第一条记录。
- InnoDB找到idx_key1的第一条二级索引记录,并返回给server层(注意:由于此时只是统计记录数量,所以并不需要回表)。
- 由于COUNT函数的参数是
*,MySQL会将*当作常数0处理。由于0并不是NULL,server层给count变量加1。 - server层向InnoDB要下一条记录。
- InnoDB通过二级索引记录的next_record属性找到下一条二级索引记录,并返回给server层。
- server层继续给count变量加1。
- … 重复上述过程,直到InnoDB向server层返回没记录可查的消息。
- server层将最终的count变量的值发送到客户端。
我们看一下源码里给count变量加1的代码是怎么写的:
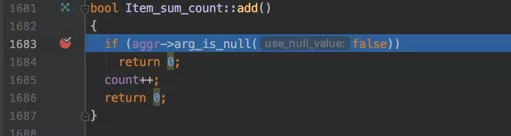
其大意就是判断一下COUNT里的表达式是不是NULL,如果不是NULL的话就给count变量加1。
我们再来看一下arg_is_null的实现:
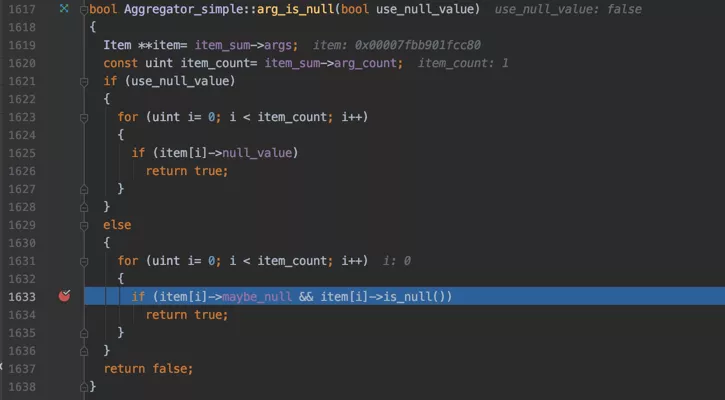
其中最重要的是我们标蓝的那一行,item[i]表示的就是COUNT函数中的参数,我们调试一下对于COUNT(*)来说,表达式*的值是什么:

可以看到,*表达式的类型其实是Item_int,这表示MySQL其实会把*当作一个整数处理,它的值是0(见图中箭头)。也就是说我们在判断表达式*是不是为NULL,也就是在判断整数0是不是为NULL,很显然不为NULL。
2.COUNT(1),COUNT(id),COUNT(非主键列)
那在执行COUNT(1)呢?比方说下边这个语句:
SELECT COUNT(1) FROM t;
我们看一下:

可以看到,常数1对应的类型其实是PTI_num_literal_num,它其实是Item_int的一个包装类型,本质上还是代表一个整数,它的值是1(见图中箭头)。也就是说我们其实是在判断表达式1是不是为NULL,很显然不为NULL。
再看一下COUNT(id):
SELECT COUNT(id) FROM t;
我们看一下:
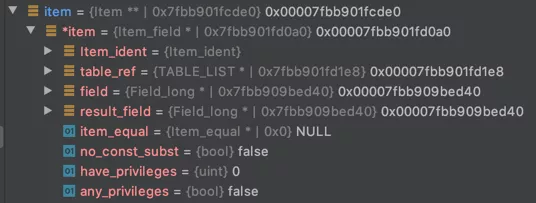
可以看到,id对应的类型是Item_field,代表一个字段。
对于COUNT(*)、COUNT(1)或者任意的COUNT(常数)来说,读取哪个索引的记录其实并不重要,因为server层只关心存储引擎是否读到了记录,而并不需要从记录中提取指定的字段来判断是否为NULL。所以优化器会使用占用存储空间最小的那个索引来执行查询。
对于COUNT(id)来说,由于id是主键,不论是聚簇索引记录,还是任意一个二级索引记录中都会包含主键字段,所以其实读取任意一个索引中的记录都可以获取到id字段,此时优化器也会选择占用存储空间最小的那个索引来执行查询。
而对于COUNT(非主键列)来说,我们指定的列可能并不会包含在每一个索引中。这样优化器只能选择包含我们指定的列的索引去执行查询,这就可能导致优化器选择的索引并不是最小的那个。
3.总结
对于COUNT(*)、COUNT(常数)、COUNT(主键)形式的COUNT函数来说,优化器可以选择最小的索引执行查询,从而提升效率,它们的执行过程是一样的,只不过在判断表达式是否为NULL时选择不同的判断方式,这个判断为NULL的过程的代价可以忽略不计,所以我们可以认为COUNT(*)、COUNT(常数)、COUNT(主键)所需要的代价是相同的。
而对于COUNT(非主键列)来说,server层必须要从InnoDB中读到包含非主键列的记录,所以优化器并不能随心所欲的选择最小的索引去执行。
4.优化
InnoDB的记录都是存储在数据页中的(页面大小默认为16KB),而每个数据页的Page Header部分都有一个统计当前页面中记录数量的属性PAGE_N_RECS。那么在执行COUNT函数的时候直接去把各个页面的这个PAGE_N_RECS属性加起来不就好了么?
答案是:WRONG!对于普通的SELECT语句来说,每次查询都要从记录的版本链上找到可见的版本才算是读到了记录;对于加了FOR UPDATE或LOCK IN SHARE MODE后缀的SELECT语句来说,每次查询都要给记录添加合适的锁。所以这个读取每一条记录的过程(就是上边给出的row_search_mvcc函数)在InnoDB的目前实现中是无法跳过的,InnoDB还是得读一条记录,返给server层一条记录。
如果我的业务中有COUNT需求,但是由于数据量太大导致即使优化器即使通过扫描二级索引记录的方式也还是太慢怎么办?既然业务上有需求,我们可以在另一个地方存储一份待统计数据的行数,每次增删改记录都维护一下。

若有收获,就点个赞吧
0 人点赞
