数据管道
通常有两种使用场景:
- 作为数据管道的两个端点之一(例如把 Kafka 里的数据移动到 S3 上,或者把 MongoDB 里的数据移动到 Kafka 里)
- 作为数据管道两个端点的中间媒介(例如为了把 Twitter 的数据移动到 ElasticSearch 上,需要先把它们移动到 Kafka 里,再将它们从 Kafka 移动到 ElasticSearch 上)
主要意义在于构建各个数据段之间的大型缓冲区,解耦数据生产者和消费者。
数据存储
介绍一下,不常用
流式处理
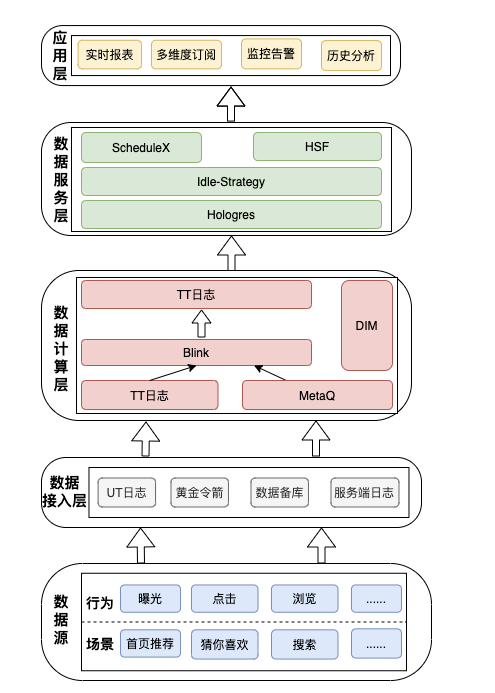
主要展示流式处理在系统中所处的位置
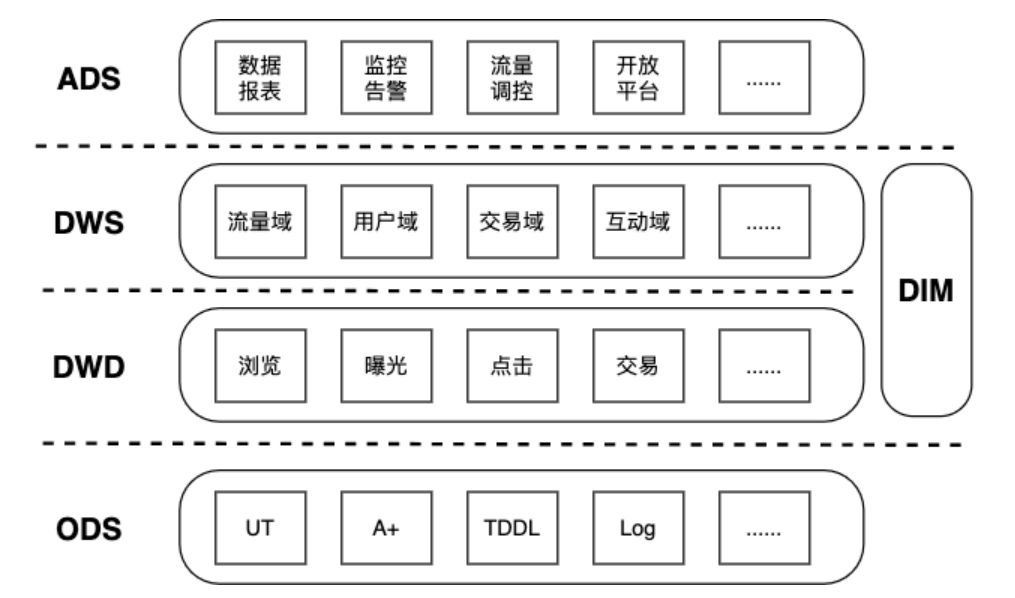
- ODS(Operational Data Store): 贴源层
- 这一层又叫做贴源层,最为接近数据源的一层,需要存储的数据量是最大的,存储的数据也是最原始。对众多数据源而言,他们的数据格式基本不一致,经过统一规格化后可以得到规整的数据,将数据源中的数据经过抽取、清洗、传输后装入ODS层。
- DWD(Data Warehouse Detail):数据明细层
- 业务层与数据仓库的隔离层,主要对ODS层做一些数据清洗和规范化的操作,并且可以按照不同的行为维度对数据进行划分,例如本文对数据源就进行了划分,主要分为浏览、曝光、点击、交易等不同的维度,这些不同的维度能够对上层调用方提供更细粒度的数据服务。
- DWS(Data WareHouse Servce):数据服务层
- 对各个域进行了适度汇总,主要以数据域+业务域的理念建设公共汇总层,与离线数仓不同的是,实时数仓的汇总层分为轻度汇总层和高度汇总层,例如将轻度汇总层数据写入 ADS,用于前端产品复杂的OLAP查询场景,满足自助分析和产出报表的需求。
- ADS(Application Data Store):应用数据服务层
- 主要是为了具体需求而构建的应用层,通过 RPC 框架对外提供服务,例如本文中提到的数据报表分析与展示、监控告警、流量调控、开放平台等应用。
- DIM(Dimension):维表
- 在实时计算中非常重要,也是重点维护的部分,维表需要实时更新,且下游基于最新的维表进行计算,例如闲鱼的实时数仓维表会用到闲鱼商品表、闲鱼用户表、人群表、场景表、分桶表等。
扩展参考
闲鱼大规模实时数仓搭建实践
知乎提问:有了kafka+流处理框架,为什么还需要时序数据库
这个问题问的很好。抽象来看,消息队列与时序数据库没有本质的区别,都是对时间序列数据的处理。但功能上,时序数据库要有查询、计算,而消息队列只是简单的生产、消费,先进先出。由于要有计算、分析,无论是结构化写入还是schemaless写入,时序数据库内部一定要把数据结构化处理,否则没法进行计算和分析的。而消息队列完全不用考虑这个,完全做非结构化数据处理就行。从存储设计的角度来看,两者是没有区别的,都需要有数据的保留策略,都需要对数据进行分区分片。一个时间线的ID可以作为kafka来的key, 对数据指定partition. 两者正在融合,开源的TDengine就是这样的,它不仅是时序数据库,但同时又具备消息队列的功能。这样在大数据框架下,就能减少一个环节,降低系统复杂度,降低运维成本。Kafka的企业版也在做类似的事情,除消息队列功能外,对外还提供SQL查询,提供各种分析计算功能。 更进一步,流式计算也可以融合进来。流式计算也是基于时序数据的,因此TDengine从设计的第一天起,就考虑了流式计算,但目前还仅仅提供时间驱动的流式计算,后续版本会提供基于事件驱动的流式计算。这样对于物联网、车联网、IT运维等场景,系统架构将更进一步简化,运维成本进一步降低。

若有收获,就点个赞吧
0 人点赞
