@Author: Basil Guo
@Date: Jan. 27, 2021
@Description: SQL基础内容
@Keyword: Database, SQL
@Type: tutorial
1. 简介
SQL,Structured Query Language,结构化查询语言。定义了操作所有关系型数据库的规则。不同的数据库操作方式存在一些不同的地方,称之为“方言”。
通用格式,可单行或多行书写,以分号结尾。使用空格或者缩进来增强语句的可读性。不区分大小写,建议语句使用大写。
注释:
- 单行注释:
-- Comment,# Comment,后一种是MySQL的方言。尽量使用第一种; - 多行注释:
/* Comment */
2. SQL语句
- DDL(Data Definition Language)数据定义语言,用来操作数据库和表的;
- DML(Data Modify Language)增删改表中的数据;
- DQL(Data Query Language)查询表中的数据;
- DCL(Data Control Language)授权用户操作。
2.1 DDL:操作数据库和表
主要就是CRUD: Create、Retrieve、Update、Delete。
2.1.1 数据库
Create(创建)
CREATE DATABASE db1;CREATE DATABASE IF NOT EXISTS db1; -- 不存在才创建CREATE DATABASE db2 CHARACTER SET GBK; -- 指定字符集CREATE DATABASE IF NOT EXISTS db3 CHARACTER SET GBK; -- 综合使用
Retrieve(查询)
- 查询所有数据库名称
SHOW DATABASES;+--------------------+| Database |+--------------------+| information_schema | -- 视图,没有实体| mysql | --| performance_schema | -- 性能相关| sys |+--------------------+4 rows in set (0.01 sec)
- 查询所有数据库名称
1. 查看某个数据库的创建语句,包含字符集```mysqlSHOW CREATE DATABASE mysql;+----------+----------------------------------------------------------------------------------------------+| Database | Create Database |+----------+----------------------------------------------------------------------------------------------+| mysql | CREATE DATABASE `mysql` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci */ |+----------+----------------------------------------------------------------------------------------------+
Update(修改)
修改数据库的字符集,注意这里的字符集是utf8。ALTER DATABASE db2 CHARACTER SET UTF8;
Delete(删除)
DROP DATABASE db3;DROP DATABASE IF EXISTS db3; -- 存在才删除库
使用数据库
SELECT database(); -- 正在使用的数据库USE mysql; -- 切换数据库
2.1.2 表
- Create(创建)
- 创建表
表的列字段可以设置默认值,使用default关键字。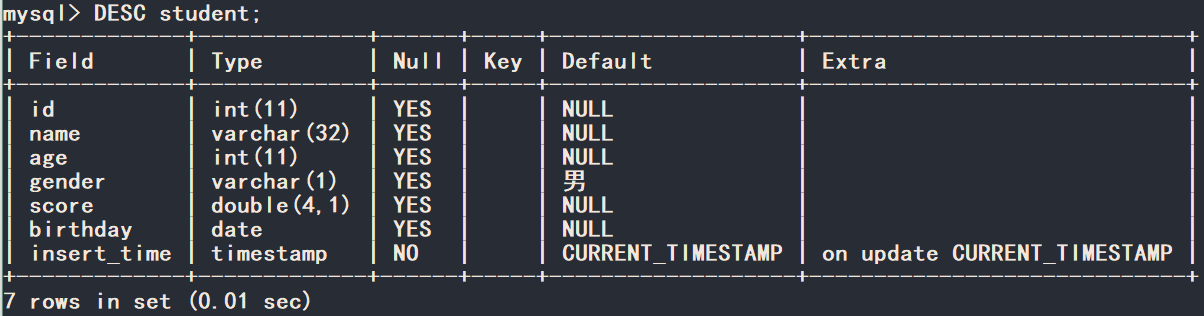 ```mysql
CREATE TABLE
```mysql
CREATE TABLE ( , , … — 这里不要有逗号, );
- 创建表
CREATE TABLE student ( id INT, name VARCHAR(32), age INT, gender VARCHAR(1) DEFAULT ‘男’, score DOUBLE(4,1), birthday DATE, insert_time TIMESTAMP );
2. 复制表```mysqlCREATE TABLE stu LIKE student; -- 创建一个类似student的表stu,其实是复制
Retrieve(查询)
SHOW TABLES; -- 需要先使用一个数据库DESC <tablename> -- 查看表结构
Update(修改)
修改表名
ALTER TABLE <tablename> RENAME TO <new_tablename>;
修改表的字符集
SHOW CREATE TABLE <tablename>; -- 查看,保存查看字符集ALTER TABLE <tablename> CHARACTER SET <character_set>;
添加列
ALTER TABLE <tablename> ADD <column_name> <data_type>;
修改列名称 类型
```mysql — 直接修改列名称和列类型 ALTER TABLECHANGE ;
— 只修改列类型
ALTER TABLE
5. 删除列```mysqlALTER TABLE <tablename> DROP <column_name>;
- Delete(删除)
DROP TABLE <tablename>;DROP TABLE <tablename> IF EXISTS;
2.2 DML:增删改表中的数据
2.2.1 添加数据
INSERT INTO <tablename>(column1, column2, ..., columnN) VALUES(value1, value2, ..., valueN);
注意:
- 列名需要和值一一对应;
- 如果表名后不定义列名,则默认给所有列添加值,建议都写明;
- 除了数字类型,其它类型需要使用引号起来,不区分单引号和双引号,如时间。
INSERT INTO <tablename> VALUES(value1, value2, ..., valueN);
2.2.2 删除数据
TRUNCATE TABLE <tablename>; -- 删除所有数据DELETE FROM <tablename> [WHERE <condition_expressions>];
注意:
- 如果不添加where条件,则会删除表中所有记录;
- 删除所有记录最好使用
TRUNCATE,DELETE的形式是有多少条记录就会执行多少次,而TRUNCATE则是先删除表,然后创建表,效率高。
2.2.3 修改数据
UPDATE <tablename> SET column1=value1, column2=value2, ..., columnN=valueN [WHERE <condition_expressions>];
注意
- 如果不添加where条件,则会修改表中所有记录;
2.3 DQL:查询表中的数据
SELECT<column1>[, column2, ...]FROM<table1>[, <table2>, ...]WHERE<condition_expressions>GROUP BY<column1>[, column2, ...]HAVING<condition_expressions>ORDER BY<column1> [ASC|DESC]LIMIT<start_index>, <items_per_page>;
2.3.1 MySQL基本查询
去除重复的字段
SELECT DISTINCT <column> FROM <table_name>;
计算运算,一般可以直接使用四则数值运算
SELECT name, chinese, math, english, chinese+math+english FROM student;
如果有
null参与的运算,所有运算结果都为null,通过IFNULL(FIELDisNULL, REPLACE_VALUE)函数进行处理SELECT name, chinese, math, english, IFNULL(chinese, 0)+math+english FROM student;
起别名,
AS可写可不写。SELECTname 姓名,chinese 语文,math AS 数学,english 英语,chinese+math+english AS 总分FROMstudent;
2.3.2 条件查询
where子句后跟条件表达式。
支持的运算符有:
> >= < <= = <> !=,后两者都是不等于;BETWEEN...AND...,主要是介于两个值(最大和最小)之间的IN(集合),查询在一个集合中的所有数据LIKE,占位符:_单个字符,%多个字符IS NULL,主要是因为null值很特殊,不能判断相等与否,不相等判断IS NOT NULL。and &&or ||not !,推荐使用英文。
SELECT * FROM student WHERE name LIKE 'b%';
当有多条件查询的需求时,但是又不知道最后会使用到的到底是哪些条件,就可以这样子做拼接SQL语句,首先写出基础的查询语句和一定正确的WHERE条件:SELECT * FROM student WHERE 1=1,然后继续拼接条件AND name LIKE 'b%',这样子所有的拼接条件就有据可循了。最后拼接上;就可以了。
2.3.3 排序查询
SELECT * FROM <tablename> ORDER BY 排序字段1 [ASC|DESC][, 排序字段2 [ASC|DESC], ...];
默认升序排序ASC,可指定降序排序DESC。
当有多个排序条件,则会顺序排序。
2.3.4 聚合函数
将一列数据作为一个整体,进行纵向的计算。一般会对聚合函数取别名,后续判断也使用别名进行。
count:计算个数sum:计算和max:计算最大值min:计算最小值avg:计算平均值
但是聚合函数的计算会自动排除空值
null。
- 可以选择不包含非空列进行计算,如主键
- 使用
IFNULL函数把null替换为0COUNT(*),不推荐使用
SELECT COUNT(<column_name>) FROM <tablename>;SELECT SUM(<column_name>) FROM <tablename>;SELECT MAX(<column_name>) FROM <tablename>;SELECT MIN(<column_name>) FROM <tablename>;SELECT AVG(<column_name>) FROM <tablename>;
2.3.5 分组查询
SELECT <column_name>, <functions> FROM <tablename> [WHERE <conditions>] GROUP BY <column_name> [HAVING ...];
分组之后查询的字段是共性的东西,一般是分组字段和聚合函数。
where与having的区别
where在分组之前进行限定,如果不满足,则不参与分组;having在分组之后进行限定,如果不满足,则不会显示出来(参与分组但是不显示);where后不可跟聚合函数,而having后可以跟聚合函数。
2.3.5 分页查询
limit分页查询是MySQL的一个方言。
SELECT * FROM <tablename> LIMIT <start_index>, <items_per_page>;
索引从0开始。开始索引=(当前页码-1) * 每页显示条数;。
2.3.6 多表查询
直接查询多表生成得是笛卡尔积A×B。
SELECT * FROM <table1>, <table2>;
内连接查询
隐式内连接:使用
WHERE清除无用记录SELECTemp.name, gender, dept.nameFROMemp, deptWHEREemp.dept_id = dept.id;
显示内连接:需要指定
INNER JOIN,其中INNER可以省略SELECT <column_name> FROM <table1> [INNER] JOIN <table2> ON <conditions>;
- 确定从哪些表中查询数据;
- 确定查询条件是什么;
- 确定查询字段。
外连接查询
左外连接,查询的是左边表中的数据以及两表的交集部分。用的相对右外连接多一点。
其中的OUTTER可以省略。SELECT * FROM <table1> LEFT [OUTER] JOIN <table2> ON <conditions>
右外连接,查询的是右边表中的数据以及两表的交集部分。
SELECT * FROM <table1> RIGHT [OUTER] JOIN <table2> ON <conditions>
子查询
查询中嵌套查询,嵌套查询就是子查询。子查询的结果是单行单列
子查询的结果可以作为条件,使用运算符去判断。-- 查询薪水最高的员工信息SELECT * FROM emp WHERE salary = (SELECT MAX(salary) FROM emp);
子查询的结果是多行单列
子查询的结果也可以作为条件,但是运算符只能使用IN-- 查询财务部和市场部所有员工信息SELECT * FROM emp WHERE dept_id IN (SELECT id FROM dept WHERE name="财务部" OR name="市场部");
子查询的结果是多行多列
-- 查询员工入职日期位于2011-11-11之后的信息和部门信息SELECT * FROM dept t1,(SELECT * FROM emp WHERE join_date > "2011-11-11") t2 -- 作为虚拟表WHERE t1.id = t2.dept_id;
2.4 DCL:管理用户和授权
DBA(Database Administration)的事情。
2.4.1 管理用户
USE mysql;
添加
CREATE USER '<username>'@'<hostname>' IDENTIFIED BY '<password>';
删除
DROP USER '<username>'@'<hostname>';
修改密码
MySQL修改root密码
修改root用户密码:
```mysql UPDATE user SET password = PASSWORD(“new_password”) WHERE user=; UPDATE user SET authentication_string = PASSWORD(“new_password”) WHERE user=’ ‘ AND host=’ ‘; FLUSH PRIVILEGES; — 这里有时候修改了之后不好使,需要这样子刷新一下
SET PASSWORD FOR ‘
```powershell# 1. 停止mysql服务$ net start mysql# 2. 使用无验证的方式启动mysql服务$ mysqld --skip-grant-tables# 3. 新开一个mysql$ mysql # 直接启动,就可以修改了# 4. 修改完了,结束mysqld服务进程# 5. 启动mysql服务$ net start mysql# 6. 使用新密码登录
- 查询
这里结果中的HOST字段中%表示可以在任意主机使用用户登录数据库,localhost表示只能在本机登录。SELECT * FROM user;
2.4.2 权限管理
查询权限
SHOW GRANTS FOR '<username>'@'<hostname>';
授予权限
privilege有SELECT, DELETE, UPDATE等。所有权限ALL,所有数据库和表*.*。GRANT <privileges> ON <db_name>.<tablename> TO '<username>'@'<hostname>';
撤销权限
REVOKE <privileges> ON <db_name>.<tablename> FROM '<username>'@'<hostname>';
3. 数据类型
SQL中的数据类型:
int:整数类型,age int。double:双精度类型,score double(5,2),最大5位数,包括两位小数。date:日期,只包含年月日,yyyy-MM-dddatetime:日期,包含年月日时分秒,yyyy-MM-dd HH:mm:ss。timestamp:时间戳类型,包含年月日时分秒,yyyy-MM-dd HH:mm:ss。如果将来不给这个字段赋值或者赋值为null,则使用系统当前时间。varchar:字符串类型。name varchar(20)姓名最大20个字符。
4. 约束
限定数据,保证数据的正确性、有效性和完整性。
分类:
- 主键约束:primary key
- 非空约束:not null
- 唯一约束:unique
- 外键约束:foreign key
4.1 非空约束
CREATE TABLE <tablename>(<column_name> <data_type> NOT NULL);
有可能在创建表的时候没有添加非空约束,后续需要添加非空约束
ALTER TABLE <tablename> MODIFY <column_name> NOT NULL;
删除和后续添加一样
ALTER TABLE <tablename> MODIFY <column_name>;
4.2 唯一约束
CREATE TABLE <tablename>(<column_name> <data_type> UNIQUE);
MySQL中不保证值不为NULL且不保证NULL不重复。
后续添加唯一约束:
ALTER TABLE <tablename> MODIFY <column_name> UNIQUE;
删除唯一约束语法比较特殊:
ALTER TABLE <tablename> DROP INDEX <column_name>;
4.3 主键约束
primary key代表非空且唯一,综合了上述两个约束。一张表只能有一个字段为主键。逐渐就是表中记录的唯一标识。
CREATE TABLE <tablename>(<column_name> <data_type> PRIMARY KEY;);
删除主键:
ALTER TABLE <tablename> DROP PRIMARY KEY;
后续添加:
ALTER TABLE <tablename> MODIFY <column_name> <data_type> PRIMARY KEY;
联合主键,就是类似外键,在创建表的时候,可以在所有字段之后再添加主键。
PRIMARY KEY(key1, key2,...)
4.4 自动增长
某一列是数值类型的,使用AUTO_INCREMENT可以完成值的自动增长。一般配合主键使用。
CREATE TABLE <tablename>(<column_name> <data_type> PRIMARY KEY AUTO_INCREMENT;);
删除自动增长:
ALTER TABLE <tablename> MODIFY <column_name> <data_type>; -- 这样子不会删除主键
后续添加自动增长:
ALTER TABLE <tablename> MODIFY <column_name> <data_type> AUTO_INCREMENT;
4.5 外键约束
所谓外键,就是别的表的主键或具有唯一约束的字段。用于表拆分后,仍然使得表可以关联起来,同时不能删除有被在使用中外键记录。既然要关联,就应该先存在。CONSTRAINT以及之后的外键名称可以不写,数据库系统会自动创建外键名称。
CREATE TABLE <tablename>(<column_name> <data_type>,CONSTRAINT<foreign_key_name> -- 外键名称FOREIGN KEY(<foreign_key_column_name>) -- 外键字段REFERENCES<main_table>(<column_name>) -- 表名表中关联外键的字段);
删除外键:
ALTER TABLE <tablename> DROP FOREIGN KEY <foreign_key_name>;
后续添加外键:
ALTER TABLE<tablename>ADD CONSTRAINT<foreign_key_name>FOREIGN KEY(<foreign_key_column_name>)REFERENCES<main_table>(column_name>);
4.6 级联操作
级联操作,由于涉及多张表,谨慎使用。
级联更新
ALTER TABLE<tablename>ADD CONSTRAINT<foreign_key_name>FOREIGN KEY(<foreign_key_column_name>)REFERENCES<main_table>(<column_name>)ON UPDATE CASCADE; -- 级联操作
级联删除,一般最好别用吧。不然删除了,数据都无法恢复。
ALTER TABLE<tablename>ADD CONSTRAINT<foreign_key_name>FOREIGN KEY(<foreign_key_column_name>)REFERENCES<main_table(<column_name>)ON DELETE CASCADE;
5. 数据库设计
5.1 多表关系
一对一,个人和身份证,很少存在。
+---------+ +---------+| entity1 | 1---1 | entity2 |+---------+ +---------+
在任意一方添加唯一外键,指向另一方的主键,并且外键唯一。
当然合成一张表更好。
一对多,或者是多对一,员工和部门,最常见,最重要。
+---------+ +---------+| entity1 | 1---N | entity2 |+---------+ +---------+
在‘多’的一方建立外键,指向‘一’这一方的主键。
多对多,学生和课程。
+---------+ +---------+| entity1 | M---N | entity2 |+---------+ +---------+
一般需要借助第三张中间表来拆分成一对多关系。该表至少包含2个字段,这2个字段作为第三张表的外键,分别指向两张表的主键。这里外键可以做成联合主键。
5.2 范式
就是一些需要在设计数据库时需要遵循的范式。范式是递进的,遵循后续范式必须先遵循前边的范式。越高的数据库,冗余度越低。
- 第一范式1NF:每一列都是不可再分的原子数据项
- 第二范式2NF:在1NF的基础上,非码属性必须完全依赖于候选码(在1NF的基础上,消除了非主属性对于主码的部分函数依赖)
- 函数依赖:A—>B,如果通过A可以唯一确定B,则B依赖于A。
- 完全函数依赖:A—>B,如果A是一个属性组(包含多个属性),B属性值的确定需要依赖于A这个属性组的所有属性。
- 部分函数依赖:A—>B,如果A是一个属性组(包含多个属性组),B属性值的确定只需要依赖A这个属性组的部分属性。
- 传递函数依赖:A—>B—>C,A属性可以唯一确定B,B可以唯一确定C,则C传递函数依赖于A。
- 码:如果一张表中,一个属性或者属性组,被其它所有属性所完全依赖,则称这个属性(属性组)为该表的码。
- 主属性:码属性组中的所有属性
- 非主属性:除码属性组中的所有属性
- 第三范式3NF:在2NF的基础上,任何非主属性不依赖于其它非主属性(在2NF的基础上消除传递依赖)
- BCNF
- 第四范式4NF
- 第五范式5NF
6. 数据库备份和还原
6.1 数据库备份
$ mysqldump -uUSERNAME -pPASSWORD DB_NAME > /path/to/save/file.sql
6.2 数据库还原
# 1. 登录数据库$ mysql -uUSERNAME -p# 2. 切换到要用的数据库> CREATE DATABASE <db_name>;> USE <db_name>;# 3. 执行sql语句> SOURCE /path/to/save/file.sql
7. 事务
7.1 简介
一个包含多个步骤的业务操作,由事务管理,要么同时成功,要么同时失败。例如转账操作。
操作:
- 开启
START TRANSACTION; - 有错误回滚
ROLLBACK; - 无错误提交
COMMIT;
MySQL数据库中的事务默认自动提交事务。一条DML(增删改)语句会自动提交事务。而Oracle是需要手动提交的。
查看是否是自动提交事务:SELECT @@AUTOCOMMIT;,其中1代表自动提交,0代表手动提交。
7.2 四大特征
- 原子性:不可分割的最小操作单位,要么同时成功,要么同时失败;
- 持久性:如果事务一旦提交或者回滚,数据库会持久化保存数据;
- 隔离性:多个事务之间相互独立;
- 一致性:事务操作前后,数据总量不变。
7.3 隔离级别
多个事务之间是隔离的,相互独立。但是多个事务操作同一批数据,则会引发一些问题。设置不同的隔离级别就可以解决这些问题。
问题:
- 脏读:一个事务读取到另一个事物中的没有提交数据;
- 不可重复读:在同一个事务中,两次读取到的数据不一样,也称为虚读;
- 幻读:一个事务操作(DML)数据表中所有记录,另一个事务添加了一条记录,则第一个事务查询不到自己的修改。
MySQL中支持的隔离级别
- read uncommitted: 读未提交,会产生:脏读、不可重复读、幻读
- read committed:读已经提交,会产生:不可重复读、幻读(Oracle默认)
- repeatable read:可重复读,会产生幻读。(MySQL默认)
- serializable:串行化,可解决所有问题。会将表锁上。相当于多线程中的锁。
隔离级别从小到大安全性越来越高,效率越来越低。
查询隔离级别:SELECT @@TX_ISOLATION;
设置隔离级别:SET GLOBAL TRANSACTION ISOLATION LEVEL <isolation-level>;

若有收获,就点个赞吧
0 人点赞
