什么是线性回归
现有数据:工资和年龄(2个特征)
预测目标:银行会贷款给人多少钱(标签)
考虑问题:工资和年龄都会影响银行贷款的结果那么它们各自有多大的影响呢?
x1,x2就是我们的两个特征(年龄,工资),y是银行最终会借多少钱
找到一个最合适的一条线,拟合数据点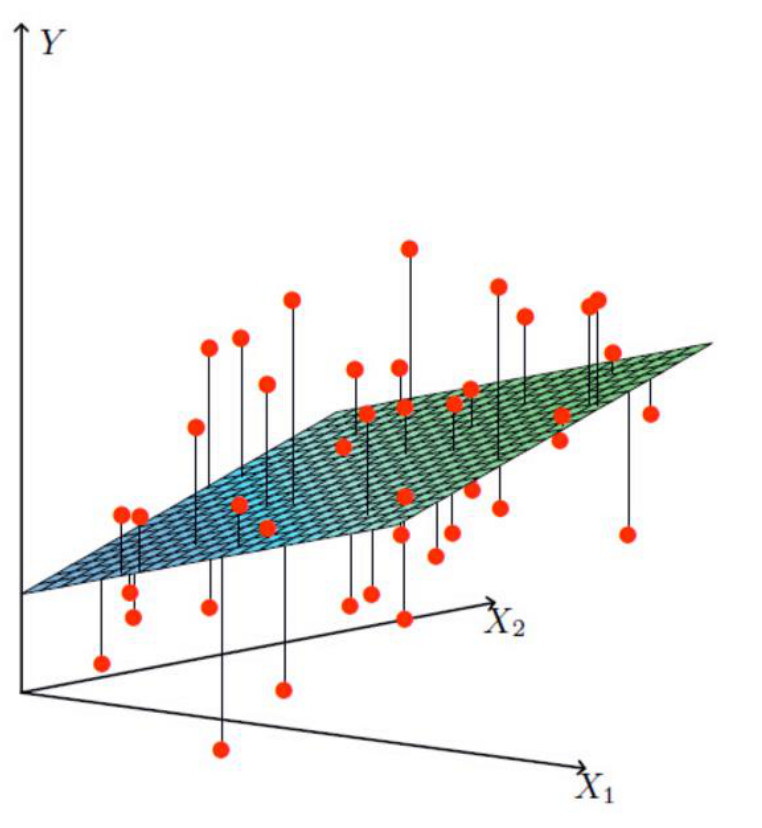
假设θ1是年龄的参数,θ2是工资的参数
拟合的平面: (θ1~2是权重项;θ0是偏置项,上下微调)
(θ1~2是权重项;θ0是偏置项,上下微调)
整合: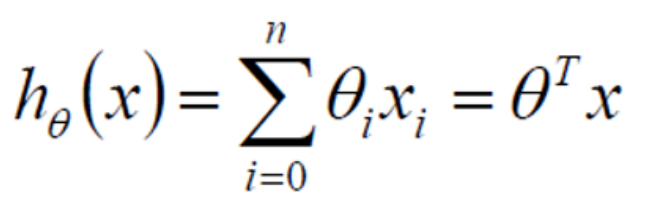
什么是误差
误差项定义
真实值和预测值之前肯定是要存在差异的(用ε来表示该误差)
对于每个样本:
独立同分布的意义
误差ε(i)是独立并且具有相同的分布,并且服从均值为0方差为θ2的高斯分布
独立:张三和李四一起来贷款,他俩没关系
同分布:他俩都来的是我们假设的这家银行
高斯分布:银行可能会给多,也可能会少给,但是绝大多数情况下这个浮动不会太大,极小情况下浮动会比较大,符合正常情况
预测值与误差:
由于误差服从高斯分布: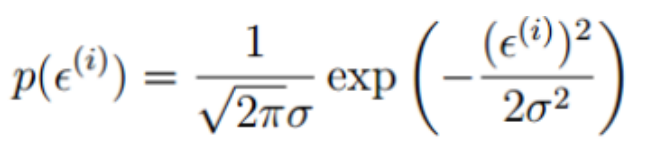
公式合并: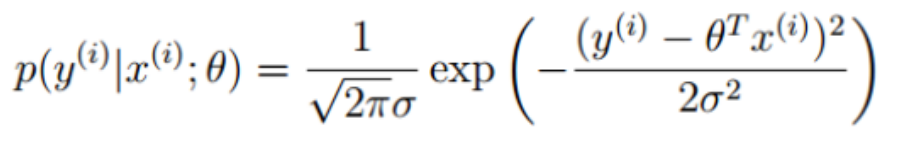
似然函数
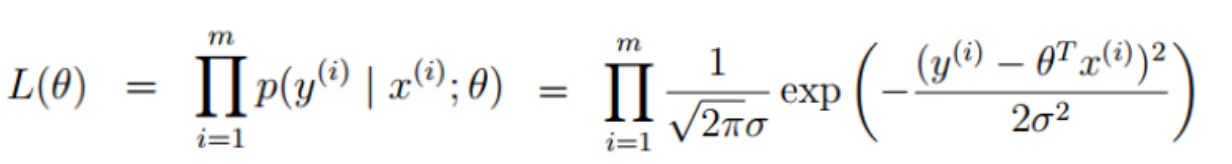

评估方法
最常用的评估项R2: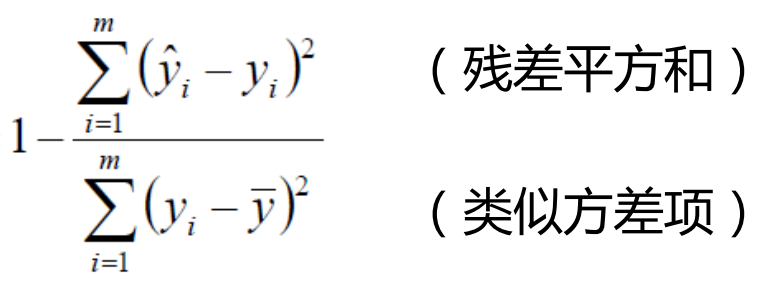
R2的取值越接近于1,我们认为模型拟合的越好
梯度下降

下山步骤
1:找到当前最合适的方向
2:走一小步,走到悬空了
3:按照方向和步伐去更新我们的参数
梯度下降参数:

批量梯度下降:
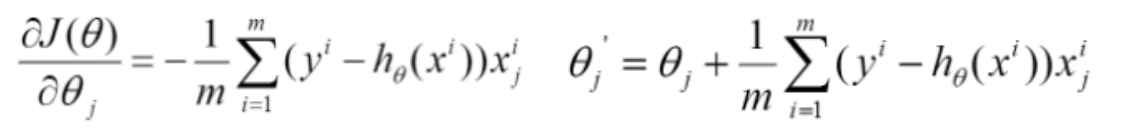
随机梯度下降:

小批量梯度下降法:

学习率
对结果会产生巨大的影响,一般偏小一些
选择:从小的时候,不行再小
批处理数量:32,64,128都可以,很多时候需要考虑内存和效率

若有收获,就点个赞吧
0 人点赞
