Elasticsearch使用的是 term frequency/inverse document frequency算法,简称为TF/IDF算法。TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)
相关性算分的几个重要概念如下:
- Term Frequency(TF)词频:即单词在该文档中出现的次数,词频越高,相关度越高。
- Inverse Document Frequency(IDF)逆向文档频率:与文档频率相反,简单理解为1/DF。即单词出现的文档数越少,相关度越高。
- Document Frequency(DF)文档频率:即单词出现的文档数。
- Field-length Norm:文档越短,相关性越高,field长度,field越长,相关度越弱
ES目前主要有两个相关性算分模型,如下:
- TF/IDF 模型
- BM25 模型,5.x之后的默认模型
相关性算分-TF/IDF 模型
TF/IDF模型是Lucene的经典模型,其计算公式如下: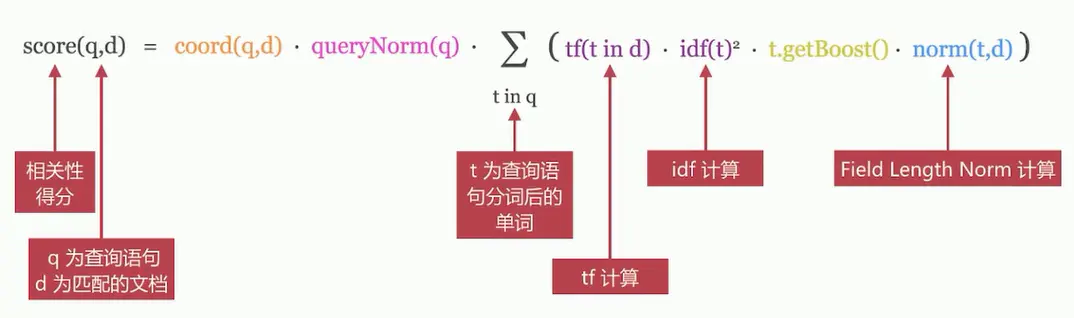
可以通过explain参数来查看具体的计算方式,但要注意:
- es的算分是按照shard进行的,即shard的分数计算是相互独立的,所以在使用explain的时候要注意分片数。
- 可以设置索引的分片数为1来避免这个问题。
也可以查看具体数据的打分计算方式GET test_index1/_search{"explain":true,"query":{"match":{"name":"lisi"}}}
test_index1/_doc/1/_explain{"query":{"match":{"name":"lisi"}}}
相关性算分-BM25 模型
BM25 模型中BM指的Best Match,25指的是在BM25中的计算公式是第25次迭代优化,是针对TF/IDF的一个优化,其计算公式如下:
对IDF的改良
BM25中的IDF公式为: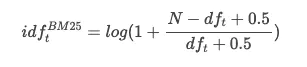
原版BM25的log中是没有加1的,Lucene为了防止产生负值,做了一点小优化。虽然对公式进行了更改,但其实和原来的公式没有实质性的差异,下面是新旧函数曲线对比:
对TF的改良
BM25中TF的公式为:
其中tf是传统的词频值。先来看下改良前后的函数曲线对比(下图中k=1.2):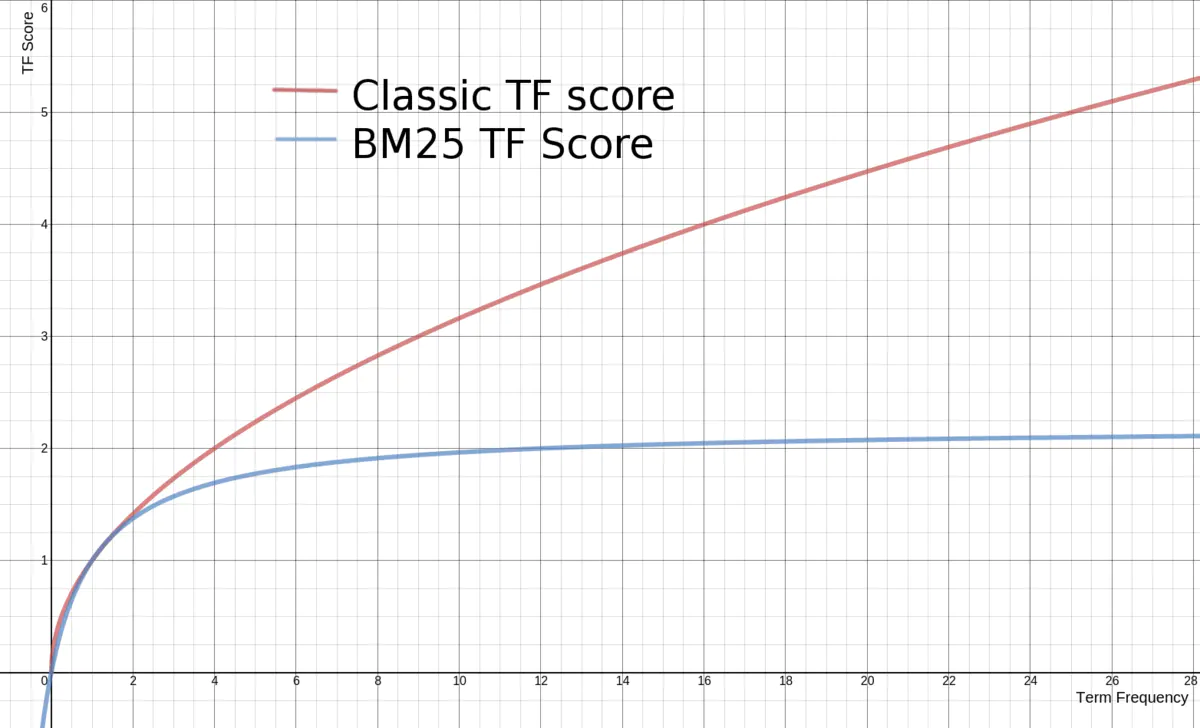
可以看到,传统的tf计算公式中,词频越高,tf值就越大,没有上限。但BM中的tf,随着词频的增长,tf值会无限逼近(k+1),相当于是有上限的。这就是二者的区别。一般 k取 1.2,Lucene中也使用1.2作为 k 的默认值。
在传统的计算公式中,还有一个norm。BM25将这个因素加到了TF的计算公式中,结合了norm因素的BM25中的TF计算公式为: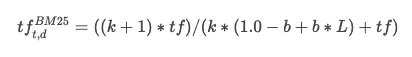
和之前相比,就是给分母上面的 k 加了一个乘数 (1.0−b+b∗L)(1.0−b+b∗L)。 其中的 L 的计算公式为: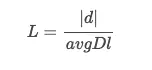
其中,|d|是当前文档的长度,avgDl 是语料库中所有文档的平均长度。
b 是一个常数,用来控制 L 对最总评分影响的大小,一般取0~1之间的数(取0则代表完全忽略 L )。Lucene中 b 的默认值为 0.75。
通过这些细节上的改良,BM25在很多实际场景中的表现都优于传统的TF-IDF,所以从Lucene 6.0.0版本开始,上位成为默认的相似度评分算法。
配置
{"settings":{"index":{"analysis":{"analyzer":"ik_smart"}},"similarity":{"my_custom_similarity":{"type":"BM25","k1":1.2,"b":0.75,"discount_overlaps":false}}},"mappings":{"doc":{"properties":{"title":{"type":"text","similarity":"my_custom_similarity"}}}}}
上例是通过similarity属性来指定打分模型,用到了以下三个参数:
- k1:控制对于得分而言词频(TF)的重要性,默认为1.2。
- b:是介于0 ~ 1之间的数值,控制文档篇幅对于得分的影响程度,默认为0.75。
- discount_overlaps:在某个字段中,多少个分词出现在同一位置,是否应该影响长度的标准化,默认值是true。
如果我们要使用某种特定的打分模型,并且希望应用到全局,那么就在elasticsearch.yml配置文件中加入:
index.similarity.default.type: BM25
评分中的boosting
通过boosting可以人为控制某个字段的在评分过程中的比重,有两种类型:
- 索引期间的boosting
- 查询期间的boosting
通过在mapping中设置boost参数,可以在索引期间改变字段的评分权重:
{"mappings":{"doc":{"properties":{"name":{"boost":2.0,"type":"text"},"age":{"type":"long"}}}}}
需要注意的是:在索引期间修改的文档boosting是存储在索引中的,要想修改boosting必须重新索引该篇文档。
一旦映射建立完成,那么所有name字段都会自动拥有一个boost值,并且是以降低精度的数值存储在Lucene内部的索引结构中。只有一个字节用于存储浮点型数值(存不下就损失精度了),计算文档的最终得分时可能会损失精度。
另外,boost是应用与词条的。因此,再被boost的字段中如果匹配上了多个词条,就意味着计算多次的boost,这将会进一步增加字段的权重,可能会影响最终的文档得分。
查询期间的boosting可以避免上述问题。
几乎所有的查询类型都支持boost,例如:
GET /book/_search{"query": {"bool": {"should": [{"match": {"name":{"query": "java","boost": 2.5}}},{"match": {"description": "java 程序员"}}]}}}
就对于最终得分而言,加了boost的name查询更有影响力。也只有在bool查询中,boost更有意义。
boost也可以用于multi_match查询。
GET /book/_search{"query":{"multi_match":{"query":"java 程序员","fields":["name","description"],"boost":2.5}}}
除此之外,我们还可以使用特殊的语法,只为特定的字段指定一个boost。通过在字段名称后添加一个^符号和boost的值。告诉ES只需对那个字段进行boost:
GET /book/_search{"query":{"multi_match":{"query":"java 程序员","fields":["name^3","description"]}}}
上例中,title字段被boost了3倍。
需要注意的是:在使用boost的时候,无论是字段或者词条,都是按照相对值来boost的,而不是乘以乘数。如果对于所有的待搜索词条boost了同样的值,那么就好像没有boost一样。因为Lucene会标准化boost的值。如果boost一个字段4倍,不是意味着该字段的得分就是乘以4的结果。
explain评分细节
ES背后的评分过程比我们想象的要复杂,有时候某个查询结果可能跟我们的预期不太一样,这时候可以通过explain让ES解释一下评分细节。
GET /book/_search{"query": {"match": {"name": "spring"}},"explain": true,"_source": "name","size": 1}
由于结果太长,我们这里对结果进行了过滤(”size”: 1返回一篇文档),只查看指定的字段(”_source”: “name”只返回name字段)。
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.9331132,"hits" : [{"_shard" : "[book][0]","_node" : "jSOjG5zoTwuvHsd5KJTUZw","_index" : "book","_type" : "_doc","_id" : "3","_score" : 0.9331132,"_source" : {"name" : "spring开发基础"},"_explanation" : {"value" : 0.9331132,"description" : "weight(name:spring in 2) [PerFieldSimilarity], result of:","details" : [{"value" : 0.9331132,"description" : "score(freq=1.0), product of:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.98082924,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 1,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 3,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.43243244,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 1.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 3.0,"description" : "dl, length of field","details" : [ ]},{"value" : 2.6666667,"description" : "avgdl, average length of field","details" : [ ]}]}]}]}}]}}
在新增的_explanation字段中,可以看到value值是0.9331132,那么是怎么算出来的呢?
分词spring在描述字段(name)出现了1次,所以TF的综合得分经过”description” : “tf, computed as freq / (freq + k1 (1 - b + b dl / avgdl)) from:”计算,得分是0.43243244。
那么逆文档词频呢?根据”description” : “idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:”计算得分是0.98082924。
需要注意的是,explain的特性会给ES带来额外的性能开销,一般只在调试时使用。
分析一个document是如何被匹配上的
Doc value
搜索的时候,要依靠倒排索引;排序的时候,需要依靠正排索引,看到每个document的每个field,然后进行排序,所谓的正排索引,其实就是doc values。
在建立索引的时候,一方面会建立倒排索引,以供搜索用;一方面会建立正排索引,也就是doc values,以供排序,聚合,过滤等操作使用。
doc values是被保存在磁盘上的,此时如果内存足够,os会自动将其缓存在内存中,性能还是会很高;如果内存不足够,os会将其写入磁盘上。
DocValues默认是启用的,可以在创建索引的时候关闭,如果后面要开启DocValues,需要做reindex操作。
参考:
https://www.elastic.co/guide/cn/elasticsearch/guide/current/scoring-theory.html
https://blog.csdn.net/qq_29860591/article/details/109574595
https://www.jianshu.com/p/2624f61f1d02
http://www.dtmao.cc/news_show_378736.shtml
https://blog.csdn.net/molong1208/article/details/50623948
https://www.cnblogs.com/Neeo/articles/10721071.html
https://www.cnblogs.com/jpfss/p/10775376.html
https://www.jianshu.com/p/70d1c3045c11
https://zhuanlan.zhihu.com/p/27951938

若有收获,就点个赞吧
0 人点赞
