关系抽取的应用:
- 建立新的结构化的知识库
- 扩大现有知识库
-
实体关系类别名称
检查方法 → 疾病(Test_Disease)
- 临床表现 → 疾病(Symptom_Disease)
- 非药治疗 → 疾病(Treatment_Disease)
- 药品名称 → 疾病(Drug_Disease)
- 部位 → 疾病(Anatomy_Disease)
- 用药频率 → 药品名称(Frequency_Drug)
- 持续时间 → 药品名称(Duration_Drug)
- 用药剂量 → 药品名称(Amount_Drug)
- 用药方法 → 药品名称(Method_Drug)
- 不良反应 → 药品名称(SideEff_Drug)
关系分类和关系抽取的区别
- 关系分类:一般是判断一个句子中两个entity是哪种关系,属于多分类问题。
关系抽取:从一个句子中判断两个entity是否有关系,一般是一个二分类问题,已指定某种关系。
关系抽取方法(Relation extractors)
人工规则
优点:高准确率,可以为特定领域制定规则。
- 缺点:低召回率,对所有可能的pattern考虑周全很困难,而且需要为每条关系来定义pattern,很费时间精力。
- Stanford CoreNLP 的 tokensRegex:基于字符串的 pattern 和基于 ner 的 pattern 结合
Example: Who holds what office in what organization?
- PERSON, POSITION of ORG
- George Marshall, Secretary of State of the United States
- PERSON (named | appointed | chose | etc.) PERSON Prep? POSITION
- Truman appointed Marshall Secretary of State
- PERSON [be]? (named | appointed | etc.) Prep? ORG POSITION
- PERSON, POSITION of ORG
选择我们想要提取的关系集合
- 选择相关的命名实体集合
- 寻找并标注数据
- 选择有代表性的语料库
- 标记命名实体
- 人工标注实体间的关系
- 分成训练、验证、测试集
- 训练分类器:MaxEnt、Naive Bayes、SVM ….
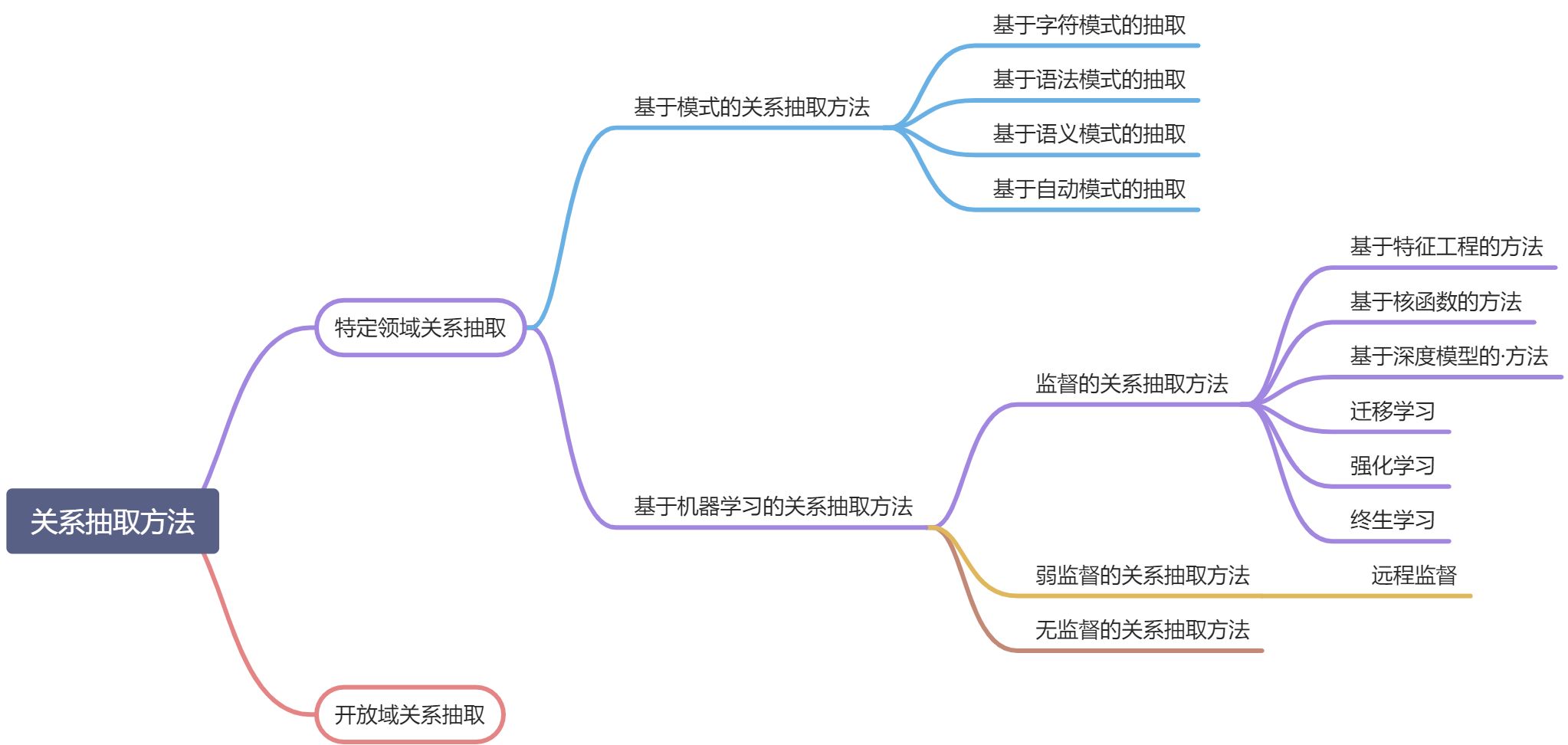

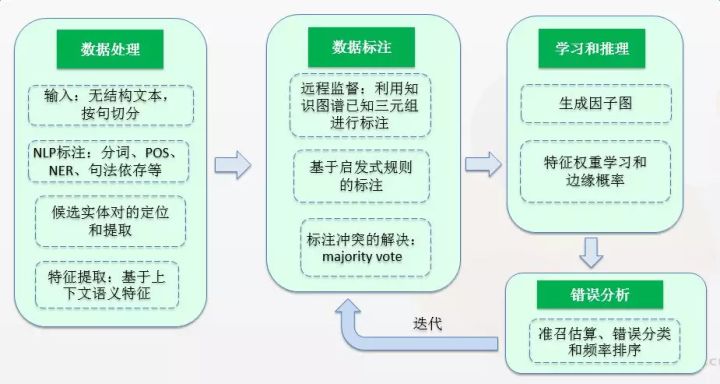
半监督学习
- 利用少量的标注信息进行学习。
- 基于 Bootstrap 的方法利用少量的实例作为初始种子(seed tuples)的结合,
- 利用 pattern 学习方法进行学习,通过不断地迭代,从非结构化数据中抽取实例,
- 从新学到的实例中学习新的 pattern 并扩充 pattern 集合。

若有收获,就点个赞吧
0 人点赞
