1 中文自然语言处理简介
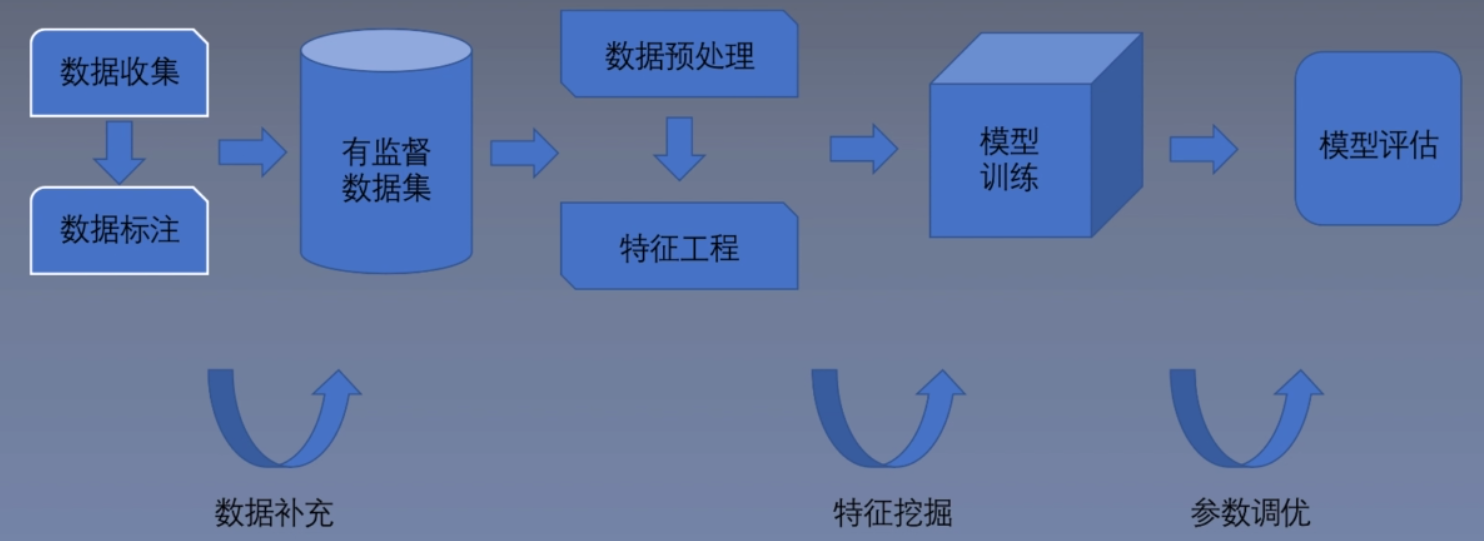
机器学习的基本流程
自然语言处理(Natural Language Processing, NLP)技术被称为“人工智能皇冠上的明珠”。
中文NLP一般流程.jpg
中文分词(Chinese word segmentation)
中文分词常见方法里既有经典的机械切分法(如正向/逆向最大匹配,双向最大匹配等),也有效果更好一些的统计切分方法(如隐马尔可夫HMM,条件随机场CRF),以及近年来兴起的采用深度神经网络的RNN、LSTM等方法。
# encoding=utf-8import jiebajieba.enable_paddle() # 启动paddle模式。0.40版之后开始支持,早期版本不支持。# 使用paddle模式strs = ["我来到北京清华大学","乒乓球拍卖完了","中国科学技术大学","无线电法国别研究","过几天天天天气不好","一位友好的哥谭市民"]for str in strs:seg_list = jieba.cut(str, use_paddle=True)print("Paddle Model: " + '/'.join(list(seg_list)))# 全模式seg_list = jieba.cut("我来到北京清华大学", cut_all=True)print("Full Mode: " + "/ ".join(seg_list))# 精确模式 默认seg_list = jieba.cut("我来到北京清华大学", cut_all=False)print("Default Mode: " + "/ ".join(seg_list))# 搜索引擎模式seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造")print(", ".join(seg_list))
代码执行后:
Paddle Mode: 我/来到/北京清华大学Paddle Mode: 乒乓球/拍卖/完/了Paddle Mode: 中国科学技术大学Paddle Mode: 无线电法/国别/研究Paddle Mode: 过几天/天天/天气/不好Paddle Mode: 一位/友好/的/哥谭/市民Full Mode: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学Default Mode: 我/ 来到/ 北京/ 清华大学小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, ,, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
词性标注(Part-of-speech Tagging, POS)
常见的词性标注方法可以分为基于规则和基于统计的方法。其中基于统计的方法,如基于最大熵的词性标注、基于统计最大概率输出词性和基于HMM的词性标注。近年来兴起的采用深度神经网络的RNN、LSTM等方法。
import jieba.posseq as pseqjieba.enable_paddle() # 启动paddle模式。strs = ["我爱北京天安门","我感觉他喜欢我这种感觉","我喜欢你对我的喜欢"]for str in strs:words = pseg.cut(str, use_paddle=True) # paddle模式print(" ".join(['/'.join([word, flag]) for word, flag in words]))
代码执行后:
我/r 爱/v 北京/LOC 天安门/LOC我/r 感觉/v 他/r 喜欢/v 我/r 这种/r 感觉/n我/r 喜欢/v 你/r 对/p 我/r 的/u 喜欢/vn
| 标签 | 含义 | 标签 | 含义 | 标签 | 含义 | 标签 | 含义 |
|---|---|---|---|---|---|---|---|
| n | 普通名词 | f | 方位名词 | s | 处所名词 | t | 时间 |
| nr | 人名 | ns | 地名 | nt | 机构名 | nw | 作品名 |
| nz | 其他专名 | v | 普通动词 | vd | 动副词 | vn | 名动词 |
| a | 形容词 | ad | 副形词 | an | 名形词 | d | 副词 |
| m | 数量词 | q | 量词 | r | 代词 | p | 介词 |
| c | 连词 | u | 助词 | xc | 其他虚词 | w | 标点符号 |
| PER | 人名 | LOC | 地名 | ORG | 机构名 | TIME | 时间 |
去停用词(Stop words)
停用词词典是根据具体场景来决定的,比如在情感分析中,语气词、感叹词是应该保留的,因为他们对表达语气程度、感情色彩有一定的贡献和意义。
中文常用停用词表
| 词表名 | 词表文件 |
|---|---|
| 中文停用词表 | cn_stopwords.txt |
| 哈工大停用词表 | hit_stopwords.txt |
| 百度停用词表 | baidu_stopwords.txt |
| 四川大学机器智能实验室停用词库 | scu_stopwords.txt |
2 命名实体识别详解
中文命名实体识别特点
NER通常包括两部分:(1)实体边界识别;(2)确定实体类别(人名、地名、机构名或其他)。
英文中的命名实体具有比较明显的形式标志(即实体中的每个词的第一个字母要大写),所以实体边界识别相对容易,任务的重点是确定实体的类别。和英文相比,中文命名实体识别任务更加复杂,而且相对于实体类别标注子任务,实体边界的识别更加困难。
中华人民共和国中央人民政府
中华 人民 共和国 中央 人民 政府
中华人民 共和国 中央 人民政府
中华人民共和国 中央人民政府
Central Government of the People’s Republic of China
实体标注体系(Entity labeling system)
大部分情况下,标签体系越复杂准确度也越高,但相应的训练时间也会增加。因此需要根据实际情况选择合适的标签体系。
| Tokens | IO | BIO | BIOES |
|---|---|---|---|
| 突 | O | O | O |
| 发 | O | O | O |
| 心 | I-SYM | B-SYM | B-SYM |
| 绞 | I-SYM | I-SYM | I-SYM |
| 痛 | I-SYM | I-SYM | E-SYM |
| , | O | O | O |
| 未 | I-NEG | B-NEG | S-NEG |
| 加 | I-DEV | B-DEV | B-DEV |
| 重 | I-DEV | I-DEV | E-DEV |
| 。 | O | O | O |
序列标注(Sequence Labeling)

分类的评价标准(Measure of classification)
Accuracy:准确率 = 预测正确 / 总样本
Precision:精确率 = 正确预测为正 / 预测为正
Recall:召回率 = 正确预测为正 / 真实为正
F1 score:1:1调和准确和召回
如何辨别机器学习模型的好坏?秒懂Confusion Matrix
NER的评价标准
- 基于token标签进行直接评测
- 考虑实体边界 + 实体类型的评测
- 完全匹配
- 部分匹配(重叠)
Message Understanding Conference(MUC)
- Correct (COR): 匹配成功;
- Incorrect (INC): 匹配失败;
- Partial (PAR): 预测的实体边界与测试集重叠,但不完全相同;
- Missing (MIS): 测试集实体边界没有被预测识别出来;
- Spurius (SPU): 预测出的实体边界在测试集中不存在
- 测试集标签个数统计(golden):

- 预测结果标签个数统计(predict):

- 精确匹配(exact):


- 部分匹配(partial):


多分类的评价标准
Macro F1:将n分类的评价拆成n个二分类的评价,计算每个二分类的F1 score,n个F1 score的平均值即为Macro F1。
Micro F1:将n分类的评价拆成n个二分类的评价,将n个二分类评价的TP、FP、RN对应相加,计算评价准确率和召回率,由这2个准确率和召回率计算的F1 score即为Micro F1。
注意:Macro F1受样本数量少的类别影响大。基于规则的信息抽取回顾
基于规则的信息抽取:精确率高,但召回率比较低。
基于规则的方式比较适合半结构化或比较规范的文本中的进行抽取任务,结合业务需求能够达到一定的效果。
优点:简单,快速;
缺点:召回低,泛化能力差。3 HMM与维特比解码
隐马尔可夫模型实例
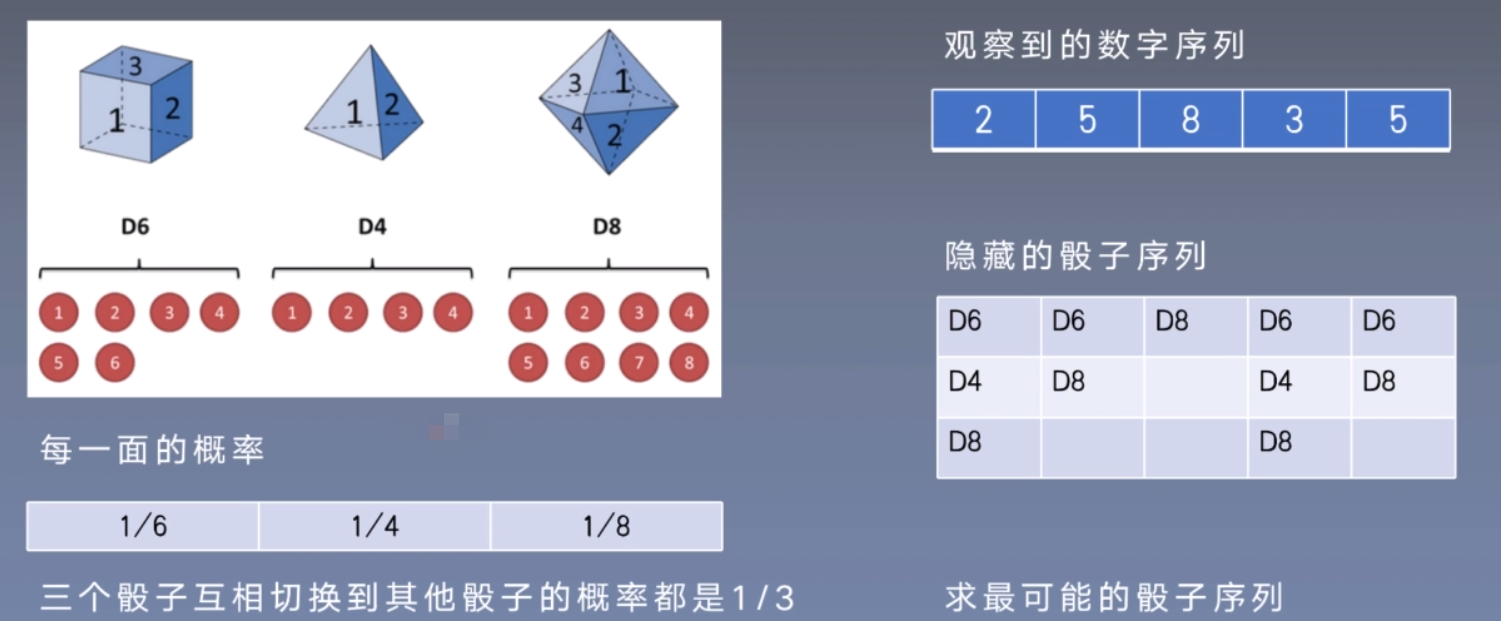
隐马尔可夫模型(Hidden Markov Model)
马尔可夫过程为状态空间中经过从一个状态到另一个状态的转换的随机过程。
该过程要求具备“无记忆”的性质:下一状态的概率分布只能由当前状态决定,在时间序列中它前面的时间均与之无关。这种特定类型的“无记忆性”称作马尔可夫性质。
隐马尔可夫模型,是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。HMM的两个假设
- 齐次马尔可夫假设:第t个隐状态(骰子)只跟前一时刻的t-1隐状态(骰子)有关,与除此之外的其他隐状态(如t-2,t+3)无关。
观测独立假设:在任意时刻观测 o(点数)只依赖于当前时刻的隐状态 i(骰子),与其他时刻的隐状态无关。
隐马尔可夫模型数学定义
前面的“BIO”的实体标签,是一个不可观测的隐状态,而HMM模型描述的就是由这些隐状态序列(实体标记)生成可观测状态(可读文本)的过程。
设我们的可观测状态序列是由所有汉字组成的集合,我们用 来表示:
来表示:
上式中, 表示字典中单个字,假设我们已知的字数为
表示字典中单个字,假设我们已知的字数为 。
。
设所有可能的隐藏状态集合为 ,一共有
,一共有 种隐藏状态,例如我们现在的命名实体识别数据里面只有7种标签:
种隐藏状态,例如我们现在的命名实体识别数据里面只有7种标签:
设我们有观测到的一串自然语言序列文本 ,一共有
,一共有 个字,又有这段观测到的文本多对应的实体标记,也就是隐状态
个字,又有这段观测到的文本多对应的实体标记,也就是隐状态 :
: (隐状态)
(隐状态) (观测)
(观测)
注意上式中,我们常称t为时刻,如上式中一共有个时刻(个汉字)。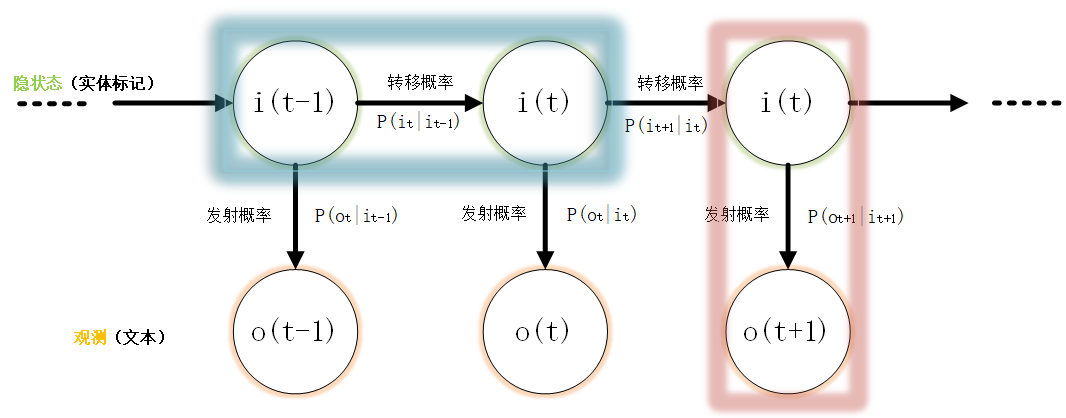
HMM的初始隐状态概率
初始隐状态概率通常用 来表示:
来表示: ,其中
,其中
序列中第一个观测对象 的隐状态是
的隐状态是 的概率,也就是初始隐状态概率。
的概率,也就是初始隐状态概率。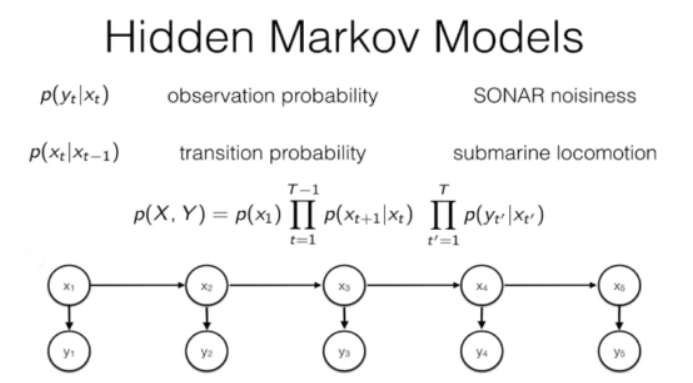
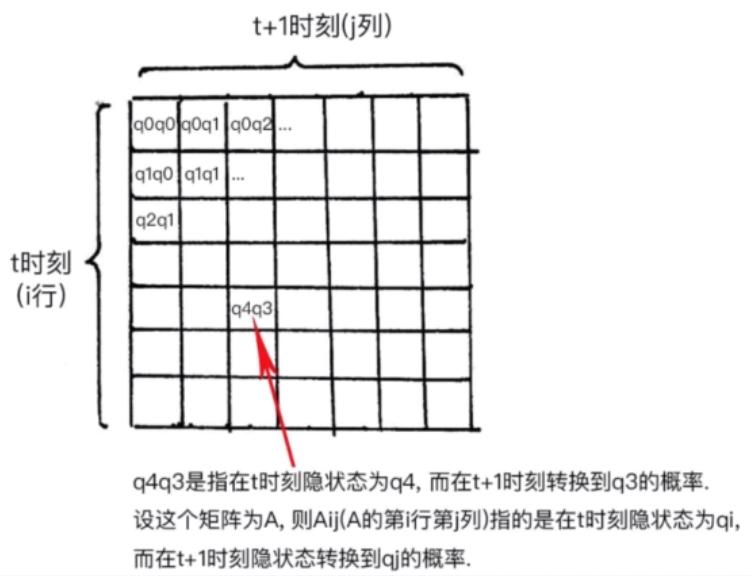
HMM的转移概率
 指的是隐状态i从t-1时刻转向t时刻的概率。用A表示转移概率矩阵(transition matrix),
指的是隐状态i从t-1时刻转向t时刻的概率。用A表示转移概率矩阵(transition matrix), ,其中
,其中 。
。
HMM的发射概率
发射概率 描述
描述 依赖于当前时刻的隐状态
依赖于当前时刻的隐状态 程度。
程度。
用B表示发射概率矩阵(emission matrix): ,其中,
,其中,

用HMM解决序列标注问题

HMM的3个基本问题
模型:
观测序列:
状态序列:
- 概率计算问题:已知模型和观测序列,计算在该模型下观测序列出现的概率。即求
 。
。 - 学习问题:已知观测序列,估计模型的参数。
学习问题根据训练数据是否包含对应的状态序列,分为:
2.1. 监督学习:极大似然估计。即求 。
。
2.2. 非监督学习:EM算法。即求 。
。
 。
。


- 转移概率的估计


- 发射概率的估计


维特比解码
维特比算法解码使用了动态规划算法来解决HMM的预测问题,找到概率最大路径,也就是最优路径。
在每一时刻,计算当前时刻落在每种隐状态的最大概率,并记录这个最大概率是从前一时刻哪一隐状态转移过来的,最后再从结尾回溯最大概率,也就是最有可能的最优路径。
设有N个状态序列长度为T,则时间复杂度为:
- 穷举法:

- 维特比:

4 条件随机场
概率图模型
概率图模型是指一种用图结构来描述多元随机变量之间条件独立关系的概率模型。
图中的每个节点都对应一个随机变量,可以是观察变量、隐变量或是未知参数等;每个连接表示两个随机变量之间具有依赖关系。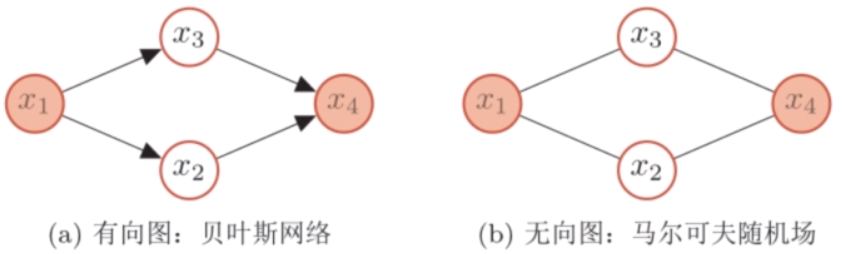
有向图 VS 无向图
有向图:联合概率分布可以利用条件概率来表示。
无向图:通过因子分解将无向图所描述的联合概率分布表达为若干个子联合概率的乘积。
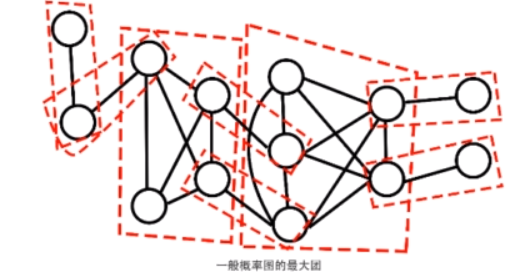
因子分解
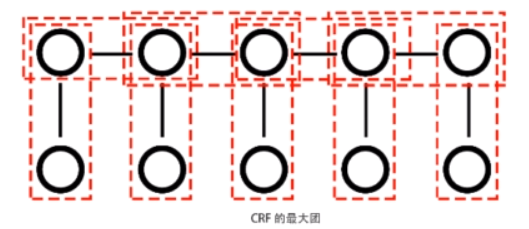
无向图G中任何两个结点均有边连接的节点子集称为团。若C是无向图G的一个团,并且不能再加进任何一个G的结点使其成为一个更大的团,则称此C为最大团。
Hammersly-Clifford定理
无向图的联合概率可以分解为一系列定义在最大团上的非负函数的乘积形式。
条件随机场(Conditional random field, CRF)
定义:如果随机变量Y构成一个由无向图 表示的马尔可夫随机场,对任意节点
表示的马尔可夫随机场,对任意节点 都成立,即
都成立,即
则称 是条件随机场。式中
是条件随机场。式中 表示w是除v以外的所有节点,
表示w是除v以外的所有节点, 表示w是与v相连接的所有节点。
表示w是与v相连接的所有节点。
CRF是条件概率分布模型,表示的是给定一组输入随机变量X的条件下另一组输出随机变量Y的马尔可夫随机场,也就是说CRF的特点是假设输出随机变量构成马尔可夫随机场。
这里说的CRF指的是用于序列标注问题的线性链条件随机场,是由输入序列来预测输出序列的判别式模型。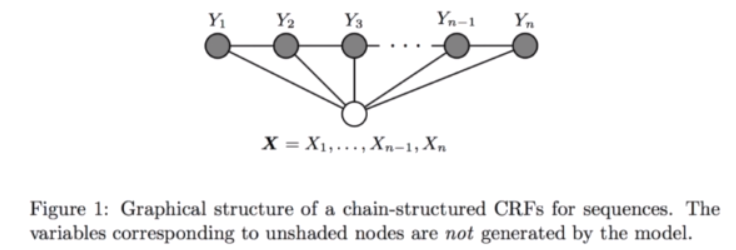
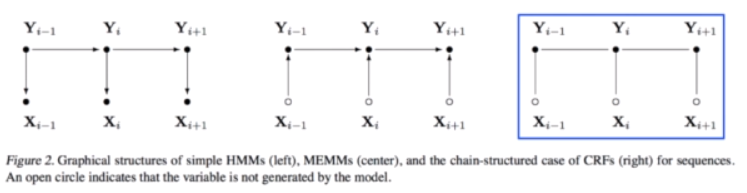
生成 VS 判别
 建模;判别:对条件概率
建模;判别:对条件概率
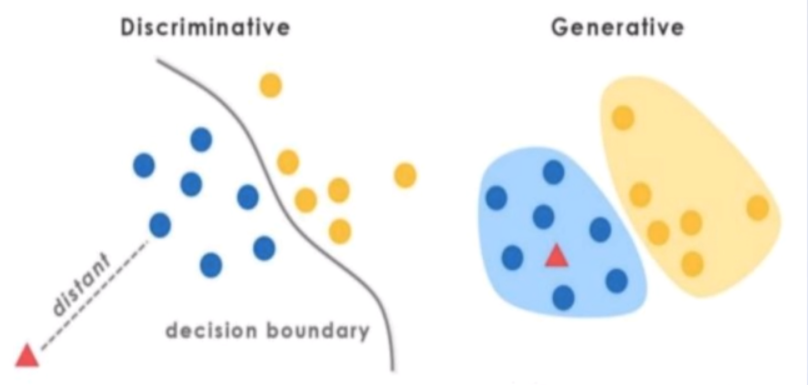
线性链条件随机场
图G的每条边都存在于状态序列Y的相邻两个节点,最大团C是相邻两个节点的集合,X和Y有相同的图结构意味着每个 都与
都与 一一对应。
一一对应。
设两组随机变量 ,
, ,那么线性链条件随机场的定义为:
,那么线性链条件随机场的定义为:
其中,当 取1或n时只考虑单边。
取1或n时只考虑单边。
参数化形式
给定一个线性链条件随机场,当观测序列为 时,状态序列为
时,状态序列为 的概率为(实际上应该写为
的概率为(实际上应该写为 )
)

 作为规范化因子,是对y的所有可能取值求和。
作为规范化因子,是对y的所有可能取值求和。
特征函数
- 转移特征
 是定义在边上的特征函数(transition),依赖于当前位置i和前一位置i-1,对应的权值为
是定义在边上的特征函数(transition),依赖于当前位置i和前一位置i-1,对应的权值为 。
。 - 状态特征
 是定义在节点上的特征函数(state),依赖于当前位置i,对应的权值为
是定义在节点上的特征函数(state),依赖于当前位置i,对应的权值为 。
。 - 特征函数的取值为1或0,当满足规定好的特征条件时取值为1,否则为0。
特征函数例子


权重大,就表明倾向于将痛标注为症状的结尾。


正权重:倾向于将冒号前的字标注为检验的结尾,例如’舒张压: 80’。


权重大,就表明倾向于认为B-SYM后面跟着I-SYM。


从特征到概率
实际上CRF就是序列版本的逻辑回归(logistic regression)。正如逻辑回归是分类问题的对数线性模型,CRF是序列标注问题的对数线性模型。 (第一个求和是对遍历特征方程j的求和,而内层的求和是对句子里面的每一个位置i进行遍历进行求和)
(第一个求和是对遍历特征方程j的求和,而内层的求和是对句子里面的每一个位置i进行遍历进行求和)
最终,我们通过求指数与归一化的方式将这些得分转换为0、1之间的概率值:
CRF VS HMM
CRF更加强大
- CRF可以为任何HMM能够建模的事物建模,甚至更多。
- CRF可以定义更加广泛的特征集。HMM在本质上必然是局部的,而CRF就可以使用更加全局的特征。
- CRF可以有任意权重值,HMM的概率值必须满足特定的约束。


- 为每个HMM的转换概率
 ,定义一组CRF转换特征如
,定义一组CRF转换特征如 if
if  且
且 的。给定每个特征权重值为
的。给定每个特征权重值为 。
。 - 类似的,为每个HMM的发射概率
 ,定义一组CRF发射特征如
,定义一组CRF发射特征如 if
if  且
且  。给定每个特征的权重值为
。给定每个特征的权重值为 。
。
CRF总结
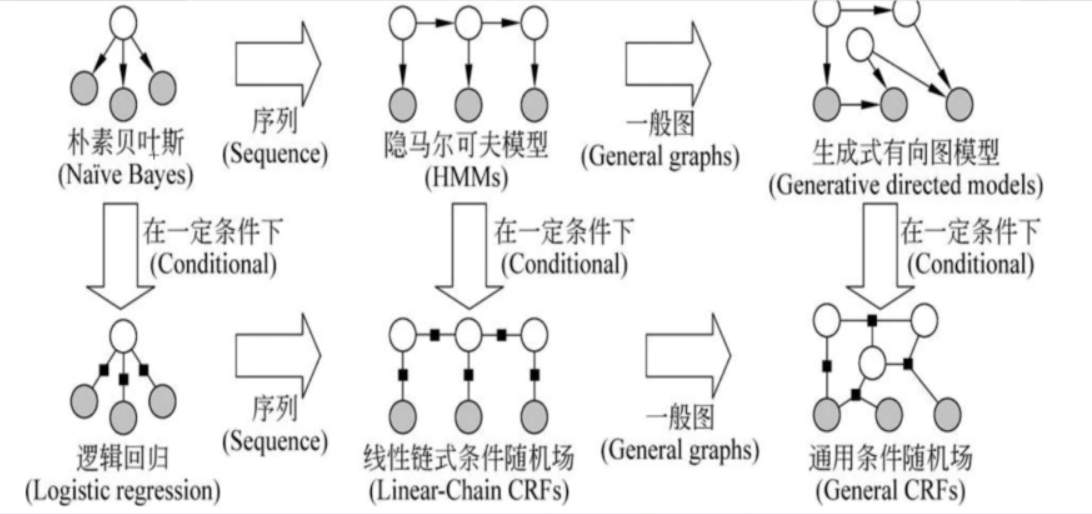
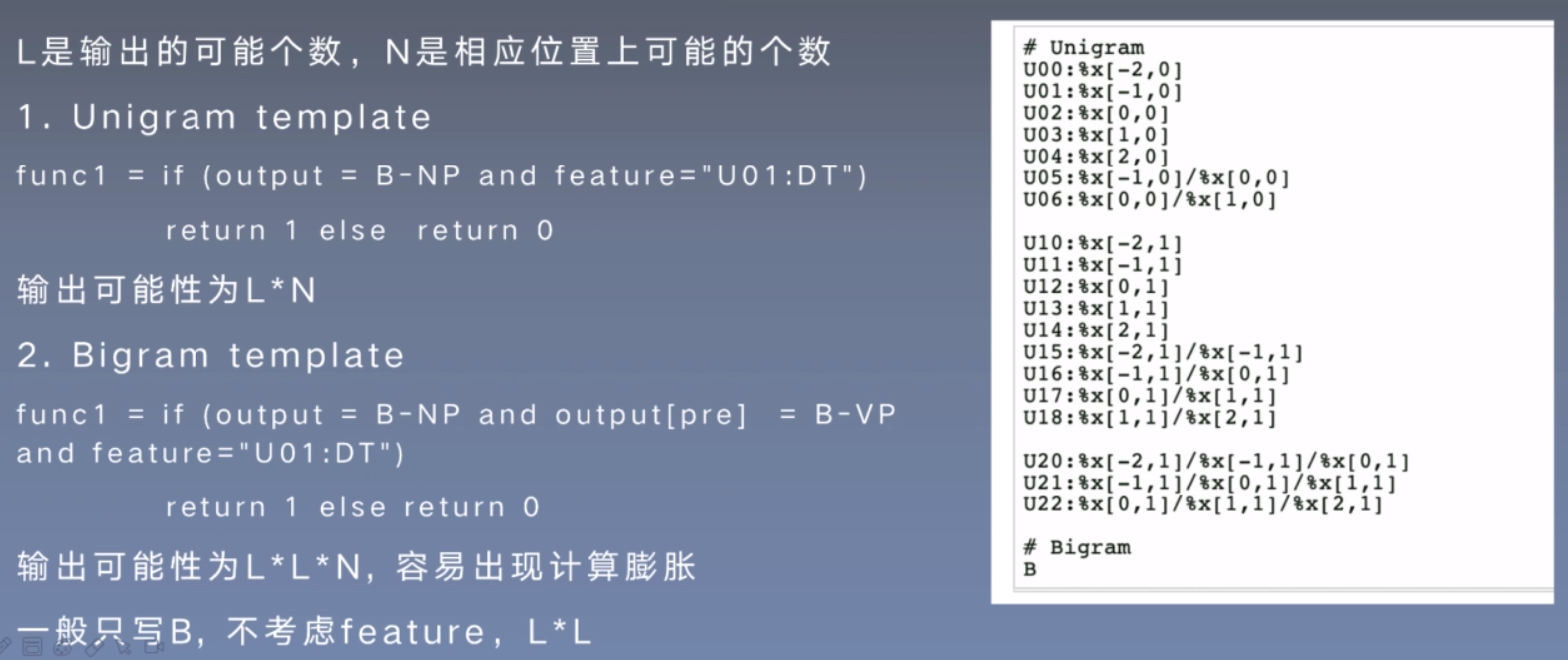
CRF++
C++代码
特征模板

若有收获,就点个赞吧
0 人点赞

{kind=link}