https://blog.csdn.net/weixin_51954021/article/details/110767134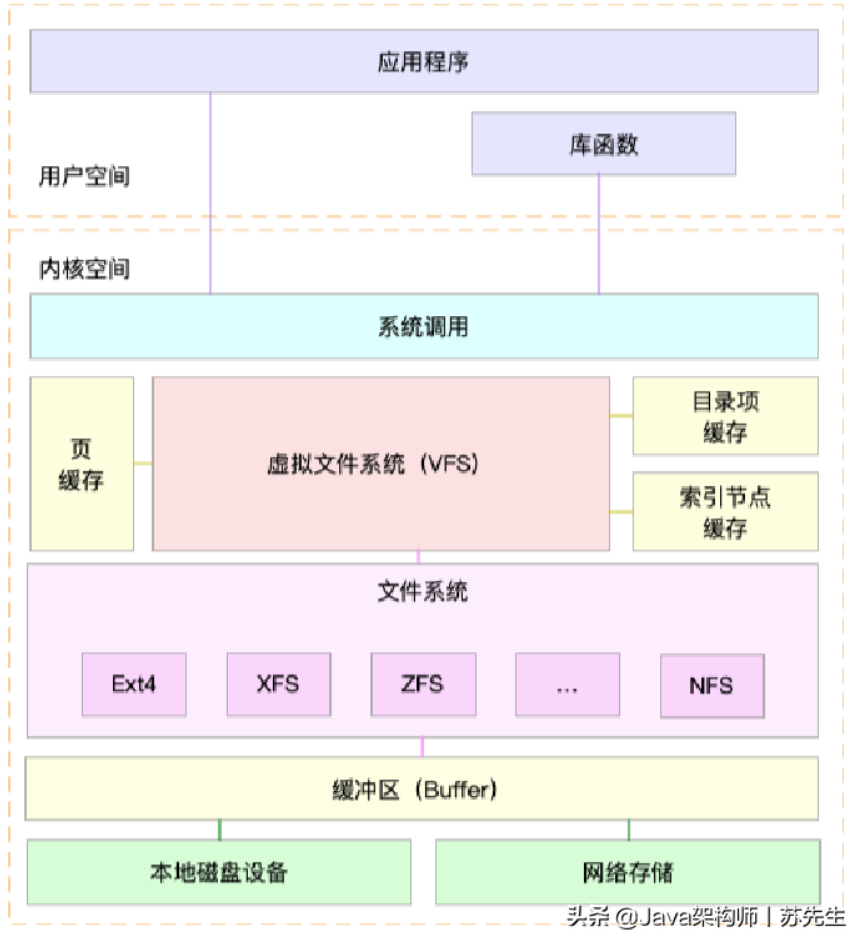
性能工具掌握文件系统和磁盘 I/O 的性能指标后,我们还要知道,怎样去获取这些指标,也就是搞明白工具的使用问题。第一,在文件系统的原理中,我介绍了查看文件系统容量的工具 df。它既可以查看文件系统数据的空间容量,也可以查看索引节点的容量。至于文件系统缓存,我们通过/proc/meminfo、/proc/slabinfo 以及 slabtop 等各种来源,观察页缓存、目录项缓存、索引节点缓存以及具体文件系统的缓存情况。第二,在磁盘 I/O 的原理中,我们分别用 iostat 和 pidstat 观察了磁盘和进程的 I/O 情况。它们都是最常用的 I/O 性能分析工具。通过 iostat ,我们可以得到磁盘的 I/O 使用率、吞吐量、响应时间以及 IOPS 等性能指标;而通过 pidstat ,则可以观察到进程的 I/O吞吐量以及块设备 I/O 的延迟等。第三,在狂打日志的案例中,我们先用 top 查看系统的 CPU 使用情况,发现 iowait 比较高;然后,又用 iostat 发现了磁盘的 I/O 使用率瓶颈,并用 pidstat 找出了大量 I/O 的进程;最后,通过 strace 和 lsof,我们找出了问题进程正在读写的文件,并最终锁定性能问题的来源——原来是进程在狂打日志。第四,在磁盘 I/O 延迟的单词热度案例中,我们同样先用 top、iostat ,发现磁盘有 I/O瓶颈,并用 pidstat 找出了大量 I/O 的进程。可接下来,想要照搬上次操作的我们失败了。在随后的 strace 命令中,我们居然没看到 write 系统调用。于是,我们换了一个思路,用新工具 filetop 和 opensnoop ,从内核中跟踪系统调用,最终找出瓶颈的来源。最后,在 MySQL 和 Redis 的案例中,同样的思路,我们先用 top、iostat 以及 pidstat ,确定并找出 I/O 性能问题的瓶颈来源,它们正是 mysqld 和 redis-server。随后,我们又用 strace+lsof 找出了它们正在读写的文件。关于 MySQL 案例,根据 mysqld 正在读写的文件路径,再结合 MySQL 数据库引擎的原理,我们不仅找出了数据库和数据表的名称,还进一步发现了慢查询的问题,最终通过优化索引解决了性能瓶颈。至于 Redis 案例,根据 redis-server 读写的文件,以及正在进行网络通信的 TCPSocket,再结合 Redis 的工作原理,我们发现 Redis 持久化选项配置有问题;从 TCPSocket 通信的数据中,我们还发现了客户端的不合理行为。于是,我们修改 Redis 配置选项,并优化了客户端使用 Redis 的方式,从而减少网络通信次数,解决性能问题。————————————————原文链接:https://blog.csdn.net/weixin_51954021/article/details/110767134
案例篇:为什么我的磁盘I/O延迟很高?

若有收获,就点个赞吧
0 人点赞
