| 题目 | 思路 | 备注 |
|---|---|---|
| 删除有序数组重复项 | 同向快慢双指针 | 当num[i]!=num[j]时,把右指针的值赋给左指针后边那个位置,左指针++ |
| 买卖股票的最佳时机 | 动规 or 迭代,注意只能买卖一次 | - 动规:最大利润:preHas=0, preNone=-prices[0] - 迭代:min = Math.min(min, prices[i]), max = Math.max(max, prices[i]-min) |
| 买卖股票的最佳时机 II | 正差之和, 注意每天都可买卖且可当天出售 | 最大利润: sum += (pirce[i]-price[i-1]>0 ? delta : 0); |
| 旋转数组 | 取模后三次翻转 | |
| 存在重复元素 | 用Set判重 | if(!set.add(x)) return true |
| 只出现一次的数字 | 挨个异或 | ret ^= nums[i] |
| 两个数组的交集II | 1. 先排序再双指针 1. 直接用频率哈希表 |
|
| 加一 | 倒着处理,遇9变0,遇非9加1返回 | |
| 移动零 | 维护一个记录0个数的计数器:count | count>0时, nums[i-count]=nums[i] |
| 两数之和 | 哈希表:Map |
|
| 三数之和 | 排序+双指针 | 第一层循环,依次先个定值,并向右缩小总区间范围:k: [0, n-3] 第二层循环, 在剩余区间内左右夹逼双指针:i, j : [k+1, n-1] 目标组合:nums[i]+nums[j]+nums[k]=0, 注意: i和j指针如果指到了重复值跳过即可 |
| 四数相加II | 两个二重循环,用HashMap存储每两个数组元素之和出现的频次 |  |
| 有效的数独 | 用三个二维数组,共两层循环进行判断 其中:由行列号可计算出所在的9宫格为:3 * (i / 3) + j/3 |
row [m][n] //记录第m行中的数字n是否存在,如果存在则记1,否则记0 col[m][n] //记录第m列中数字n是否存在,如果存在则记1,否则记0 cell[m][n] //记录第m格中的数字n是否存在,如果存在则记1,否则记0 |
| 旋转图像 | 先上下互换,再对角互换 | 真正的旋转变换须线代中公式支持,但对于特定角度的旋转,如果能对称变换,难度就会下降 |
| 矩阵置零 | 声明两个一维状态数组,然后两次遍历即可 | 如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 row[m]=true : 表示第m行存在0 col[n]=true : 表示第n列存在0 |
| 递增的三元子序列 | 先更新最小值,再更新次小值,若有比次小值大的,即存在这样的三元子序列。 注:这样的操作,隐含了一种顺序:就是次小值总在最小值后边被赋值 |
if (num <= min) min = num;//当前值比最小值还小,则更新最小值 else if (num <= small) small = num;//当前值比最小值大,但比次小值小,则更新次小值 else return true; //当前值比次小值大,视为找到 |
| 除自身以外数据的乘积 | 原理:余项乘积=前缀积 x 后缀积 具体见右侧推导 |
 表示前i项积(前缀积) 表示前i项积(前缀积) 表示后缀积 表示后缀积则  即为所求结果 即为所求结果 |
螺旋矩阵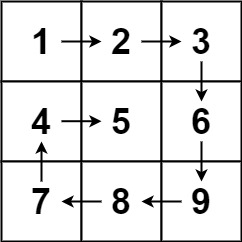 |
维护四个方向的边界值: 行界:up=0, down=m-1, up<=down 列界:left=0, right=n-1, left<=right 在while中四个子循环遍历:上右下左,直接打破上述规则 |
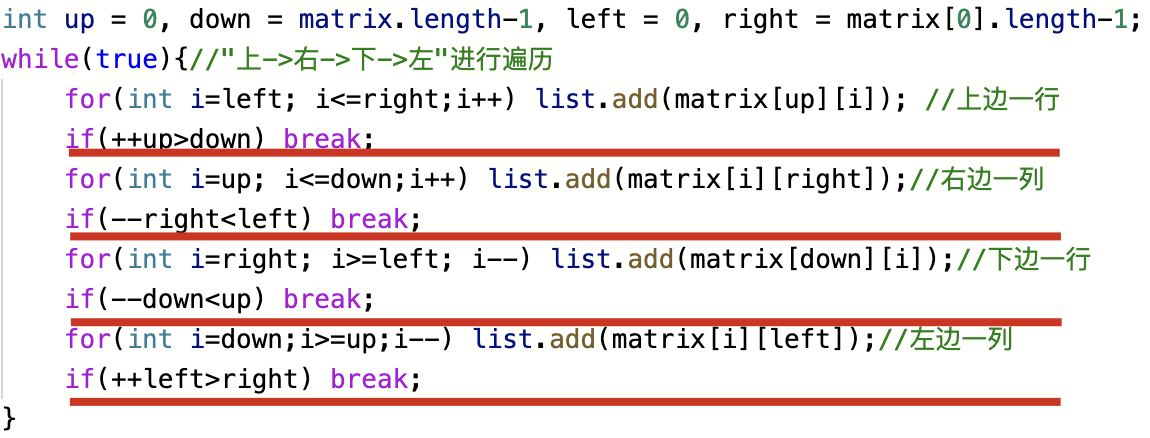 |
| 盛最多水的容器 | 左右夹逼双指针: 与 与 之间的水量s可表示为: 之间的水量s可表示为: 因此,双指针的目标是找到能让s变得更大的i和j 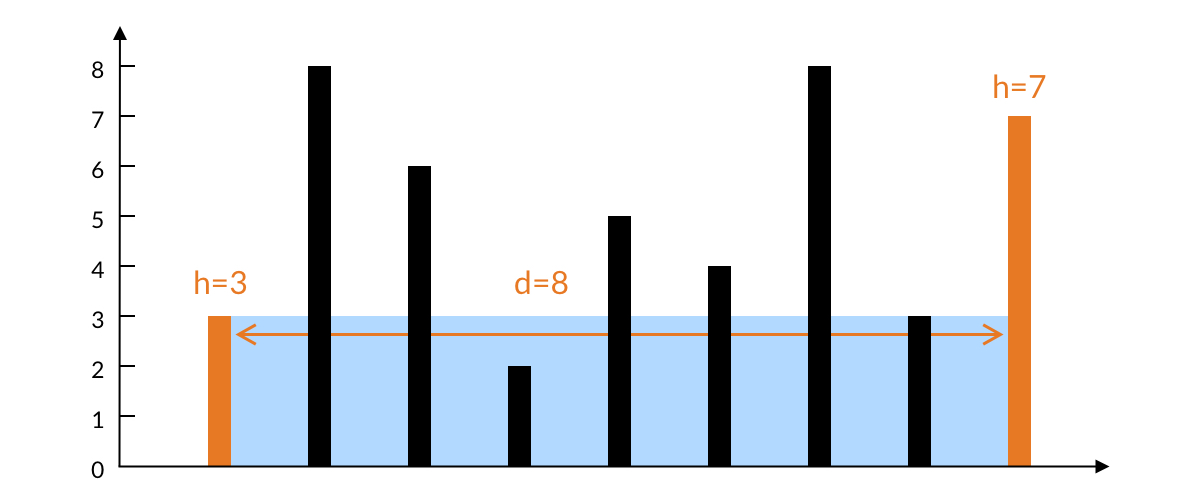 |
当前容量能否有继续扩大的可能,总是由“能否找到比当前最短木板更高的木板”来决定 |
接雨水  |
法一:动规—— 1. 先用两个不同方向的循环分别计算出i位置的左侧最高和右侧最高 1. 再循环一次,分别计算i位置能容纳的水量 |
 | 法二:左右夹逼双指针——
| 法二:左右夹逼双指针——
和动规类似,只不过是只用了两个变量分别表示leftMax和rightMax,在指针夹逼的过程中,不断更新leftMax和rightMax |
| 生命游戏 | 遍历一遍历,针对每个单元格,统计周转八个邻格的存活状态,并据此更新当前细胞状态 | 注意,要区分新旧状态避免状态污染。 例如原矩阵中,1表示存活,0表示死亡,但在遍历过程中,可把本轮复活的置为2,本轮死亡的置为-1. 最后大于0的都代表复活态,需恢复为1, 小于等于0的都代表死亡态,恢复为0 |
| 缺失的第一个正数 | 显然由于数组一共有n个元素,因此数组内缺失的最小正数,一定位于[1,n]内,可以配合下标范围处理,具体使用三轮循环:
|
| 生命游戏 | 遍历一遍历,针对每个单元格,统计周转八个邻格的存活状态,并据此更新当前细胞状态 | 注意,要区分新旧状态避免状态污染。 例如原矩阵中,1表示存活,0表示死亡,但在遍历过程中,可把本轮复活的置为2,本轮死亡的置为-1. 最后大于0的都代表复活态,需恢复为1, 小于等于0的都代表死亡态,恢复为0 |
| 缺失的第一个正数 | 显然由于数组一共有n个元素,因此数组内缺失的最小正数,一定位于[1,n]内,可以配合下标范围处理,具体使用三轮循环:
1. 把[1,n]范围外的值置为n+1; 2. 把[1,n]范围内的值映射到[0,n-1]的下标范围,并把对应下标值置负; 3. 顺序遍历,若nums[i]>0,则i+1即是结果
|  |
| 最长连续序列 |
|
| 最长连续序列 |
1. 排序后动规, 
1. 哈希表, 
|
1. 动规思路:针对排序数组,dp[i]表示以nums[i]作为结尾的最长子序列长度, 则:
1. 当 ,
,
1. 当 ,
, 
2. 哈希表思路: 将数组元素全部装入Set中,然后遍历此Set,当遍历到n时,如果Set不包含n-1,即表示当前元素n是一个新起点,此时在内循环中不断查找n+1, n+2, …等是否存在,并更新子序列长度。
|
| 寻找重复数 | 长度为n+1的数组,元素范围是[1,n],有一个重复数,是谁呢?
由于值域: ,而下标域:
,而下标域: ,因此
,因此 .
.
i->y的关系可看成是一个链表,索引i为节点,值为next指针,问题转化为“判断环形链表入口”。故使用快慢指针即可。
理解 :因[1,n]内存在重复数,就会得到相同下标,因此就会出现多个节点指向同一个下标
总结: 若题目给一个数组,且数组中的元素的取值范围与数组下标范围有一个明确的对应关系时,就可考虑使用下标这一隐含映射关系 |  |
| 基本计算器II | 思路:中缀表达式转后缀表达式,然后再用栈来解决,优化点:不一定要做实际转换,相当于一边转后缀一边计算结果。
|
| 基本计算器II | 思路:中缀表达式转后缀表达式,然后再用栈来解决,优化点:不一定要做实际转换,相当于一边转后缀一边计算结果。
具体转换方法:遍历原表达式——
- 如果是数字,则入数字栈;须保证数字的完整性
- 如果是 ‘(‘ ,则入符号栈;
- 如果是’)’,则循环出栈两数一符,计算后入数字栈,直至栈空或遇到’(‘
- 如果是+-/,则判断栈顶是否为高优运算符(同级算高优,因前者优先):
- 若是高优运算符,则出栈两数一符,运算后再入栈,最后当前符入栈
- 否则当前符直接入栈
- 栈不空,则不断出栈两数一符执行运算后压栈。最后栈中数字即为结果
|  |
| 字符串解码
|
| 字符串解码 | 此题的本质是考察栈,和基本计算器II的思路是一样的:
| 此题的本质是考察栈,和基本计算器II的思路是一样的:
- 遇到非”]”,则持续入栈,
- 遇到”]”,则出栈,直到”[“
- 出栈时,遇到完整数字,需要将临时字符串替换成一个新的字符串,然后再压栈
| |
| 滑动窗口最大值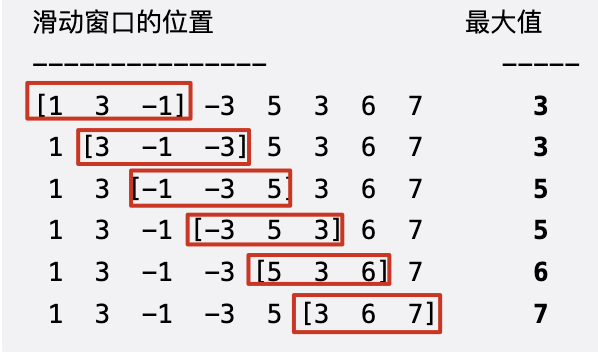 | 大顶堆+滑动窗口, 堆中元素:
| 大顶堆+滑动窗口, 堆中元素:
初始化前k个元素以构建初始窗口,每次新元素入堆时,都要将下标过期的堆顶元素干掉。然后新的堆顶元素即是当前窗口的合法最大值 |  |
| 数组中的逆序对 | 归并排序(递归划分再合并),在并的过程中统计逆序对。
|
| 数组中的逆序对 | 归并排序(递归划分再合并),在并的过程中统计逆序对。 |
|  |
| 计算右侧小于当前元素的个数 | 最直观思路:与求逆序对数的题类似,但不要搞混了, 这里的要注意理解这几个场景:
|
| 计算右侧小于当前元素的个数 | 最直观思路:与求逆序对数的题类似,但不要搞混了, 这里的要注意理解这几个场景:
- 场景1:只剩左边时,如:[x,x,5,6] | [x,x,x,x],此时5和6必然大于右边已合并的所有数,即5和6与右侧已合并的数均构成逆序关系,所以合并时,5和6的位置都应加上(right-mid);
- 场景2:n[i]<=n[j],如:[x,x,3,6] | [x,3,5,8], 此时要合左侧的3,而3必大于右边已合并的所有数,即,3与右侧已合并的数均构成逆序,故合3时,3的位置应加上(j-mid-1)
- 场景3:只剩右边时,如: [x,x,x,x] | [x,4,5,8],此时要合4、5、8,他们是升序的,且合并后仍在结果的右侧,后边不会有比他们更小的,故他们的位置的逆序数一定均为0,
- 场景4: n[i]>n[j],如: [x,x,5,6] | [x,x,4,7],此时要合4,而4虽然也必大于左边已合并的所有数,但4本来就在后边,相关于左边已合并的数来说本就是升序的,因此逆序数也一定是0
因此,场景3、4可以忽略, 统计结果是相对于每一个原始索引位置而言的,而归并过程又是依据原始索引位置对应数据的大小 | 
 |
| 计算右侧小于当前元素的个数(便于理解版) | 思路同上,只不过本方法将索引和值打包成了一个元素对象:
|
| 计算右侧小于当前元素的个数(便于理解版) | 思路同上,只不过本方法将索引和值打包成了一个元素对象: |
|  |
| 每日温度
|
| 每日温度
(计算右侧大于当前元素的第一个的位置) | 单调递减栈, 栈中只用保存元素下标即可
依次入栈,如果当前元素比栈顶元素大了,则证明栈中元素遇到了右侧更大值,此时挨个出栈直到栈顶小于当前元素即可。出栈过程中,依次得到位置值:i-popIdx | |
| 转变数组后最接近目标值的数组和 | 将数组中所有大于 value 的值变成 value 后,数组的和最接近给定的target值,求此value
- 解法一:排序+前缀和+二分查找。
- 解法二:先按递增排序;然后一趟遍历,发现当下值大于(目标值减去累加和除以剩下个数的值)时,则返回剩余的平均值
- 解法三(推荐): 纯粹二分法, 本质是暴力尝试所有的value,通过二分优化,在0和max之间夹逼得到bestValue
| 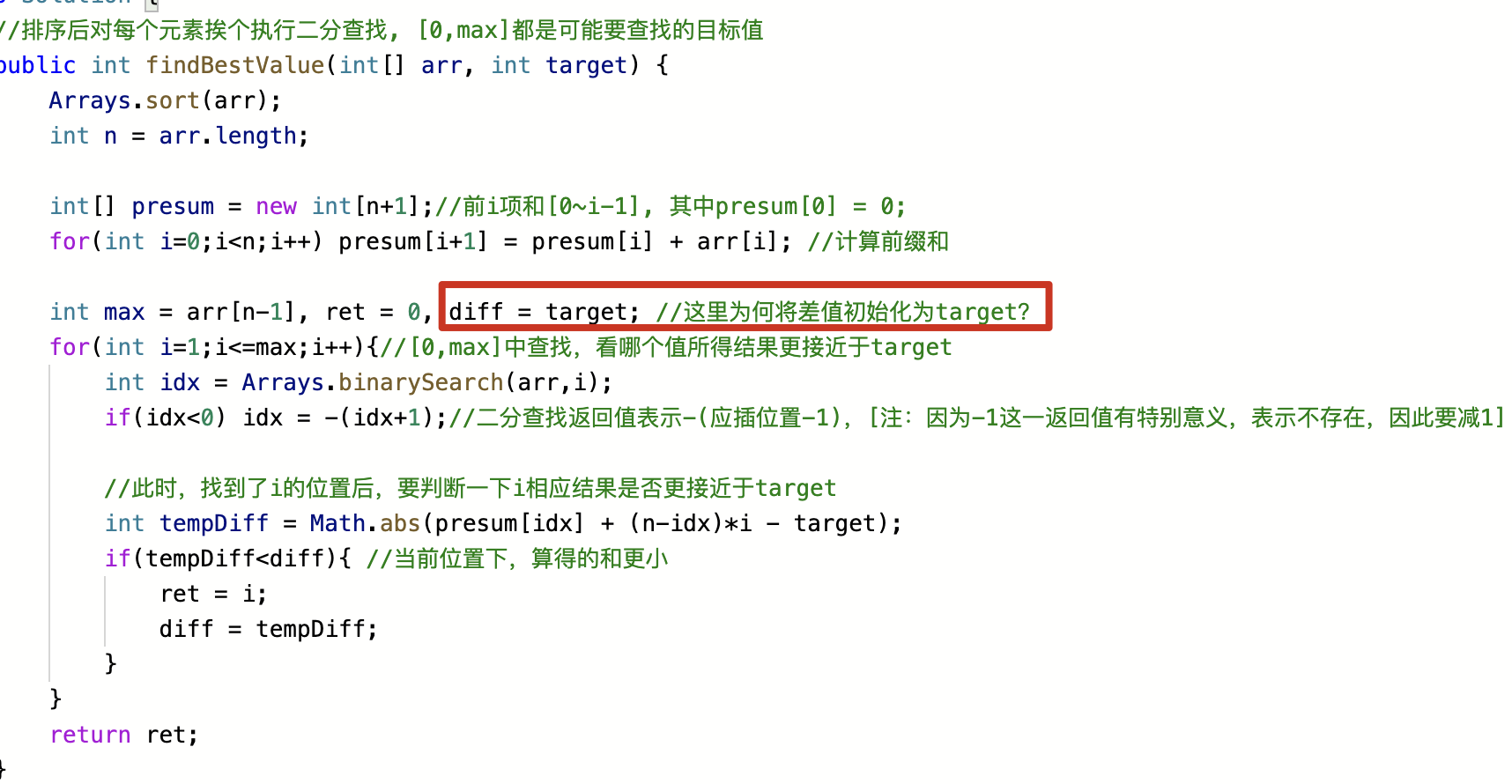 |
| 和可被K整除的连续子数组 | 前缀和: (sum[j+1]-sum[i])%k=0时表示sum[i~j]能被k整除, 即需要满足*同余
|
| 和可被K整除的连续子数组 | 前缀和: (sum[j+1]-sum[i])%k=0时表示sum[i~j]能被k整除, 即需要满足*同余
- 具体做法:声明一个余数的频次Map,将每一项前缀和对K的余数作为key,来记录频次。同余的频数和即为结果
- 注意点:前缀和可能为负数,在求余时需要纠正为正数:
余数+k后再对k求余: int yushu = (presum%k+k)%k | 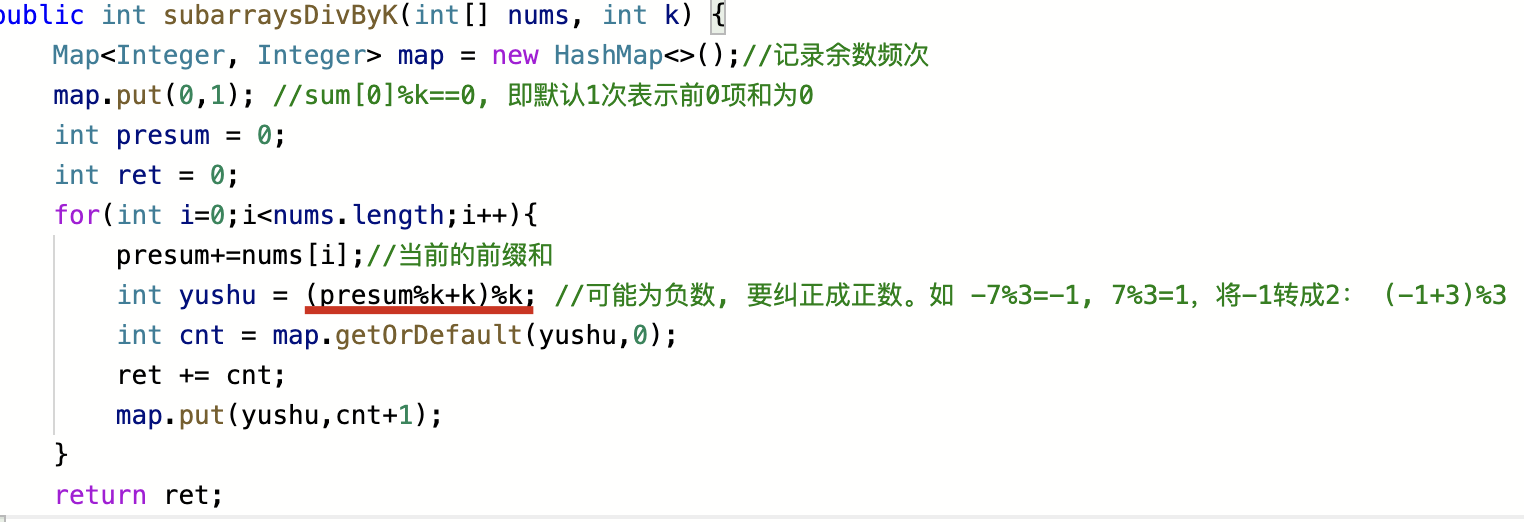 |
| 和为K的子数组 | 前缀和,思路同上, (sum[j]-sum[i])=k时表示arr[i~j]是符合条件的子数组
|
| 和为K的子数组 | 前缀和,思路同上, (sum[j]-sum[i])=k时表示arr[i~j]是符合条件的子数组
- 具体作法:声明一个 key = sum[i]的前缀和频次Map,然后一遍历循环找到key = sum[j]-k的频次,累加到结果中即可
|  |
| | | |
| | | |
| | | |
| | | |
|
| | | |
| | | |
| | | |
| | | |

若有收获,就点个赞吧
0 人点赞
