三种常见的索引模型
- 哈希表
- key->value的数据存储结构,只要输入对应的key,就可以查找对应其对应的值value。
- 哈希的思路很简单,就是把值放在一个数组里,用一个哈希函数把key换算成一个确定的位置。然后把value放在这个数组的这个位置。
- 不可避免的,多个key经过哈希函数的计算,会出现同一个值的情况<哈希冲突>。处理这种情况的发放就是拉出一个链表。
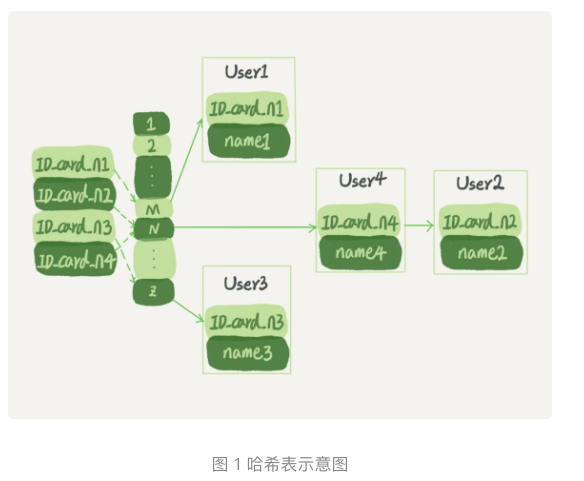
- 好处是插入数据的时候会很快,缺点是,因为不是有序的,哈希索引做区块查询的速度是很慢的。
- 哈希表这种结构适用于只有等值查询的场景。
- 有序数组
- 在等值查询和范围查询中的性能是比较优秀的。
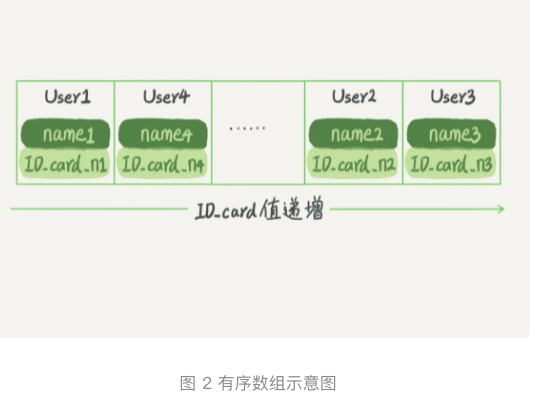
- 假设身份证号码没有重复的,这个数组按照身份证号码递增的顺序保存着。如果想要查某个身份证号码对应的name,用二分法就可以快速查找到。时间复杂度为O(log(N))。
- 支持范围查询。如果仅看查询效率的话,有序数组就是最好的数组结构。但是在更新插入的时候成本比较高,插入一条记录,就要挪动后面所有的记录。
- 有序数组只适用于静态引擎。比如保存过去某一年某个城市人口信息,这种不会修改的数据。
二叉搜索树
在innodb中,表都是根据主键顺序以索引的形式存放的。这种存储结构成为索引组织表,innodb使用了B+树索引模型,所以数据都是存在B+树中的。
- 每一个索引在innodb中都对应一棵B+树。

- 索引类型分为主键索引和非主键索引
- 主键索引:叶子节点存放的是整行的数据,在innodb里,主键所以也成为聚蔟索引
。 - 非主键索引: 叶子节点存放的是主键的值,在innodb里,非主键索引也成为二级索引
。
- 主键索引:叶子节点存放的是整行的数据,在innodb里,主键所以也成为聚蔟索引
- 基于主键索引跟普通索引查询的区别
- 如果语句是select * from t where id =1;即主键查询方式,则只需要搜索id这棵B+树。
- 如果语句是select * from t where age = 10;即普通查询索引方式,则需要先搜索age索引树,获取到对应的id值,然后再到id索引树搜索一次,这个过程称为回表。
- 基于非主键索引的查询,需要多扫描一棵索引树,一般尽量使用主键查询。
- 索引类型分为主键索引和非主键索引
- 索引维护
- B+树为了维护索引的有序性,在插入新值的时候做必要的维护。
- 已图4为例,如果插入新的行id=700,则只需要在R5后面插入一条新记录。如果插入的新的行的id=400,就相对麻烦,需要逻辑上挪动后面的数据,空出位置。
- 如果R5所在的数据页已经满了,根据B+树的算法,那么就需要申请一个新的数据页,然后挪动部分数据过去,这个过程称为页分裂。<性能会降低>
- 除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页上的数据,现在分到两个页中,整体空间利用率大概降低了50%。
- 当相邻两个页删除了数据之后,利用率很低之后,会将数据页做合并。合并的过程,可以认为是分裂过程的逆过程。
- B+树为了维护索引的有序性,在插入新值的时候做必要的维护。

若有收获,就点个赞吧
0 人点赞
