- sort_buffer:mysql会给每个线程分配一块内存用于排序。
- select city,name,age from t where city=’杭州’ order by name limit 1000;
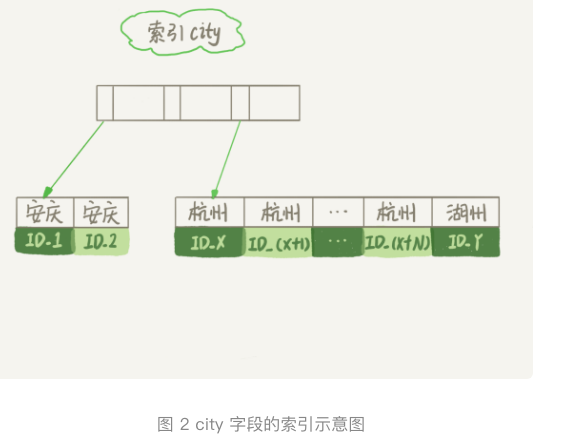
- 满足city=杭州条件的行是从id.x到id.(x+n)的这些记录,语句执行顺序为:
- 初始化sort_buffer,确定放入city name age这三个字段。
- 从索引city找到第一个满足 city=’杭州’的主键id
。 - 到主键id索引取出整行,取name、city、age三个字段的值,放入sort_buffer中。
- 从索引city取下一个记录的主键id。
- 重复iii、iv直到city的值不满足查询条件为止,对应的主键id也就是图中的id.y。
- 对sort_buffer中的数据按照字段name做快速排序。
- 按照排序结果取出1000行返回给客户端。
- 按name排序这个动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数sort_buffer_size。
- sort_buffer_size就是mysql为排序开辟的内存(sort_buffer)的大小。
- 如果排序的数据量小于sort_buffer_size,排序就在内存中完成。
- 如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
- 全字段排序缺点:返回字段很多的话,内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能很差。
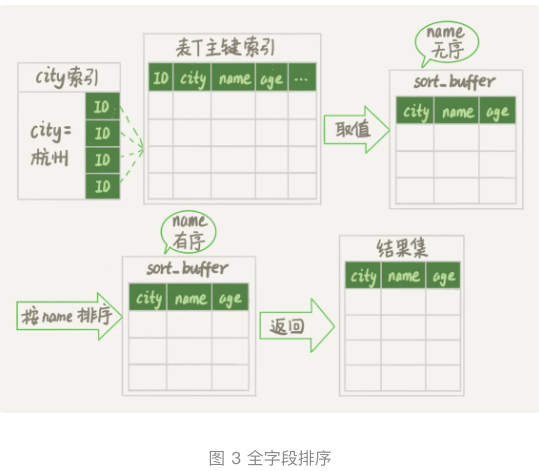
- rowid排序执行流程为:

- 初始化sort_buffer,确认放入两个字段,name和id。
- 从索引city找到第一个满足city=’杭州’条件的主键id,图中的id.x。
- 到主键id索引取整行数据,取name、id这两个字段,存入sort_buffer中。
- 从索引city取下一条记录的主键id。
- 重复iv、v知道不满足city=’杭州’条件为止,也就是图中ID_y。
- 对sort_buffer中的数据按照字段name进行排序。
- 遍历排序结果,取前1000行,并按照id的值回到原表中取出city、name和age三个字段返回给客户端。
- rowid排序多访问了一次表t的主键索引。
- 全字段排序VSrowid排序
- 如果内存小,会影响排序效率,会采用rowid排序算法,这样排序过程中一次可以排序更多的行,但是需要再回到原表取数据。
- 如果内存足够大,会优先选择全字段排序,把需要的字段都放到sort_buffer中,这样排序后就会直接从内存里面返回查询结果了,不用再回到原表取数据。
- 对于innodb来说,rowid排序会要求回表多造成磁盘读,因此不会被优先选择。
- 并不是所有的order by语句,都需要排序操作的,mysql之所以需要生成临时表,并且在临时表上做排序操作,原因是原来的数据都是无序的。
- 如果能够保证从city这个索引上取出来的行,天然就是按照name递增排序的,就可以不用再排序
- 在city、name创建一个联合索引- city_user(city,name)

- 可以用树搜索的方式定位到第一个满足city=’杭州’的记录,并且而外确保了,接下来按顺序去的的下一条记录的遍历过程中,只要city是杭州的,name的值就一定是有序的。
- 查询流程为:
- 从索引(city,name)找到第一个满足city=’杭州’条件的主键id。
- 到主键id索引取出整行,取出name、city、age三个字段的值,作为结果集的一部分直接返回。
- 从索引(city,name)取下一个记录主键id。
- 重复ii、iii,直到查到第1000条记录,或者是不满足city=’杭州’条件时循环结束。
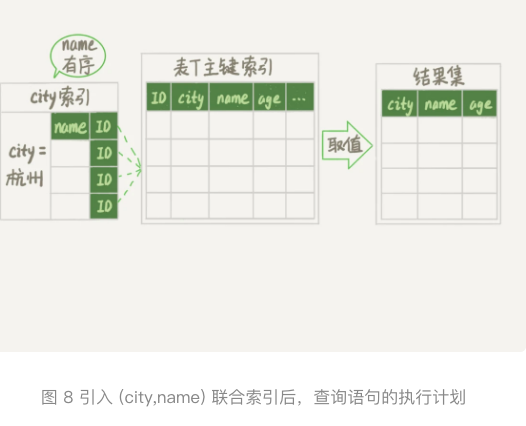
- 整个查询过程不需要临时表,也不需要排序。
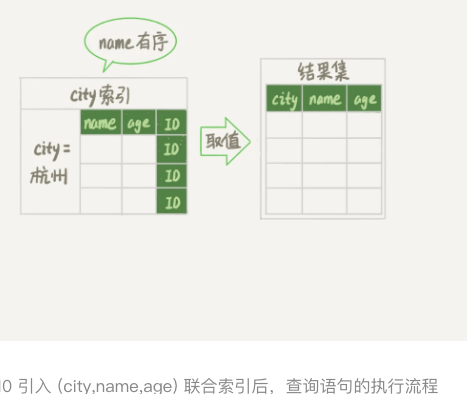
- 再次优化,创建一个city、name、age的联合索引 city_user_age(city,name,age)
- 对于city字段的值相同的行来说,还是按照name字段的值递增排序的,此时的查询语句也不在需要排序了
- 执行流程为:
- 从索引(city,name,age)找到第一个满足city=’杭州’条件的记录,取出其中的city、name、age这个三个字段的值,作为结果集的一部分直接返回。
- 从索引(city,name,age)取出满足条件的记录,同样把city、name、age三个字段的值,作为结果集的一部分返回。
- 重复ii步骤,知道取到1000行或者不满足city=’杭州’的条件结束。
- 覆盖索引(using index):索引上的信息足够满足查询请求,不需要再回到主键索引上取数据。
- 文件排序(using filesort):本次查询语句中有order by,且排序依照的字段不在本次使用的索引中,不能自然有序。需要进行额外的排序工作。
- 索引下推(using index condition):虽然本次查询所需的数据,不能从利用的索引上完全取得,还是需要回表去主索引获取,但在回表前,充分利用索引中的字段,根据where条件进行过滤,提前排序了不符合查询条件的列,减少了回表次数,提高了效率。
- using where: 本次查询要进行筛选过滤。ß

若有收获,就点个赞吧
0 人点赞
