我去,为什么最左前缀原则失效了?_Java技术栈的博客-CSDN博客
NULL
IP存储
在看高性能MySQL第3版(4.1.7节)时,作者建议当存储IPv4地址时,应该使用32位的无符号整数(UNSIGNED INT)来存储IP地址,而不是使用字符串。 但是没有给出具体原因。为了搞清楚这个原因,查了一些资料,记录下来。 相对字符串存储,使用无符号整数来存储有如下的好处: 通常,在保存IPv4地址时,一个IPv4最小需要7个字符,最大需要15个字符,所以,使用VARCHAR(15)即可。 MySQL在保存变长的字符串时,还需要额外的一个字节来保存此字符串的长度。而如果使用无符号整数来存储,只需要4个字节即可。 另外还可以使用4个字段分别存储IPv4中的各部分,但是通常这不管是存储空间和查询效率应该都不是很高(可能有的场景适合使用这种方式存储)。 使用字符串和无符号整数来存储IP的具体性能分析及benchmark,可以看这篇文章。 使用无符号整数来存储也有缺点:
- 不便于阅读
- 需要手动转换
MySQL ip 转换函数
对于转换来说,MySQL提供了相应的函数来把字符串格式的IP转换成整数INET_ATON,以及把整数格式的IP转换成字符串的INET_NTOA。如下所示:
对于IPv6来说,使用VARBINARY同样可获得相同的好处,同时MySQL也提供了相应的转换函数,即INET6_ATON和INET6_NTOA。
mysql> select inet_aton('192.168.0.1');+--------------------------+| inet_aton('192.168.0.1') |+--------------------------+| 3232235521 |+--------------------------+1 row in set (0.00 sec)mysql> select inet_ntoa(3232235521);+-----------------------+| inet_ntoa(3232235521) |+-----------------------+| 192.168.0.1 |+-----------------------+1 row in set (0.00 sec)mysql> select inet_aton('192.168.0.1');+--------------------------+| inet_aton('192.168.0.1') |+--------------------------+| 3232235521 |+--------------------------+1 row in set (0.00 sec)mysql> select inet_ntoa(3232235521);+-----------------------+| inet_ntoa(3232235521) |+-----------------------+| 192.168.0.1 |+-----------------------+1 row in set (0.00 sec)
Java转换工具类
对于转换字符串IPv4和数值类型,可以放在应用层,下面是使用java代码来对二者转换:java
/**
* @author Mikan
*/
public class IpLongUtils {
/**
* 把字符串IP转换成long
*
* @param ipStr 字符串IP
* @return IP对应的long值
*/
public static long ip2Long(String ipStr) {
String[] ip = ipStr.split("\\.");
return (Long.valueOf(ip[0]) << 24) + (Long.valueOf(ip[1]) << 16)
+ (Long.valueOf(ip[2]) << 8) + Long.valueOf(ip[3]);
}
/**
* 把IP的long值转换成字符串
*
* @param ipLong IP的long值
* @return long值对应的字符串
*/
public static String long2Ip(long ipLong) {
StringBuilder ip = new StringBuilder();
ip.append(ipLong >>> 24).append(".");
ip.append((ipLong >>> 16) & 0xFF).append(".");
ip.append((ipLong >>> 8) & 0xFF).append(".");
ip.append(ipLong & 0xFF);
return ip.toString();
}
public static void main(String[] args) {
System.out.println(ip2Long("192.168.0.1"));
System.out.println(long2Ip(3232235521L));
System.out.println(ip2Long("10.0.0.1"));
}
}
java
3232235521
192.168.0.1
167772161
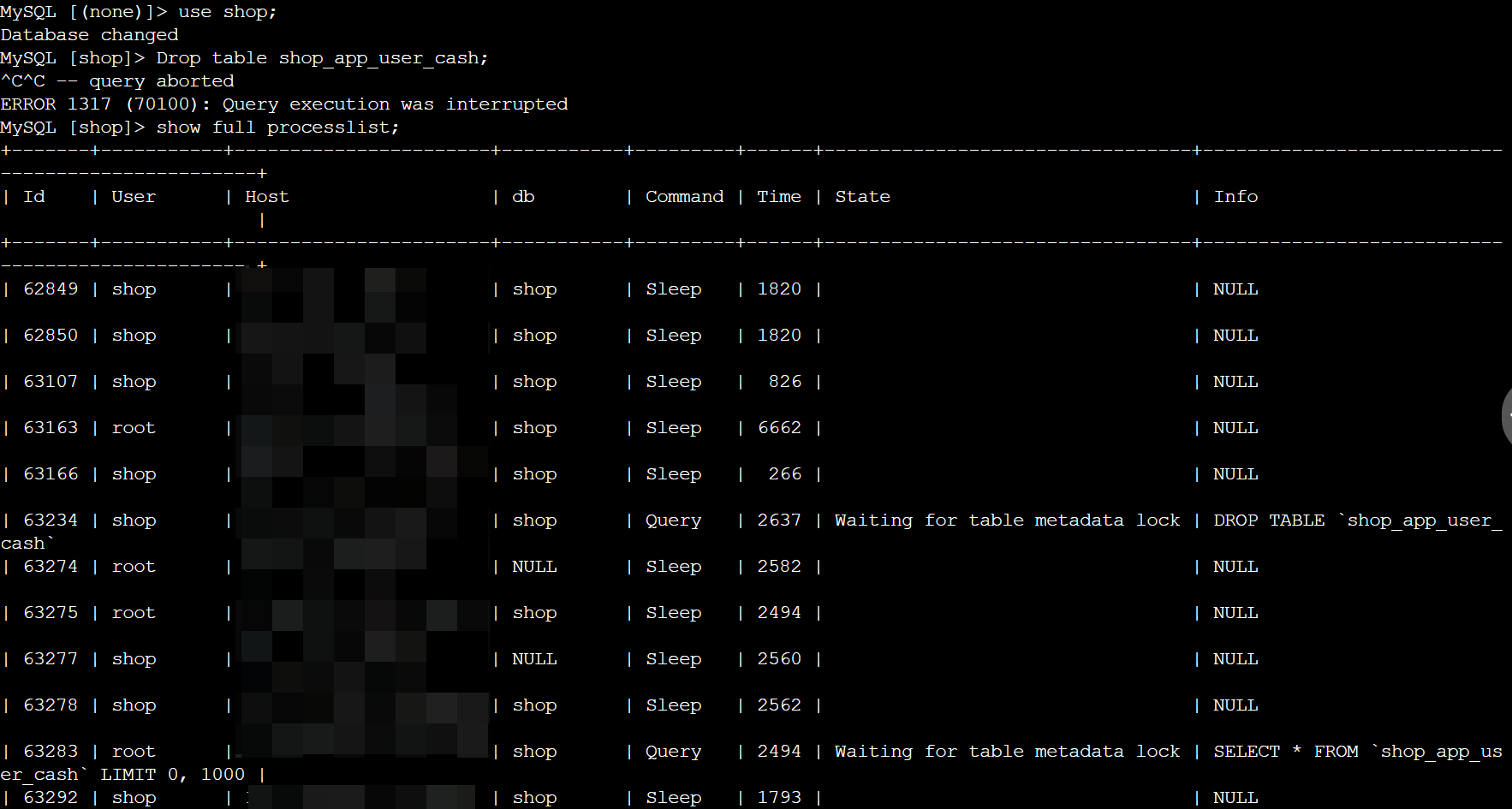
# DDL操作时,出现Waiting for table metadata lock
一旦alter table TableA的操作停滞在Waiting for table metadata lock的状态,后续对TableA的任何操作(包括读)都无法进行,因为他们也会在Opening tables的阶段进入到Waiting for table metadata lock的锁等待队列。
如果是产品环境的核心表出现了这样的锁等待队列,就会造成灾难性的后果。
造成alter table产生Waiting for table metadata lock的原因其实很简单,一般是以下几个简单的场景:
场景一:长事务运行,阻塞DDL,继而阻塞所有同表的后续操作
通过 show full processlist 可以看到TableA上有正在进行的操作(包括读),此时alter table语句无法获取到metadata 独占锁,会进行等待。 这是最基本的一种情形,这个和mysql 5.6中的online ddl并不冲突。一般alter table的操作过程中(见下图),在after create步骤会获取metadata 独占锁,当进行到altering table的过程时(通常是最花时间的步骤),对该表的读写都可以正常进行,这就是online ddl的表现,并不会像之前在整个alter table过程中阻塞写入。处理方法: kill 掉 DDL所在的session. kill id 比如:kill 63234
可以编写shell脚本,kill 大量堵塞操作
方案一(两个步骤):
1、查询所有堵塞操作
kill_thread_id.sql:
#!/bin/bashmysql -u root -e "show processlist" | grep -i "Locked" >> locked_log.txtfor line in `cat locked_log.txt | awk '{print $1}'`doecho "kill $line;" >> kill_thread_id.sqldone
kill 66402982;kill 66402983;kill 66402986;kill 66402991;.....
2、**mysql>source kill_thread_id.sql**
方案二(一步即可):
for id in `mysqladmin processlist | grep -i locked | awk '{print $1}'`domysqladmin kill ${id}done
场景二:未提交事物,阻塞DDL,继而阻塞所有同表的后续操作
通过show processlist看不到TableA上有任何操作,但实际上存在有未提交的事务,可以在 information_schema.innodb_trx中查看到。在事务没有完成之前,TableA上的锁不会释放,alter table同样获取不到metadata的独占锁。小知识点:
我们可以用下面三张表来查原因: innodb_trx ## 当前运行的所有事务information_schema 数据库 保存了MySQL服务器所有数据库的信息。如数据库名,数据库的表,表栏的数据类型与访问权限等。再简单点,这台MySQL服务器上,到底有哪些数据库、各个数据库有哪些表,每张表的字段类型是什么,各个数据库要什么权限才能访问,等等信息都保存在information_schema表里面。
innodb_locks ## 当前出现的锁
innodb_lock_waits ## 锁等待的对应关系
处理方法:
通过 select from *information_schema.innodb_trx, 找到未提交事物的trx_mysql_thread_id, 然后 kill 掉,让其回滚。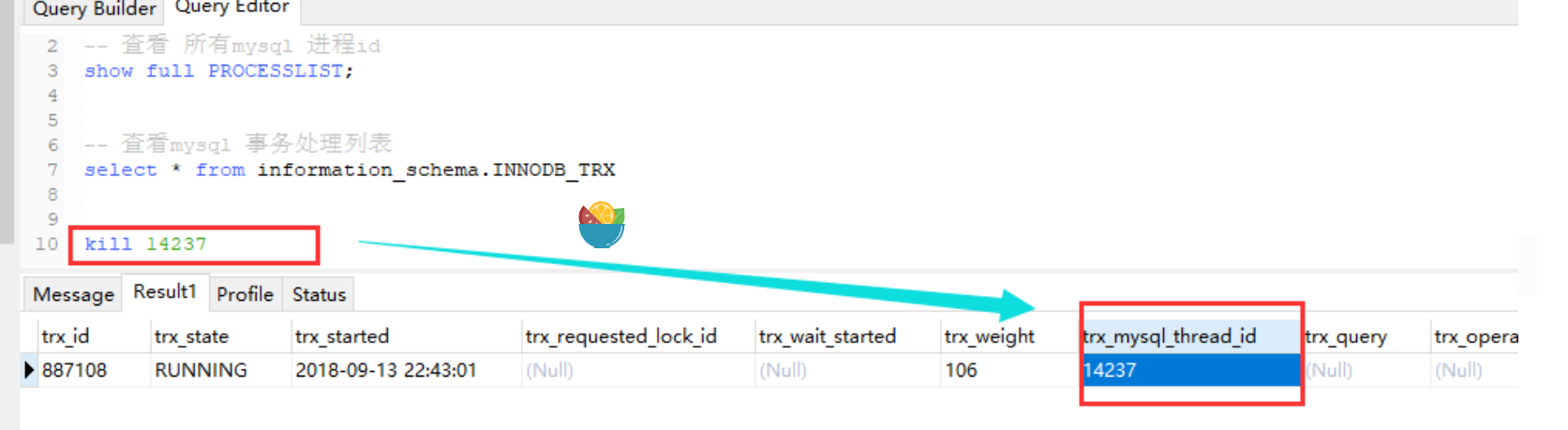
场景三:
通过show processlist看不到TableA上有任何操作,在information_schema.innodb_trx中也没有任何进行中的事务。这很可能是因为在一个显式的事务中,对TableA进行了一个失败的操作(比如查询了一个不存在的字段),这时事务没有开始,但是失败语句获取到的锁依然有效,没有释放。从select from *performance_schema.events_statements_current表中可以查到失败的语句。 官方手册上对此的说明如下: If the server acquires metadata locks for a statement that is syntactically valid but fails during execution, it does not release the locks early. Lock release is still deferred to the end of the transaction because the failed statement is written to the binary log and the locks protect log consistency. 也就是说除了语法错误,其他错误语句获取到的锁在这个事务提交或回滚之前,仍然不会释放掉。because the failed statement is written to the binary log and the locks protect log consistency 但是解释这一行为的原因很难理解,因为错误的语句根本不会被记录到二进制日志。
处理方法:
通过performance_schema.events_statements_current找到其sid, kill 掉该session. 也可以 kill 掉DDL所在的session.总结
alter table的语句是很危险的(其实他的危险其实是未提交事物或者长事务导致的),在操作之前最好确认对要操作的表没有任何进行中的操作、没有未提交事务、也没有显式事务中的报错语句。如果有alter table的维护任务,在无人监管的时候运行,最好通过lock_wait_timeout设置好超时时间,避免长时间的metedata锁等待。mysql大小写敏感配置
1.理论配置:mysql大小写敏感配置
mysql大小写敏感配置相关的两个参数,lower_case_file_system 和 lower_case_table_names。
查看当前mysql的大小写敏感配置
show global variables like ‘%lower_case%’;
+————————————+———-+
| Variable_name | Value |
+————————————+———-+
| lower_case_file_system | ON |
| lower_case_table_names | 0 |
+————————————+———-+
lower_case_file_system表示当前系统文件是否大小写敏感,只读参数,无法修改。ON 大小写不敏感 OFF 大小写敏感
lower_case_table_names表示表名是否大小写敏感,可以修改。
lower_case_table_names = 0时,mysql会根据表名直接操作,大小写敏感。
lower_case_table_names = 1时,mysql会先把表名转为小写,再执行操作。
设置lower_case_table_names的值
打开my.cnf文件,加入以下语句后重启。 lowercase_table_names = 0 或 lowercase_table_names = 112.实践配置(不同的case)
1、测试lower_case_table_names为0和1时的不同情况
创建表 user
CREATE TABLE user (
id int(11) unsigned NOT NULL AUTO_INCREMENT,
name varchar(20) NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
1.设置lower_case_table_names = 0
表名与创建时大小写一致
select count(*) from user;
+—————+
| count(*) |
+—————+
| 0 |
+—————+
表名与创建时大小写不一致
select count(*) from User;
ERROR 1146 (42S02): Table ‘user.User’ doesn’t exist
lower_case_table_names=0时,表名大小写敏感。
[
](https://blog.csdn.net/fdipzone/article/details/73692929)
2、设置lower_case_table_names = 1
表名与创建时大小写一致
select count(*) from user;
+—————+
| count(*) |
+—————+
| 0 |
+—————+
表名与创建时大小写不一致
select count(*) from User;
+—————+
| count(*) |
+—————+
| 0 |
+—————+
结论:
lower_case_table_names=1时,表名大小写不敏感。
3、设置lower_case_table_names=1时,原来在lower_case_table_names=0时创建的表提示不存在;
在lower_case_table_names=0时使用大小写混用创建表名,再设置lower_case_table_names=1后,原创建的表使用时会提示不存在。
演示
首先设置lower_case_table_names=0
创建表 User(大小写混用)
CREATE TABLE User (
id int(11) unsigned NOT NULL AUTO_INCREMENT,
name varchar(20) NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
show tables;
+————————+
| Tables_in_user |
+————————+
| User |
+————————+
再设置lower_case_table_names=1
执行查询,不管表名是大写还是小写,都提示表不存在
select * from User;
ERROR 1146 (42S02): Table ‘user.user’ doesn’t exist
select * from user;
ERROR 1146 (42S02): Table ‘user.user’ doesn’t exist
select * from USER;
ERROR 1146 (42S02): Table ‘user.user’ doesn’t exist
结论:
因为lower_case_table_names=1时,会先把表名转为小写后再操作,而文件中根本不存在小写的表名文件,因此出错。
解决方法:
如果要将lower_case_table_names从0修改为1时,应先对旧数据表的表名进行处理,把所有数据库的表名先改为小写,最后再设置lower_case_table_names为1,否则会出现上述的问题。
总结:
操作系统不同导致大小写敏感不一致。我们在开发时,应该按大小写敏感的原则去开发,这样可以使开发的程序兼容不同的操作系统。因此,建议在开发测试环境下把lower_case_table_names的值设为0,便于在开发中就严格控制代码大小写敏感,提高代码的兼容和严谨。
死锁
xxl-job发生报警,通过查看错误日志,发现是mysql死锁导致的,如图:
查看死锁日志
show engine innodb status 查看innodb引擎时间信息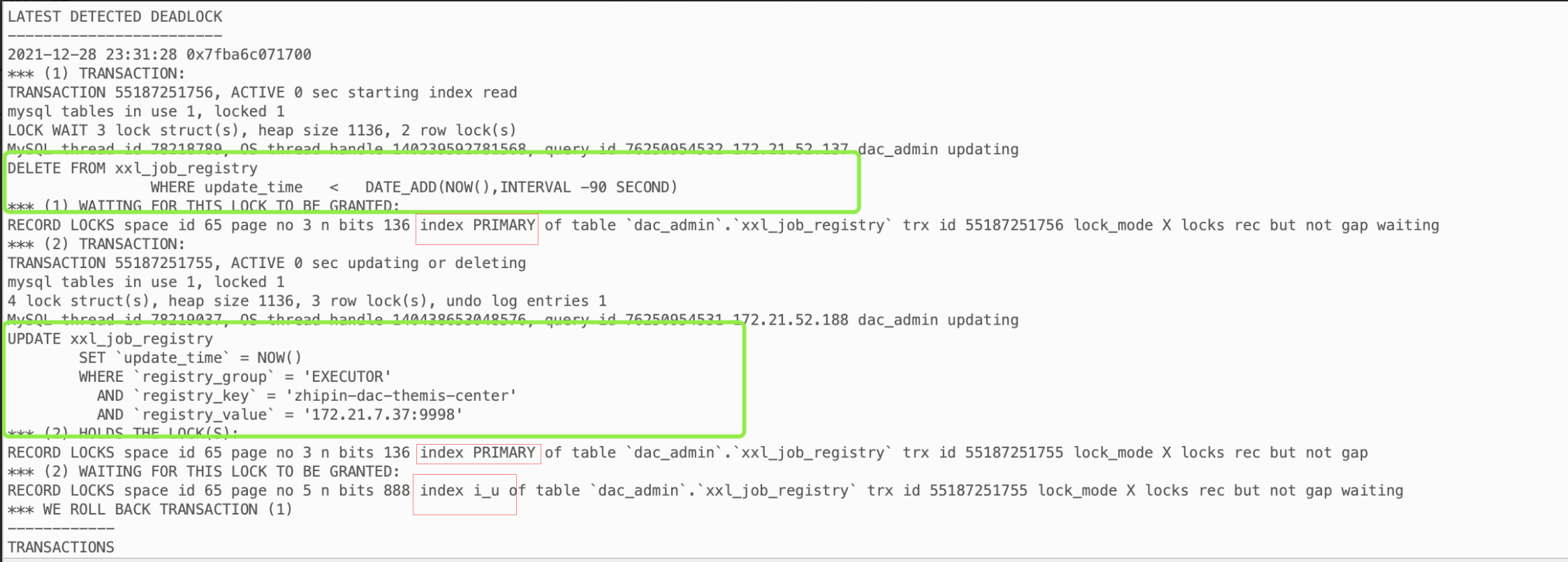
该表的索引

原因分析:
事务1:delete 语句 where 条件为 i_u 索引
事务2:update 语句 where 条件为 i_g_k_v 索引
可以看到该表有i_u普通索引和i_g_k_v联合索引也就是非主键索引; (2)死锁日志里可以看到,事务1 开始索引读,锁定i_u索引,等待主键索引的锁去执行delete操作; (3)事务2 持有三个字段的联合索引锁,会先锁住i_g_k_v索引,再根据主键去更新,获取主键上的行级锁,等待i_u索引去执行更新操作; (4)这样就是 事务1 锁定了i_u索引,等待主键索引,事务2 锁定i_g_k_v索引和主键索引,等待i_u索引,这样就导致了死锁。解决方法:
参考乐观锁:https://www.jianshu.com/p/ed896335b3b4 优化事务1的sql; 先根据时间查出符合条件的id、update_time 再按照id、update_time 删除记录 : 这样 事务1 就会首先持有行级锁 、同时也能防止 该条记录update_time已经更新的情况;参考博客:
https://blog.51cto.com/yanzongshuai/2142602
https://blog.csdn.net/weixin_45073171/article/details/107071103
https://www.cnblogs.com/hankyoon/p/14686498.html
索引过长问题
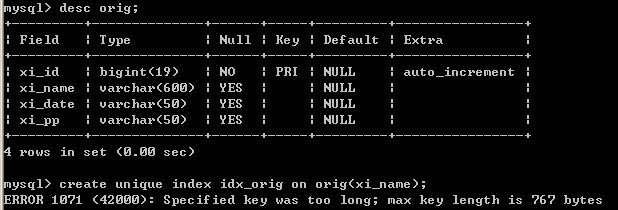
问题处理办法
在mysql中创建表的时候,有一列类型是varchar(600),数据库的字符集是utf-8,出现错误提示:ERROR 1071: Specified key was too long; max key length is 767 bytes 原因是utf-8的一个字符按三个字节来算,255个三个字节的字符总长度超过了767 bytes(有768 bytes)。 主要字符集的计算方式如下:
latin1 = 1 byte = 1 character
uft8 = 3 byte = 1 character
gbk = 2 byte = 1 character 可见,字符型的长度是根据你的编码有很大的关系。
在表关联中,类型隐式转换导致索引失效
SQL 调整前
explainselectpre.push_type,pre.cnt as request_pv,pre.cnt_uv as request_uv,pre.date8,pre.type,record.cnt as send_pv,record.cnt_uv as send_uv,app.cnt as outer_click_pv,app.cnt_uv as outer_click_uvfrompush_manage_pre_flink_sql preleft join push_manage_record_flink_sql record on record.push_type = pre.push_type and record.date8 = pre.date8left join app_push_record_flink_sql app on app.push_type = record.push_type and record.date8 = app.date8wherepre.type = 3and pre.app_type = 1and pre.date8 >= 20220424and pre.date8 <= 20220425and pre.push_type in (60018808)ORDER BYpre.date8 desclimit0, 20

SQL 调整后
app.push_type = record.pushType ——》 app.push_type =convert(record.pushType, char)

并发大量删除时范围扫描给第一个不符合条件记录加了锁导致锁等待超时
背景
目标
事情是这样的,最近公司需要统一更改一些老表的主键类型,以前表的主键都是 int 类型,这次要改成 bigint。避免 #「过早优化」
我整理的时候发现一张表,里面竟然有 5 亿的数据,之前排查问题优化过几条慢 sql,这个表的查询竟然没进慢 sql 名单,有点突破我的认知,平日使用也没啥问题。 后面还发现了好多张 3000w 到 8000w 的表,里面字段数量也比较正常,10个左右,也在好好的用着,所以不要死板的听网上说超过 1000w、2000w 就要分表啥的。避免 #「过早优化」 ,出了问题再处理才是王道,因为你提前做的一些准备,很大可能是无用功,浪费了感情和精力。
所遇到的问题&原因:
话说回 5 亿数据的这张表。当天晚上执行修改类型语句时,由于执行时间超过了自建 sql 平台的时间阈值(平台发现一条 sql 执行超过 2 小时就会主动关闭连接) 而这个修改类型的 modify 语句又不能分开执行,只能一次性执行,所以就尬住了。方案
方案一:是绕开 sql 平台, 让 dba 在外面直接执行,后面由于时间太晚了,所以就等第二天再说。 方案二:归档 到了第二天,分析了下这张表,发现其实之前的数据都是没用的,可以进行归档,也就是把 21 年的数据移到另一张表中,只留下 22 年的数据。
归档
这张表是有时间索引的。
我查了下 21 年的数据大概有 3 亿多,删除这些数据后,估计能减少一半多 modify 的时间,而且本身这张表也是要归档的,只是今年忘了做了(说明一直没遇到查询慢的问题)。 所以方案就变成,先进行数据归档,即 insert into 21年的数据到新表中,然后 delete 这张表里面 21 年的数据,然后再 modify 更改类型。 insert into 和 delete 语句都很简单,但是由于数据量太大,避免#「长事务」的问题,dba要求我们自行拆分 sql 语句给他执行。 当时我就寻思着:这拆分也得开发来拆?DBA 就仅仅是个无情的执行机器? 行吧,拆就拆,然后我就将 insert into 拆成了 100 条, delete 也拆成了 100 条给了 DBA。问题(锁超时):
当天晚上 DBA 又执行了一波,不过当时的 delete 有好几条失败了,他询问我,这个表当前还会有请求让其变更吗? 我说不可能,因为这张表相当于流水表,删除的是 21 年的数据,当前不可能有 21 年数据的变更,但确实是报错了,我看了下错误,#「锁超时」。 当时我就奇怪,为什么有锁等待超时,现在不可能有业务在操作 21年的数据。
当时我就奇怪,为什么有锁等待超时,现在不可能有业务在操作 21年的数据。
原因分析:
后面我才发现 DBA 是在并行执行多条 delete 语句。(起多个客户端)
于是,我在群里跟 DBA 说应该因为你并行执行多条 delete ,它们之前有竞争关系,而一条 delete 删除的数据挺多的,所以等锁等超时了。 DBA :有 id 范围限制的,delete 之间应该不会有冲突的。 我简化下,几条 delete 语句如下所示:看到这你可以思考一下,并行执行上面这几条 delete 语句,它们之间是否会发生竞争锁呢? 当前事务隔离级别为:可重复读隔离级别,mysql 版本5.7+ 答案是它们之间会冲突,会竞争锁。 一切拿事实说话,为了这个事实首先我们得有一张表。
delete from xxxxx where date < '2022-06-25' and (id >= 1 and id <10)delete from xxxxx where date < '2022-06-25' and (id >= 10 and id <20)delete from xxxxx where date < '2022-06-25' and (id >= 20 and id <30)
CREATE TABLE `xxxxx` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`name` varchar(45) DEFAULT NULL,`address` varchar(45) DEFAULT NULL,`date` date DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_date` (`date`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
小数据量演示
复现
先来看看小数据量,可以看到数据库就 5 条数据。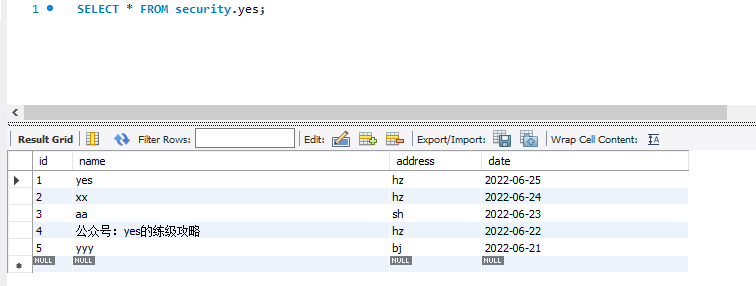 这时候我在客户端 A 执行一条 delete 语句:
delete from yes where date < ‘2022-06-25’ and (id > 1 and id <3)
不提交事务。
此时在客户端 B 执行另一条 delete语句:
delete from yes where date < ‘2022-06-25’ and (id >= 3 and id <5)
可以看到,此时发生了阻塞:
这时候我在客户端 A 执行一条 delete 语句:
delete from yes where date < ‘2022-06-25’ and (id > 1 and id <3)
不提交事务。
此时在客户端 B 执行另一条 delete语句:
delete from yes where date < ‘2022-06-25’ and (id >= 3 and id <5)
可以看到,此时发生了阻塞:
 是不是有点奇怪?看起来它们之间没有冲突的呀?
是不是有点奇怪?看起来它们之间没有冲突的呀?
查看锁
让我们执行下 select * from information_schema.innodb_locks;,看看锁的详情: 可以看到 lock_mode 是 X 锁,说明是#「排他锁」,然后 lock_type 是 RECORD 说明是#「行锁」。
可以看到 lock_mode 是 X 锁,说明是#「排他锁」,然后 lock_type 是 RECORD 说明是#「行锁」。
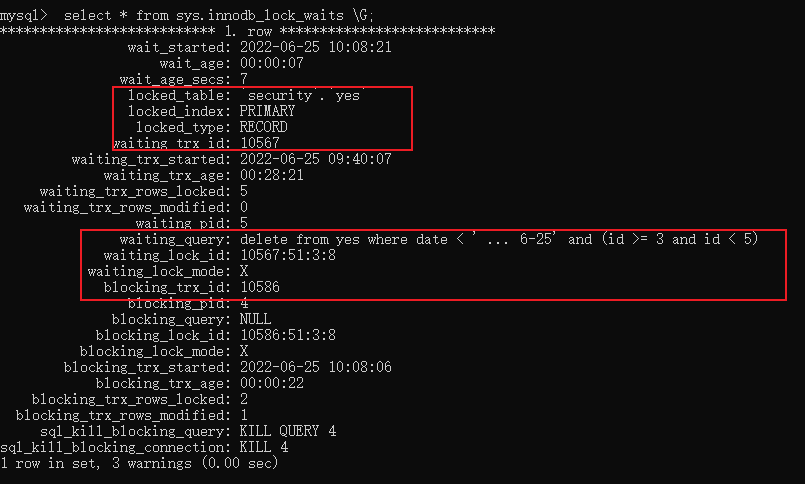 可以看到,确实是 10586 被阻塞了,对应的就是客户端 B 执行的那条语句。
可以看到,确实是 10586 被阻塞了,对应的就是客户端 B 执行的那条语句。
explain分析
我们来 explain 一下这个 delete 语句: 发现 delete 语句用的是主键索引,即使 date 列有索引能也能覆盖到条件字段(id),用的也是主键索引。
发现 delete 语句用的是主键索引,即使 date 列有索引能也能覆盖到条件字段(id),用的也是主键索引。
因为在可重复读隔离级别下,实际上范围加锁(id >1)规则是会往后遍历,直到扫描到不满足条件 即 id = 3 的那行,然后停止,因此这条语句最后扫描到的那行恰巧就是 id =3 的这一行,于是锁住了它。
此时另一条 delete 语句执行的时候是需要 id =3 这条记录的行锁(这个没啥疑问吧?),所以就竞争了,然后由于第一条语句 delete 的数据量大,所以执行的久,于是就触发了第二条的锁超时。 好了,通过小数据分析得到的结果已经和那天晚上执行的结果一致,其实到这已经可以结束了,但是为了严谨一些,现在我们拿大数据量来继续实验一次。大数据量演示
复现
为了更加真实,首先我多加了一些字段,然后随机插入了 1000w 数据: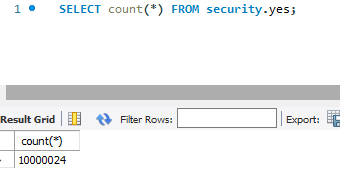

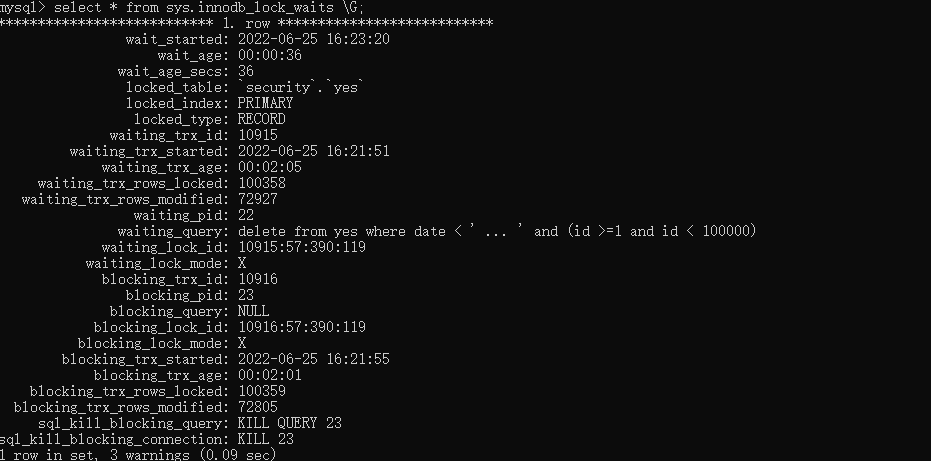 好了,大数据量的也测试过了,得到一样的结论,这样就能解释为啥当天并行执行多条 delete 语句会出现锁超时的情况。
好了,大数据量的也测试过了,得到一样的结论,这样就能解释为啥当天并行执行多条 delete 语句会出现锁超时的情况。
结论:
在可重复读隔离级别下,带上索引键和主键通过范围搜索条件来执行 delete 语句,不论数据量大还是小,mysql 都会利用主键索引来扫描记录(我猜测反正都要删数据,即本来就要删除二级索引和聚簇索引的数据,所以索性就用主键索引扫描?) 而范围扫描加锁的数据会扫到第一个不满足条件的记录,即第一个不满足条件的记录也会被上锁,因此并行删除的时候因为边界值产生了竞争关系,又由于 delete 语句执行的时间长,导致了 lock wait timeout 的报错。最后
话说今天随机插入数据的时候搞了我好久…写了个存储过程来插,但是执行了半天发生一直插不进去,一直在 runing,就非常的纳闷,想着一千万数据也不需要这么久的啊。 后面奇了怪了,于是新建了一张表,分分钟就插成功了。于是又回来看之前的表,看来看去看不出个所以然,于是准备把这张表删了,发现删都删不掉,最终发现我有个小窗口执行的语句把整个表锁了….所以怎么都插不进去。 话说回来,这 DBA 是真的懒,感觉他的活都不用动脑,搞啥都是 sql 平台上我们提交sql,由我们的技术负责人审核,审核过了,他在界面上点一下执行就行。 前面说的拆 SQL 这种非业务相关的也得我们拆,给他排的整整齐齐让他执行。 平时我们监控报警,什么数据库 CPU 报警了,也是报警到我们这边,由我们来看具体是什么导致的。 总之,不要过多信任 DBA,一切还是得靠自己,自己行才是真的行,包括 DBA 告诉你的一些结论,还是自己实验最为靠谱。You can’t specify target table
— 在MySQL中,写SQL语句的时候 ,可能会遇到You can’t specify target table ‘表名’ for update in FROM clause这样的错误,
— 它的意思是说,不能先select出同一表中的某些值,再update这个表(在同一语句中),即不能依据某字段值做判断再来更新某字段的值。
UPDATE t2 set c2= “6” WHERE id in (SELECT id from t2 where c1= “3”)
— 将SELECT出的结果再通过中间表SELECT一遍,这样就规避了错误。
— 需要注意的是,这个问题只出现于MySQL,MSSQL和Oracle不会出现此问题。
UPDATE t2 set c2= “6” WHERE id in (
SELECT a.id from
( SELECT id from t2 where c1= “3” ) a
)

若有收获,就点个赞吧
0 人点赞
