一 Google Protobuf
1.1 编码与解码
- 编写网络应用程序时,因为数据在网络中传输的都是二进制字节码数据,在发送数据时就需要编码,接收数据时就需要解码
- codec(编解码器) 的组成部分有两个:decoder(解码器)和 encoder(编码器)。encoder 负责把业务数据转换成字节码数据,decoder 负责把字节码数据转换成业务数据。

- Netty本身的编解码的机制和问题分析(为什么要引入Protobuf)
- Netty 提供的编码器
- StringEncoder,对字符串数据进行编码
- ObjectEncoder,对Java对象进行编码
- Netty 提供的解码器
- StringDecoder, 对字符串数据进行解码
- ObjectDecoder,对 Java 对象进行解码
Netty 本身自带的 ObjectDecoder 和 ObjectEncoder 可以用来实现 POJO 对象或各种业务对象的编码和解码,底层使用的仍是Java序列化技术 , 而Java 序列化技术本身效率就不高,存在如下问题
Protobuf 是以message的方式来管理数据的
- 支持跨平台、跨语言,即[客户端和服务器端可以是不同的语言编写的(支持目前绝大多数语言,例如 C++、C#、Java、python 等
- 高性能,高可靠性
- 使用 protobuf 编译器能自动生成代码,Protobuf 是将类的定义使用.proto 文件进行描述。说明,在idea 中编写 .proto 文件时,会自动提示是否下载 .ptotot 编写插件. 可以让语法高亮。
- 然后通过 protoc.exe 编译器根据.proto 自动生成.java 文件
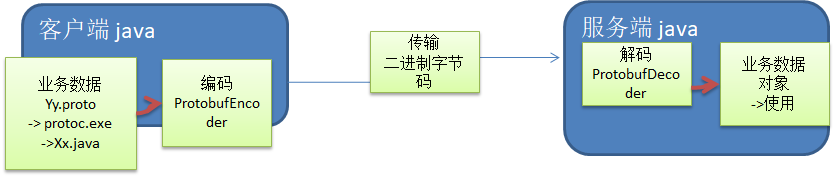
1.3 proto文件格式
首先我们需要在.proto文件中定义好实体及他们的属性,再进行编译成java对象为我们所用。下面将介绍proto文件的写法。
文件头 就想我们写java需要写package包名一样,.proto文件也要写一些文件的全局属性,主要用于将.proto文件编译成Java文件。
| 实例 | 介绍 |
|---|---|
| syntax=”proto3”; | 声明使用到的protobuf的版本 |
| optimize_for=SPEED; | 表示 |
| java_package=”com.mical.netty.pojo”; | 表示生成Java对象所在包名 |
| java_outer_classname=”MyWorker”; | 表示生成的Java对象的外部类名 |
我们一般将这些代码写在proto文件的开头,以表明生成Java对象的相关文件属性。
定义类和属性
syntax = "proto3"; //版本option optimize_for = SPEED; //加快解析option java_outer_classname = "MyDataInfo"; //生成的外部类名,同时也是文件名message Student { //会在StudentPojo 外部类生成一个内部类Student,他是真正发送的pojo对象int32 id = 1; //Student类中有一个属性名字为ID,类型为int32(protobuf类型),1表示序号,不是值string name = 2;}enum DateType {StudentType = 0; //在proto3中,要求enum的编号从0开始WorkerType = 1;}
如上图所示,我们在文件中不但声明了protobuf的版本,还声明了生成java对象的类名。当生成java对象后,MyDataInfo将是对象的类名,同时,它使用message声明了Student这个内部类,使用enum声明了DataType这个内部枚举类。就像下面这个样子
- messag:声明类。
- enum:声明枚举类。
然后需要注意的是,protobuf中的变量类型和其他语言的声明有所不同。下面是类型的对照表。public final class MyDataInfo {public static final class Student { }public enum DataType { }}
| .proto类型 | java类型 | C++类型 | 备注 |
|---|---|---|---|
| double | double | double | |
| float | float | float | |
| int32 | int | int32 | 使用可变长编码方式。编码负数时不够高效——如果你的字段可能含有负数,那么请使用sint32。 |
| int64 | long | int64 | 使用可变长编码方式。编码负数时不够高效——如果你的字段可能含有负数,那么请使用sint64。 |
| unit32 | int[1] | unit32 | 总是4个字节。如果数值总是比总是比228大的话,这个类型会比uint32高效。 |
| unit64 | long[1] | unit64 | 总是8个字节。如果数值总是比总是比256大的话,这个类型会比uint64高效。 |
| sint32 | int | int32 | 使用可变长编码方式。有符号的整型值。编码时比通常的int32高效。 |
| sint64 | long | int64 | 使用可变长编码方式。有符号的整型值。编码时比通常的int64高效。 |
| fixed32 | int[1] | unit32 | |
| fixed64 | long[1] | unit64 | 总是8个字节。如果数值总是比总是比256大的话,这个类型会比uint64高效。 |
| sfixed32 | int | int32 | 总是4个字节。 |
| sfixed64 | long | int64 | 总是8个字节。 |
| bool | boolean | bool | |
| string | String | string | 一个字符串必须是UTF-8编码或者7-bit ASCII编码的文本。 |
| bytes | ByteString | string | 可能包含任意顺序的字节数据 |
我们看到代码中string name = 2,它并不是给name这个变量赋值,而是给它标号。每个类都需要给其中的变量标号,且需要注意的是类的标号是从1开始的,枚举的标号是从0开始的。
复杂对象
当我们需要统一发送对象和接受对象时,就需要使用一个对象将其他所有对象进行包装,再获取里面的某一类对象。
syntax = "proto3"; //版本option optimize_for = SPEED; //加快解析option java_outer_classname = "MyDataInfo"; //生成的外部类名,同时也是文件名message MyMessage {//定义一个枚举类型enum DateType {StudentType = 0; //在proto3中,要求enum的编号从0开始WorkerType = 1;}//用data_type来标识传的是哪一个枚举类型DateType data_type = 1;//标识每次枚举类型最多只能出现其中的一个类型,节省空间oneof dataBody {Student stuent = 2;Worker worker = 4;}}message Student { //会在StudentPojo 外部类生成一个内部类Student,他是真正发送的pojo对象int32 id = 1; //Student类中有一个属性名字为ID,类型为int32(protobuf类型),1表示序号,不是值string name = 2;}message Worker {string name = 1;int32 age = 2;}
这里面我们定义了MyMessage、Student、Worker三个对象,MyMessage里面持有了一个枚举类DataType和,Student、Worker这两个类对象中的其中一个。这样设计的目的是什么呢?当我们在发送对象时,设置MyMessage里面的对象的同时就可以给枚举赋值,这样当我们接收对象时,就可以根据枚举判断我们接受到哪个实例类了。
1.4 Netty中使用Protobuf
需要给发送端的pipeline添加编码器:ProtobufEncoder。
bootstrap.group(group).channel(NioSocketChannel.class).handler(new ChannelInitializer<SocketChannel>() {@Overrideprotected void initChannel(SocketChannel ch) throws Exception {ChannelPipeline pipeline = ch.pipeline();pipeline.addLast("encoder", new ProtobufEncoder());pipeline.addLast(new ProtoClientHandler());}});
需要在接收端添加解码器:ProtobufDecoder
serverBootstrap.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class).handler(new LoggingHandler()).option(ChannelOption.SO_BACKLOG, 128).childOption(ChannelOption.SO_KEEPALIVE, true).childHandler(new ChannelInitializer<SocketChannel>() {@Overrideprotected void initChannel(SocketChannel ch) throws Exception {ChannelPipeline pipeline = ch.pipeline();//需要指定对哪种对象进行解码pipeline.addLast("decoder", new ProtobufDecoder(MyDataInfo.MyMessage.getDefaultInstance()));pipeline.addLast(new ProtoServerHandler());}})
在发送时,如何构造一个具体对象呢?以上面复杂对象为例,我们主要构造的是MyMessage对象,设置里面的枚举属性,和对应的对象。
MyDataInfo.MyMessage build = MyDataInfo.MyMessage.newBuilder().setDataType(MyDataInfo.MyMessage.DateType.StudentType).setStuent(MyDataInfo.Student.newBuilder().setId(5).setName("王五").build()).build();
在接收对象时,我们就可以根据枚举变量去获取实例对象了。
MyDataInfo.MyMessage message = (MyDataInfo.MyMessage) msg;MyDataInfo.MyMessage.DateType dataType = message.getDataType();switch (dataType) {case StudentType:MyDataInfo.Student student = message.getStuent();System.out.println("学生Id = " + student.getId() + student.getName());case WorkerType:MyDataInfo.Worker worker = message.getWorker();System.out.println("工人:name = " + worker.getName() + worker.getAge());case UNRECOGNIZED:System.out.println("输入的类型不正确");}
二 Handler
2.1 Handler介绍
- netty的组件设计:Netty的主要组件有Channel、EventLoop、ChannelFuture、ChannelHandler、ChannelPipe等
- 我们先来复习一下ChannelHandler和ChannelPipeline的关系。示例图如下:我们可以将pipeline理解为一个双向链表,ChannelHandlerContext看作链表中的一个节点,ChannelHandler则为每个节点中保存的一个属性对象。
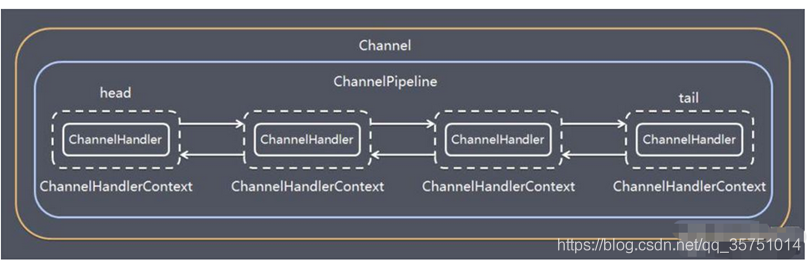
- ChannelHandler充当了处理入站和出站数据的应用程序逻辑的容器。例如,实现ChannelInboundHandler接口(ChannelInboundHandlerAdapter),你就可以接收入站事件和数据,这些数据会被业务逻辑处理。当要给客户端发送响应时,也可以从ChannelInboundHandler冲刷数据。业务逻辑通常写在一个或者多个ChannelInboundHandler中。ChannelOutboundHandler原理一样,只不过它是用来处理出站数据的
- ChannelPipeline提供了ChannelHandler链的容器。以客户端应用程序为例,如果事件的运动方向是从客户端到服务端的,那么我们称这些事件为出站的,即客户端发送给服务端的数据会通过pipeline中的一系列ChannelOutboundHandler,并被这些Handler处理,反之则称为入站的
- 简单来说,以服务器端为例:接受数据的过程就是入站,发送数据的过程就是出站。客户端也一样。
- 下面,来看看我们常用的Handler的关系图:Inbound处理入站,Outbound处理出站
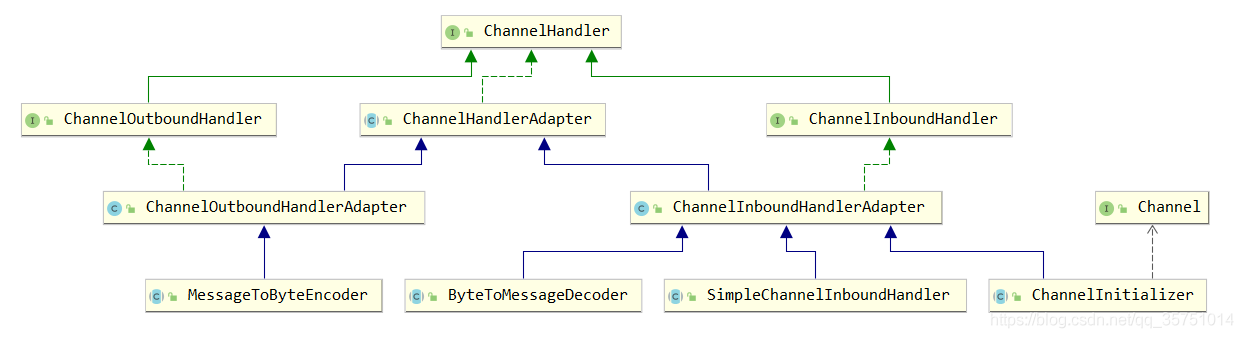
- 一般来说,在我们接收数据时将数据解码后,就进行业务的相关处理,所以上图的入站的常用类更多。在数据出站时,一般我们只需要将数据编码后直接发出。
2.2 Handler链式调用
我们知道,Pipeline中的Handler可以当作一个双向链表。但是Handler却又存在着入站和出站之分。那么Netty是如何将两种类型的Handler保存在一个链表中,却又能够入站的时候调用InboundHandler,出栈的时候调用OutBoundHandler呢?看下图,黄色的表示入站,以及入站的Handler,绿色的表示出站,以及出站的Handler。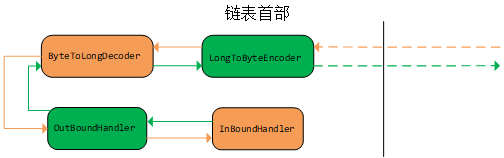
当我们调用如下代码时,我们就会获得一个上图所示的Handler链表。下面代码时在ChannelInitializer类中添加Handler的部分代码。
@Overrideprotected void initChannel(SocketChannel ch) throws Exception {ChannelPipeline pipeline = ch.pipeline();pipeline.addLast(new LongToByteEncoder()); //outpipeline.addLast(new ByteToLongDecoder()); //inpipeline.addLast(new OutBoundHandler()); //outpipeline.addLast(new InBoundHandler()); //in}
当一个请求来了的时候,首先会将请求发给pipeline中位于链表首部的Handler。如图所示,首先由LongToByteEncoder(这个东西不管,就是个出站的)接受到入站请求,但是这个东西是个OutBound。所以它收到入站请求时就不做处理,直接转发给它的下一个ByteToLongDecoder(这个东西也不管,它是入站的)。这个东西接受到了入站请求了,一看它自己也是一个Inbound,所以它就将请求的数据进行处理,然后转发给下一个。之后又是一个Outbound,然后再进行转发,到了最后的InBoundHandler,在这里我们可以进行业务的处理等等操作。
然后如果需要返回数据,我们就调用writeAndFlush方法,这个方法可不简单,当他一调用,就会触发出站的请求,然后就由当前所在的Handler节点往回调用。往回调用的途中,如果遇到InBound就直接转发给下一个Handler,直到最后将消息返回。
- 通过上面的描述,我们可以总结添加Handler的以下节点总结:
- 调用InboundHandler的顺序和添加的顺序是一致的。
- 调用OutboundHandler的顺序和添加它的顺序是相反的。
- 链表的末尾不能有OutHandler,因为如果最后是OutHandler的话,当他前面的InHandler处理完数据返回消息调用writeflush时,它直接在前面进行反向调用了,就调用不到最后的这个Out了。所以我们平常可以将OutHandler写在前面,InHandler写在后面。
InHandler一旦进行writeAndFlush,只有这个InHandler之前添加的OutHandler能够处理他
2.3 Handler编解码器
当Netty发送或者接受一个消息的时候,就将会发生一次数据转换。入站消息会被解码:从字节转换为另一种格式(比如java对象);如果是出站消息,它会被编码成字节。
- Netty提供一系列实用的编解码器,他们都实现了ChannelInboundHadnler或者ChannelOutboundHandler接口。在这些类中,channelRead方法已经被重写了。以入站为例,对于每个从入站Channel读取的消息,这个方法会被调用。随后,它将调用由解码器所提供的decode()方法进行解码,并将已经解码的字节转发给ChannelPipeline中的下一个ChannelInboundHandler。
解码器-ByteToMessageDecoder
由于不可能知道远程节点是否会一次性发送一个完整的信息,tcp有可能出现粘包拆包的问题,这个类会对入站数据进行缓冲,直到它准备好被处理。
下面是段示例代码:
public class ToIntegerDecoder extends ByteToMessageDecoder {@Overrideprotected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {if (in.readableBytes() >= 4) {out.add(in.readInt());}}}
这个例子,每次入站从ByteBuf中读取4字节,将其解码为一个int,然后将它添加到下一个List中。当没有更多元素可以被添加到该List中时,它的内容将会被发送给下一个ChannelInboundHandler。int在被添加到List中时,会被自动装箱为Integer。在调用readInt()方法前必须验证所输入的ByteBuf是否具有足够的数据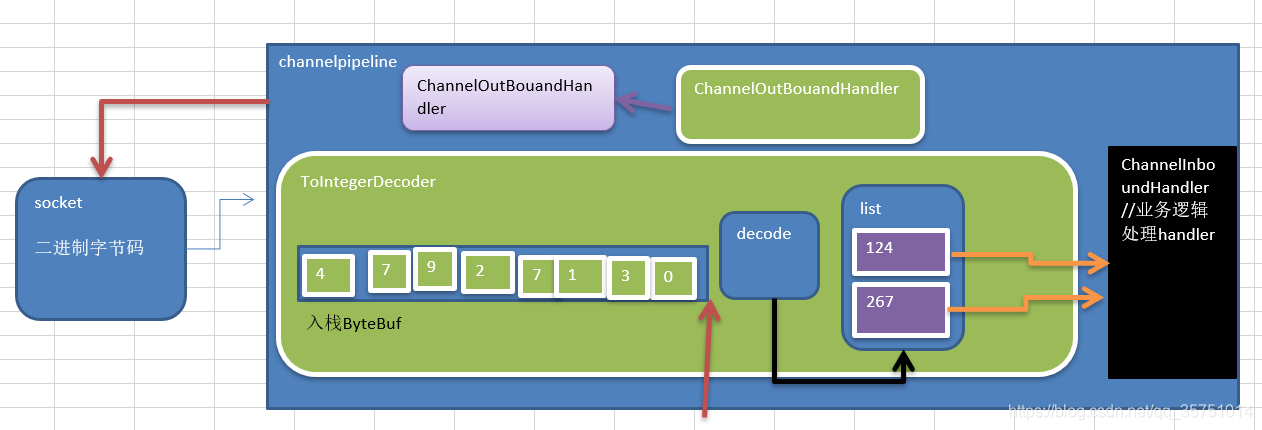
解码器-ReplayingDecoder
- public abstract class ReplayingDecoder
extends ByteToMessageDecoder{ } ReplayingDecoder扩展了ByteToMessageDecoder类,使用这个类,我们不必调用readableBytes()方法。参数S指定了用户状态管理的类型,其中Void代表不需要状态管理下面是代码示例:这段代码起到了上面ByteToMessageDecoder一样的作用public class ByteToLongDecoder2 extends ReplayingDecoder<Void> {@Overrideprotected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {out.add(in.readLong());}}
ReplayingDecoder使用方便,但它也有一些局限性:- 并不是所有的 ByteBuf 操作都被支持,如果调用了一个不被支持的方法,将会抛出一个 UnsupportedOperationException。
- ReplayingDecoder 在某些情况下可能稍慢于 ByteToMessageDecoder,例如网络缓慢并且消息格式复杂时,消息会被拆成了多个碎片,速度变慢
其他解码器
- LineBasedFrameDecoder:这个类在Netty内部也有使用,它使用行尾控制字符(\n或者\r\n)作为分隔符来解析数据。
- DelimiterBasedFrameDecoder:使用自定义的特殊字符作为消息的分隔符。
- HttpObjectDecoder:一个HTTP数据的解码器
LengthFieldBasedFrameDecoder:通过指定长度来标识整包消息,这样就可以自动的处理黏包和半包消息。
2.4 简单实例
实例要求
使用自定义的编码器和解码器来说明Netty的handler 调用机制
- 客户端发送long -> 服务器
- 服务端发送long -> 客户端
实例代码
这里只展示,Handler相应的代码和添加Handler的关键代码。
Decoder:
public class ByteToLongDecoder extends ByteToMessageDecoder {/*** decode 方法会根据接收到的数据,被调用多次,知道确定没有新的元素被添加到list,或者是ByteBuf 没有更多的可读字节为止* 如果 list out不为空,就会将list的内容传递给下一个 Handler 进行处理,该处理器的方法也会被调用多次。* @param ctx 上下文对象* @param in 入栈的 ByteBuf* @param out list集合,将解码后的数据传给下一个Handler* @throws Exception*/@Overrideprotected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {//因为long为8个字节,所以需要8个字节才能读取成一个long类型的数据System.out.println("ByteToLongDecoder:入栈数据被解码");if (in.readableBytes() >= 8){out.add(in.readLong());}}}
Encoder:
public class LongToByteEncoder extends MessageToByteEncoder<Long> {@Overrideprotected void encode(ChannelHandlerContext ctx, Long msg, ByteBuf out) throws Exception {System.out.println("LongToByteEncoder: 出栈数据,msg = " + msg);out.writeLong(msg);}}
服务端添加Handler:
@Overrideprotected void initChannel(SocketChannel ch) throws Exception {ChannelPipeline pipeline = ch.pipeline();pipeline.addLast(new LongToByteEncoder()); //编码器,出站pipeline.addLast(new ByteToLongDecoder()); //解码器,入站pipeline.addLast(new ServerInBoundHandler()); //业务处理,入站}
客户端添加Handler:
@Overrideprotected void initChannel(SocketChannel ch) throws Exception {ChannelPipeline pipeline = ch.pipeline();pipeline.addLast(new LongToByteEncoder()); //编码器,出站pipeline.addLast(new ByteToLongDecoder()); //解码器,入站pipeline.addLast(new ClientInBoundHandler()); //业务处理,入站。}
这里当客户端或者服务端接受消息的时候,首先会调用入站的解码器,然后业务处理,然后调用出站的编码器返回消息。后面可以在业务处理类中,增加发送消息的代码,此处省略。
2.5 Log4j整合到Netty
添加依赖
<dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.25</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.25</version><scope>test</scope></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-simple</artifactId><version>1.7.25</version><scope>test</scope></dependency>
添加配置文件:
在resource目录下新建log4j.properties即可
log5j.rootLogger=DEBUG, stdoutlog4j.appender.stdout=org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.layout=org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern=[%p] %C{1} - %m%n
三 TCP粘包和拆包
3.1 什么是拆包和粘包
- TCP是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发给接收端的包,更有效的发给对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样做虽然提高了效率,但是接收端就难于分辨出完整的数据包了,因为面向流的通信是无消息保护边界的
- 由于TCP无消息保护边界,需要在接收端处理消息边界问题,也就是我们所说的粘包、拆包问题。
通常的解决方案是:发送端每发送一次消息,就需要在消息的内容之前携带消息的长度,这样,接收方每次先接受消息的长度,再根据长度去读取该消息剩余的内容。如果socket中还有没有读取的内容,也只能放在下一次读取事件中进行。
3.2 拆包、粘包的图解
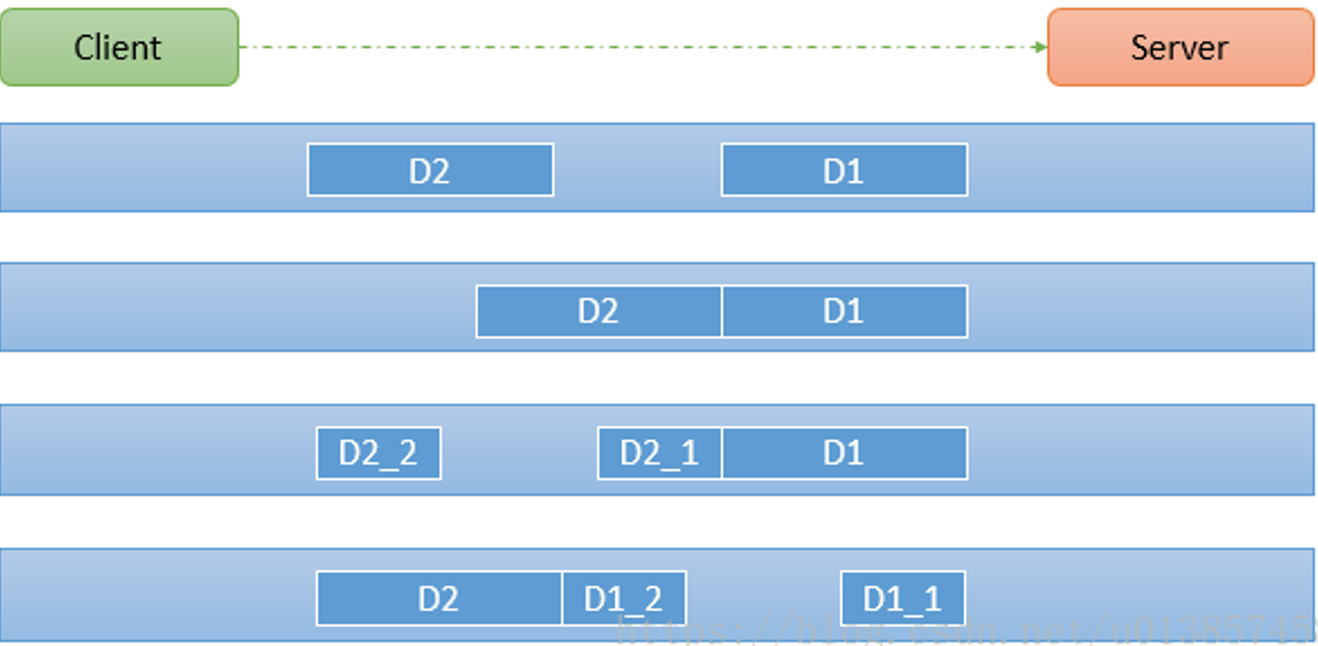
假设客户端同时发送了两个数据包D1和D2给服务端,由于服务端一次读取到字节数是不确定的,固可能存在以下四种情况:服务端分两次读取到了两个独立的数据包,分别是D1和D2,没有粘包和拆包
- 服务端一次接受到了两个数据包,D1和D2粘合在一起,称之为TCP粘包
- 服务端分两次读取到了数据包,第一次读取到了完整的D1包和D2包的部分内容,第二次读取到了D2包的剩余内容,这称之为TCP拆包
服务端分两次读取到了数据包,第一次读取到了D1包的部分内容D1_1,第二次读取到了D1包的剩余部分内容D1_2和完整的D2包。
3.3 解决方案图解
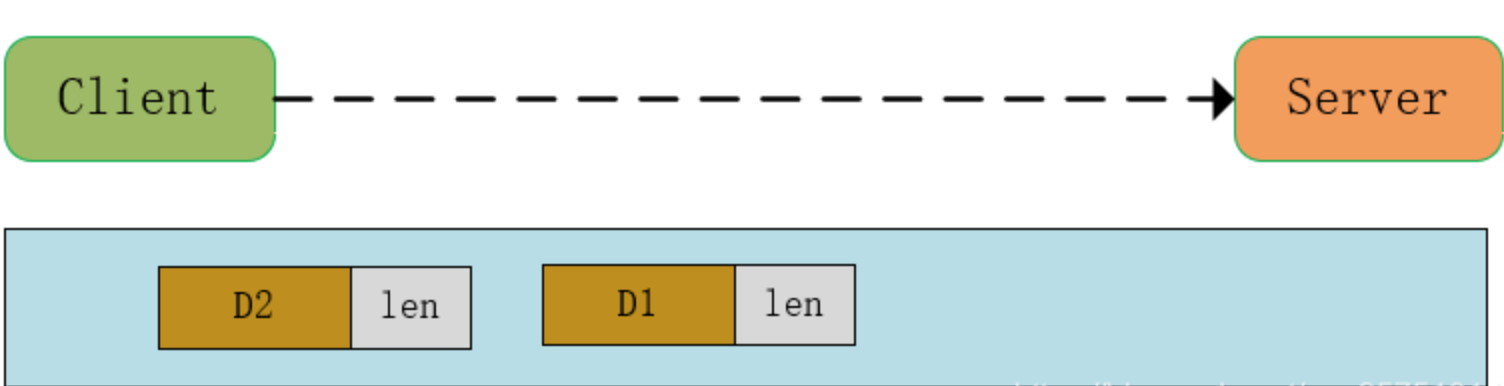
我们可以在数据包的前面加上一个固定字节数的数据长度,如加上一个 int(固定四个字节)类型的数据内容长度
- 就算客户端同时发送两个数据包到服务端,当服务端接受时,也可以先读取四个字节的长度,然后根据长度获取消息的内容,这样就不会出现多读取或者少读取的情况了。
3.4 TCP粘包代码示例
本实例主要演示出现拆包和粘包的场景。
客户端部分代码:
我们将使用循环连续发送10个String类型的字符串。这里相当于发送了10次。 ```java @Override public void channelActive(ChannelHandlerContext ctx) throws Exception { //使用客户端发送10条数据,hello,server for (int i = 0; i < 10; i++) {
} }String msg = "server" + i + " ";System.out.println("发送消息 " + msg);ByteBuf byteBuf = Unpooled.copiedBuffer(msg, CharsetUtil.UTF_8);ctx.writeAndFlush(byteBuf);
**服务端部分代码:**<br /> 我们接受客户端发过来的字符串。```javaprivate int count = 0;@Overrideprotected void channelRead0(ChannelHandlerContext ctx, ByteBuf msg) throws Exception {byte[] bytes = new byte[msg.readableBytes()];msg.readBytes(bytes);//将buffer转成字符串String message = new String(bytes, CharsetUtil.UTF_8);System.out.println("服务器接收到数据 " + message);System.out.println("服务器接收到消息量 = " + (++this.count));//服务器回送数据到客户端,回送一个随机IdByteBuf response = Unpooled.copiedBuffer(UUID.randomUUID().toString() + "--", CharsetUtil.UTF_8);ctx.writeAndFlush(response);}
服务端输出结果如下:
- 我们可以看到,服务端直接一次就把我们客户端10次发送的内容读取完成了。
这里也印证了我们开篇所说的,当数据量小且发送间隔短,如果我们客户端每次发送的都是不同的结果,这种情况下我们就不知道客户端返回了多少次结果以及每次结果究竟是什么。这就是我们本篇需要解决的问题。
3.5 解决方案代码示例
使用自定义协议 + 编解码器 来解决
- 关键就是要解决 服务器端每次读取数据长度的问题, 这个问题解决,就不会出现服务器多读或少读数据的问题,从而避免的TCP 粘包、拆包 。
自定义Message对象:
public class MessageProtocol {private int len; //关键private byte[] content;}
添加将ByteBuf转换成Message的解码器:
public class MessageDecoder extends ReplayingDecoder<Void> {@Overrideprotected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {System.out.println("MessageDecoder 被调用");//需要将获取到的二进制字节码转换成 MessageProtocolint length = in.readInt();byte[] content = new byte[length];in.readBytes(content);//封装成 MessageProtocol 对象,放入 out,传递到下一个HandlerMessageProtocol messageProtocol = new MessageProtocol();messageProtocol.setLen(length);messageProtocol.setContent(content);out.add(messageProtocol);}}
添加将Message转换为ByteBuf的编码器:
public class MessageEncoder extends MessageToByteEncoder<MessageProtocol> {@Overrideprotected void encode(ChannelHandlerContext ctx, MessageProtocol msg, ByteBuf out) throws Exception {System.out.println("MessageEncoder 方法被调用");out.writeInt(msg.getLen());out.writeBytes(msg.getContent());}}
客户端连续发送3个Message对象:
@Overridepublic void channelActive(ChannelHandlerContext ctx) throws Exception {//使用客户端发送10条数据,"今天天气冷,吃火锅" 编号for (int i = 0; i < 3; i++) {String message = "Server" + i;byte[] content = message.getBytes(CharsetUtil.UTF_8);int length = content.length;//创建协议包对象MessageProtocol messageProtocol = new MessageProtocol();messageProtocol.setLen(length);messageProtocol.setContent(content);ctx.writeAndFlush(messageProtocol);}}
服务端接收:
//接收的Handler继承了SimpleChannelInboundHandler,以MessageProtocol的类型接受消息@Overrideprotected void channelRead0(ChannelHandlerContext ctx, MessageProtocol msg) throws Exception {//接收到数据,并处理int len = msg.getLen();byte[] content = msg.getContent();System.out.println("服务器第 " + (++count) +" 次接收到信息如下:");System.out.println("长度:" + len);System.out.println("内容:" + new String(content, CharsetUtil.UTF_8));//回复消息String response = UUID.randomUUID().toString();int length = response.getBytes(CharsetUtil.UTF_8).length;MessageProtocol messageProtocol = new MessageProtocol();messageProtocol.setLen(length);messageProtocol.setContent(response.getBytes());ctx.writeAndFlush(messageProtocol);}
**
- 首先,当客户端的通道激活后,就直接调用方法发送10个Message对象。
- 服务端接收对象时,首先调用MessageDecoder进行解码,将ByteBuf类型的数据转换成MessageProtocol,然后再进入进行读取的Handler中读取消息。
- 最后返回给客户端消息,调用MessageEncoder将MessageProtocol转换成Byte然后发送出去。

若有收获,就点个赞吧
0 人点赞
