一 如何设计一款数据库?
- 程序实例模块
- 存储管理
- 缓存机制
- sql解析
- 日志管理(灾难机制)
- 权限划分(DBA 需要关心的事情)
- 容灾机制
- 索引模块
- 锁管理
存储(文件系统)
不适合范围查询,仅仅满足 = IN
- 无法排序操作
- 不能利用部分索引键查询
- 不能避免表扫描
-
2.3.2 B+tree 索引 主流
适合范围查询
- 适合排序查找
- 适合联合索引
2.3.3 BitMap 索引(mysql不支持)
2.4 密集索引和稀疏索引的区别
- 密集索引:文件中的每个搜索码值都对应一个索引值
- 稀疏索引:文件只为索引码的某些值建立索引项
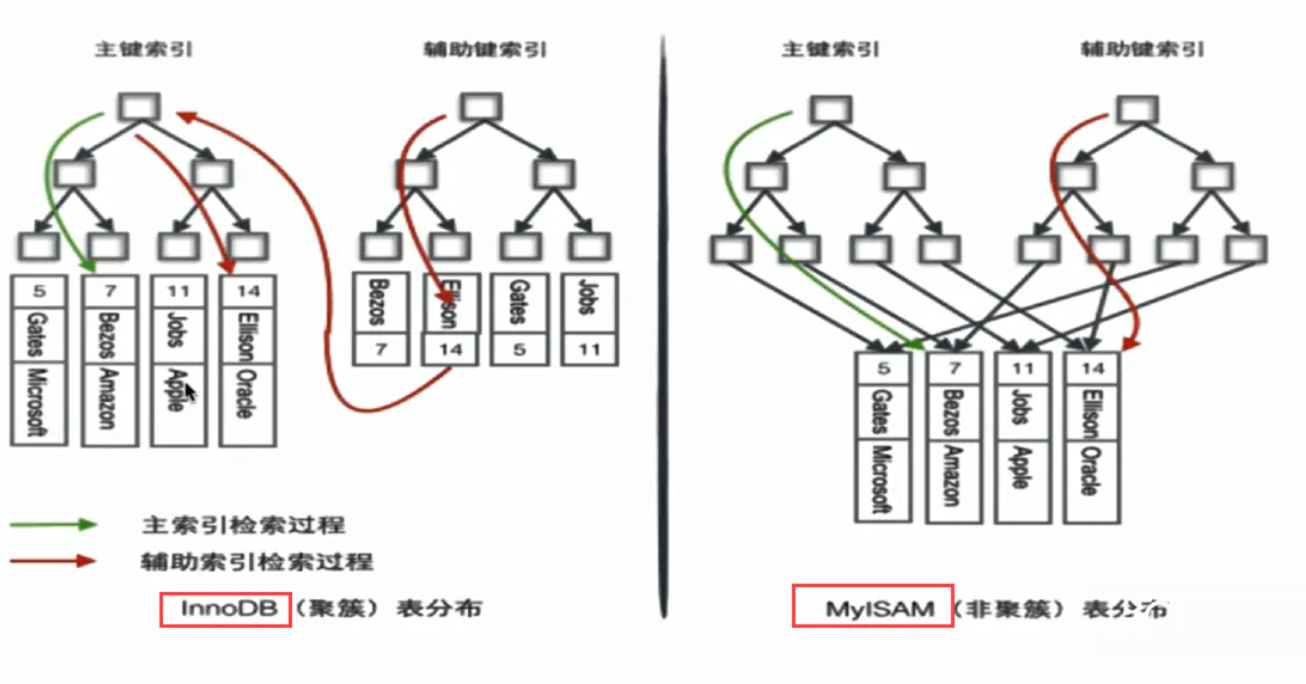
有图得知:
- InnoDB:
- 它是索引和数据放在一个文件中,即每个主键下面挂了该行的数据。因此它是密集索引,同样,也因为每个主键挂载这数据,索引辅助索引要通过主键查询数据
- 稀疏索引(辅助索引),对应的是主键索引,比如我们更加name索引匹配,即 where name=”yanyulou”,那么他会去找对应的主键,然后根据密集索引找数据
- MyISAM:
- 都是稀疏索引,都存在单独的索引文件中,它的主键索引和辅助索引结构基本一致,因为他们保存的行数据的地址,所以直接找到数据,而不需要通过主键索引做二次查找
InnoDB,必须有主键即密集索引
- 一个主键被定义,则该主键是密集索引
- 若没有主键,那么该表第一个唯一非空索引是密集索引
- 若都没有,则InnoDB内部生成一个隐藏主键(密集索引)
- 非主键索引存储相关键位和其对应的主键值,包含两次查找
MyISAM没有密集索引
不管是主键索引、唯一键索引或者普通索引,其索引都属于稀疏索引
2.5 如何定位慢sql
三步走:
慢日志(一般大公司都会有自己的监控系统,定时邮件通知到你😀)
- 查看相关变量 show variables like ‘%quer%’
- 打开慢日志:set global slow_query_log=on ;设置慢查询时间为一秒:set global longquery_time=1 ;
- 查看慢sql的条数 show status like ‘%slow_queries%’
- 查看xxx.log 查看具体的sql,所花费的时间
- explain 分析sql
- 语法 explain …sql…..
- id 表示优先级 id越大,越先执行,即子查询id越大
- select_type 区别普通查询、联合查询、子查询等的复杂查询
- table 指的就是当前执行的表
- type(重点考察对象) system > const > eq_ref > ref > range > index > all
- possible_keys 和 key,显示可能应用在这张表中的索引,一个或多个
- key_len显示的值为索引字段的最大可能长度,并非实际使用长度
- Extra(重点考察对象) 十分重要的额外信息,查询下面下面的情况要重点优化:
- Using filesort(九死一生)说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。MySQL中无法利用索引完成的排序操作称为“文件排序”。
- Using temporary(十死无生)使用了用临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序order by和分组查询group by
- 修改sql 建立索引
2.6 最左匹配原则
最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配
假如创建一个(a,b)的联合索引,那么它的索引树是这样的: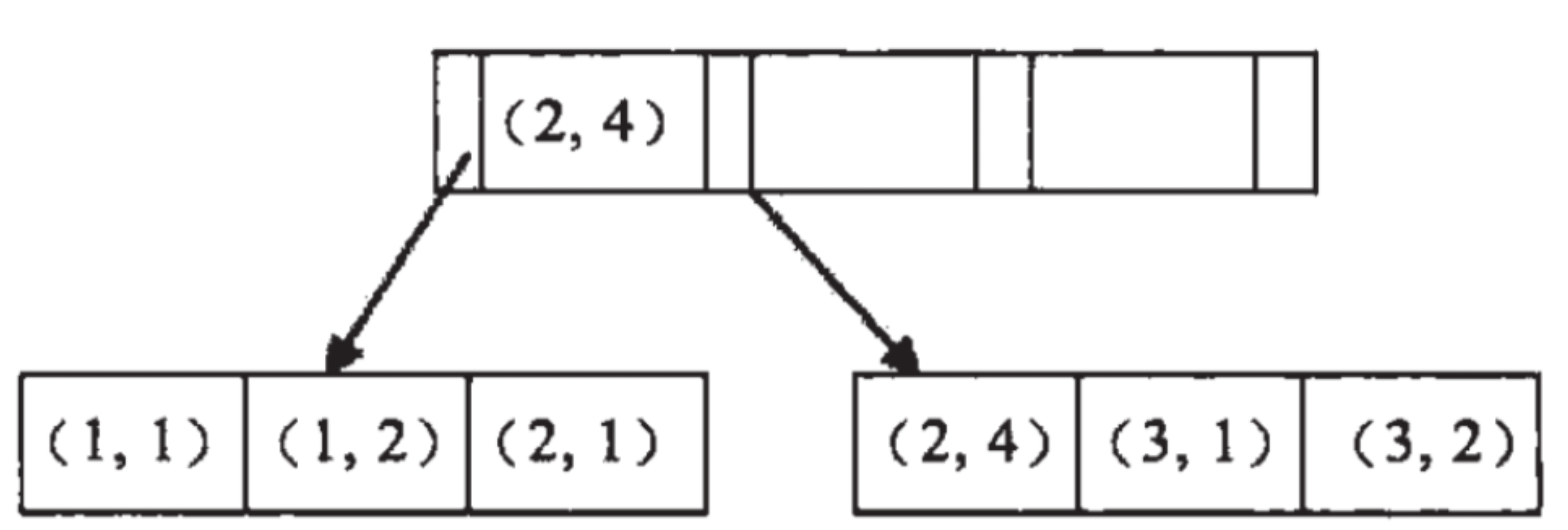
- 可以看到a是有顺序的: 1,1,2,2,3,3,而b是无顺序的: 1,2,1,4,1,2。所以where b = 2这种查询条件没有办法走索引,因为联合索引首先是按a排序的,b是无序的。
- 同时发现在a值相等的情况下,b值又是有序的,但这种顺序是相对的。所以最左匹配原则遇上范围查询就会停止,剩下的字段都无法使用索引。例如 where a = 1 and b = 2 a,b字段都可以使用索引,因为在a值确定的情况下b是相对有序的,而where a >1 and b=2,a字段可以匹配上索引,但b值不可以,因为a的值是一个范围,在这个范围中b是无序的。
2.6.1 全值匹配查询时
假如建立联合索引(a,b,c)
用到了索引,where子句几个搜索条件顺序调换不影响查询结果,因为Mysql中有查询优化器,会自动优化查询顺序
都从最左边开始连续匹配,用到了索引select * from table_name where a = '1' and b = '2' and c = '3'select * from table_name where b = '2' and a = '1' and c = '3'select * from table_name where c = '3' and b = '2' and a = '1'
2.6.2 匹配左边的列时
都从最左边开始连续匹配,用到了索引
这些没有从最左边开始,最后查询没有用到索引,用的是全表扫描select * from table_name where a = '1'select * from table_name where a = '1' and b = '2'select * from table_name where a = '1' and b = '2' and c = '3'
如果不连续时,只用到了a列的索引,b列和c列都没有用到select * from table_name where b = '2'select * from table_name where c = '3'select * from table_name where b = '1' and c = '3'
select * from table_name where a = '1' and c = '3'
2.6.3 匹配列前缀
如果列是字符型的话它的比较规则是先比较字符串的第一个字符,第一个字符小的哪个字符串就比较小,如果两个字符串第一个字符相通,那就再比较第二个字符,第二个字符比较小的那个字符串就比较小,依次类推,比较字符串。
如果a是字符类型,那么前缀匹配用的是索引,后缀和中缀只能全表扫描了select * from table_name where a like 'As%'; //前缀都是排好序的,走索引查询select * from table_name where a like '%As'//全表查询select * from table_name where a like '%As%'//全表查询
2.6.4 匹配范围值
可以对最左边的列进行范围查询
多个列同时进行范围查找时,只有对索引最左边的那个列进行范围查找才用到B+树索引,也就是只有a用到索引,在1select * from table_name where a > 1 and a < 3
select * from table_name where a > 1 and a < 3 and b > 1;
2.6.5 精确匹配某一列并范围匹配另外一列
如果左边的列是精确查找的,右边的列可以进行范围查找,a=1的情况下b是有序的,进行范围查找走的是联合索引select * from table_name where a = 1 and b > 3;
2.6.6 排序
一般情况下,我们只能把记录加载到内存中,再用一些排序算法,比如快速排序,归并排序等在内存中对这些记录进行排序,有时候查询的结果集太大不能在内存中进行排序的话,还可能暂时借助磁盘空间存放中间结果,排序操作完成后再把排好序的结果返回客户端。Mysql中把这种再内存中或磁盘上进行排序的方式统称为文件排序。文件排序非常慢,但如果order子句用到了索引列,就有可能省去文件排序的步骤
因为b+树索引本身就是按照上述规则排序的,所以可以直接从索引中提取数据,然后进行回表操作取出该索引中不包含的列就好了。 ```java select from table_name order by a,b,c limit 10; //order by的子句后面的顺序也必须按照索引列的顺序给出,比如这种颠倒顺序的没有用到索引 select from table_name order by b,c,a limit 10;
//这种用到部分索引 select from table_name order by a limit 10; select from table_name order by a,b limit 10;
//联合索引左边列为常量,后边的列排序可以用到索引 select * from table_name where a =1 order by b,c limit 10;
<a name="JzWUB"></a>## 2.7 索引建立越多越好吗?1. 数据量小的表不需要建立索引,建立会增加额外的索引开销1. 数据变更需要维护索引,因此更多的索引意味着更多的维护成本1. 更多的索引意味着也需要更多的空间<a name="7fTKb"></a># 三 锁模块<a name="CIQ09"></a>## 3.1 MyISAM与InnoDB 关于锁方面的区别是啥?1. MyISAM 默认用的是表级锁,不支持行级锁1. 显示加锁: lock tables xxxx read1. 有读锁,后面的读不阻塞,即读读不阻塞。1. 当表查询的时候即读锁,后面的增删改的操作被阻塞。即读写互斥1. 有更新表的时候即写锁,后面的读阻塞,等待写锁释放,即写读互斥1. 总结:读是共享锁,可以读读,写是排他的,2. InnoDB 默认用的是行级锁,也支持表级锁1. show variables like 'autocommit' 关闭自动提交:set autocommit=0;1. select xxxxx lock in share mode (共享锁)1. 增删改 默认上排它锁1. sql如果没有走索引用的是表级锁,走索引的是行级锁<a name="lBpuW"></a>## 3.2 MyISAM与InnoDB 适合场景?1. MyISAM1. 频繁执行全表count1. 对增删改频率不多,查询频繁1. 没有事务要求2. InnoDB1. 增删改频率多1. 支持事务,对数据可靠性要求高<a name="GO7yr"></a>## 3.3 锁的分类1. 粒度划分: 表级锁 行级锁 页级锁1. 锁级别:共享锁 排他锁1. 锁方式:自动锁 显示锁1. 操作方式:DML锁 DDL锁1. 使用方式:乐观锁 悲观锁乐观锁 即在表里新增一个version字段,即每次更新一次++即```javaupdate xxx set xxx=xxx, version=0+1 where version=0 and xxxx=xxx
四 事务
4.1 四大特性
原子性(Atomic)
一致性(Consistency)
隔离性(Isolation)
持久性(Durability)
4.2 事务隔离级别
更新丢失: mysql所有事务隔离级别在上数据库层面上都能避免。
read-uncommitted
脏读: read-committed 事务隔离级别以上可以避免
读取未提交的数据,如果线程一的数据未提交,线程二的数据读取了。然后线程一数据回滚了,那么线程二读取的数据就是脏数据。
- 查看隔离级别 select @@tx_isolation
- 设置读未提交的级别:set session transaction isolation level read uncommitted
- 开启事务:start transaction;
不可重复读:repeatable-read(默认的)事务隔离级别以上可以避免
两次读数据,其结果不一样,但是对于同一个客户端就会疑惑两次查询数据不同。
- select balance from table where id =1 ,第一次查询 balance=1000
- 线程二更新了值balance=2000,并提交了,
- 此时线程一查询的结果变成balance=2000,看起来没有问题,但是线程一就会很疑惑
- 因此设置不可重复读即可 即线程一查询的值还是1000。那有人说不对啊应该是2000哈。其实它已经改成了2000.。不信我们更新下。
- 如果此时线程一需要更新操作,那么update table set balance=balance(这里取的是2000)-500 where id =1
幻读:serializable 事务级别可避免
本来需要更新3条记录,发现执行完更新了4条记录。出现了幻觉
- 线程一插入一条数据,比如原来3条数据,变成了4条
-
4.3 可重复读如何避免幻读
表象 它是快照读(非阻塞读)—伪MVCC
- 内在:next-key锁(行锁+gap锁)
4.3.1 当前读和快照读
当前读就是读取最新的版本的数据,并对读取数据加锁,阻止其他事物的修改。说白了,当前读就是加锁的增删改查。
当前读: select ….lock in share mode ,select ….for update
当前读:update,delete, insert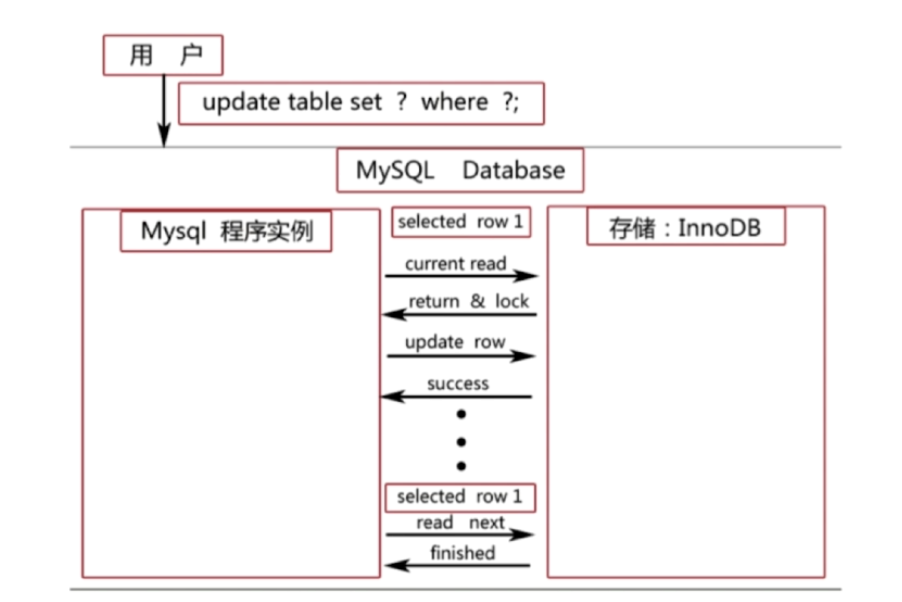
快照读:不加锁的非阻塞读(select),提升了很大的性能。它有可能读到历史版本。因为在事物开始时开启的快照,这个时候数据还没有更新,此时快照了旧的数据,所以后面更新的时候,我们查询的数据是上一个版本的数据。
4.3.2 RC RR 级别下INnoDB 的快照读(非阻塞读)如何实现
- 数据行的额外字段
DB_TEX_ID : 最近一次对本行数据做修改的事务ID
DB_ROLL_PTR : 回滚指针
DB_ROW_D : 行号
- undo日志
当我们对记录做了变更操作时,就会产生undo记录,undo记录存储的是老数据。当一个旧的事务需要读取事务时,为了能读取到老版本的数据,需要顺着undo链找到其可见性的记录。
- insert undo.log 事务对数据进行insert产生的undo log,只在事务回滚时需要,并且在事务提交后就可以立即丢弃。
- update undo.log 示事务对数据进行delete/update产生的undo log,不仅在事务回滚时需要,快照读也需要,不能随便删除,只有当数据库所使用的快照不涉及该日志记录,对应的回滚日志才会被删除
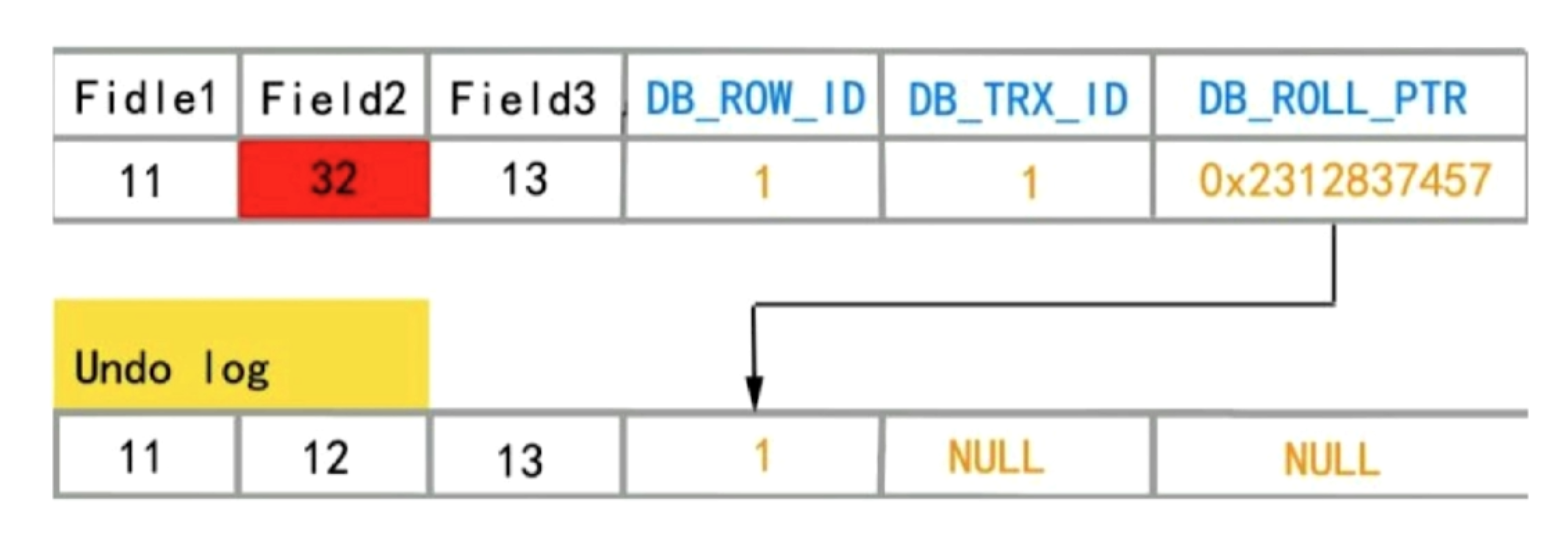
上图的过程是将12修改成32
- 首先拷贝一份数据记录到undo.log日志中,并在行记录中,记录回滚地址
- 更新行记录的值12==>32
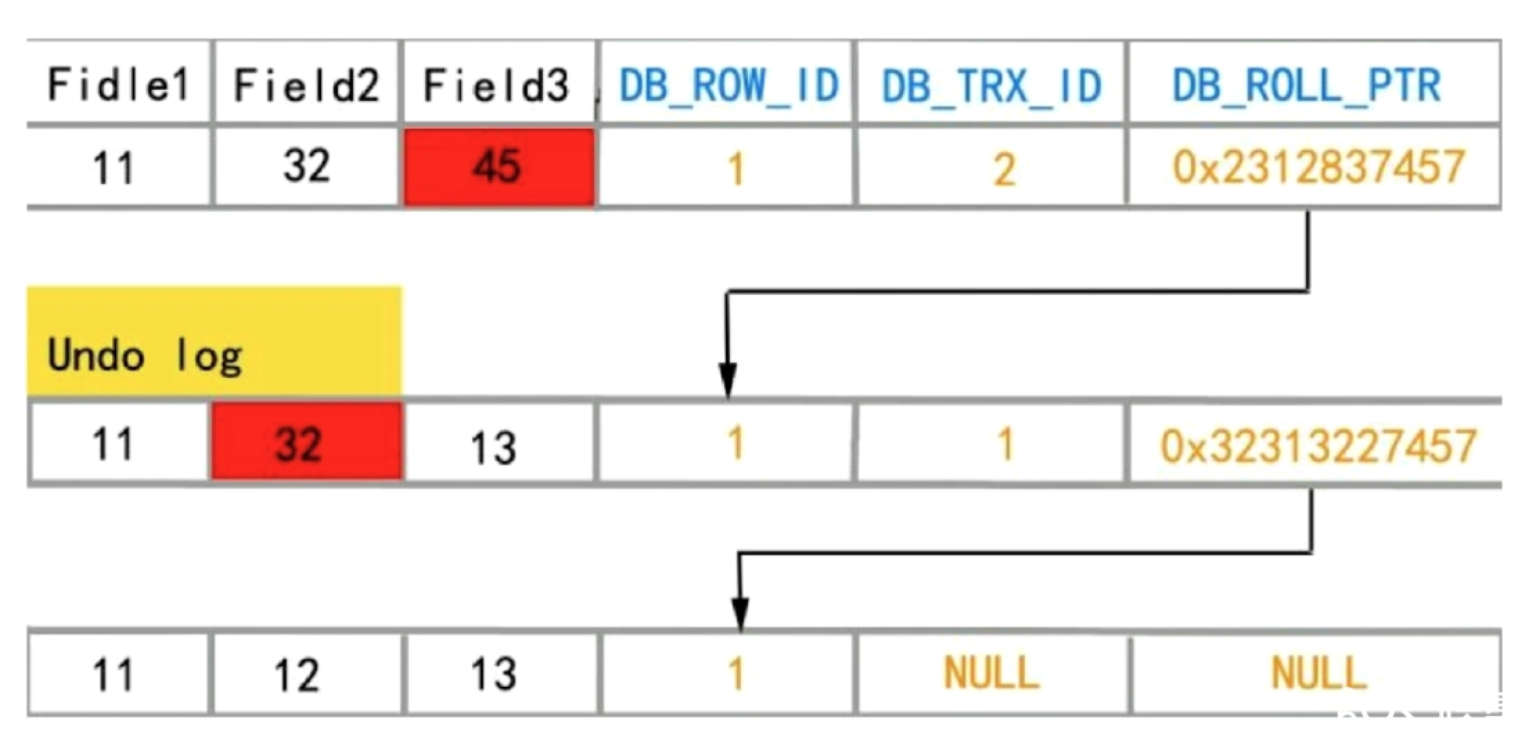
如果又有其他事物更新数据即32==>45(假设前一个快照日志还没有删除)
- 首先拷贝一份数据记录到undo.log日志中,并在行记录中,记录回滚地址
- 更新行记录的值32==>45
Read view 可见性判断,这个我觉得快照时机很重要
针对的是主键或者唯一键:如果where条件全部命中,因为都精确命中了,自然只需要加记录锁即可。
- 数据保证唯一,因为不唯一的话会出现多条数据,那么就会形成gap,即间隙
- select * from tb where id (1,2,3)返回全部数据1,2,3 ,只会加行锁
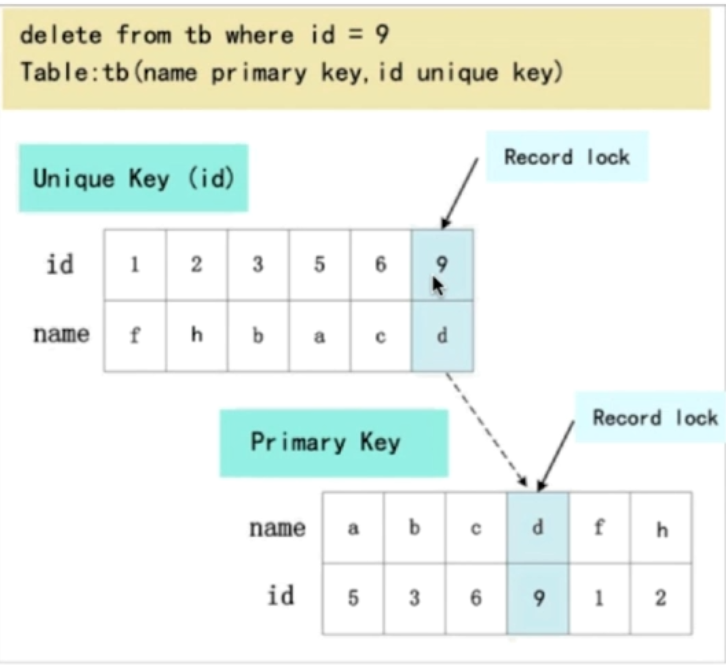
为啥密集索引为啥要加锁呢?
因为密集索引不加锁是不能保证串行的操作(即锁不住)。试想下如果我们直接通过密集索引更新这条行记录(如果密集索引没有加锁),那么就不能保证更新删除操作的串行,从而引发幻读
Gap锁:RR 以上支持 gap锁
- 针对的是主键或者唯一键:如果where条件部分命中或者全不命中,则会加Gap锁
- 全部不命中,则gap锁全表
- 假设where id in (5,7,9),数据库存在(123,9),只命中了9,那么他的gap是(4-9],(9-max]。
非唯一索引和不走索引,那么就命中多条记录,那么形成gap,故需要gap锁。
非唯一索引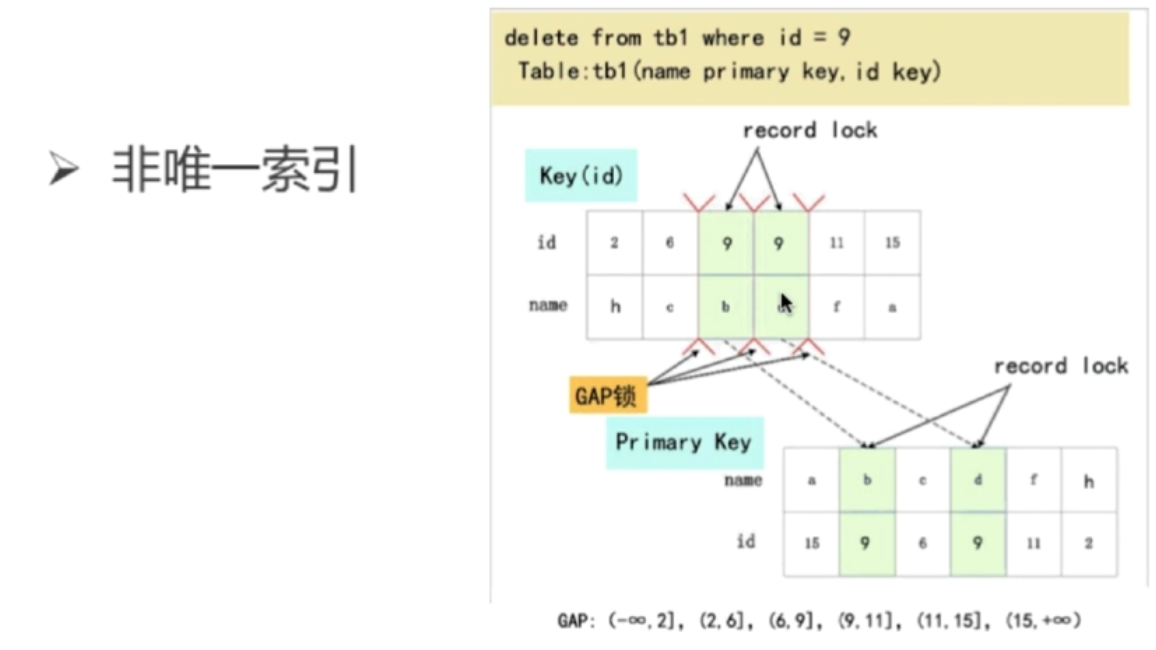
上图如果是行锁锁住两条记录(即id=9的数据),那么线程二在插入一条记录id=9的数据,是不是就会出现幻读了。那如果上一个gap锁,即id=9的记录前后间隙(6-11]都上锁,则不会出现幻读,
注意主键的值与会影响锁的情况,例如 name=d,id=6那么这个记录就在(6,c)的后面,即会被锁住。
不走索引,相当于锁表了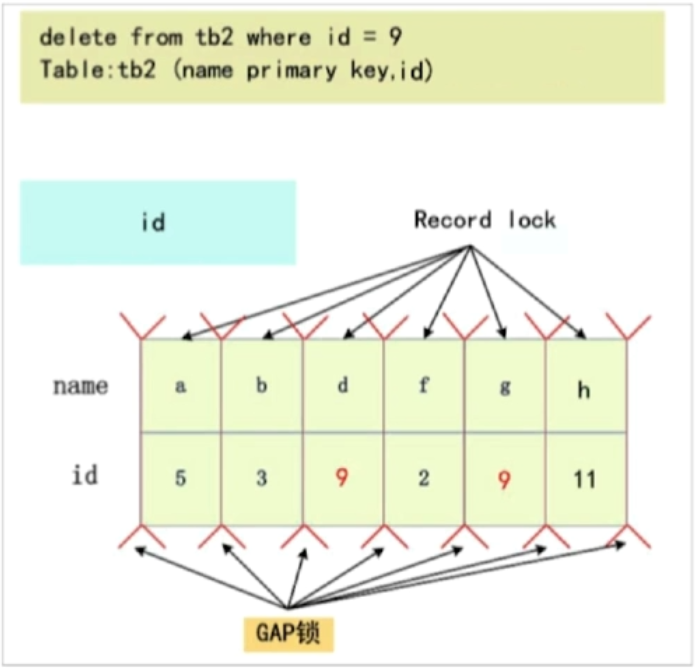
五 二进制日志文件
二进制日志记录了对数据库执行更改的所有操作,但是不包括select和show这类操作,因为这类操作对数据本身并没有修改,如果你还想记录select和show操作,那只能使用查询日志了,而不是二进制日志。
此外,二进制还包括了执行数据库更改操作的时间和执行时间等信息。二进制日志主要有以下几种作用:
- 恢复(recovery): 某些数据的恢复需要二进制日志,如当一个数据库全备文件恢复后,我们可以通过二进制的日志进行point-in-time的恢复
- 复制(replication) : 通过复制和执行二进制日志使得一台远程的 MySQL 数据库(一般是slave 或者 standby) 与一台MySQL数据库(一般为master或者primary) 进行实时同步
- 审计(audit):用户可以通过二进制日志中的信息来进行审计,判断是否有对数据库进行注入攻击
六 读写分离
主库将变更写binlog日志,然后从库连接到主库之后,从库有一个IO线程,将主库的binlog日志拷贝到自己本地,写入一个中继日志中。接着从库中有一个SQL线程会从中继日志读取binlog,然后执行binlog日志中的内容,也就是在自己本地再次执行一遍SQL,这样就可以保证自己跟主库的数据是一样的。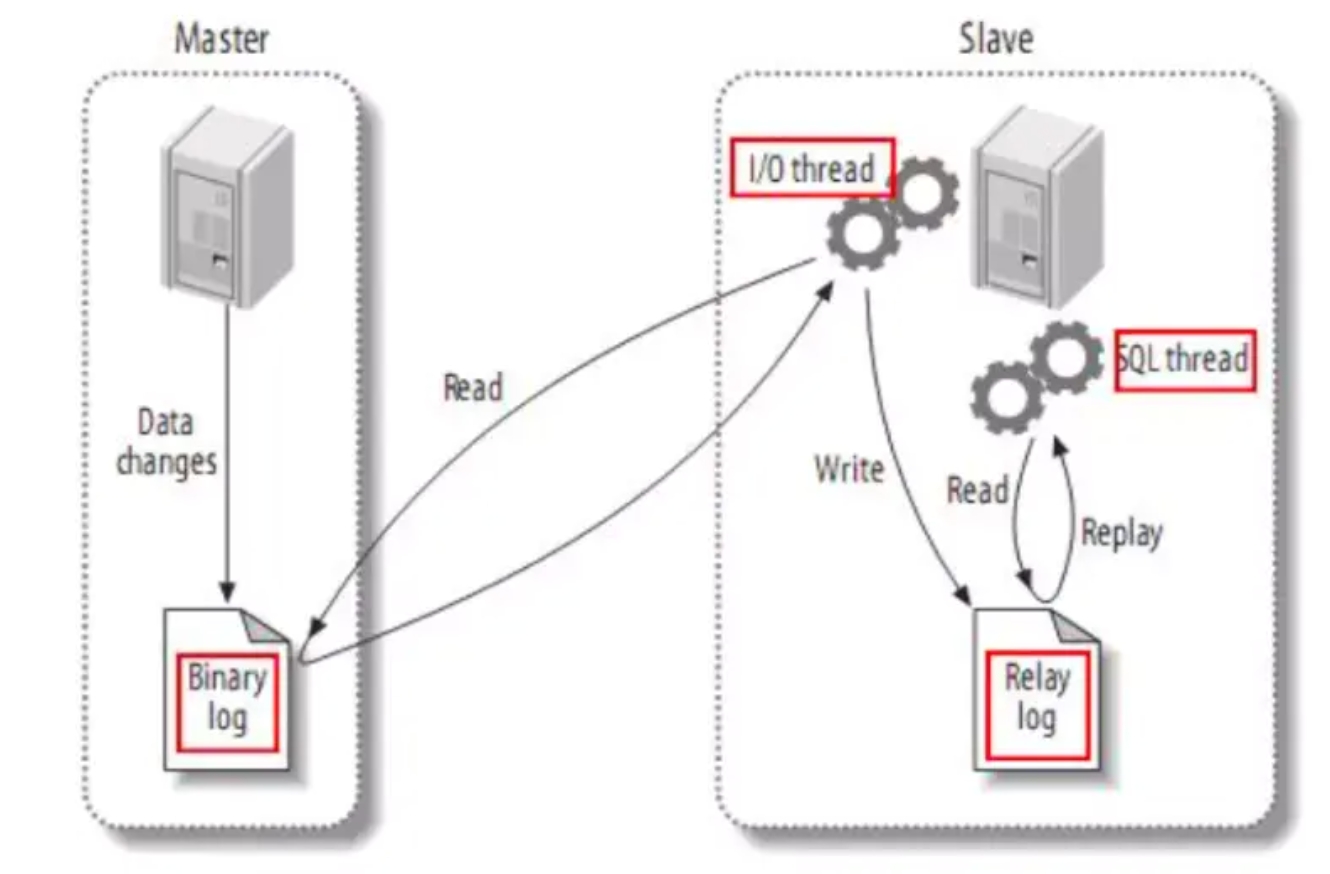
这里就有一个问题了。有数据传输就会有间延,一旦并发量大就有可能造成较大的间延,也产生了主从延时问题。
如何解决主从延时问题?
- 分库,将一个主库拆分为4个主库,每个主库的写并发就500/s,此时主从延迟可以忽略不计。
- 打开 mysql 支持的并行复制,多个库并行复制。如果说某个库的写入并发就是特别高,单库写并发达到了2000/s,并行复制还是没意义。28法则,很多时候比如说,就是少数的几个订单表,写入了2000/s,其他几十个表10/s。(所谓并行复制,指的是从库开启多个线程,并行读取relay log中不同库的日志,然后并行重放不同库的日志,这是库级别的并行。)
- 直接查主库(不推荐)
- 检查代码,一般INSERT/UPDATE后,马上进行SELECT,这种代码要避免。
七 如何实现事物的?
那么数据库是如何实现事物的呢,即如何保证数据的一致性呢?。满足四个特性即可。即满足原子性 隔离性 和持久性 就能达到一致性是这个目标。
思路:
- 1.单线程成情况下,我们就考虑原子性和持久性,即只要保证数据是可靠的就好,即宕机重启的时候数据可以恢复,那简单搞两个日志即可,即(undo log,redo log)。
- 2.多线程并发情况下,我们怎么办。比较高效的办法是上锁,或者版本控制,低效的办法就是串行。
具体实现
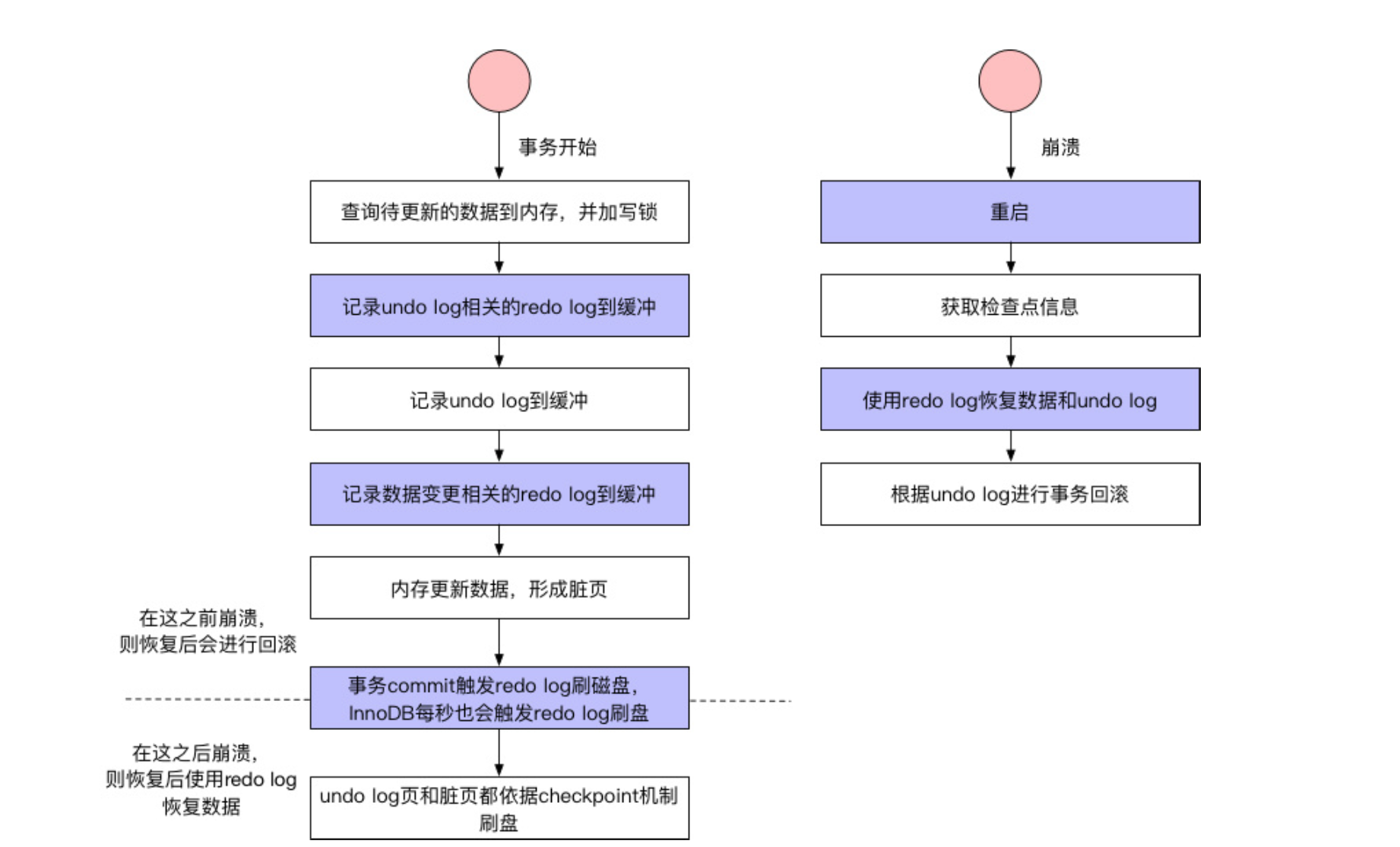
事务进⾏过程中,每次sql语句句执⾏,都会记录undo log和redo log,然后更更新数据形成脏⻚页,然后redo log按照时间或者空间等条件进⾏行行落盘,undo log和脏⻚页按照checkpoint进⾏落盘,落盘后相应的redo log就可以删除了了。此时,事务还未COMMIT,如果发⽣生崩溃,则⾸先检查checkpoint记录,使⽤相应的redo log进⾏数据和undo log的恢复,然后查看undo log的状态发现事务尚未提交,然后就使⽤用undo log进⾏行行事务回滚。事务执⾏COMMIT操作时,会将本事务相关的所有redo log都进⾏落盘,只有所有redo log落盘成功,才算COMMIT成功。然后内存中的数据脏⻚页继续按照checkpoint进⾏落盘。如果此时发生了崩溃,则只使⽤用redo log恢复数据。

若有收获,就点个赞吧
0 人点赞
