一、简述

1、Prometheus获取数据方式:
- Pull:指Prometheus用pull这种方式(HTTP get)去访问每个节点上的exporter并采样回去需要的数据
- Push:指客户端(或服务端)安装官方提供的Pushgateway插件,然后使用我们运维自行编写的各种脚本把需要监控的数据形成K/V的形式以metrics形式发送到Pushgateway,之后Pushgateway会推送给Prometheus
2、Prometheus报警方式
- Prometheus本身不具备报警功能,只能通过开源软件Alermanager等或商业软件实现报警
3、Prometheus数据展示方式
- 自带UI
- Grafana
- 另开发
二、Prometheus metrics的数据类型
metrics翻译过了也就是指标的意思
Prometheus监控中,对于采集过来的数据统一称为metrics数据
metrics是一种采样数据的总称(metrics并不代表某一种具体的数据格式)
metrics几种主要的类型:
1、Gauge
最简单的的度量指标,只有一个简单的返回值或者叫瞬时状态。
例如:如果我要监控硬盘容量或内存容量,那么就应该使用gauges的metrics格式来度量。
因为硬盘容量或内存容量时随着时间的推移 不断的顺时 没有规则的变化的,这种变化没有规律,当前是多少采集回来的数据就是多少,即不时一直增长和一直降低。
是多少 就是多少 这种就是gauges使用类型的代表
2、Counter
counter翻译过来计数器的意思,从数据值0开始累计计算,在正常情况下只能累计增长,不会降低(特殊除外)
例如:用户访问网站的次数。
Key-Value介绍
k/v(key-value)翻译过了也就是键值的意思
当一个exporter被安装和运行在服务器上的时候,其给我们采集的就是k/v形式的metrics数据
如:访问exporyer的IP:9100/metrics,即可看到数据都是以k/v的形式进行展示的
如上图所示带#一行是注释,下一项就是以k/v形式展现的数据
process_open_fds 12
这就是用空格分开的Key/Value数据,代表当前被打开的文件句柄数是:12,另外可以看到注释一行告诉了我们这是gauge类型的metrics数据,因为文件句柄的使用是没有规律的,瞬时的。
三、Prometheus示例监控cpu的方式
在Prometheus的Web Ui上输入node_cpu,可以看到cpu的相关指标数据
但是,看到他的返回值是一个持续不断累加的庞大数字,正常不应该是百分比吗?
这就关系到prometheus对linux数据的采集精细特性了,其实prometheus对linux cpu的采集并不是直接返回现成的百分比,而是返回linux中很底层的cpu时间片,积累数值的这样的一个数据。
扩展:Linux中CPU时间实际是指:从操作系统开启,CPU启动后及开始记录自己在工作中总使用的‘时间’的累计值并把它保存在系统中,而累计的CPU使用时间还会分为几种重要的状态类型。比如CPU time 分组CPU user time/sys time/nice time/idle time等等...那么所谓的CPU使用率准确的定义就是CPU各种状态中除了idle(空闲)这个状态外,其他所有CPU状态的总和/总CPU时间 得出来的就是我们所说的CPU使用率那么,刚才开的的node_cpu值其实是各个核 各状态下从开机一直累积下来的CPU使用时间
Linux系统开启后,CPU开始进⼊⼯作状态,每⼀个不同状态 的CPU使⽤时间都从零开始累计,⽽我们在被监控客户端安装的node_exporter会抓取并返回给我们常⽤的⼋种CPU状态的累积时间数值。
先使⽤⽤户态CPU来举个例⼦,⽤户态CPU通常是占⽤整个CPU状态 最多的类型,当然也 有个别的情况,内核态 或 IO等待 占⽤的更多 。
例如:
在三十分钟内,CPU被使⽤在⽤户态 的时间⼀共是 8分钟,CPU被使⽤在内核态 的时间⼀共是 1.5分钟,CPU被使⽤在IO等待状态 的时间⼀共是 0.5分钟,CPU被在Idle状态的时间⼀共是 20分钟 (idle空闲状态的CPU时间), CPU被使⽤在其他⼏个状态的时间是0
计算三十分钟内的使用率,那么可以根据公式‘ CPU的使⽤率 = (所有⾮空闲状态的CPU使⽤时间总和 )/ (所有状态CPU时间的总和)’来计算
(user(8mins) + sys(1.5mins) + iowa(0.5min) + 0 + 0 + 0 + 0 ) / (30mins) = 10分钟 / 30分钟 = 30%
所以针对这30分钟的CPU平均使⽤率就是 30%
上⾯的这个计算公式还是有⼀点点累赘,可以换⼀个更简明的算法’空闲时间 除以 总时间 等于 空闲CPU的⽐例‘
idle(20mins) / (30mins) => 70% 然后100% - 70% = 30%
上⾯这样的⽅法去计算,最终只能是算出CPU在30分钟内的总平均时间,如果我们要那么中间的某⼀分钟之内CPU的总平均时间是 多少 ?那么使⽤当前的这个算法我们就没办法精确的知道某⼀分钟内的平均值了,所以就要使用计算函数了
Prometheus 的数学查询命令⾏,给我们提供了⾮常丰富的计算函数 ,那么就要学习函数了
四、Prometheus常用函数
1、increase()
increase函数在promethes中,是用来针对Counter这种持续增长的数值,截取其中⼀段时间的增量:increase(node_cpu[1m]),这样就解决了cpu某分钟的使用率计算
但是increase(node_cpu[1m])取值回来的是所有核的值,又要都多核进行计算,就用到sum了
2、sum()
sum( ) 就如其字⾯意思⼀样,起到value加合的作⽤
sum( increase(node_cpu[1m]) ) 外⾯套⽤⼀个sum即可把所有核数值加合
但是我们采集的是多台服务器的信息,sum都加在一起,这是不正确的,所以再引进一个函数 by (instance)
3、by (instance)
by (instance) 这个函数可以把 sum加合到⼀起的数值,按照指定的⼀个⽅式 进⾏⼀层的拆分。
instance代表的是机器名,意思就是说把sum函数中服务器加合的这个糗事再给它强⾏拆分出来
可以看到加上by (instance)就把每台机器的cpu的值都分出了
接下来就可以计算每台服务器的CPU的使用率了
使用以上三个函数计算CPU使用率
结合公式’空闲时间 除以 总时间 等于 空闲CPU的⽐例‘最后可以得出命令:sum(increase(node_cpu{mode="idle"}[1m])) by (instance) / sum(increase(node_cpu[1m])) by (instance)
sum(increase(node_cpu{mode="idle"}[1m])) by (instance) 是空闲CPU时间 1分钟的增量 sum(increase(node_cpu[1m])) by (instance) 是全部CPU时间 1分 钟增量
获取百分比:1- (sum(increase(node_cpu{mode="idle"}[1m])) by (instance) / sum(increase(node_cpu[1m])) by (instance))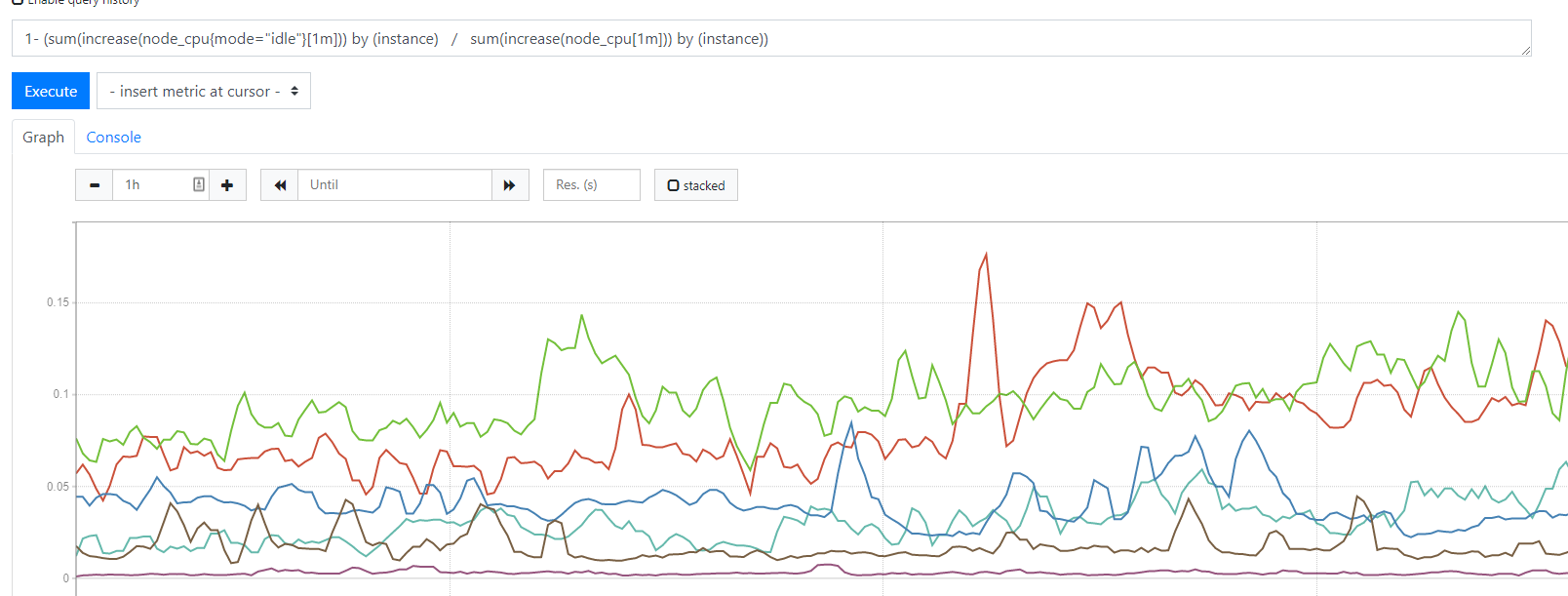
但是看到的是0.0几数字,可以乘以100就为百分比了
(1- (sum(increase(node_cpu{mode="idle"}[1m])) by (instance) / sum(increase(node_cpu[1m])) by (instance))) * 100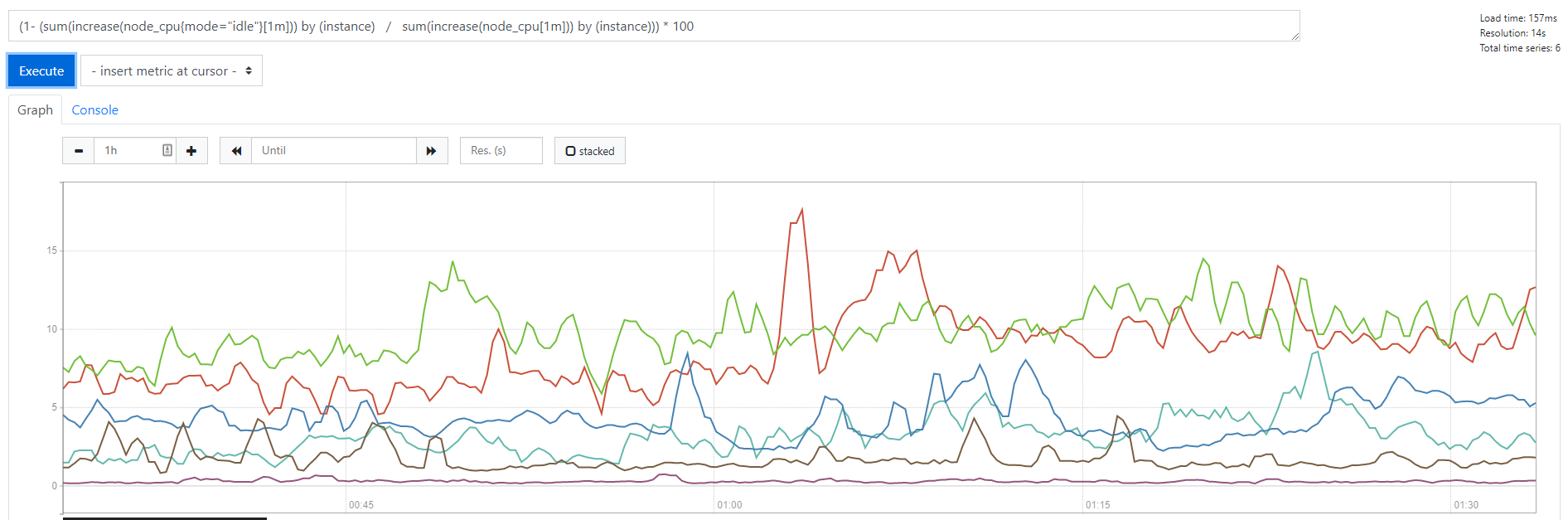
4、rate()
rate 函数可以说 是prometheus提供的 最重要的函数之⼀
rate() 函数是专门搭配counter类型数据使⽤的函数,它的功能是按照设置⼀个时间段,取counter在这个时间段中的平均每秒的增量
例如使⽤的node_exporter的key:node_network_receive_bytes (网络接收字节数)
对于这种持续增长的counter数据,直接输⼊key 是没有任何意义的,我们必须要以获取单位时间内,增量的⽅式 来进⾏加⼯才能有意义。那么 对于counter数据,进⾏第⼀步的初始化的增量获取加工,通常的使⽤方法就是直接⽤ rate() 。
rate(node_network_receive_bytes[1m])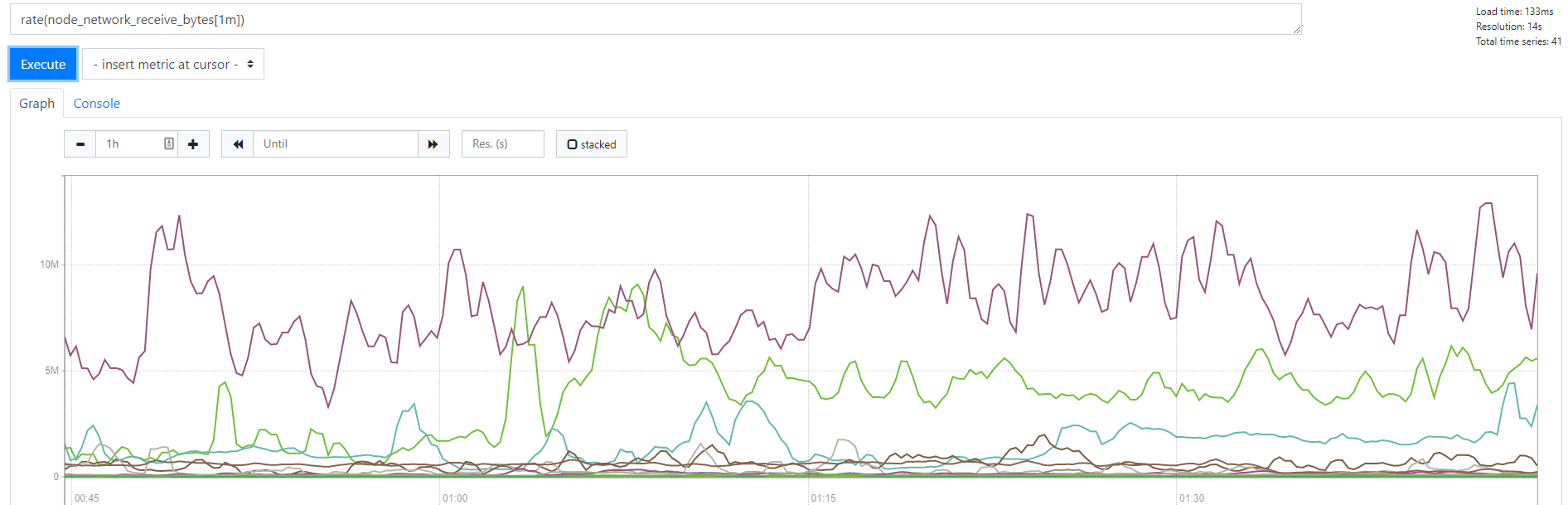
如上图,加上rate函数后就可以获取到1分钟内,平均每秒钟的增量
另外如果是把rate(1m)换成rate(10m),rate(20m)会怎么样子呢
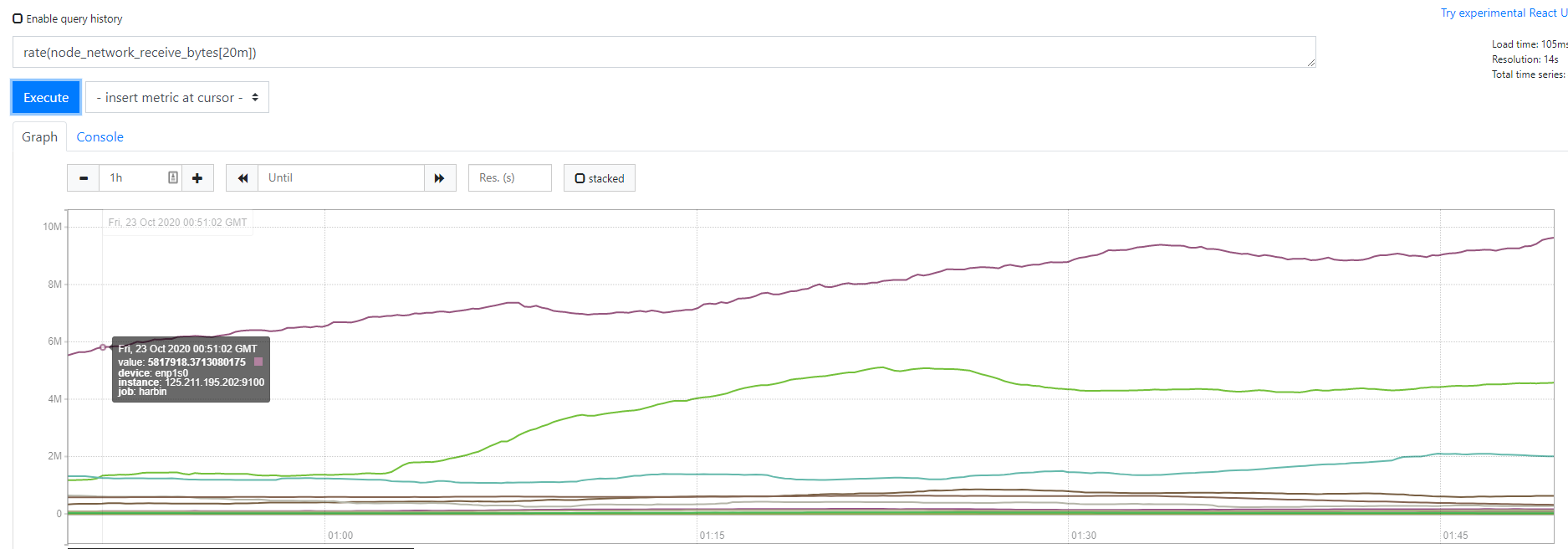
rate(10m) 把整个10分钟内的都⼀起平均了,那么当发⽣瞬时凸起的时候 ,会显得图平缓了⼀些 (因为 取的时间段长把波峰波⾕都给平均消下去了) ,20m就更加平缓了
所以 这个取决于 我们对于监控数据的敏感性程度来挑选
另外 increase 函数 其实和rate函数的概念及使用方法十分相似
rate(1m) 是取⼀段时间增量的平均每秒数量
increase(1m) 则是 取⼀段时间增量的总量
⽐如 :
increase(node_network_receive_bytes[1m]) 取的是1分钟内的增量总量rate(node_network_receive_bytes[1m]) 取的是 1分钟内的增量 除以 60秒 每秒数量
5、topk()
定义:取前⼏位的最⾼值
Gauge类型的使⽤ topk(3,count_netstat_wait_connections)
Counter类型的使⽤ topk(3,rate(node_network_receive_bytes[20m]))
这个函数⼀般在使⽤的时候只适合于在console查看,graph的 意义不⼤,如下图所⽰ :
Topk因为对于每⼀个时间点都只取前三⾼的数值,那么必然会造成 单个机器的采集数据不连贯
6、count()
定义: 把数值符合条件的 输出数目进行加合
例:找出CPU使用率大于5%的机器数量
count ((1- (sum(increase(node_cpu{mode="idle"}[1m])) by (instance) / sum(increase(node_cpu[1m])) by (instance))) * 100 > 5)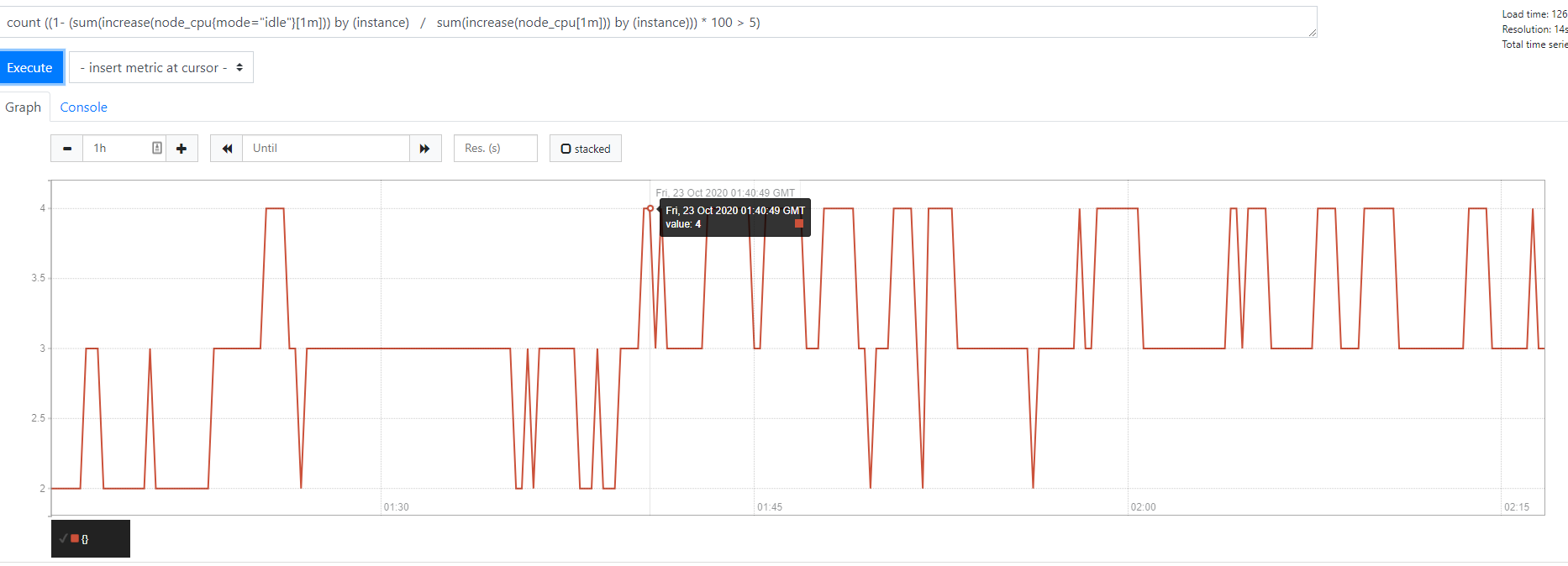
其他函数可以到Prometheus官网进行学习查看:https://prometheus.io/docs/prometheus/latest/querying/functions/
五、Prometheus Pushgateway
1、pushgateway 的介绍
pushgateway是另⼀种采⽤被动推送的⽅式(⽽不是exporter 主动获取)获取监控数据。
prometheus 插件可以单独运⾏在任何节点上,(并不⼀定要在被监控客户端) 然后通过⽤户⾃定义开发脚本把需要监控的数据发送给pushgateway然后pushgateway再把数据推送给prometheus server
2、pushgatway安装
pushgateway跟prometheus和node_exporter⼀样,下载-解压-直接运行
下载地址:https://prometheus.io/download/#pushgateway
3、pushgateway配置
关于pushgateway的配置 主要指的是 在prometheus sever端的配 置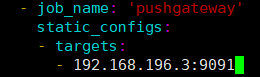
在prometheus.yml 配置⽂件中, 单独定义⼀个job然后target指向到 pushgateway运⾏所在的机器和 pushgateway运⾏的端口,后重启一下prometheus服务端即可
4、客户端自定义脚本采集数据
pushgateway本⾝是没有任何抓取监控数据的功能的,它只是被动的等待推送过来
推送方式:echo key vlaue | curl --data-binary @-http://$IP:$Port/metrics/job$job_name/instance/$instance_name
如:我在服务器上执行echo ssh_logins 2 | curl --data-binary @- http://192.168.196.3:9091/metrics/job/pushgateway/instance/192.168.196.3
到pushgateway的metrics页面上即可看到已经推送的数据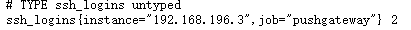
下面在客户端使用脚本方式向pushgateway推送数据
脚本如下:
#!/bin/bashinstance_name=`ip a|grep eth0|grep inet|awk '{print $2}'|awk -F "/" '{print $1}'` #本机ip 变量#定义一个新的数值 (已登录数量)ssh_logins=`who|wc -l`label="ssh_logins" # 定义个新的 keyecho "$label $ssh_logins" | curl --data-binary @- http://192.168.196.3:9091/metrics/job/pushgateway/instance/$instance_name
执行脚本后到pushgateway的metrics页面即可看到新推送的数据

脚本解析:
label=”ssh_logins” 就是key
ssh_logins=who|wc -l 就是value,数据值
URL解析:
http://192.168.196.3:9091/metrics是URL的主location ;
/job/pushgateway 这⾥是第一部分(第⼀个标签),推送到prometheus.yml 定义的哪一个job⾥ ; /instance/$instance_name 这⾥是第二部分(第二个标签),推送后显⽰的机器名是什么
然后echo 将k/v形式的数据推送至pushgateway
最后将监控数据的脚本结合contab定时任务反复执行上传数据,服务端就能持续获得数据了
六、结合Grafana实现报警
部署Grafana—>略过
1、Grafana开启邮件报警
修改配置文件如下: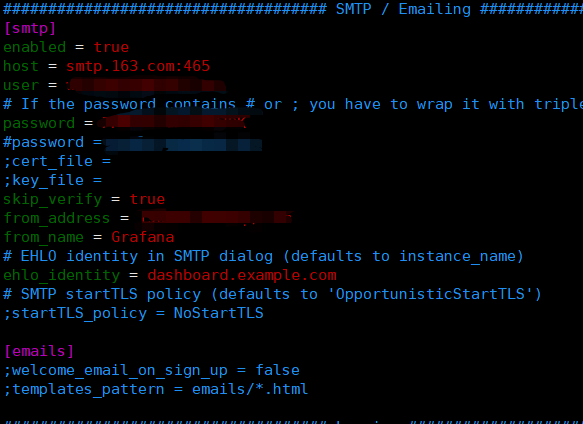
重启Grafana
测试Grafana邮件报警功能:
Grafana页面修改如如下,address处填写自己邮箱,点击Test可收到测试邮件,收到邮件代表邮箱配置正确,Save即可,没有收到可以查看Grafana日志进行分析。
测试邮件如下: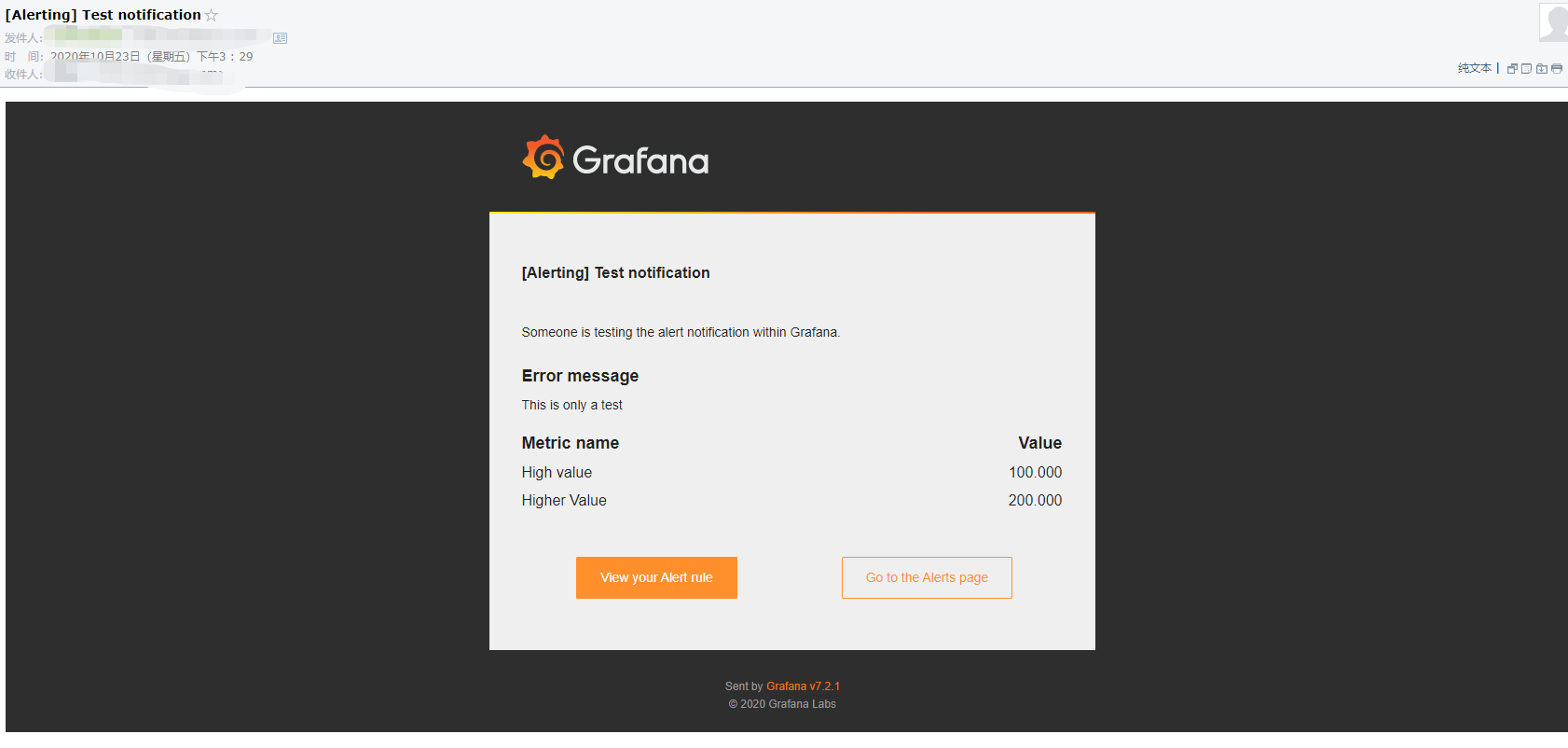
2、添加仪表盘
点击Dashboard—>Add new Panel,在Metrics中填写查询数据命令
可以使用之前自定义的ssh_logins数据做展示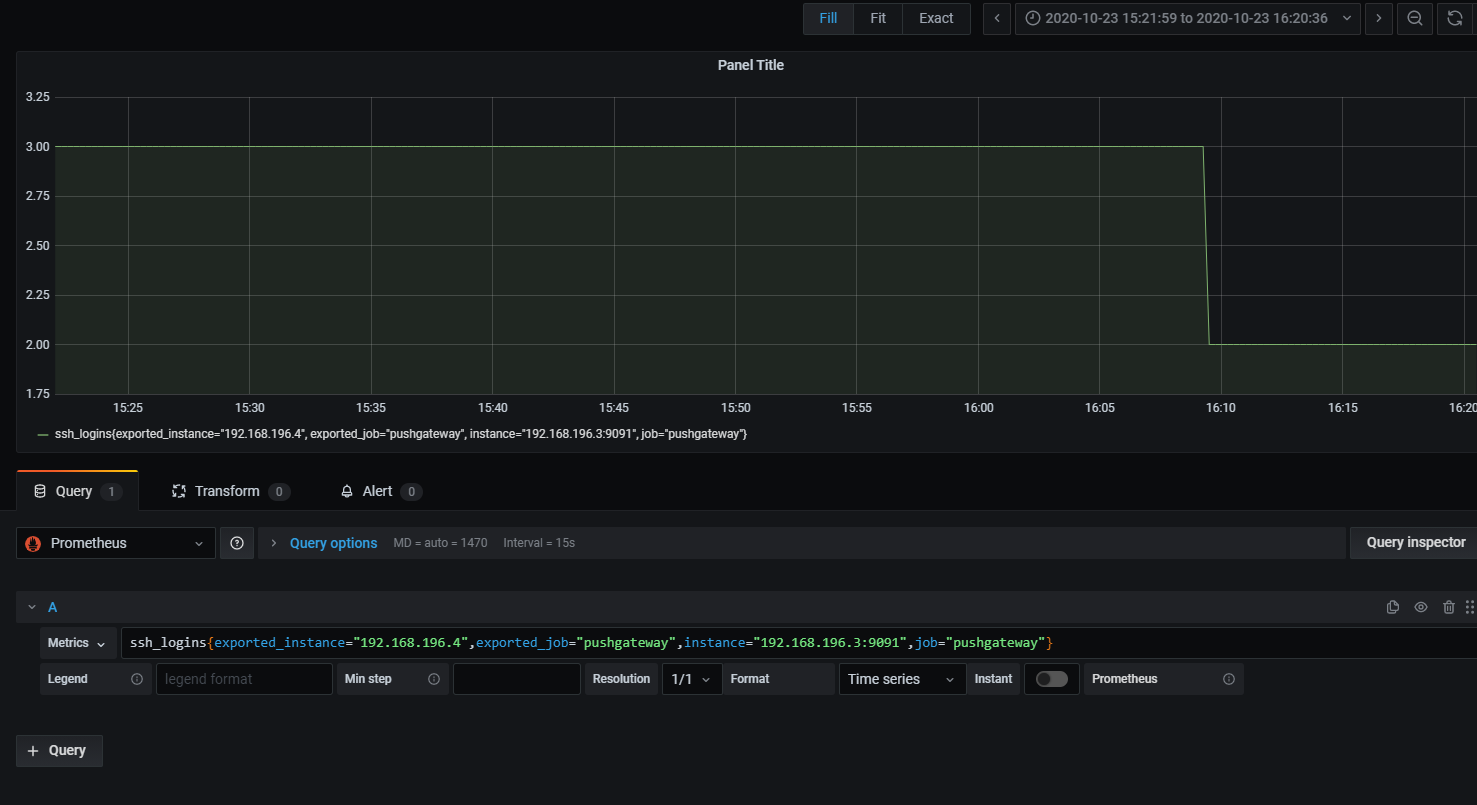
3、配置报警规则
在仪表盘中点击Alert—>Create Alert
配置以上后保存即可( 上图WHEN根据自己适合选择)
然后在客户端多开启几个终端,稍后就可以在Grafana中看到预警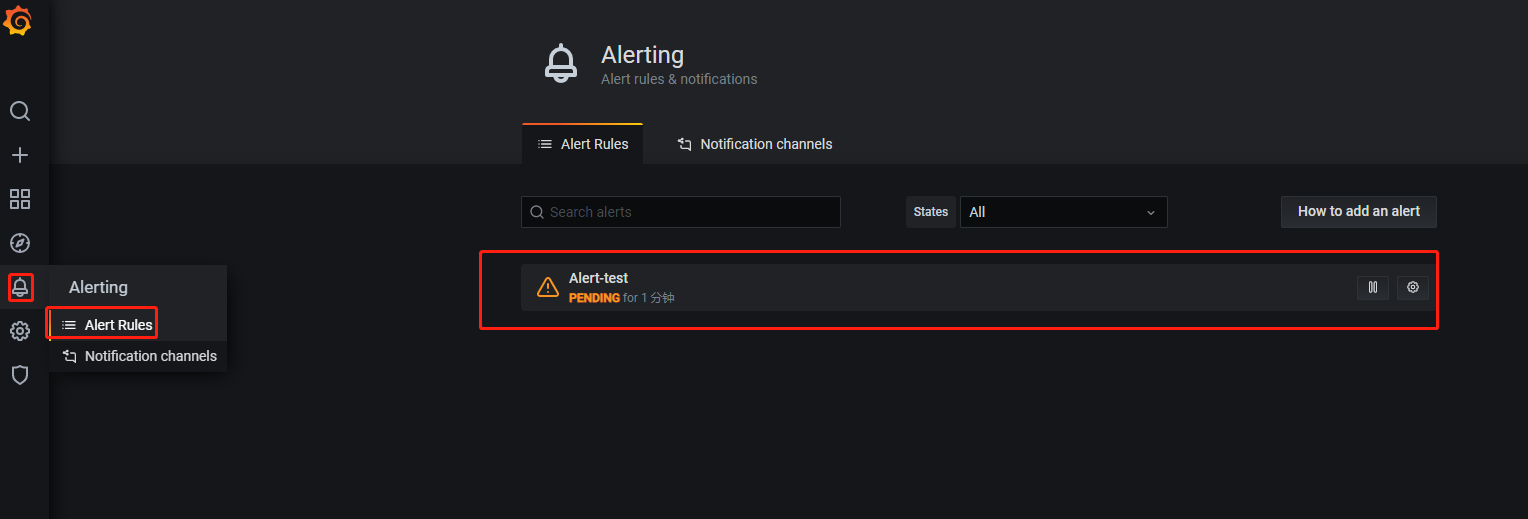
邮件见邮箱

若有收获,就点个赞吧
0 人点赞
