模式比较
| 模式 | 简介 |
|---|---|
| standalone | Spark 自带,如果一个集群是 Standalone 的话,需要在每台机器上部署 Spark |
| YARN | 建议大家在生产上使用该模式,统一使用 YARN 对整个集群作业 (MR/Spark) 的资源调度,前期调试可以使用 client 模式,方便通过打印查看输出,稳定后切换到 cluster 模式,此时所有打印将不会出现,可在日志查看任务运行情况。 |
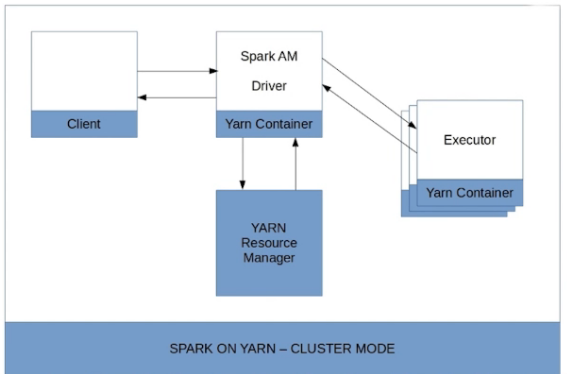
Spark on YARN 之 client 与 cluster 模式区别
| 模式 | Driver运行于 | 优点 | 缺点 |
|---|---|---|---|
| client | client Client 请求 container 完成作业调度执行,client 不能退出;日志在控制台输出,方便查看 |
固定P 方便诊断 |
需要自行维护本地机器(性能要求较高) 需要本地机器与集群网络良好 |
| cluster | cluster 一但提交作业就可以关掉,作业已经运行在 yarn 上;日志在客户端看不到,以为作业运行在 yarn 上,通过 yarn logs -applicationIdapplication_id |
不需要考虑client机器与集群关系; 有框架容错 |
不方便诊断 |
Spark Standalone-Client
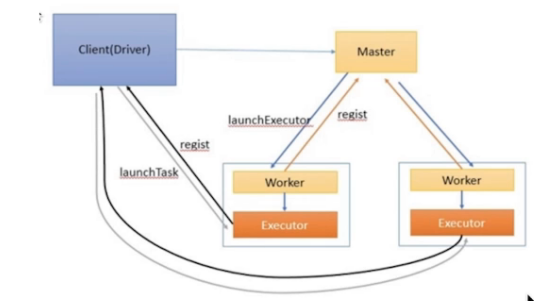
Spark Standalone-Cluster
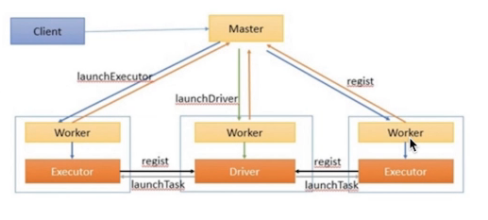
Yarn Application
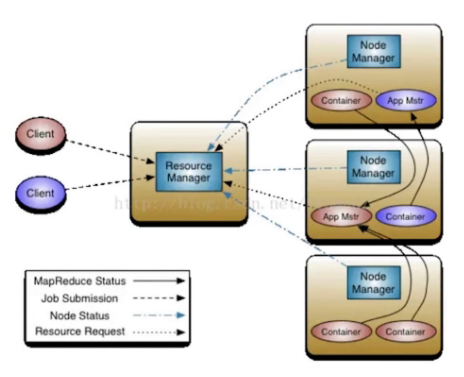
Spark Yarn-Client
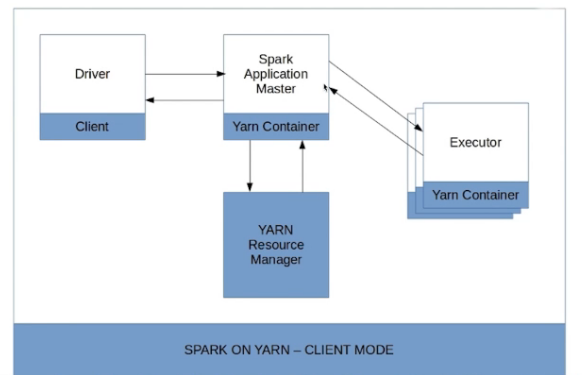
Spark Yarn-Cluster
Spark 基本的提交语句
./bin/spark-submit \ —class \ —master \ —deploy-mode \ —conf = \ … # other options \ [application-arguments]
#/bin/shjarspath=''for file in `ls /home/alp_jars/*.jar`dojarspath=${file},$jarspathdonejarspath=${jarspath%?}#echo $jarspathspark2-submit \--master yarn \--deploy-mode client \--class realtime.Spark2HBase \--jars $jarspath \--num-executors 12 \--executor-memory 30G \--executor-cores 5 \--driver-memory 10G \--driver-java-options "-XX:+TraceClassPaths" \/home/alp-spark.jar $1 $2 $3 $4 $5
- 参数的含义:
—class: 主函数所在的类。
—master: master 的 url,后面会解释 (e.g. spark://23.195.26.187:7077)
—deploy-mode: 部署 driver 在本地还是集群的一个 work 节点上,这也是 client 模式与 cluster 模式的区别。默认是 client 的模式。
—conf: 用 key=value 形式指定参数,如果包含空格那么要用双引号引起来,例如 “key=value”
application-jar:jar 包的路径。该路径必须在集群内全局可见。 例如: hdfs:// path 或者 file:// 这个 path 必须是所有节点都存在。.
application-arguments: 传递给 main 函数 参数,如 java main 方法中的 args [].
- 关于默认配置文件:
spark-submit 会默认读取 conf/spark-defaults.conf 里面设置 配置
- 依赖管理:
使用 spark-submit 来提交 spark 程序,spark app 本身 jar 以及使用 —jars 指定的所有 jar 包都会自动被分发到集群。
—jars 参数必须使用逗号分隔。spark 使用下面这些方法指定 jar 来分发 jar:
file: - 绝对路径 file:/ dirver 的 http file server。executors 会从该 driver 上拉取 jar。
hdfs:, http:, https:, ftp: - 从这些位置拉取
local: - 从 worke 所在 每台机器本地拉取文件,适合于 jar 包很大的场景。
配置说明
| 参数 | 说明 | 默认值 | |
|---|---|---|---|
| —conf spark.yarn.maxAppAttempts=4 |
配置重新运行应用程序的最大尝试次数 | 2 | |
| —confspark.yarn.am.attemptFailuresValidityInterval=1h | 尝试计数器应该在每个小时都重置 | ||
| —conf spark.task.maxFailures=8 | Task重试最大次数 | 4 | |
| —queue realtime_queue | 建议使用YARN Capacity Scheduler并将长时间运行的作业提交到单独的队列 | ||
| —conf spark.speculation=true | 启用推测性执行。只有当Spark操作是幂等时,才能启用推测模式。 | ||
| —principal user/hostname@domain—keytab /path/to/foo.keytab | Kerberos主体和keytab作为spark-submit命令传递(在安全的HDFS群集上,长时间运行的Spark Streaming作业由于Kerberos票据到期而失败。没有其他设置,当Spark Streaming作业提交到集群时,会发布Kerberos票证。当票证到期时Spark Streaming作业不能再从HDFS写入或读取数据) | ||
| kafka.max.partition.fetch.bytes | 从kafka获取数据大小限制,如果Kafka数据大小超过设定值则无法获取 |
对于依赖jar包的管理
每次 Application 的提交都会上传相关依赖的jar包,影响HDFS的性能以及占用HDFS的空间,同样我们也可以将程序 jar 包与依赖 jar 包上传到HDFS,避免重复分发。
方法一:--jars hdfs://**.jar
方法二:
修改conf/spark-default.conf添加以下配置spark.yarn.jar hdfs://**.jar
或者
修改 vim conf/spark-env.shspark.executor.extraClassPath=/home/lib/*spark.driver.extraClassPath=/home/lib/*
这种方式使用较少,因为把依赖 jar 包写死了,只要 Application 依赖包发生变化就需要重新修改路径文件,并且需要把所有的jar包都拷一遍。
方法三:
spark on yarn(cluster),如果应用依赖第三方jar文件
最终解决方案:将第三方的jar文件copy到${HADOOP_HOME}/share/hadoop/common/lib文件夹中(所有节点均要求copy)。

若有收获,就点个赞吧
0 人点赞
