一般设置写在外面,代码执行优先级最高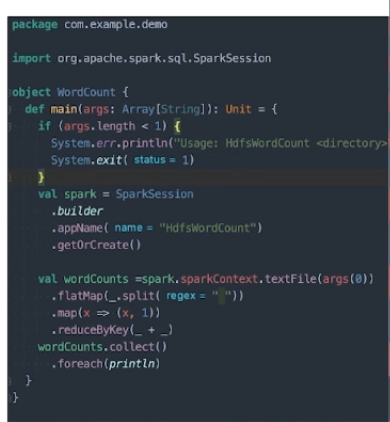
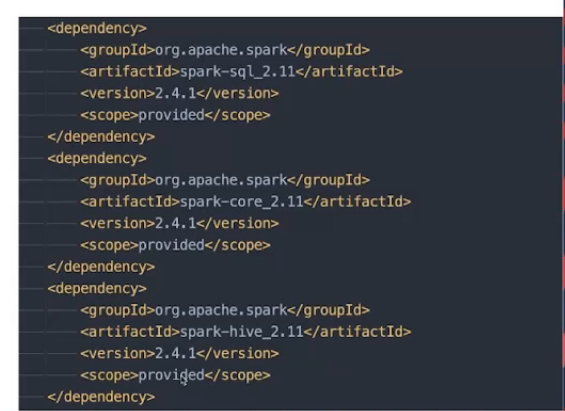
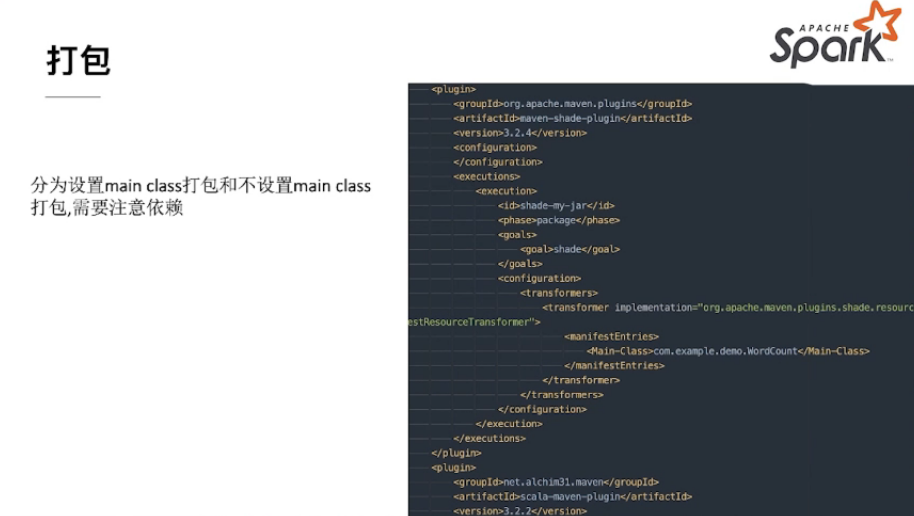
设置main class
在pom写入main,适合单个main
环境准备
准备Hadoop配置
- Hadoop相关配置文件
- Export HADOOP_CONF_DIR
- 复制hadoop配置到SPARK_HOME/conf
kerberos相关
- Spark配置spark.yarn.keytab |—keytab
- Spark配置spark.yarn.Principal |—principal
- 多个hdfs集群需要配置spark.yarn.access.hadoopFileSystems=nn1,nn2
2.4中kerberos生命周期由Application master维护 client任务启动,RM会启动AM生成token,同时AM同步HDFS并将token保存,发送给executor
准备Hive配置
Driver CLASS_PATH需要有hive-site.xml
- 复制hive-site.xml 到SPARK_HOME/conf(需保证有hivemetastore地址及端口,默认9083)
- 打包的时候带入hive-site.xml(不推荐)
- Spark打包的hive版本和集群版本需要一致
- 通过设置spark.sql.hive.metastore.jars=/hive/jar/*
常用进阶配置
1.设置启动时的JVM参数
- spark.yarn.am.extraJavaOptions
- spark.driver.extraJavaOptions
- spark.executor.extraJavaOptions
2.设置spark.yarn.dist.files可以把executor代码运行需要文件分发
本地文件分发到各节点 同:spark-submit —files
3.eventlog相关配置,可以方便诊断
- spark.eventLog.enabled
- spark.eventLog.dir(hdfs路径必须带上schema,否则默认访问本地文件系统)
Spark读取配置优先级
1.读取代码设置
2.提交任务使用 —conf设置
3.spark-defaults.conf

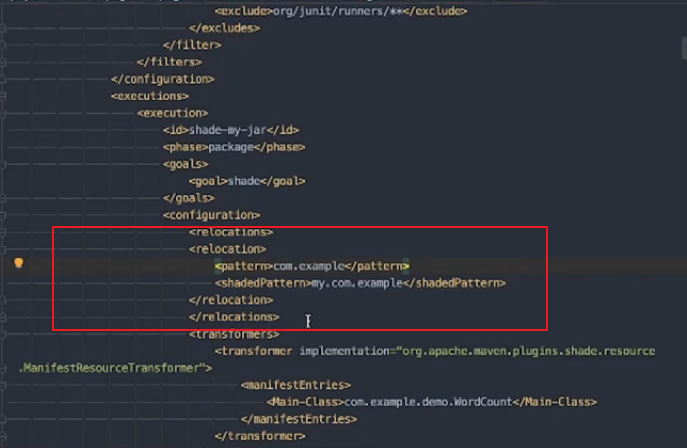
将pattern内开头的包替换为shaded下的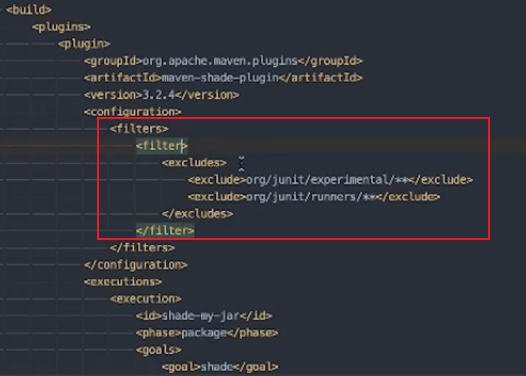
过滤包
mvn package -DskipTests
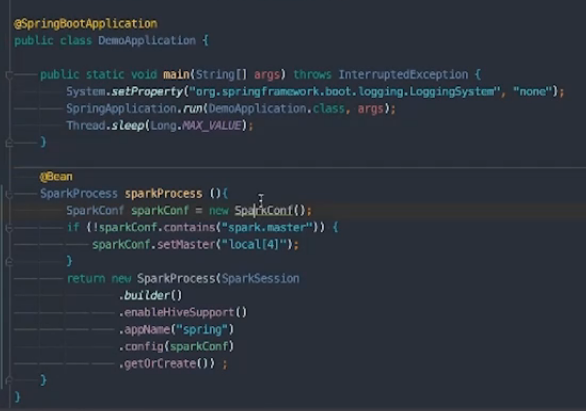
spring与driver在一个节点
hadoop相关配置经常改动,so不放在spark下,采用环境变量的方式导入进去
spark-submit启动方式会将spark下的jars加到classpath里





验证:

若有收获,就点个赞吧
0 人点赞
