Canal 介绍
Canal 是阿里巴巴开发数据实时同步框架,原理与OGG基本类似,都是捕获数据库日志数据,进行解析,将其发送到目标端(比如Kafka 消息队列,Canal 1.1版本支持)。
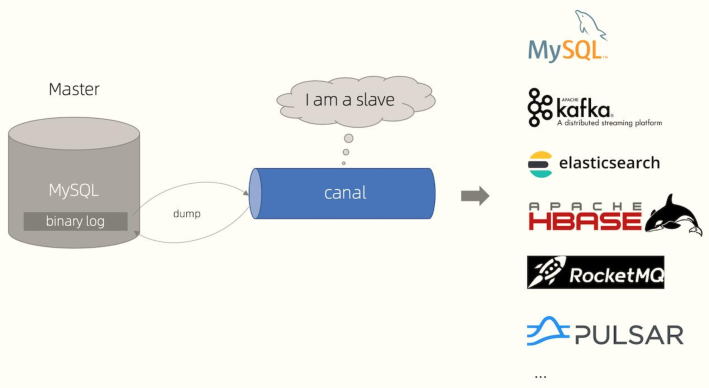
MySQL 的 binlog
针对MySQL数据库来说,日志数据:binlog日志,二进制日志。
什么是 binlog
MySQL的二进制日志可以说MySQL最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。
默认情况下,MySQL数据库没有开启binlog日志,开启二进制日志大概会有1%的性能损耗。二进制有两个最重要的使用场景:
- MySQL Replication在Master端开启binlog,Master把它的二进制日志传递给slaves来达到master-slave数据一致的目的。
- 数据恢复,通过使用mysqlbinlog工具来使恢复数据。
二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
binlog的分类设置
mysql binlog的格式有三种,分别是STATEMENT,MIXED,ROW。
在配置文件中可以选择配置 binlog_format= statement|mixed|row
三种格式的区别:
- statement
语句级,binlog会记录每次一执行写操作的语句。
相对row模式节省空间,但是可能产生不一致性,比如
update tt set create_date=now()
如果用binlog日志进行恢复,由于执行时间不同可能产生的数据就不同。
优点:节省空间
缺点:有可能造成数据不一致。
- row
行级, binlog会记录每次操作后每行记录的变化。
优点:保持数据的绝对一致性。因为不管sql是什么,引用了什么函数,他只记录执行后的效果。
缺点:占用较大空间。
- mixed
statement的升级版,一定程度上解决了,因为一些情况而造成的statement模式不一致问题
默认还是statement,在某些情况下譬如:
当函数中包含 UUID() 时;
包含 AUTO_INCREMENT 字段的表被更新时;
执行 INSERT DELAYED 语句时;
用 UDF 时;
会按照 ROW的方式进行处理
优点:节省空间,同时兼顾了一定的一致性。
缺点:还有些极个别情况依旧会造成不一致,另外statement和mixed对于需要对binlog的监控的情况都不方便。
综合上面对比,Canal想做监控分析,选择row格式比较合适
Canal 工作原理
Canal框架原理,参考MySQL数据主从复制原理。
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看);变更数据,记录日志:biglog
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log);IO 线程,获取binlog
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据;SQL线程,执行语句

- Canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 Canal )
- Canal 解析 binary log 对象(原始为 byte 流),发送到 kafka
Canal 架构
Canal框架使用Java语言编写,启动服务Server,每个服务配置多个实例Instance,如下结构所示: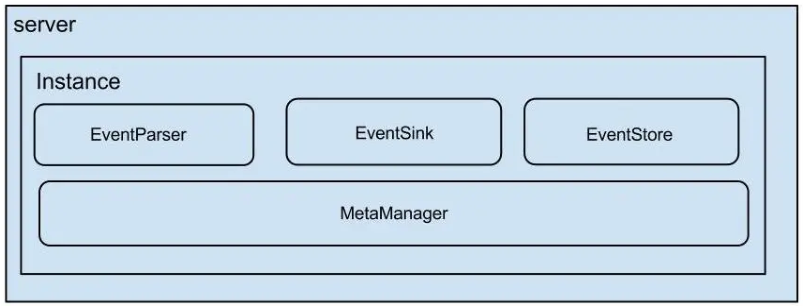
- Canal Server 代表一个 Canal 运行实例,对应于一个 JVM;
- Instance 对应于一个数据队列 (1个 Canal Server 对应 1…n 个 Instance)
- 监控某个数据库database binlog日志,需要将数据,发送到Kafka消息队列和Es索引index
- 发送到Kafka,称为1个实例:instance(binlog -> instance -> kafka)
- 发送到Es,称为1个实例:instance(binlog -> instance -> es)
- Instance下的子模块
- eventParser: 数据源接入,模拟 slave 协议和 master 进行交互,协议解析
- eventSink: Parser 和 Store 链接器,进行数据过滤,加工,分发的工作
- eventStore:数据存储
- metaManager:增量订阅 & 消费信息管理器
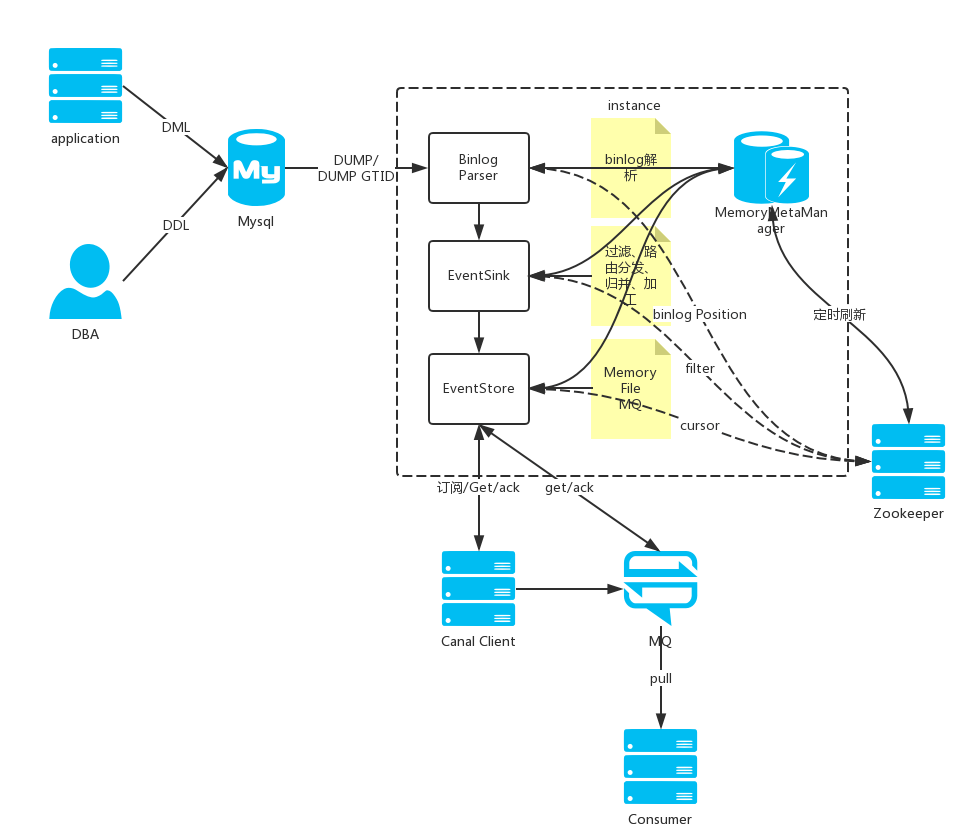
总结:CanalServer来说,启动1个服务,运行多个instance实例(每个实例对应一个sink),每个实例instance包含四个部分:eventParse、eventSink、eventStore、metaManager。
EventParser在向MySQL发送dump命令之前会先从Log Position中获取上次解析成功的位置(如果是第一次启动,则获取初始指定位置或者当前数据段binlog位点)。
Canal 集群高可用
Canal 1.1.4版本开始,提供集群高可用HA,运行2个CanalServer服务,一个为Active,一个为Standby,当Active宕掉以后,Standby接收工作,继续进行数据实时同步功能。
Canal 集群高可用如何实现的,如下图所示,核心点2个:
- CanalServer服务启动2个:running(active)、Standby
- 依赖Zookeeper监控CanalServer状态,并且存储状态
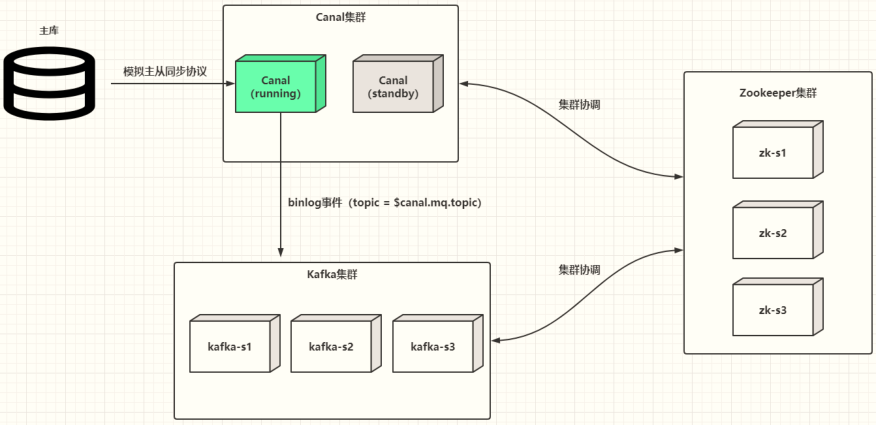
比如CanalServer中有2个Instance实例时,高可用集群如何工作: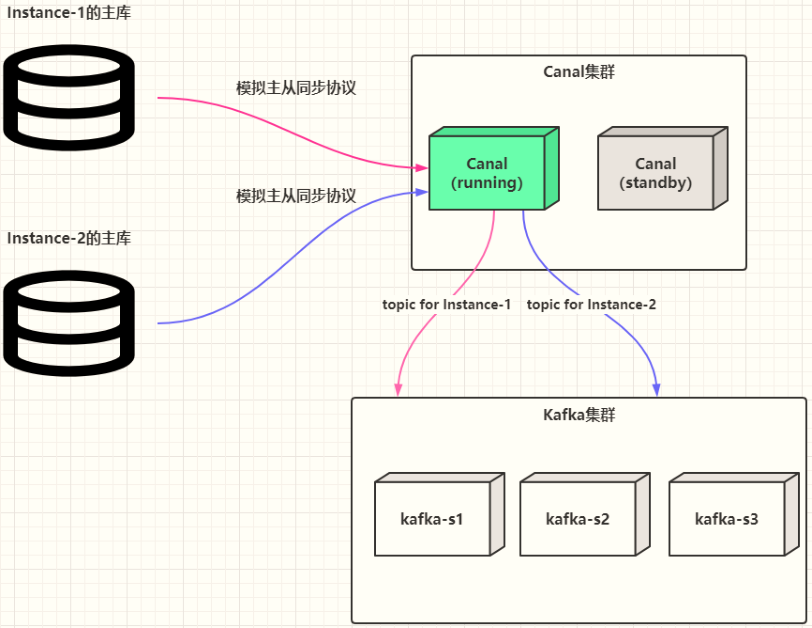
常见业务逻辑
业务系统 -> MySQL(业务主库) -> Canal 集群 -> Kafak Topic -> 实时应用程序 :统计分析 -> Redis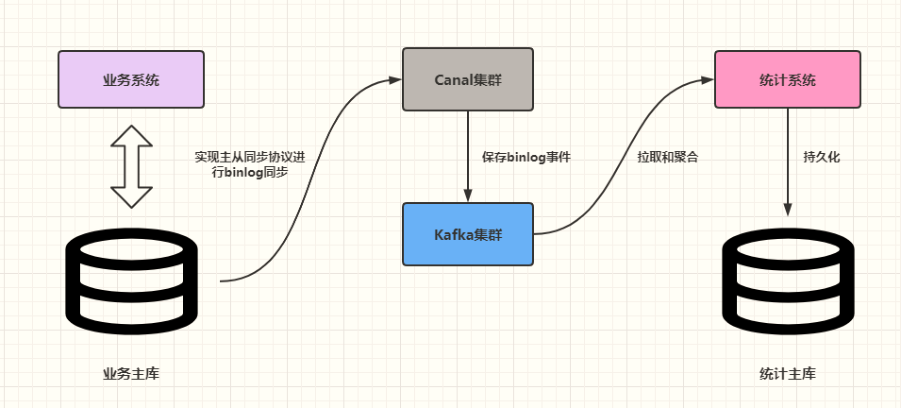

若有收获,就点个赞吧
0 人点赞
