前言
安装hadoop
0-使用ssh进行无密码验证登录
需要对ssh进行设置,在配置完hadoop后才能成功运行hadoop,不然在运行时会出现下面截图:
步骤如下:
首先运行ssh localhost
正常情况下是免密登录的,如果你还要输入密码的话,那就是你ssh没有配置好。这里要说一下的是ssh7.0之后就关闭了dsa的密码验证方式,如果你的秘钥是通过dsa生成的话,需要改用rsa来生成秘钥。
ssh-keygen -t rsa -P ‘’ -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
再次运行ssh localhost。如果不需要输入密码,说明ssh配置好了。
详情见:
hadoop 3.x 启动过程中 Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
https://blog.csdn.net/qq_38025219/article/details/95460630
接下来,在配置完hadoop之后,再运行hadoop,执行如下指令:start-all.sh就可以了。
下载hadoop
从官网下载tar.gz后缀名的linux下的压缩包到win10系统下,然后通过Xshell的FTP插件或者rz指令来从win10中上传该压缩包到linux的当前用户目录下。
上传服务器,解压,安装
解压缩压缩包到指定文件夹
tar -zxvf hadoop-3.2.0.tar.gz // 解压
mv hadoop-3.2.0 /hadoop // 移动到指定目录下
配置相关文件
hadoop3.2.1目录下的etc/hadoop中共四个文件需要配置:hadoop-env.sh,core-site.xml,mapred-site.xml,hdfs-site.xml
1.配置hadoop-env.sh
执行命令vim hadoop-env.sh
设置JAVA_HOME: export JAVA_HOME=/usr/local/jdk-1.8(这里是安装jdk时配置的java环境变量)
2.core-site.xml 配置如下:
hadoop.tmp.dir file:/hadoop/tmp Abase for other temporary directories. fs.defaultFS hdfs://192.168.0.151:9000

其中的hadoop.tmp.dir的路径可以根据自己的习惯进行设置。
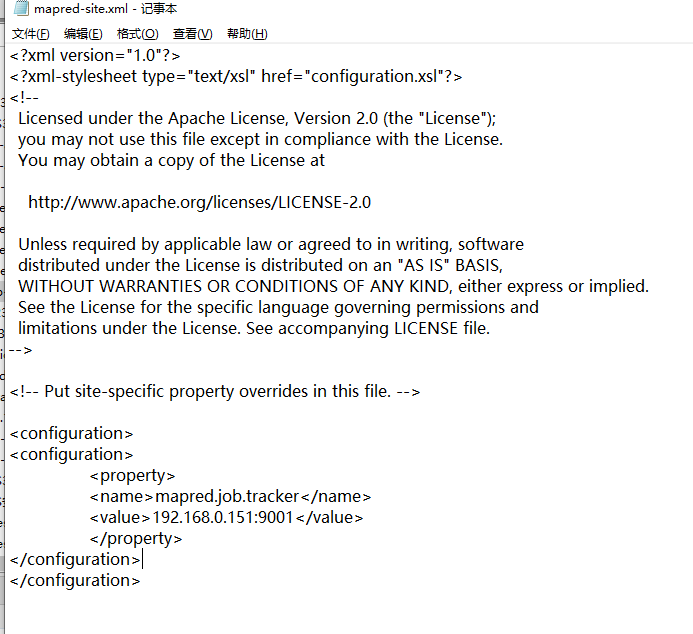
3.mapred-site.xml.template配置如下:
mapred.job.tracker 192.168.0.151:9001
4.hdfs-site.xml配置如下:
dfs.replication 1 dfs.namenode.name.dir file:/hadoop/tmp/dfs/name dfs.datanode.data.dir file:/hadoop/tmp/dfs/data

其中dfs.namenode.name.dir和dfs.datanode.data.dir的路径可以自由设置,最好在hadoop.tmp.dir的
目录下面。
将hadoop添加到环境变量中
vim /etc/profile
profile中存储的就是很多配置的环境变量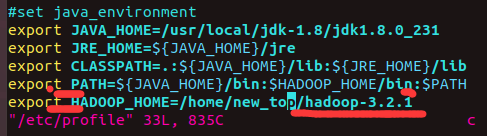
保存该文件之后,source /etc/profile使此配置立即生效.—该指令在修改上面四个hadoop配置文件时也可以使用一下, 来进行更新。
然后,输入hadoop若出现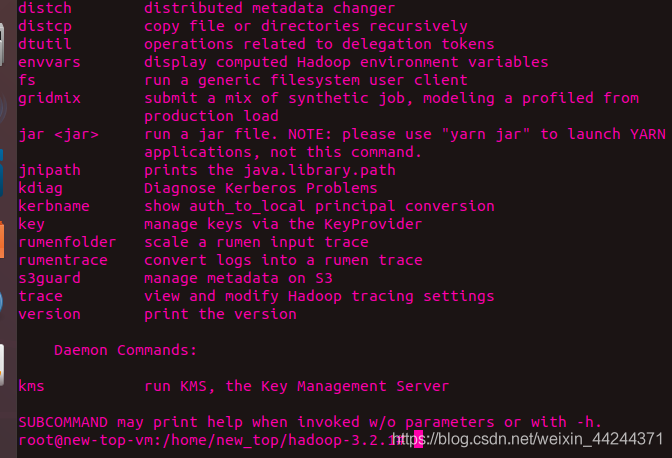

过程需要进行ssh免密验证,这里只需要输入y继续运行即可
运行成功的截图如下: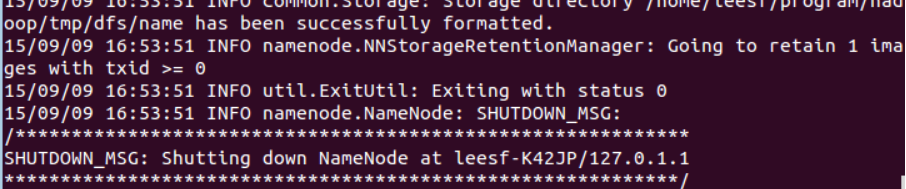
开启NameNode和DataNode守护进程
使用命令:sbin/start-all.sh 。
然后使用命令:jps。若出现截图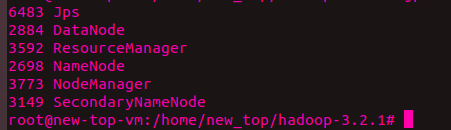
就代表运行成功。
然而就是这里出现了最多的问题,具体如下:
① jps或者java命令使用后,显示没有resourceMananger与NodeManager这两个进程,如下: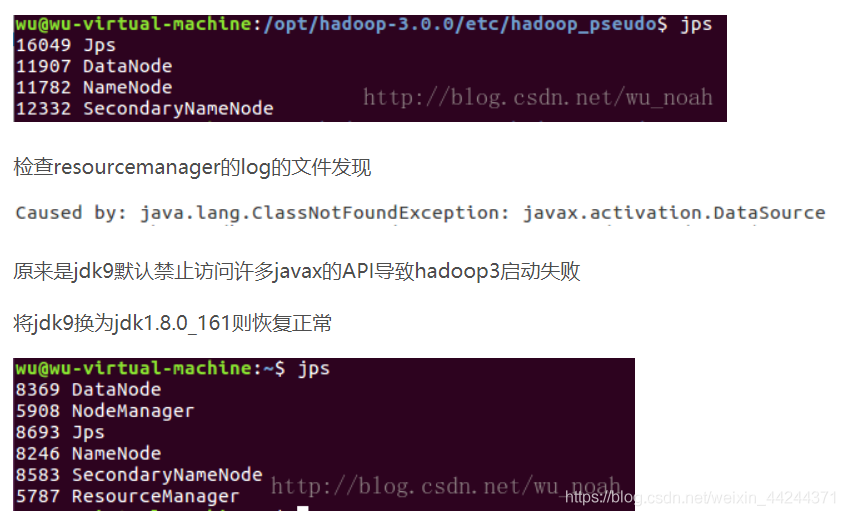
好,那么问题又来了,如何切换jdk版本呢?有如下三种方法:
1. 从官网下载jdk1.8(与jdk8一样,只是名字不同),解压到usr/local/下的自定义目录,然后配置相关环境变量(/etc/profile中),因为我之前已经安装了jdk13,所以这里配置时只需要把相应位置的名称换一下。最后source /etc/profile即可。—这种是配置文件进行改变,比较麻烦。
2. 通过alternative命令进行切换—见: jdk版本切换-系统命令版https://blog.csdn.net/meilin_ya/article/details/80650945
3. 通过自定义命令进行切换——见:jdk版本切换-自定义命令版https://www.cnblogs.com/c-xiaohai/p/6985581.html
② 执行jps与java时,显示找不到的命令。原因是在切换到root目录时使用的是:su root而不是su - root,su - root 才是真正的完全切换,包括将环境变量也切换过去
③执行sbin/start-all.sh时,出现如下截图:
Starting namenodes on [namenode] ERROR: Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation. Starting datanodes ERROR: Attempting to operate on hdfs datanode as root ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation. Starting secondary namenodes [datanode1] ERROR: Attempting to operate on hdfs secondarynamenode as root ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation. Starting resourcemanager ERROR: Attempting to operate on yarn resourcemanager as root ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation. Starting nodemanagers ERROR: Attempting to operate on yarn nodemanager as root ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
解决办法:
在Hadoop安装目录下找到sbin文件夹,在里面修改四个文件:
1、对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
!/usr/bin/env bash
HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
2、对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
之后再start一次即可
————————————————
版权声明:本文为CSDN博主「沉浸致远」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_44244371/article/details/103606951
Linux环境下HDFS安装
https://blog.csdn.net/xiaohu21/article/details/108028516
Linux安装hadoop和HDFS
https://blog.csdn.net/weixin_39549656/article/details/79748459

若有收获,就点个赞吧
0 人点赞
