3.ES的核心概念
3.1 NRT(Near Realtime)近实时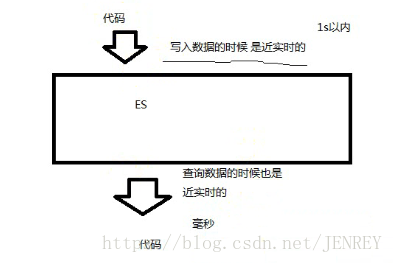
3.2 cluster集群,ES是一个分布式的系统
ES直接解压不需要配置就可以使用,在hadoop1上解压一个ES,在hadoop2上解压了一个ES,接下来把这两个ES启动起来。他们就构成了一个集群。
在ES里面默认有一个配置,clustername 默认值就是ElasticSearch,如果这个值是一样的就属于同一个集群,不一样的值就是不一样的集群。
3.3 Node节点,就是集群中的一台服务器
3.4 index 索引(索引库)
我们为什么使用ES?因为想把数据存进去,然后再查询出来。
我们在使用Mysql或者Oracle的时候,为了区分数据,我们会建立不同的数据库,库下面还有表的。
其实ES功能就像一个关系型数据库,在这个数据库我们可以往里面添加数据,查询数据。
ES中的索引非传统索引的含义,ES中的索引是存放数据的地方,是ES中的一个概念词汇
index类似于我们Mysql里面的一个数据库 create database user; 好比就是一个索引库
3.5 type类型
类型是用来定义数据结构的
在每一个index下面,可以有一个或者多个type,好比数据库里面的一张表。
相当于表结构的描述,描述每个字段的类型。
3.6 document:文档
文档就是最终的数据了,可以认为一个文档就是一条记录。
是ES里面最小的数据单元,就好比表里面的一条数据
3.7 Field 字段
好比关系型数据库中列的概念,一个document有一个或者多个field组成。
例如:
朝阳区:一个Mysql数据库
房子:create database chaoyaninfo
房间:create table people
3.8 shard:分片
一台服务器,无法存储大量的数据,ES把一个index里面的数据,分为多个shard,分布式的存储在各个服务器上面。
kafka:为什么支持分布式的功能,因为里面是有topic,支持分区的概念。所以topic A可以存在不同的节点上面。就可以支持海量数据和高并发,提升性能和吞吐量
3.9 replica:副本
一个分布式的集群,难免会有一台或者多台服务器宕机,如果我们没有副本这个概念。就会造成我们的shard发生故障,无法提供正常服务。
我们为了保证数据的安全,我们引入了replica的概念,跟hdfs里面的概念是一个意思。
可以保证我们数据的安全。
在ES集群中,我们一模一样的数据有多份,能正常提供查询和插入的分片我们叫做 primary shard,其余的我们就管他们叫做 replica shard(备份的分片)
当我们去查询数据的时候,我们数据是有备份的,它会同时发出命令让我们有数据的机器去查询结果,最后谁的查询结果快,我们就要谁的数据(这个不需要我们去控制,它内部就自己控制了)
总结:
在默认情况下,我们创建一个库的时候,默认会帮我们创建5个主分片(primary shrad)和5个副分片(replica shard),所以说正常情况下是有10个分片的。
同一个节点上面,副本和主分片是一定不会在一台机器上面的,就是拥有相同数据的分片,是不会在同一个节点上面的。
所以当你有一个节点的时候,这个分片是不会把副本存在这仅有的一个节点上的,当你新加入了一台节点,ES会自动的给你在新机器上创建一个之前分片的副本。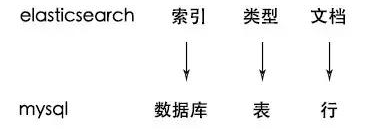
3.10 举例
比如一首诗,有诗题、作者、朝代、字数、诗内容等字段,那么首先,我们可以建立一个名叫 Poems 的索引,然后创建一个名叫 Poem 的类型,类型是通过 Mapping 来定义每个字段的类型。
比如诗题、作者、朝代都是 Keyword 类型,诗内容是 Text 类型,而字数是 Integer 类型,最后就是把数据组织成 Json 格式存放进去了。
Keyword 类型是不会分词的,直接根据字符串内容建立反向索引,Text 类型在存入 Elasticsearch 的时候,会先分词,然后根据分词后的内容建立反向索引。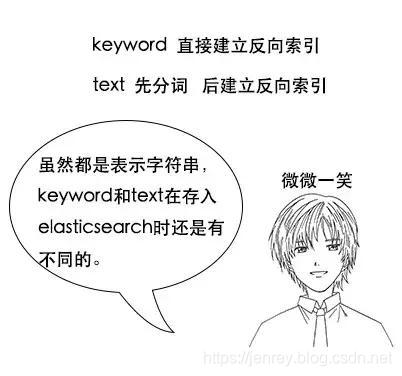
————————————————
版权声明:本文为CSDN博主「Jenrey」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/JENREY/article/details/81290535

若有收获,就点个赞吧
0 人点赞
