1.ElasticSearch的简介
ElasticSearch:智能搜索,分布式的搜索引擎
是ELK的一个组成,ELK是一个产品,而且是非常完善的产品,ELK代表的是:E就是ElasticSearch,L就是Logstach,K就是kibana
E:EalsticSearch 搜索和分析的功能
L:Logstach 搜集数据的功能,类似于flume(使用方法几乎跟flume一模一样),是日志收集系统
K:Kibana 数据可视化(分析),可以用图表的方式来去展示,文不如表,表不如图,是数据可视化平台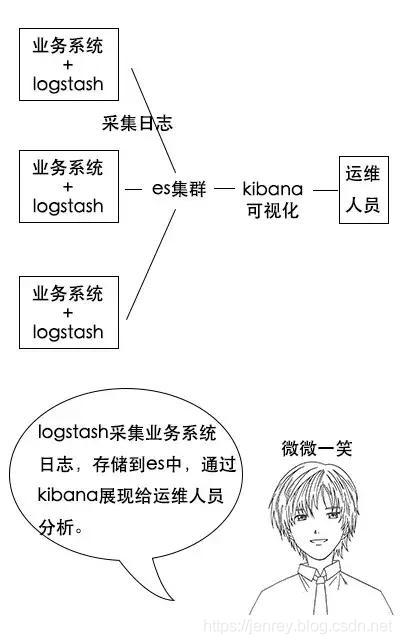
分析日志的用处:假如一个分布式系统有 1000 台机器,系统出现故障时,我要看下日志,还得一台一台登录上去查看,是不是非常麻烦?
但是如果日志接入了 ELK 系统就不一样。比如系统运行过程中,突然出现了异常,在日志中就能及时反馈,日志进入 ELK 系统中,我们直接在 Kibana 就能看到日志情况。如果再接入一些实时计算模块,还能做实时报警功能。
这都依赖ES强大的反向索引功能,这样我们根据关键字就能查询到关键的错误日志了。
什么是搜索?
1)百度,谷歌,必应。我们可以通过他们去搜索我们需要的东西。但是我们的搜索不只是包含这些,还有京东站内搜索啊。
2)互联网的搜索:电商网站,招聘网站,新闻网站。各种APP(百度外卖,美团等等)
3)windows系统的搜索,OA软件,淘宝SSM网站,前后台的搜索功能
总结:搜索无处不在。通过一些关键字,给我们查询出来跟这些关键字相关的信息
什么是全文检索
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同的语言而言,字有不同的含义,比如英文中字与词实际上是合一的,而中文中字与词有很大分别。按词检索指对文章中的词,即语义单位建立索引,检索时按词检索,并且可以处理同义项等。英文等西方文字由于按照空白切分词,因此实现上与按字处理类似,添加同义处理也很容易。中文等东方文字则需要切分字词,以达到按词索引的目的,关于这方面的问题,是当前全文检索技术尤其是中文全文检索技术中的难点,在此不做详述。
什么是倒排索引
以前是根据ID查内容,倒排索引之后是根据内容查ID,然后再拿着ID去查询出来真正需要的东西。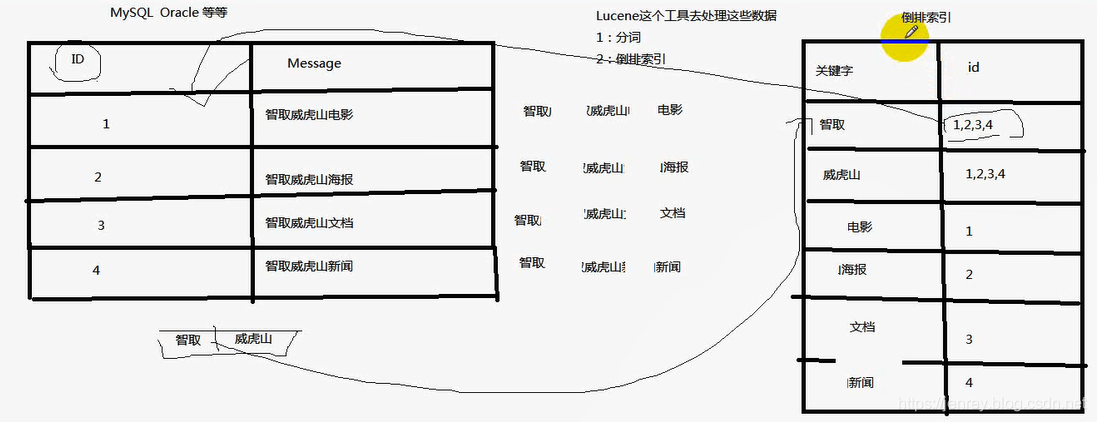
什么是Lucene
Lucene就是一个jar包,里面包含了各种建立倒排索引的方法,java开发的时候只需要导入这个jar包就可以开发了。
Lucene的介绍及使用
https://blog.csdn.net/JENREY/article/details/81004130
典型的用空间换时间。
ES 和 Lucene的区别
Lucene不是分布式的。
ES的底层就是Lucene,ES是分布式的
为什么不用数据库去实现搜索功能?
我们用搜索“牙膏”商品为例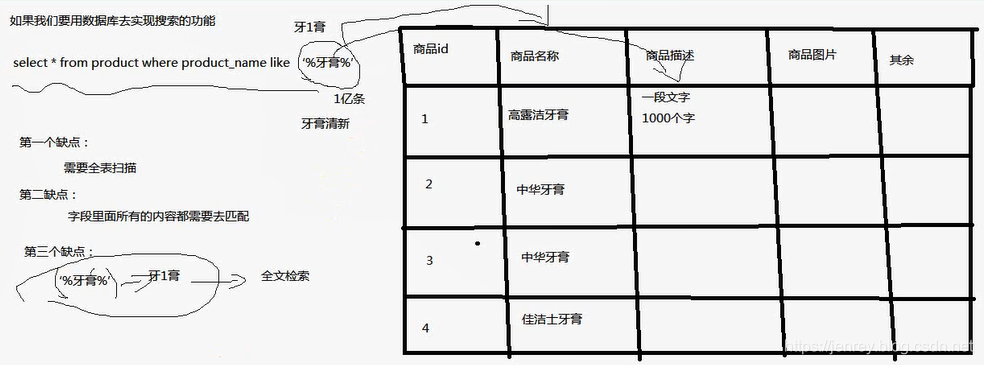
如果用我们平时数据库来实现搜索的功能在性能上就很差。
ES的官网
ES官网点我
https://www.elastic.co/products/elasticsearch
简单使用如下图,可以切换成中文的文档
或者使用spark的中文网站,也有ES的文档,传送门在下面
ES中文文档
http://cwiki.apachecn.org/pages/viewpage.action?pageId=4260364
ES的由来
因为Lucene有两个难以解决的问题,
1)数据越大,存不下来,那我就需要多台服务器存数据,那么我的Lucene不支持分布式的,那就需要安装多个Lucene然后通过代码来合并搜索结果。这样很不好
2)数据要考虑安全性,一台服务器挂了,那么上面的数据不就消失了。
ES就是分布式的集群,每一个节点其实就是Lucene,当用户搜索的时候,会随机挑一台,然后这台机器自己知道数据在哪,不用我们管这些底层、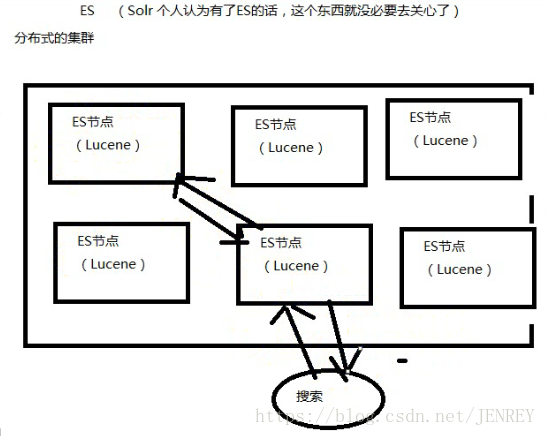
ES的优点
1.分布式的功能
2.数据高可用,集群高可用
3.API更简单
4.API更高级。
5.支持的语言很多
6.支持PB级别的数据
7.完成搜索的功能和分析功能
基于Lucene,隐藏了Lucene的复杂性,提供简单的API
ES的性能比HBase高,咱们的竞价引擎最后还是要存到ES中的。
搜索引擎原理
反向索引又叫倒排索引,是根据文章内容中的关键字建立索引。
搜索引擎原理就是建立反向索引。
Elasticsearch 在 Lucene 的基础上进行封装,实现了分布式搜索引擎。
Elasticsearch 中的索引、类型和文档的概念比较重要,类似于 MySQL 中的数据库、表和行。
Elasticsearch 也是 Master-slave 架构,也实现了数据的分片和备份。
Elasticsearch 一个典型应用就是 ELK 日志分析系统。
ES支持的语言
Curl、java、c#、python、JavaScript、php、perl、ruby
Curl ‘www.baidu.com’ 就是linux的shell命令。可以访问百度,返回的是百度的网页代码
ES的作用
1)全文检索:
类似 select * from product where product_name like ‘%牙膏%’
类似百度效果(电商搜索的效果)
2)结构化搜索:
类似 select * from product where product_id = ‘1’
3)数据分析
类似 select count (*) from product
ES的安装
直接解压就能用(针对中小型项目),大型项目还是要调一调参数的
————————————————
版权声明:本文为CSDN博主「Jenrey」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/JENREY/article/details/81290535

若有收获,就点个赞吧
0 人点赞
