1.单关系数据查询结构
- 数据查询是数据库中最常用的操作
- SQL提供SELECT语句,通过查询操作可得到所需的信息
- 关系(表)的SELECT语句的一般格式为:

2. 无条件查询
- 无条件查询是指只包含“SELECT…FROM“的查询,也称作投影查询
- 投影查询相当于关系代数中的投影运算,需要注意的是,在关系代数中,投影运算之后自动消去重复行;而SQL中必须使用关键字DISTINCT才会消去重复行

- 使用DISTINCT去掉了查询结果中的重复元组

- 查询结果中字段名的顺序是由SELECT后面所列字段名的顺序决定的
例如,在查询结果中,字段sn在sno之前,这和学生表s中字段的排列顺序是不同的
- LIMIT子句控制查询结果中元组的数量
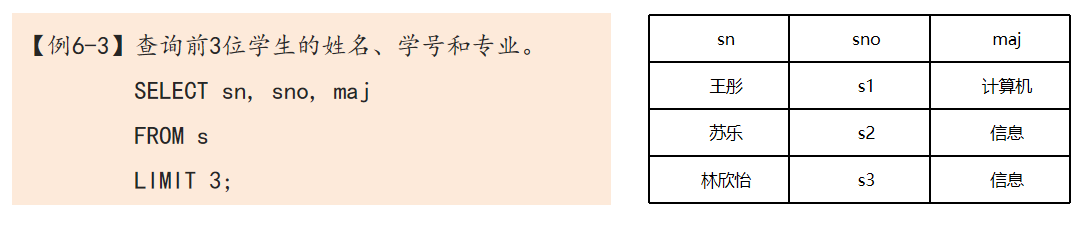
3. 条件查询
- 条件查询需使用WHERE子句指定查询条件
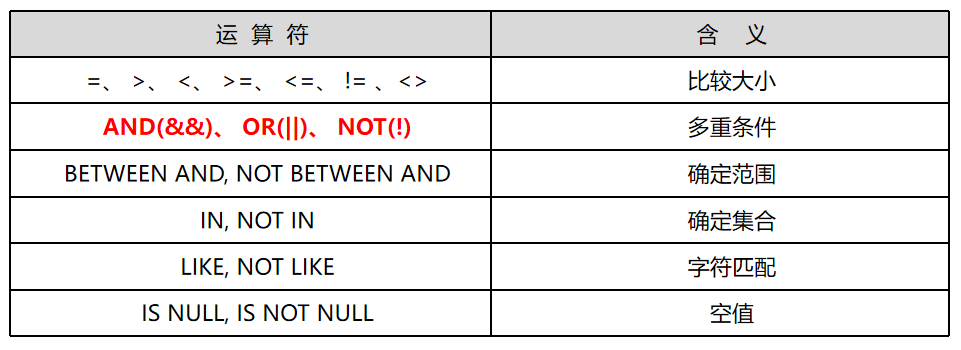
- 查询条件中,字段名与字段名之间,或者字段名与常数之间通常使用比较运算符连接
- 常用的比较运算符如表所示:
(1)比较大小
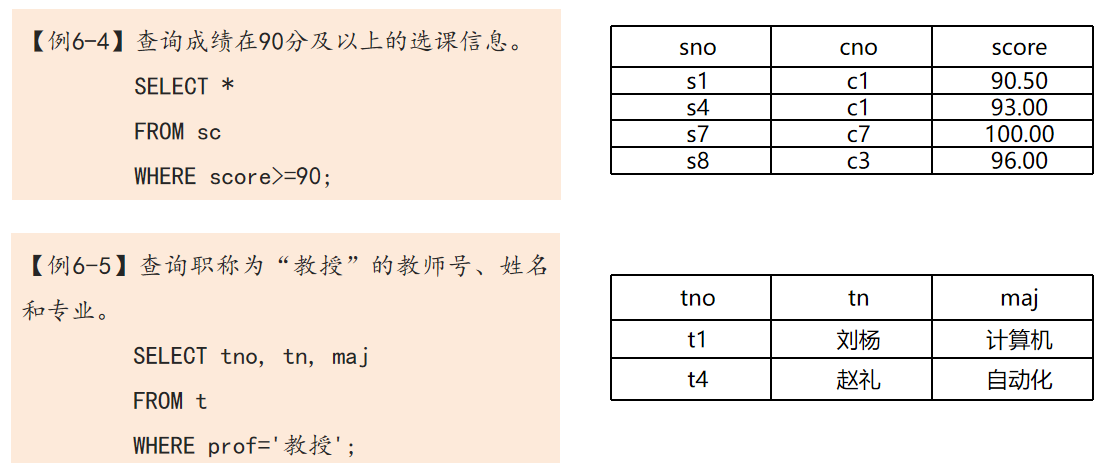
(2)多重条件查询
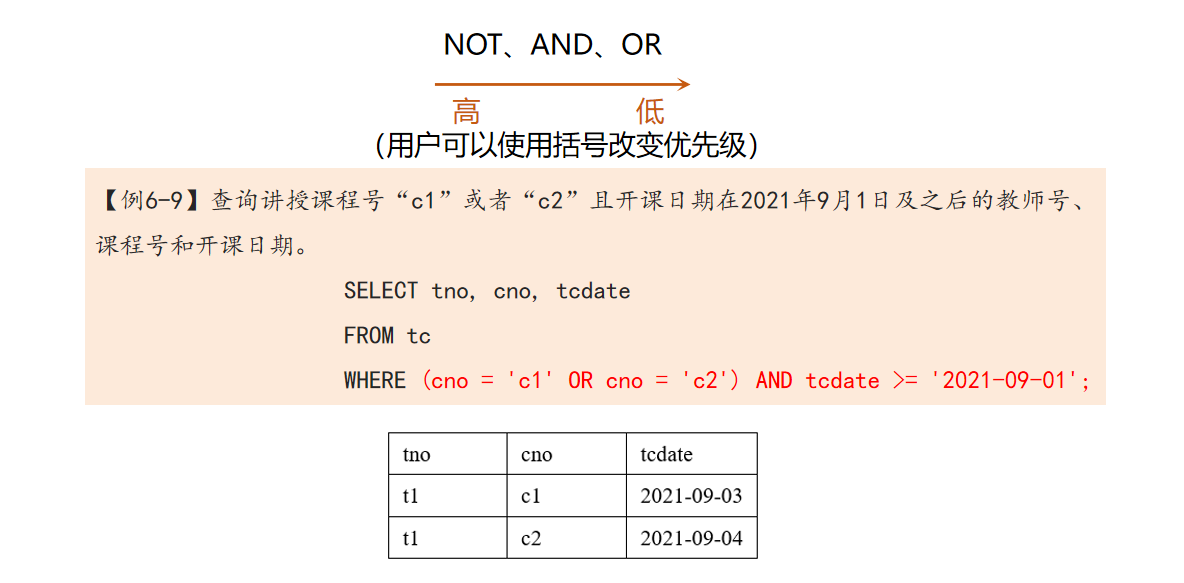
注意:在逻辑运算中,不可以对同一个属性进行逻辑“与”的等值运算
- 逻辑运算符“OR”,可以使用“||”代替;逻辑运算符“AND”可以使用“&&”代替
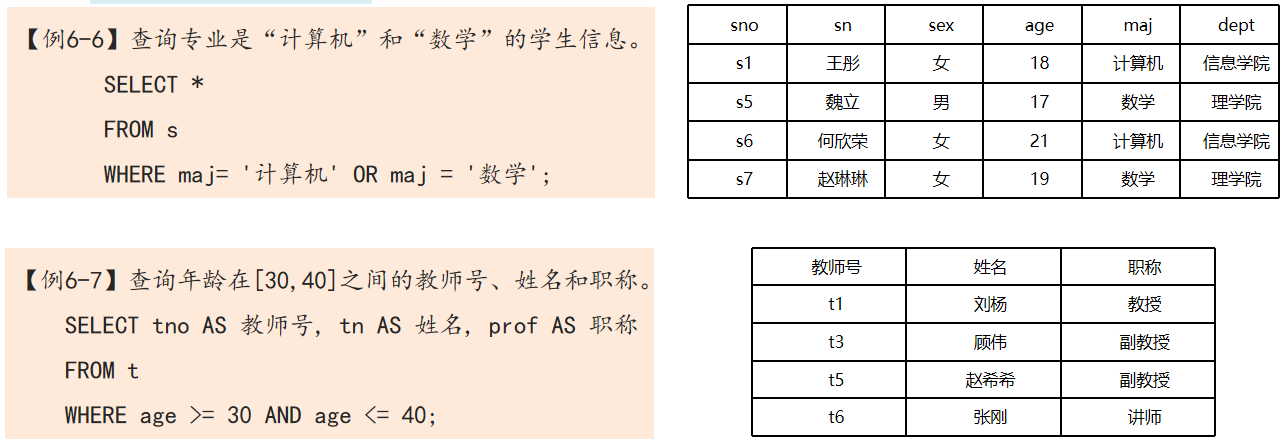

- 利用“BETWEEN AND“或者“NOT BETWEEN AND”操作可以查询字段值属于或者不属于指定连续取值区间的元组。

(3)确定范围
- 利用“BETWEEN AND“或者“NOT BETWEEN AND”操作可以查询字段值属于或者不属于指定连续取值区间的元组


(4)确定集合
- 利用“IN“或者“NOT IN”操作可以查询字段值属于或者不属于指定集合的元组


(5)部分匹配查询
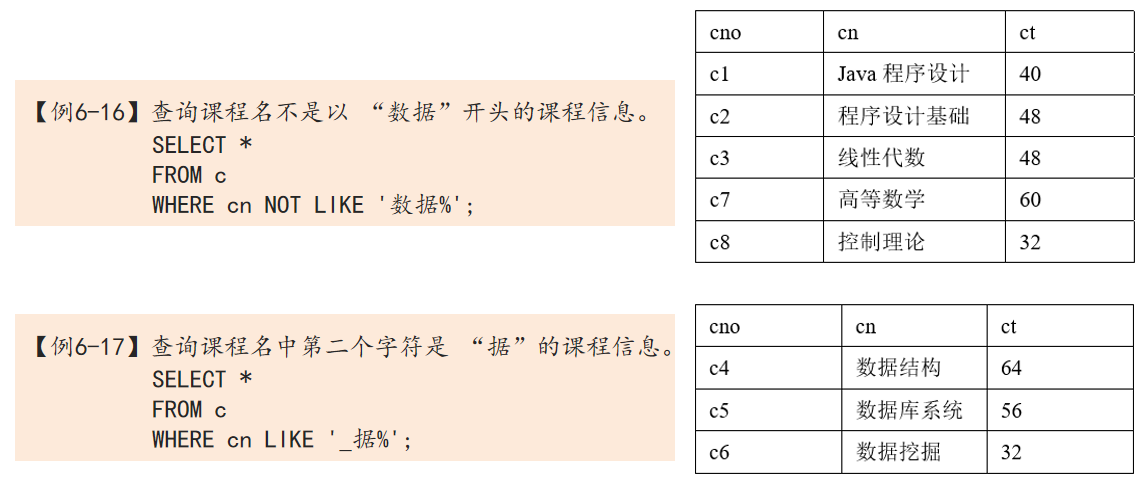
- 查询时,如果不知道完全精确的值,可以使用LIKE或NOT LIKE进行部分匹配查询(也称模糊查询)
- LIKE定义的一般格式为:
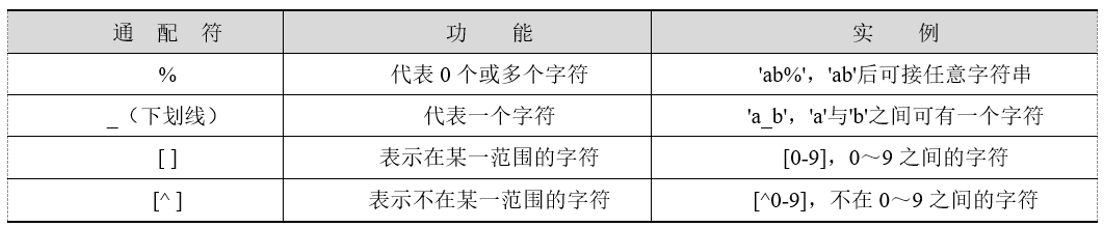
<字段名> LIKE <字符串常量>其中,字段名必须为字符型,字符串常量中的字符可以包含通配符,利用这些通配符,可以进行模糊查询,字符串中的通配符及其功能如表所示

(6)空值查询
- 某个字段没有值称为具有空值(NULL)
- 通常没有为一个元组的某个字段输入值时,该字段的值就是空值
- 空值不同于零和空格,它不占任何存储空间
- 例如,某些学生选修了课程但没有参加考试,就会造成数据表中有选课记录,但没有考试成绩
- 考试成绩为空值与考试成绩为0分是不同的

4. 聚合函数查询
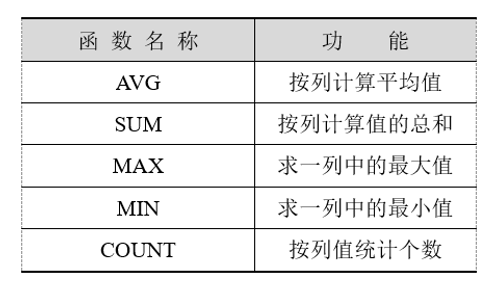
- SQL提供了许多实用的聚合函数,增强了基本查询能力
- 常用的聚合函数如表所示
SQL提供的聚合函数(aggregate function)包括:
- count( [DISTINCT | ALL] {* | <列名>} ):统计关系的元组个数或一列中值的个数;
- sum( [DISTINCT | ALL] <列名> ):统计一列中值的总和(此列必须为数值型);
- avg( [DISTINCT | ALL] <列名> ):统计一列中值的平均值(此列必须为数值型);
- max( [DISTINCT | ALL] <列名> ):统计一列中值的最大值;
- min( [DISTINCT | ALL] <列名> ):统计一列中值的最小值。
指定DISTINCT谓词,表示在计算时首先消除<列名>取重复值的元组,然后再进行统计 指定ALL谓词或没有DISTINCT谓词,表示不消除<列名>取重复值的元组

- 从上述查询结果可以看出,在使用聚合函数进行查询时,查询结果中的字段名是聚合函数的函数名
- 如果要更清楚地表示查询内容的含义,可以为聚合函数指定别名
- 例如:

- 请注意,学号为“s2“的学生共选修了4门课程,但是其中1门课程的成绩为空值,因此,聚合函数SUM和AVG对其成绩进行计算时,只考虑了有效成绩,没有将空值计算在内。

- 例6-22中的COUNT(cno)也可以写为COUNT(sno)、COUNT(score)或者COUNT(*)
- 但是,如果查询学号为“s2“或者“s4”的学生的选课门数时,由于其选课成绩包含空值,则不能使用COUNT(score),因为COUNT只对有效成绩进行计数,导致选课门数出现错误

- 上述语句中的关键字DISTINCT不能省略,它的作用是消除重复的元组

上述语句中的COUNT(*)用来统计元组的数量,不消除重复元组,不允许使用DISTINCT关键字
5. 分组查询
GROUP BY子句可以将查询结果按字段列或字段列的组合在行的方向上进行分组,每组在字段列或字段列的组合上具有相同的值

- GROUP BY子句按学号字段sno的值分组,所有具有相同学号的元组为一组,对每一组使用函数COUNT进行计算,统计出每个学生的选课门数,HAVING子句去掉不满足COUNT(*)>=3的组。
- 当在一个SQL查询中同时使用WHERE子句、GROUP BY子句和HAVING子句时,其顺序是WHERE、GROUP BY和HAVING
WHERE与HAVING子句的根本区别在于作用对象不同,WHERE子句作用于基本表或视图,从中选择满足条件的元组;HAVING子句作用于组,选择满足条件的组,必须用在GROUP BY子句之后,但GROUP BY子句可以没有HAVING子句
6. 查询结果排序
当需要对查询结果排序时,应该使用ORDER BY子句
- ORDER BY子句必须出现在其他子句之后
- 排序方式可以指定,DESC为降序,ASC为升序,缺省时为升序

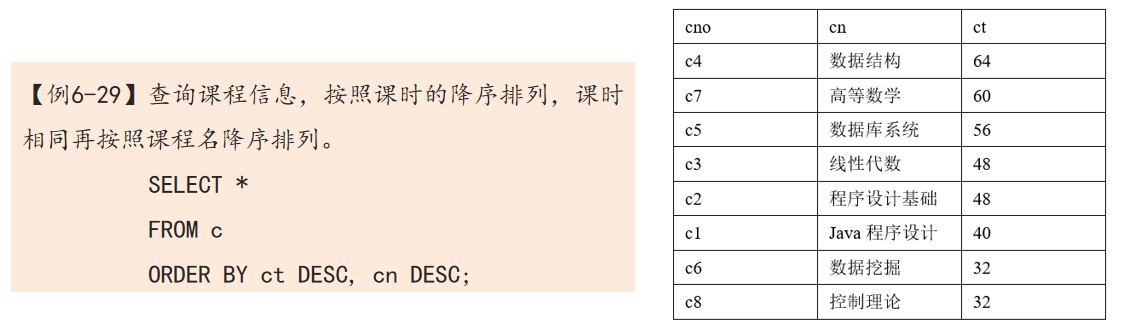
- 课时“ct“是主排序字段,课程名“cn”是次排序字段,首先按照课时降序排列,课时相同的课程再按照课程名的字典序降序排列。
7. 限制查询结果数量
- LIMIT子句用来限制查询结果的元组数量,其语法格式为:LIMIT [OFFSET,] row_count | row_count OFFSET offset
- OFFSET是非负整型常量,用于指定查询结果的第一行的偏移量,默认为0,表示查询结果的第1行,以此类推,OFFSET的值为1时,表示查询结果的第2行
- row_count是非负整型常量,用来指定查询结果的行数,如果row_count的值大于实际查询结果的行数,则返回实际行数
- row_count OFFSET后面的offset也是非负整型常量,row_count OFFSET offset表示查询结果从offset+1行开始,返回row_count行


若有收获,就点个赞吧
0 人点赞
