dpdispatcher在deepmodeling下已经公开,并欢迎大家使用和pr和提issues。
github仓库地址:https://github.com/deepmodeling/dpdispatcher
开发者们可以利用dpdispatcher,声明高性能计算作业,计算环境和计算资源,并自动完成作业生成,提交,轮询和回收的全流程。
dpdispatcher是一个python包/模块,可被其他软件集成和使用,编写自动化的工作流,也可被用作日常提交计算作业。
dpdispatcher希望能够帮助大家,让大家科学研究的过程更加自动化,并帮助大家的软件能够被更多人共享和使用。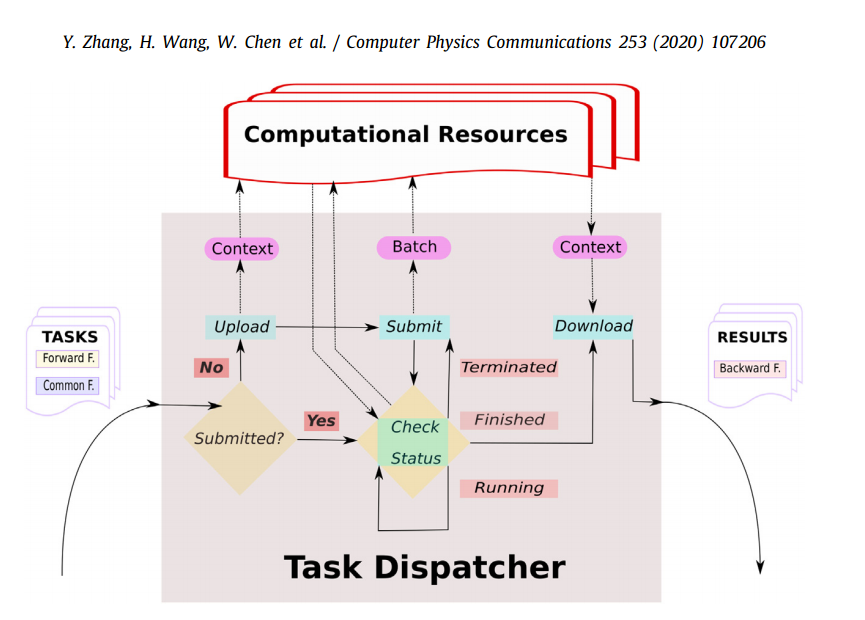
感谢张与之供图
软件功能
代替手动编写的脚本
提交高性能计算作业时,可以使用dpdispatcher可以替代原来手工的编写作业提交脚本的方式,自动生成作业提交脚本,这样在切换作业批处理系统时,就只需要修改配置文件,而避免大范围修改代码。
目前dpdispatcher支持了Slurm,PBS, LSF, DpCloudserver等系统。
自动化地完成作业
deepmodeling仓库里的rid-kit,dpgen, dpti等软件都集成了dpdispatcher,此处dpdispatcher负责向高性能计算系统提交作业,并回收。而这些软件的其他部分负责完成作业定义,文件准备,结果分析处理,等内容。
feature
作业脚本生成
各个批处理系统声明需要的计算资源的语句有所不同,比如申请一个计算节点,Slurm是#SBATCH --nodes 1,而PBS是#PBS -l select=1。软件切换批处理系统时,改写这些作业提交脚本会变得很麻烦。dpdispatcher会根据用户声明的,作业需要的计算节点数,CPU数,GPU数来自动生成作业提交脚本。
自动提交监控并回收
想要借助dpdispatcher完成一次作业定义,生成,提交的全过程,需要借助dpdispatcher提供的Machine类,定义作业批处理系统的信息,借助Resources类定义作业所需的计算资源,借助Task类,定义单个计算命令和命令所需文件,实例化一个Submission类的对象,并运行该实例的run_submission方法。 该实例在运行run_submission方法时,会完成生成作业提交脚本,文件上传,作业提交,轮询任务状态,结果下载的全流程。方法被执行完之后,会自动运行后续的python命令。
使用方式
使用时,开发者或者用户借助dpdispatcher提供的抽象,来声明计算任务,和作业提交。
dpdispatcher提供了以下抽象,提供了Task类,来定义一条计算命令,和命令所依赖的文件。
提供了Resources类,来定义计算时所需要的计算资源。
提供了Machine类,来定义计算时所用到的批处理系统,远端机器ip,工作路径等内容。目前支持了Slurm, PBS, LSF, DpCloudserver等系统.
通过构造Submission类的对象,并执行Submission.run_submission()方法,来完成作业生成,提交到回收的全流程。
这样dpdispatcher能够方便被其他软件集成。
样例代码:
from dpdispatcher import Machine, Resources, Task, Submissionmachine = Machine.load_from_json('machine.json')resources = Resources.load_from_json('resources.json')task1 = Task(command='lmp -i input.lammps', task_work_path='bct-1/', forward_files=['conf.lmp', 'input.lammps'], backward_files=['log.lammps'])task2 = Task(command='lmp -i input.lammps', task_work_path='bct-2/', forward_files=['conf.lmp', 'input.lammps'], backward_files=['log.lammps'])task3 = Task(command='lmp -i input.lammps', task_work_path='bct-3/', forward_files=['conf.lmp', 'input.lammps'], backward_files=['log.lammps'])task4 = Task(command='lmp -i input.lammps', task_work_path='bct-4/', forward_files=['conf.lmp', 'input.lammps'], backward_files=['log.lammps'])task_list = [task1, task2, task3, task4]submission = Submission(work_base='0_md/',machine=machine,resources=resources,task_list=task_list,forward_common_files=['graph.pb'],backward_common_files=[])submission.run_submission()
machine.json
{"batch_type": "Slurm","context_type": "SSHContext","local_root" : "./22_new_project/","remote_root": "/home/user123/dpdispatcher_work_dir/","remote_profile":{"hostname": "39.106.xx.xxx","username": "user123","port": 22,"timeout": 10}
resources.json
{"number_node": 1,"cpu_per_node": 4,"gpu_per_node": 1,"queue_name": "GPUV100","group_size": 5}
软件故事背景
大家在研究算法之初,会直接向超算上交任务,或者编写一些bash脚本来交任务,这样来快速验证自己的想法。算法或者某个流程work了之后,大家就会想着把这些脚本或者零散的python代码,拿出去给别人用,或者请他人在其他体系上试一下。
这时候就遇到了很大困难,其他人很难明白软件该如何使用。不太自己该怎么重复这个流程,怎么把计算作业交到自己的集群上,软件的各个参数的意义。 这很影响知识的传播,软件和方法本身的迭代。
具体到dpgen上,各个课题组想要研究自己的体系,就需要生成自己的dp势函数。
而想要把计算作业交在自己课题组的集群上,就需要用到dpdispatcher了。
dpdispatcher原本是dpgen的一个模块。后来大家开发了dpti, deepks-kit, rid-kit等一系列工作流软件,都发现自己需要用到dpdispatcher,来把作业交到各类超算上去。所以就把dpdispatcher单独抽出来,集中开发和维护了。
结语
dpdispatcher 的成长,得益于deepmodeling开源社区许多人的帮助。大家在一起交流软件的架构设计,类的设计,接口,具体实现等方方面面内容,一起把dpdispatcher打磨成一个好用的工具。
软件开发也得益于开源协同的模式。单个开发者很难了解对接的全部批处理系统,也很难事先拥有软件架构,单元测试,接口设计,文档写作,CICD,git使用和协作,软件重构等方方面面内容。而这些却是一个好用软件所需要的。
只要眼睛多,bug容易捉。大家不光能帮忙捉功能上的bug。同时冗余的设计,没必要的feature,不可行的方案,多余的系统,不一定有用的新技术。 这些架构和设计上的bug,大家同样也能摆事实,讲道理,讨论得到个结果。
而最让本文作者难忘的是,是deepmodeling里的开发者。大家在开发过程中,不断追求高质量软件,务实解决问题。

若有收获,就点个赞吧
0 人点赞
