导语
K8S网络系统是K8S的核心部分,为了便于理解该系统,本文会先介绍下K8S的网络模型,以便理解K8S网络规范;然后以Flannel,Calico为例简要介绍下实现了该模型的开源社区网络方案,并说明TKE为什么没有采用这些方案;然后会从数据面和控制面重点介绍TKE的网络方案;接着会介绍下K8S的负载均衡机制和两种负载均衡实现(iptables,IPVS)的对比;接着会科普下K8S的服务发现机制和以应用为中心的网络策略;最后会介绍下TKE的新一代网络方案和下一步计划。
K8S网络模型介绍
基本要求
- 节点上的 Pod 可以不通过 NAT 和所有 Pod 通信
- 节点上的代理(比如:kubelet) 可以和本节点上的所有Pod通信
- HostNetwork 类型的 Pod 可以不通过 NAT 和所有 Pod 通信(仅针对支持 HostNetwork Pod 的平台:Linux)
网络模型定义K8S网络规范,K8S Service和NetworkPolicy这些概念构建在该模型之上。
该模型下每个Pod都可以被视为虚拟机/物理机。Pod中的容器可以被视为虚拟机/物理机中的进程,便于应用从虚拟机/物理机迁移到Pod。
社区网络方案
额外封包
Flannel-VXLAN/Calico-IPIP
控制面介绍
一个节点关联一个PodCIDR,容器网络和节点网络分属两个网络平面
数据面介绍
Host1:PodCidr 10.10.1.0/24
Host2:PodCidr 10.10.2.0/24
Host1容器A访问Host2容器A,数据包从容器A发出,达到br0,进行路由查找,命中相应规则,转发到vtep0,vtep0是一个vxlan设备,先进行内层vxlan报文封装,依据下一跳找到mac地址,完成内层vxlan报文封装,接着依据下一跳mac地址从fdb表项找到可路由的外层目的IP,完成外层vxlan报文封装,最终由eth0发出,路由到Host2,Host2收包,解封vxlan,转发到容器A,回包类似。
为什么容器服务没有采用该方案
- 该方案可以跑在云上,不过性能损失严重(吞吐方面,全局路由要比VxLAN高40%,时延要小5%~10%),具体可以参考文章 https://cloud.tencent.com/developer/article/1006675
- 因为额外封装,网络问题定位较困难,比较难trace
直接路由
Calico-BGP
控制面介绍
一个节点关联一个PodCIDR,容器网络和节点网络在同一个网络平面数据面介绍

每一个节点都会有一个BGP client进行BGP路由的维护,跨节点Pod互访,数据包从节点发出,到达交换机后,由交换机转发相应的节点完成网络链路访问为什么容器服务没有采用该方案
利用BGP来联通容器网络,需要节点上层交换机感知容器路由,并支持BGP协议,腾讯云VPC不支持该方案(黑石1.0除外)
容器服务网络方案
基于性能考虑,容器服务采用了直接路由方案,节点间数据包的路由由VPC保证,节点内会配置网桥/策略路由实现数据包能正确发送给容器或让容器发出的数据包由节点正确的网卡发出。
全局路由
背景
- 基于社区控制面方案,简单可靠
- Pod销毁重建比较频繁,Pod底层网络配置好之后,节点内Pod网络配置可以在节点内闭环,保证Pod快速启动/销毁
- 一个节点固定关联一个容器小网段,用户不需要也不应该关心容器使用的IP,符合云原生理念

数据面
互通

数据包从Pod1发出,到达cbr0,走默认路由转发到eth0,VPC母鸡根据全局路由表项,转发到Node2,eth0收包,查找路由转发到cbr0,经过网桥二层转发到Pod2,回包类似。
访问外网

控制面
节点网段分配管理


Pod IP的分配管理
共享网卡
背景
- 在容器化的进程中,有些用户的业务系统(配置管理,监控,鉴权)强依赖于IP,改造成本高,需要实现Pod重建后可以固定IP(全局路由方案一个节点上的容器IP是固定的,无法实现Pod迁移后IP不变)
- 全局路由方案容器网段位于VPC CIDR之外,不能直接使用云上资源(CLB,NAT,EIP等),只能依赖于节点做中转。为了实现全局路由方案跨地域,跨IDC容器的互访需要各云网关额外适配,支持成本高,为此需要实现Pod直接使用VPC内IP。
数据面
互通

数据包从Pod1发出,到达veth0,查找策略路由table 1,经由eth1发出,VPC母机将数据包转发到Node2,eth1收包,查找策略路由转发到veth0,交由Pod2,回包类似。
访问外网
同全局路由,不过因为策略路由方案Pod使用的VPC IP,故可以支持使用 NAT,EIP
控制面
集群侧组件

中控组件 ipamd 负责监听节点的增加/删除事件,进行弹性网卡的创建和IP分配,并将弹性网卡和IP信息存储到CRD-NodeENIConfig中。
节点侧组件

eni-agent会监听CRD-NodeENIConfig的创建/更新事件,同步节点内IPAM信息,Pod创建时,kubelet会调用CNI,然后通过 GRPC 请求到 eni-agent,eni-agent负责节点内Pod IPAM,tke-route-eni 负责节点和容器网络协议栈的配置。
方案对比
| 方案 | 控制面复杂程度 | 容器启动速度 | 固定IP | CLB直通容器 | 互通成本 |
|---|---|---|---|---|---|
| 全局路由 | 简单 | 快(节点内闭环) | 不支持 | 不支持 | 需各网关单独适配(对等连接,用户IDC,云联网) |
| 共享网卡 | 复杂 | 慢(联动弹性网卡接口) | 支持 | 支持 | 无需单独考虑 |
K8S负载均衡介绍
负载均衡要解决的问题
虽然每个Pod都有一个独立的IP,但是为了实现业务可以水平扩展,大多数服务都会支持多副本。另外Pod的生命周期比较短,一个服务中Pod IP列表是不断变化的,所以服务访问的时候使用Pod IP是不现实的。为此K8S引入了Service来实现了多副本的统一接入和负载均衡。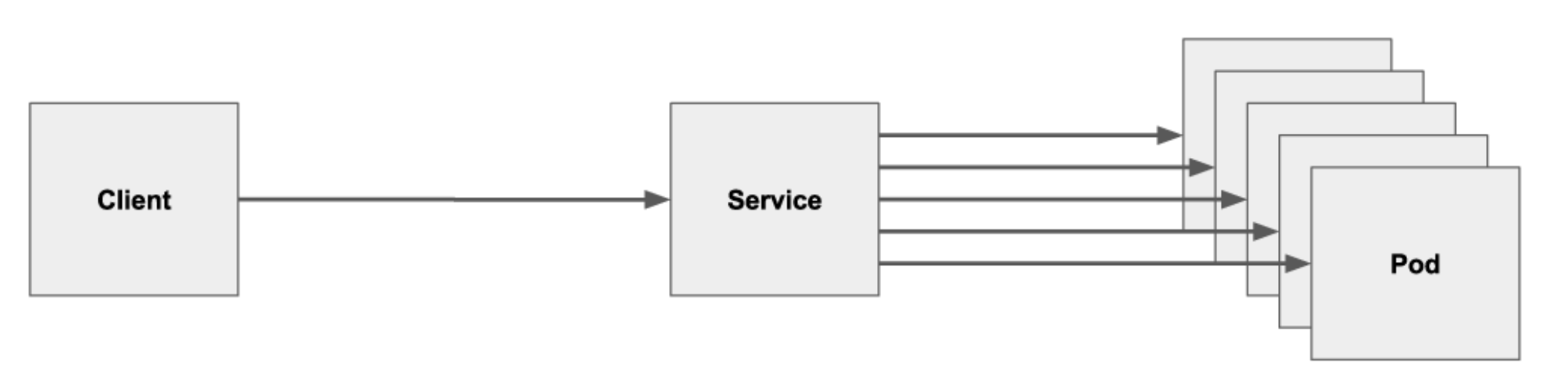
Service概念介绍

service是一个抽象的概念,是K8S用于实现一组Pod作为网络服务的抽象访问,一组Pod的集合通常是用标签选择出来的,service在形式上暴露为一个虚拟的IP,kube-proxy利用iptables/IPVS实现针对该虚拟IP的访问会负载均衡到该组Pod集合。
service类别
ClusterIP:集群内负载均衡
NodePort:基于节点端口实现的集群外负载均衡
LoadBalancer:基于外部负载均衡器实现的集群外负载均衡
ClusterIP Service
集群内负载均衡,基于iptables DNAT规则实现service负载均衡到后端Pod
NodePort Service
基于节点端口实现的集群外负载均衡,是LoadBalancer Service的实现基础,除了做DNAT,还会做SNAT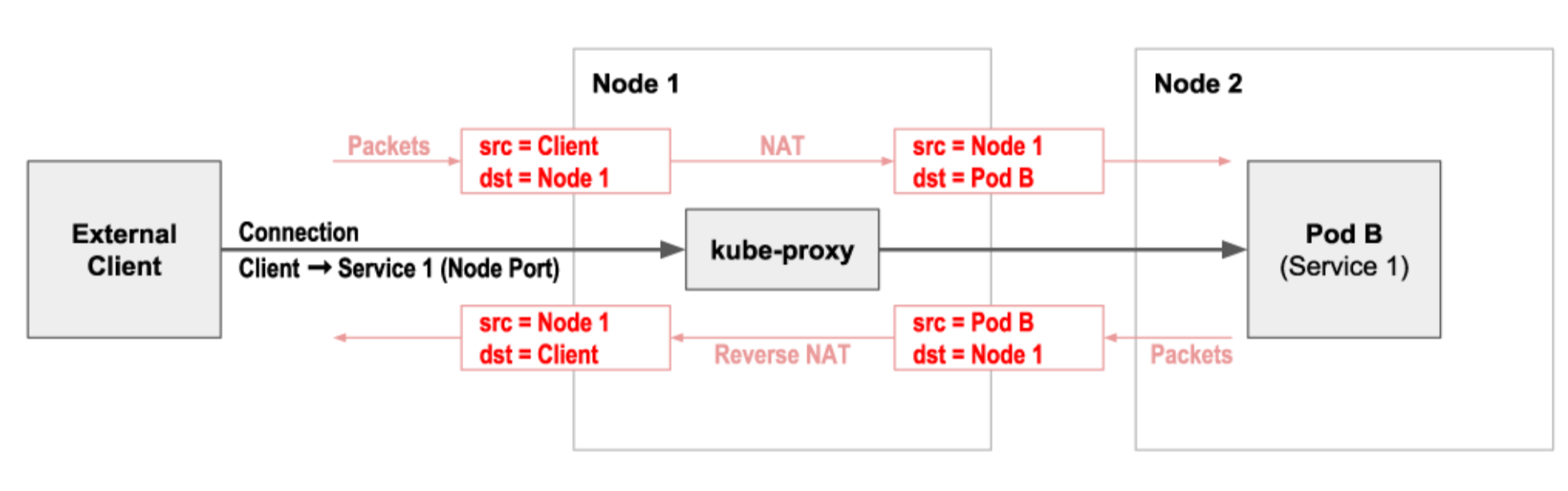
LoadBalancer Service
基于外部负载均衡器和NodePort实现的集群外负载均衡,需要走两套负载均衡的逻辑
容器服务上负责LoadBalancer Service实现的组件—-service-controller
service-controller
自研的service控制器组件,监听service的增删改事件,对接CLB的接口,创建CLB并绑定到NodePort
LB直通Pod
不再经过NodePort,由LB直接转发给Pod,性能上更优;统一的负载均衡视图,不会因为二次负载均衡造成负载不均
IPV6支持(NAT64)
Kube-Proxy
运行在节点上的网络代理,作为K8S Service的控制面组件,负责实现ClusterIP/NodePort Service到iptables/IPVS规则的映射
iptables
IPVS
iptables VS. IPVS
这里引用了外部结论,为了比较两种方案的性能差异,主要对比了RTT时延和CPU消耗
RTT时延

- 长链接情况下iptables/IPVS方案RTT时延没有明显差别
- Service的数目超过1000后,短连接RTT时延的开始显现出差别
对于iptables和IPVS来说,RTT时延的差别主要和新建连接有关,和请求的数目没有关系。因为一个数据包如果命中conntrack规则后,无需走iptables/IPVS规则。
CPU消耗

- Service的数目超过1000后,CPU消耗开始显现出差别
- 在Service的数目达到10000(100000个Pod)后,iptables单核CPU消耗在35%,IPVS在8%
CPU消耗的具体原因
- 默认情况下kube-proxy每隔30s进行iptables/IPVS规则的同步,老内核下iptables的同步会更消耗CPU
- iptables模式下,新建连接需要O(N)的时间复杂度,而IPVS只需要O(1)的时间复杂度
选择 iptables 还是 IPVS
- 当service数目在1000+,IPVS在性能上会更好。如果服务中大多是长链接,并且内核也较新,性能上的差异不会很大,但是如果服务中大多是短链接,并且内核也较老,可以选择IPVS模式
- IPVS支持更多负载均衡策略,如果有这类需求,选择IPVS模式
如果不确定是否应该选择IPVS,可以继续使用iptables,因为它在生产中进行了更多的优化,并且是默认设置
K8S服务发现
服务发现要解决的问题
使用域名而不是IP实现服务的访问,可读性高,用户可以自定义访问服务名
服务注册

服务名由Service的名称和命名空间组成,DNS中控服务组件(KubeDNS/CoreDNS)List-Watch Service/Pod/Endpoint的变化将服务名和IP的对应关系同步到内存服务发现

K8S基于DNS实现了服务发现,DNS中控服务组件以Service的形式暴露在集群,业务Pod使用DNS服务组件的Service作为NameServer,发起的DNS请求会经由Service负载均衡到中控服务组件,中控服务组件处理DNS请求。
部署NodeLocalDNS组件后,NodeLocalDNS会作为缓存层,该节点上业务Pod发起的DNS会先经过NodeLocalDNS组件,如果命中缓存,直接返回给业务Pod。否则由NodeLocalDNS组件发起到中控服务组件的DNS请求。NodeLocalDNS解决的问题
使用节点级别的缓存,降低时延,减少中控DNS组件压力
- 跳过iptables DNAT和连接跟踪减少 conntrack竞争(https://github.com/kubernetes/kubernetes/issues/56903)
- 从本地缓存代理到中控DNS组件的连接升级为TCP,降低因UDP丢包造成的延迟
K8S NetworkPolicy
以应用为中心的网络概念,允许用户指定Pod和其他网络实体(某些命名空间的Pod,IPBlock)的访问策略
功能举例

该 NetworkPolicy 作用于 default 命名空间下 label 包含 app: test-service 的 Pod 集合,允许 default 命名空间下 label 包含 app: client-green Pod 访问,拒绝其他访问。
支持的NetworkPolicy插件
新一代网络方案
随着容器技术的发展成熟,越来越多的组件迁移到容器,在技术迁移过程中,数据库,游戏,AI这些组件对容器网络性能(时延,吞吐,稳定性)提出了更高的要求。为了得到更优的时延和吞吐表现,各大云厂商都在致力于缩短节点内容器的网络访问链路,让数据包能尽可能快地转发到容器网卡。
数据面
互通

数据包从Pod 10.0.0.2发出,不再经过节点默认网络协议栈,由VPC母机将数据包转发 Pod 10.0.0.10,回包类似。
访问外网
性能表现
基础网络性能
极大缩短了容器访问链路,缩短了访问时延,并使PPS 可以达到整机上限
业务网络性能
为了得到不同网络方案下的QPS,这里控制变量,让不同网络方案的nginx Pod运行在同一节点,使用 wrk 分别压测不同Pod,并让服务端节点的 cpu 接近 100%

控制面
节点弹性网卡分配管理
为了兼顾Pod启动速度并缓解对VPC弹性网卡接口的压力,实现了网卡池,可以将空闲的网卡维持在一定的水位
集群内负载均衡
由于不再经过节点网络协议栈,传统基于 iptables 和 IPVS 的 ClusterIP service 访问方案不能直接适用于该方案。
为了实现该方案下 Pod 可以直接访问 ClusterIP service,容器服务实现了 share-NS IPVS 方案,使得在容器网络命名空间下也可以访问到节点网络协议栈的 IPVS 规则。
其他功能
- 支持Pod绑定EIP/NAT,不再依赖节点的外网访问能力,无须做SNAT,可以满足直播、游戏、视频会议等高并发,高带宽外网访问场景
- 支持Pod绑定安全组,实现Pod级别的安全隔离
- 支持基于Pod名称的固定IP,Pod重新调度后仍能保证IP不变
- 支持CLB直通Pod,不再经过NodePort转发,提升转发性能并拥有统一的负载均衡视图
参考文献
https://kubernetes.io/zh/docs/concepts/cluster-administration/networking/
https://aijishu.com/a/1060000000107387
https://www.tigera.io/blog/comparing-kube-proxy-modes-iptables-or-ipvs/
https://kubernetes.io/zh/docs/tasks/administer-cluster/nodelocaldns/
https://kubernetes.io/docs/concepts/services-networking/network-policies/
https://cloud.google.com/kubernetes-engine/docs/how-to/network-policy-logging
https://blog.csdn.net/one_clouder/article/details/103509487
https://cloud.tencent.com/developer/article/1006675

若有收获,就点个赞吧
0 人点赞
