#使用MySQL
创建表
— 新建表
-- 使用if not exists可以避免MySQL抛出异常(只抛出警告)create table if not exists `database`.`tableName` (-- unsigned 无符号`id` int unsigned auto_increment primary key,`first_name` varchar(20)) engine=InnoDB;
— 克隆表结构
create table new_customers like customers;
— 查看创建语句
show create table tableName;
— 查看表结构
desc tableName;
插入、更新和删除行
— 插入行
-- 使用ignore可以避免唯一约束和主键约束冲突时抛出异常(仅抛出警告)且忽略冲突的数据,整个语句将会执行成功insert ignore into `database`.`tableName`(id, first_name, last_name, country)values(1, 'mike', 'chiristensen', 'USA'),(2, 'andy', 'hollands', 'Australia'),(3, 'ravi', 'vedantam', 'India'),(4, 'rajiv', 'perera', 'Sri Lanka');
— 更新行
update tableName set first_name = 'Dejavu', country='UK' where id = 4;
— 删除行
delete from tableName where id = 4 and first_name = 'Dejavu';
— REPLACE、INSERT、ON DUPLICATE KEY UPDATE
REPLACE 关键字
-- 示例SQLreplace into customers values (1, 'mike', 'hiristensen', 'America');-- 如果主键冲突,则replace会删除原行并插入新hang-- 如果主键不冲突,则等同于insert
INSERRT ON DUPLICATE KEY UPDATE
insert into customers values(1, 'Jackie', 'Ma', 'USA') on duplicate key update location = 'CN';-- 如果主键不冲突,则视作insert语句-- 如果主键冲突,则执行后半句update语句
— TRUNCATING TABLE
-- 删除表的所有记录,但保留表结构truncate table customers;
加载数据
mysql -u username -p < sql.sql
查询数据
— IN 多值匹配
select count(*) from employees where last_name in ('Christ', 'Lamba');
— BETWEEN AND 范围匹配
select count(*) from employees where hire_date between '1986-12-01' and '1986-12-31';
— NOT 否定结果
select count(*) from employees where hire_date not between '1986-12-01' and '1986-12-31';
— LIKE 简单模式匹配
-- 前缀匹配select count(*) from employees where first_name like 'christ%';-- 前后缀匹配select count(*) from employees where first_name like 'christ%ed';-- 中位匹配select count(*) from employees where first_name like '%sri%';-- 后缀匹配select count(*) from employees where first_name like '%er';-- `_`的使用(占位符,代表任意匹配一个字符)select count(*) from employees where first_name like '__ka%';
— RLIKE REGEXP
-- 前缀匹配select count(*) from employees where first_name rlike '^christ';-- 后缀匹配select count(*) from employees where last_name regexp 'ba$';-- 规则匹配select count(*) from emplouees where last_name not regexp '[aeiou]';
— LIMIT OFFSET
-- limit 限制返回条数 offset起始位置select * from employees where hire_date < '1986-01-01' limit 10 offset 0;
排序
— ORDER BY
-- asc按照条件升序 desc按照条件降序select emp_no from salaries order by salary desc limit 5;-- 数字代表select 子句中查询的第几个列, 此处2指代的就是salaryselect emp_no, salary from salaries order by 2 limit 5;
聚合函数
— COUNT()
-- group by 1 和order by 1同理select gender, count(*) count from employees group by 1;
— SUM()
select year(from_date) `year`, sum(salary) sum from salaries group by year order by sum desc;
— AVERAGE()
select empno, avg(salary) avg from salaries group by emp_no order by avg desc limit 10;
— DISTINCT
-- 去重select distinct title from titles;
— HAVING 过滤
select emp_no, avg(salary) avg from salaries group by emp_no having avg > 140000 order by avg desc;
创建用户
— 基本语句
-- `username`:用户名-- `localhost`:IP地址 此处可以限制对IP范围的访问例如10.148.%.% | 未指定IP的时候,视作%,即任意主机-- `password`:密码-- `mysql_native_pass`: 使用默认身份验证,其他选项[sha256_password、LDAP、Kerberos]-- `MAX_QUERIES_PER_HOUR`:用户每小时内执行的最大查询数为500-- `MAX_UPDATES_PER_HOUR`:用户每小时内执行的最大更新次数为100create userif not exists `username`@`localhost`identitfied with mysql_native_pass by `password`with MAX_QUERIES_PER_HOUR 500 MAX_UPDATES_PER_HOUR 100;-- 以这种方式创建用户,必须明文形式输入密码,这些密码会记录在命令历史记录文件$HOME/.mysql_history中
授权和取消授权
— 授权
-- select 所授予的权限值[只读select 插入insert 只写write 全部权限all 授权权限grant option]grant select on database.tablename to `username`@`localhost`;-- 授权的同时新建用户(未来版本将移除)grant insert on database.tablename to `username`@`localhost` identified by `password`;-- 限制查询的表的列grant select(first_name, last_name) on database.tablename to `username`@`localhost`;
— 检查授权
show grants for `username`@`localhost`;
— 撤销权限
revoke delete on database.tablename from `username`@`localhost`;
— 修改mysql.user表
- 如果通过
grant、revoke、set password、rename user等账户管理语句间接修改授权表,MySQL服务器会通知进行变更,且吉利将授权表加载到内容中。 - 如果通过
insert、update、delete这些语句直接修改授权表,除非之后重启服务器或者重新加载表以外,不会影响权限检查。 可以通过执行
flush privileges来完成grant表的重新加载-- 修改用户的Hostupdate mysql.user set host = '%' where user = 'username';-- 刷新权限表flush privileges;
— 设置用户密码有效期
default_password_lifetime:所有账户密码过期日期,默认关闭。-- 创建一个用户,并为其设置为密码已过期create user `username`@`%` indentified by 'password' password expire;-- 用户首次登陆使用设置的密码登陆,登录后系统提示需要使用alter user语句进行密码的修改alter user `username`@`%` indentified by 'nwe_password';-- 手动设置过期用户alter user `username`@`%` password expire;-- 要求用户每90天更改一次密码alter user `username`@`%` password expire interval 90 day;
— 锁定用户
-- 通过alter语句锁定 也可以在创建用户时锁定alter user `username`@`%` account lock;-- 用户登录的时候会提示,该账户已被锁定的报错消息
— 解锁用户
alter user `username`@`%` account unlock;
— 为用户创建角色
-- 创建角色create role `role_name`, `role_name1`, `role_name2`;-- 角色授权grant select on `database`.tablename to `role_name`;-- 分配角色grant `role_name` to `username`@`localhost`;
查询数据并保存到文件和表中
— 保存到文件 SELECT INTO OUTFILE
在Ubuntu系统中,默认情况下MySQL不允许写入文件,需要在配置文件中设置
secure_file_priv并重启MySQL在CentOS、RedHat系统中,
secure_file_priv被设置为/var/lib/mysql-files即所有文件将被保存在此目录中sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf#添加 secure_file_priv = /var/lib/mysqlsudo systemctl restart mysql
-- 将查询结果保存为CSV格式select first_name, last_nameinto outfile 'result.csv'fields terminated by ',' optionally enclosed by '"'lines terminated by '\n'from employeeswhere hire_date < '1986-01-01'limit 10;
— 保存到表
create table titles_only as select distinct title from titles;insert into titles_only select distinct title from titles;
加载数据到表
— LOAD DATA INFILE
-- result.csv:可以指定为完整路径或相对路径,相对路径将被解析为相对于客户机程序启动的位置load data infile 'result.csv' into table employees fields terminated by ','optionally enclosed by '"'lines terminated by '\n';-- ignore 可以忽略文件开头包含的一些行load data infile 'result.csv' into table employees fields terminated by ','optionally enclosed by '"'lines terminated by '\n'ingore 1 lines;-- replace 或 ignore可以用来处理重复的行load data infile 'result.csv' replace into tableemployees fields terminated by ',' optionally enclosed by '"' linesterminated by '\n';load data infile 'result.csv' ignore into tableemployees fields terminated by ',' optionally enclosed by '"' linesterminated by '\n';--load data local infile 'result.csv' ignore into tableemployees fields terminated by ',' optionally enclosed by '"' linesterminated by '\n';
关联表
— JOIN
select emp.* from employees empjoin dept_manager dept_mgron emp.emp_no = dept_mgr.emp_no and emp.emp_no = 110022join departments depton dept_mgr.dept_no = dept.dept_no;
— 子查询
select first_name, last_name from employees where emp_no in(select emp_no from titles where title = 'Senior Engineer' and form_date = '1986-06-26');
— 查找表之间不匹配的行
-- not inselect * from employees where emp_no not in (select emp_no from empoyees_list);-- outer joinselect * from employees left outer join employees_list on employees.emp_no = employees_list.emp_no where employees_list.emp_no is null;-- outer join 会为两表间不匹配的行创建null列,如果是 A left join B 则为在B表中所有与A表不匹配的行创建null列-- 如果是 A right join B 则为在A表中所有与B表不匹配的行创建null列-- 同样也可以使用outer join的特性来寻找匹配的行select * from employees left outer join employees_list on employees.emp_no = employees_list.emp_no where employees_list.emp_no is not null;
存储过程
存储的函数
function和过程procedure都统称为存储例程routine- 创建存储过程,需要具有
create toutine权限 - 存储函数具有返回值
- 存储过程没有返回值
- 存储例程代码都写在
begin和end块之间 - 存储函数可以直接在
select语句中调用 - 可以使用
call语句调用 存储过程 因为存储例程中的语句应以分隔符
;结尾,因此需要更改MySQL的分隔符,以免MySQL不会用正常语句解释存储例程中的SQL语句。创建结束后,可以将分隔符修改回默认值— 基本语句
-- 在创建前,如果存在任何相同名称的存储过程,则删除已存在的存储过程drop procedure if exists create_employee;-- 将分隔符标识符修改为$$delimiter $$-- IN 指定作为入参的变量 INOUT 指定输出的变量create procedure create_employee(out new_emp_no int,in first_name varchar(20),in last_name varchar(20),in gender enum ('M', 'F'),in birth_date date,in emp_dept_name varchar(40),in title varchar(50))begin-- 为emp_dept_no和salary声明变量declare emp_dept_no char(4);declare salary int default 60000;-- 查询employee表的emp_no的最大值,赋值给变量new_emp_noselect max(emp_no) into new_emp_no from employees;-- 增加new_emp_noset new_emp_no = new_emp_no + 1;-- 插入数据到employees表中insert into employees values (new_emp_no, birth_date, first_name, last_name, gender, curdate());-- 找到dept_name对应的dept_noselect emp_dept_name;select dept_no into emp_dept_no from departments where dept_name = emp_dept_name;select emp_dept_no;-- 插入dept_empinsert into dept_emp values (new_emp_no, emp_dept_no, curdate(), '9999-01-01');-- 插入titlesinsert into titles values (new_emp_no, title, curdate(), '9999-01-01');-- 以title为条件查询的薪水if title = 'Staff'thenset salary = 100000;elseif title = 'Senior Staff'thenset salary = 120000;end if;-- 插入salariesinsert into salaries values (new_emp_no, salary, curdate(), '9999-01-01');end$$delimiter ;
延展
使用存储过程也可以增强数据库的安全性,因为用户需要拥有针对存储过程的
execute权限才能执行它。
根据存储例程的定义:definer:通过definer子句指定存储例程的创建者,如果没有指定,将获取当前用户。sql security:通过sql security子句指定存储例程的执行上下文。它可以是definer或者invokerdefiner:即使仅拥有execute权限的用户也可以调用并获取存储例程的输出,而不管是否对基础表有操作权限invoker:安全上下文被切换到调用存储例程的用户,这种情况下调用者应该可以访问基础表函数
— 基本语句
drop function if exists get_sal_level;delimiter $$create function get_sal_level(emp int) returns varchar(10)deterministicbegindeclare sal_level varchar(10);declare avg_sal float;select avg(salary) into avg_sal from salaries where emp_no = emp;if avg_sal < 50000 thenset sal_level = 'BRONZE';elseif (avg_sal >= 50000 and avg_sal < 70000) thenset sal_level = 'SILVER';elseif (avg_sal >= 70000 and avg_sal < 90000) thenset sal_level = 'GOLD';elseif (avg_sal >= 90000) thenset sal_level = 'PLATINUM';elseset sal_level = 'NOT FOUND';end if;return (sal_level);end$$delimiter ;
— 查看存储的函数
show function status;
— 检查现有函数定义
show create function functionName;
触发器
触发事件:
insert:无论何时通过insert、replace、load data语句插入新行,都会激活insert触发事件update:通过update语句激活update触发事件delete:通过delete或replace语句激活delete事件— 基本语句
```sql — before insert drop trigger if exists salary_round; delimiter $$ create trigger salary_round before insert on salaries for each row begin set new.salary = round(new.salary); end $$ delimiter ;
<a name="hR44M"></a>## 视图视图隐藏了SQL的复杂性,并且它还提供了额外的安全性。- 简单视图支持`update`,简单视图指的是没有子查询、`join`、`group by`、`union`的视图- 当给符合条件的视图进行`insert`的时候,VIEW算法:- `merge`:MySQL将输入查询和视图定义合并到一个查询中,然后执行组合查询。仅允许在简单视图上使用此算法- `temptable`:MySQL将结果存储在临时表中,<a name="clA1M"></a>### -- 基本语句```sql-- 创建视图create algorithm = undefined definer = `root`@`localhost` sql security definer view salary_viewas(select emp_no, salaryfrom salarieswhere from_date > '2002-01-01');-- 查看视图select * from salary_view;-- 列出所有视图show full tables where table_type like 'view';-- 查看视图定义show create view salary_view;
— 延展
create table view_table(id int primary key auto_increment,name varchar(20) default 'default',gender tinyint default 0);create table view_table2(id int primary key auto_increment,name varchar(20),gender tinyint);insert into view_tablevalues (1, '1', 1),(2, '2', 1),(3, '3', 1);insert into view_table2values (1, '1', 1),(2, '2', 1),(3, '3', 1);create view view_1 as(select *from view_table);create view view_2 as(select *from view_table2);create view view_3 as(select id, namefrom view_table);create view view_4 as(select id, namefrom view_table2);#执行失败 - 语法错误,视图列和输入列未完全匹配insert into view_1values (4);#执行成功 - 语法正确且是简单视图insert into view_1values (4, '4', 1);#执行失败 - 语法错误,视图列和输入列未完全匹配insert into view_2values (4);#执行成功 - 语法正确且是简单视图insert into view_2values (4, '4', 1);#执行成功 - 语法正确且是简单视图 且关联表带有默认值insert into view_3values (5, '5');#执行成功 - 语法正确且是简单视图 且关联表带有默认值insert into view_3 (id)values (6);#执行成功 - 语法正确且是简单视图 且关联表带有默认值insert into view_4values (5, '5');#执行失败 - 语法正确但关联表不带有默认值insert into view_4(id) value (6);
事件
MySQL的EVENTS是用来处理计划任务的。MySQL使用事件调度线程的特殊线程来执行所有预定事件。默认情况下,事件调度线程是未启用版本低于8.0.3的状态,如要启动它,执行以下命令:
set global event_scheduler = on;
所有存储的程序和视图都有一个DEFINER,如果未指定则创建该对象的用户将被选择为DEFINER。
存储例程和视图具有值为DEFINER和INVOKER的SQL SECURITY特性,来指定对象是在definer或invoker上下文中执行。触发器和时间没有SQL SECURITY特性,并且始终在definer上下文中执行。服务器会根据需要自动调用这些对象,因此不存在调用用户。
— 基本语句
-- 创建事件dropevent if exists purge_salary_audit;delimiter $$create event if not exists purge_salary_auditon scheduleevery 1 weekstarts current_datedo begindeletefrom salary_auditwhere date_modified < date_add(curdate(), interval -7 day);end $$delimiter ;-- 检查事件show events;-- 检查事件定义show create event evnetName;-- 启用/禁用事件alter event eventName enable;alter evnet eventName disabled;
获取有关数据库的表和信息
在数据库列表中有一个information_schema数据库。它是由所有数据库对象的源数据组成的视图集合,可以连接到它并浏览所有表。information_schema查询作为数据字典表的视图来实现,它具有两种类型的元数据。
- 静态表元数据:
table_schema、table_name、table_type和engine。这些统计信息将直接从数据字典中读取。 - 动态表元数据:
auto_increment、avg_row_length和data_free。动态元数据会频繁更改。在很多情况下,动态元数据在一些需要精确计算的情况下也会产生一些开销,并且准确性可能对常规查询不会有好处。考虑到data_free统计量的情况,缓存值通常足够了。
在MySQL8.0中,动态表元数据将默认被缓存。这可以通过information_schema_stats设置进行配置,并且可以更改为set @@ global.information_schema_stats = 'latest',以便始终可以直接从存储引擎中检索动态信息(代价是略长的查询时间)。
作为替代方案,用户也可以在表上执行analyze table来更新缓存的动态统计信息。
大多数表具有引用数据库名称的table_schema列和引用表名称的table_name列。
— 基本语句
use information_schema;show tables;
— TABLES表
TABLES表包含有关表的所有信息,例如那个数据库属于TABLE_SCHEMA,以及行数TABLE_ROW、ENGINE、DATA_LENGTH、INDEX_LENGTH、DATA_FREE。
-- 展示信息desc information_schema.tables;--select sum(data_length) / 1024 / 1024 data_size_mb,sum(index_length) / 1024 / 1024 index_size_mb,sum(data_free) / 1024 / 1024 data_free_mbfrom information_schema.tableswhere table_schema = 'employees';
— COLUMNS表
COLUMNS表列出了每个表的所有列及其定义。
select * from columns where table_name = 'employees';
— FILES表
MySQL将InnoDB数据存储在字典中的目录内的.idb文件中。如要获取这些文件的更多信息,可以查询FILES表:
select *from information_schema.fileswhere file_name like './employees/employees.ibd';-- 应关注data_free,它表示未分配的数据段,以及由于碎片而在数据段内部空闲的数据段。-- 在重建表时,可以释放data_free中显示的字节
— INNODB_TABLESTATS表
INNODB_TABLESTATS表提供了索引大小和近似的行数。
select *from information_schema.innodb_tablestatswhere name = 'employees/employees';
— PROCESSLIST视图
PROCESSLIST视图是最常用的视图之一,它列出了服务器上运行的所有查询。
select *from information_schema.processlist;
使用MySQL-进阶版
使用JSON
从MySQL5.7开始,MySQL支持了JSON数据类型。
JSON文档以二进制格式存储,它提供以下功能:
- 对文档元素的快速读取访问
- 当服务器再次读取JSON文档时,不需要重新解析文本获取该值
通过键或数组直接查找子对象或嵌套值,而不需要读取文档中的所有值
— 基本语句
-- 创建表create table `json_table`(id int primary key auto_increment,value json);-- 插入INSERT INTO local_database.`json_table` (id, value)VALUES (1, '{"object": {"age": 18,"name": "J`Han"}}');-- 查询 '$.object'表示起初对象 即根对象 name列的数据类型是json name_的数据类型是longtext(纯数字也会处理为longtext)select id, value, value -> '$.object.name' name, value ->> '$.object.name' name_from `json_table`;
— JSON函数
-- json_pretty 使JSON已读化展示select id, json_pretty(value)from `json_table`;-- col->>path 直接访问JSON属性select *from `json_table`where value ->> '$.object.name' = 'J`Han';-- json_contains_path(value, option, path...) value为需要检查的列, option有两个可选项:'one' 至少包含一个|'all' 必须包含全部-- path... 为可变参,可以为一个,可以为多个, 格式为json属性访问格式-- 返回值为1或0,表示是否找到了符合条件的路径select json_contains_path(value, 'one', '$.object', '$.object.name');-- json_set() 修改 | 修改的同时新增update `json_table`set value = json_set(value, '$.object.name', 'J.Han')where id = 1;update `json_table`set value = json_set(value, '$.object.name', 'J.Han', '$.object.gender', 'M')where id = 1;-- json_insert() 新增update `json_table`set value = json_insert(value, '$.object.address', 'SH')where id = 1;-- json_replace() 修改update `json_table`set value = json_replace(value, '$.object.name', 'Jay.Han', '$.object.address', 'CQ')where id = 1;-- json_remove() 删除update `json_table`set value = json_remove(value, '$.object.address', '$.object.gender')where id = 1;-- json_keys() 获取Json文档中所有的key 仅会返回当层的keyselect json_keys(value -> '$.object')from `json_table`;-- json_length() 获取Json文档中元素数 仅会返回当层的元素数select json_length(value -> '$.object')from `json_table`;
公用表表达式
MySQL8支持公用表表达式,包括非递归和递归两种。
公用表表达式允许使用命名的临时结果集,这是通过允许在SELECT语句和某些其他语句前面使用WITH子句来实现的。不能再同一查询中两次引用派生表,如果多次使用派生表,查询会根据派生表的引用次数计算两次或者多次,这会引发严重的性能问题。使用CTE后,子查询只会计算一次。
非递归CTE
CTE与派生表类似,但是它的声明会放在查询块之前,而不是在
FROM子句中。
派生查询不能引用其他派生查询,但是CTE可以引用其他CTE。-- 派生表语法select * from (subquery) as derived, t1 ...-- CTE语法with derived as (subquery) select ... from derived, t1 ...
递归CTE
递归CTE是一种特殊的CTE,其子查询会引用自己的名字。
WITH子句必须以WITH RECURSIVE开头。递归CTE子查询包括两部分:seed查询和recursive查询,由UNION [ALL]或UNION DISTINCT分隔。seed:select被执行一次以创建初始数据子集recursive:select被重复执行以返回数据的自己,直到获得完整的数据集。当迭代不会生成任何新行时,递归会停止。这对挖掘层次结构(父-子,部分-子部分)非常有用-- seedwith recursive cte as(select * from table)select * from cte;-- recursivewith recursive cte (迭代字段) as(select * from cte, table)select * from cte;
-- 表结构create table employees_mgr(id int primary key not null,name varchar(100) not null,manager_id int null,index (manager_id),foreign key (manager_id) references employees_mgr (id));-- 示例数据insert into employees_mgrvalues (333, 'yasmina', null),(198, 'john', 333),(692, 'tarek', 333),(29, 'pedro', 198),(2610, 'sarah', 29),(72, 'pierre', 29),(123, 'adil', 692);-- 查询语句with recursive employee_paths (id, name, path) as(select id, name, cast(id as char(200))from employees_mgrwhere manager_id is nullunion allselect e.id, e.name, concat(ep.path, ',', e.id)from employee_paths as epjoin employees_mgr as eon ep.id = e.manager_id)select *from employee_pathsorder by path;
生成列
生成列
Generated Column的值是根据列定义中包含的表达式计算得出的。生成列包含下面两种类型:virtual虚拟列:当从表中读取记录时,将计算该列stored存储列:当向表中写入新记录时,将计算该列并将其作为常规列存储在表中
— 基本语句
-- full_name字段就是虚拟列create table employees(emp_no int not null,birth_date date not null,first_name varchar(14) not null,last_name varchar(16) not null,gender enum ('M','F') not null,hire_date date not null,full_name varchar(30) as (concat(first_name, '', last_name)),primary key (emp_no),key name (first_name, last_name)) engine = InnoDBdefault charset = utf8mb4;-- 生成列字段的可选项`列名` `数据类型`[GENERATED ALWAYS] AS (expr) [VIRTUAL | STORED]-- 第一个选项表示这是个生成列, expr表示生成列生成的规则,最后一个选项表示这是虚拟列还是存储列[NOT NULL | NULL][UNIQUE [KEY]][[PRIMARY] KEY][COMMENT 'string']-- 执行插入时不需要指定虚拟列的值insert into employees(emp_no, birth_date, first_name, last_name, gender, hire_date)values (12456, '1987-10-02', 'ABC', 'XYZ', 'F', '2008-07-28');-- 如需要显式的指定,虚拟列的值只能为defaultinsert into employees(emp_no, birth_date, first_name, last_name, gender, hire_date, full_name)values (12456, '1987-10-02', 'ABC', 'XYZ', 'F', '2008-07-28', default);
窗口函数
窗口函数可以对查询中的每一行和与之相关的行执行计算,窗口函数是通过OVER和WINDOW子句来完成的。
cume_dist():累计分布值dense_rank():分区内当前行的等级(无间隔)first_value():窗口帧中第一行的参数值lag():落后于分区内当前行的那一行的参数值last_value():窗口帧中最末行的参数值lead():领先于分区内当前行的那一行的参数值nth_value():窗口帧中第N行的参数值ntile():分区内当前行的桶的编号percent_rank():百分比的排名值rank():分区中当前行的等级(有间隔)-
— 基本语句
-- 基本用法select concat(first_name, ' ', last_name) as full_name,salary,row_number() over (order by salary desc) as 'rank'from employeesjoin salaries on salaries.emp_no = employees.emp_nolimit 10;-- 分区用法select concat(first_name, ' ', last_name) as full_name,salary,row_number() over (partition by hire_date order by salary desc) as 'rank'from employeesjoin salaries on salaries.emp_no = employees.emp_nolimit 10;
— 窗口命名
将窗口函数命名,使得可以复用窗口函数,无须每次都重新定义。
select hire_date, salary, rank() over w as 'rank'from employeesjoin salaries on salaries.emp_no = employees.emp_nowindow w as (partition by hire_date order by salary desc)order by salary desclimit 10;
— 第一个、最后一个、第N个值
select hire_date,salary,rank() over w as 'rank',first_value(salary) over w as 'first',nth_value(salary, 3) over w as 'third',last_value(salary) over w as 'last'from employeesjoin salaries on salaries.emp_no = employees.emp_nowindow w as (partition by hire_date order by salary desc)order by salary desclimit 10;
配置MySQL
MySQL有两种类型的参数:
静态参数:重启MySQL服务器后才能使之生效的参数动态参数:可以在不重启MySQL服务器的情况下即时更改它
参数可以通过以下方式进行设置。
配置文件:MySQL有一个配置文件,我们可以在其中指定数据的位置、MySQL可以使用的内存以及其他各种参数启动脚本:可以直接将参数传递给mysqld进程。启动脚本仅在调用服务器时才有效使用SET命令(仅限动态变量):通过该手段仅限的操作将持续到服务器重新启动。且还需要在配置文件中设置变量,以便在重新启动时保持更改持久化。另一种使更改持久化的方法是在PERSIST关键字或@@persist之前加上变量名称。使用配置文件
默认配置文件是
/etc/my.cnf(Red Hat和CentOS)和/etc/mysql/my.cnf(Debian)。— 基本语句
配置文件按照片区进行划分,所有与该片区有关的参数都可以放在对应的片区下。
[mysqld] # 片区名,该部分由mysql命令行客户端读取参数名 = 参数值[client] # 该部分由所有连接的客户端读取,包括mysql-cli参数名 = 参数值[mysqldump] # 该部分由名为mysqldump的备份工具读取参数名 = 参数值[mysqld_safe] # 该部分由mysqld_safe进程读取(MySQL服务器启动脚本)参数名 = 参数值[server]参数名 = 参数值[mysql] # 该部分由mysqld服务器读取
此外,
mysqld_safe进程会从选项文件中的[mysqld]和[server]部分读取所有选项。
在使用systemd的系统中,mysqld-safe将不会被安装。要配置启动脚本,需要在/etc/systemd/system/mysqld.service.d/override.conf中设置值。[Service]LimitNOFILE=max_open_filesPIDFile=/path/to/pid/pathLimitCore=core_file_limitEnvironment="LD_PRELOAD=/path/to/malloc/libary"Environment="TZ=time_zone_setting"
使用全局变量和会话变量
根据变量的作用域可以将变量分为两种:
全局变量:适用于所有新连接-
— 基本语句
-- 全局变量set global long_query_time = 1;-- 持久变量set persist long_query_time = 1;set @@persist.long_query_time = 1;-- 会话变量set session long_qeury_time = 1;
在启动脚本中使用参数
如果希望使用启动脚本(替代
systemd)来启动MySQL,尤其是在发生测试或临时更改时,那么可以将变量传递给脚本,而不是在配置文件中更改它。— 基本语句
/usr/local/mysql/bin/mysqld --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data --plugin-dir=/usr/local/mysql/lib/plugin --user=mysql --log-error=/usr/local/mysql/data/centos7.err --pid-file=/usr/local/mysql/data/centos7.pid --init-file=/tmp/mysql-init &
配置参数
— datadir
由MySQL服务器管理的数据存储在名为数据目录的目录下。数据目录的每个子目录都是一个数据库目录,并对应服务器管理的数据库。默认情况下,数据库目录有三个子目录。
mysql:MySQL系统数据库performance_schema:提供用于在运行时检查服务器内部执行情况的信息sys:提供一组对象,帮助更轻松的解释performance schema信息
除此之外,数据目录还包含日志文件、InnoDB表空间和InnoDB日志文件、SSL和RSA秘钥文件、mysqld的pid,以及存储持久化全局系统变量设置的mysql-auto.cnf。
如要设置数据目录,则需要更改datadir值,或将datadir值添加到配置文件中。datadir的默认值是/var/lib/mysql。
innodb_buffer_pool_size
这是InnoDB最重要的调优参数,它决定InnoDB存储引擎可以使用多少内存空间来缓存内存中的数据和索引。将其值设置的太低可能会降低MySQL服务器的性能,而将其值设置的太高会增加MySQL进程的内存消耗。MySQL8中的innodb_buffer_pool_size是动态的,这意味着可以更改innodb_buffer_pool_size而不用重启服务器。
调试innodb_buffer_pool_size指南:
- 找出数据集的大小。不要将
innodb_buffer_pool_size的值设置得高于数据集的值。假设有一个12GB的机器,数据集是3Gb,那么可以设置innodb_buffer_pool_size的值为3GB。如果后续数据集的大小增长了,可以在需要是增加它,而无需重新启动MySQL - 一般情况下,数据集的大小可以比可用RAM大得多。对于整个RAM,你可以为操作系统分配一些,为其他进程分配一些,为MySQL内的
per-thread缓存区分配一些,为InnoDB之外的MySQL服务器分配一些,其余的可以分配给InnoDB缓冲池。这是一个通用性很强的表,假设它是一个专用的MySQL服务器,所有表都是InnoDB的,并且per-thread缓存区都保留默认值,那么就可以开始使用了。如果系统内存不足,可以动态减小缓冲池的大小。 - RAM与缓冲池大小设置推荐
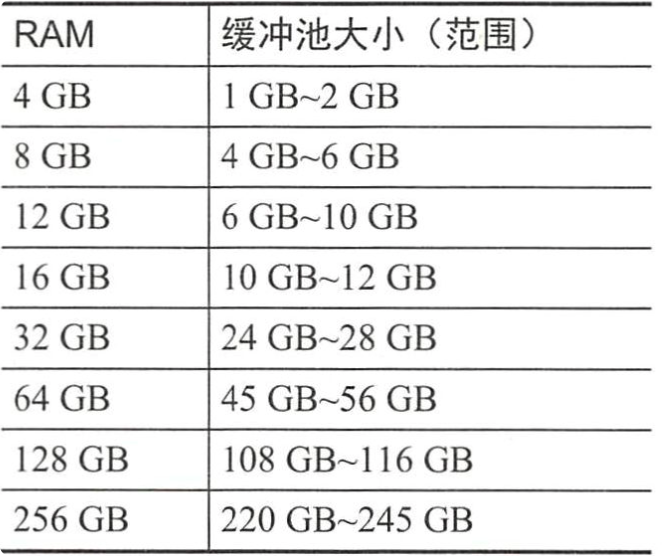
innodb_buffer_pool_instances
可以将InnoDB缓冲池换分为不同的区域,以便在不同线程读取和写入缓存页面时减少争用,从而提高并发性。例如,如果缓冲池大小分为64GB,innodb_buffer_pool_instances的值为32,则缓冲区被分为32个区域,每个区域的大小为2GB。
如果缓冲池的大小超过16GB,则可以设置示例,以便每个区域至少获得1GB的空间。
innodb_log_file_size
innodb_log_file_size是重做日志空间的大小,用于数据库崩溃是重放已提交的事务。innodb_log_file_size的默认值为48MB,这可能不足以满足生产工作负载的需求。开始的时候,可以将其值设置为1GB或2GB。此更改需要重新启动服务器才能生效。停止MySQL服务器的运行以确保它没有被错误的关闭。在my.cnf中进行修改并启动服务器。然而在早期版本中,需要停止服务器的运行,删除日志文件,然后再启动服务器。
更改数据目录
数据量会随着时间的推移而增长,当它超出文件系统的容量时,需要添加磁盘或将数据目录移动到更大的卷中。
— 基本操作
检查当前的数据目录。默认情况下,数据目录是
/var/lib/mysqlshow variables like '%datadir%';
停止MySQL,并确保它成功停止了
sudo systemctl stop mysql
检查状态
sudo systemctl status mysql应显示stopped MySQL Community Server
在新位置创建目录并将所有权更改到MySQL下
sudo mkdir -pv /datasudo chown -R mysql:mysql /data/
将文件移动到新的数据目录中
sudo rsync -av /var/lib/mysql /data
在
Ubuntu系统中,如果启用了AppArmor,则需要配置Access Controlvi /etc/apparmor.d/tunables/aliasalias /var/lib/mysql/ -> /data/mysql/,sudo systemctl restart apparmor
启动MySQL服务器并确认数据目录已更改
sudo systemctl start mysql
show variables like '%datadir%';
验证数据是否完整并删除旧的数据目录
sudo rm -rf /var/lib/mysql

若有收获,就点个赞吧
0 人点赞
